
引言
- 论文不论是在大家的刻板印象中,抑或是实际地阅读后都会给大家带来一种感觉。
所涉及的知识量是巨大的,对背后原理的理解是具有不小挑战的,其中的公式推导是极度烧脑的。 - 基于前面几点,论文确实是个硬骨头,因此用啃这个字来刻画论文阅读,是很恰当的。但是对于硬骨头,大家也都啃过真的“硬骨头”,其中的精华可能暗藏在骨缝之中,需要你对Main body的仔细阅读来发现与获取;如果莽撞的硬来,稍有不慎就会硌到牙,比如说你开始和数学公式斗争。同时,也可能会遇到有大片的肉块密布的情况,也就是这篇文章的摘要部分的信息量很大,有许多是有价值的信息,但是每个可能都需要展开查询。对于这种久旱逢甘霖的情形,有人可能就会欢欣鼓舞的大快朵颐,大家就开始疯狂查询,一会几十个页面就都打开了,但稍不留神就可能被噎住,短时间被巨大的信息量冲击可能就会有种眼花缭乱的感觉,稍有不慎就会偏离方向。综上所述,无论是因为啃不动论文,或是啃论文的方法不当,都会让我们陷入卷帙浩繁的文献汪洋,迷失了方向,迷失了自我。那么接下来我们将给出两种论文阅读的途径,一种是我们团体参与啃论文俱乐部走到今天运用的方法,另一种是清华彭明辉教授的方法。
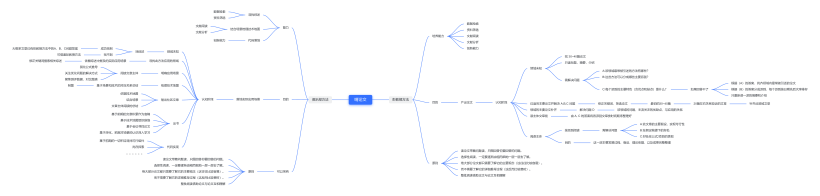
- 上图我们就详细地给出了俱乐部的方法与彭教授的方法,我们基于彭教授的方法对我们俱乐部的方法进行了相应的对比。下文我们就将上图的部分信息进行一定程度的展开补充。
1、目标导向
- 这两种方法的最终目标导向是不同的。
彭教授方法的目标导向:
根据已有的学术成果去创造出新的知识,力图实现理论层面的突破。
俱乐部啃论文的目标导向:
在已有的文献中探寻是否有更好的技术可以替换现有的技术, 力图实现代码层面的应用。
2、能力导向
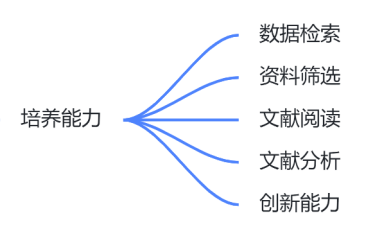
- 这一层面我们啃论文俱乐部与彭教授的要求是趋同的。彭教授方法:
- 俱乐部方法:
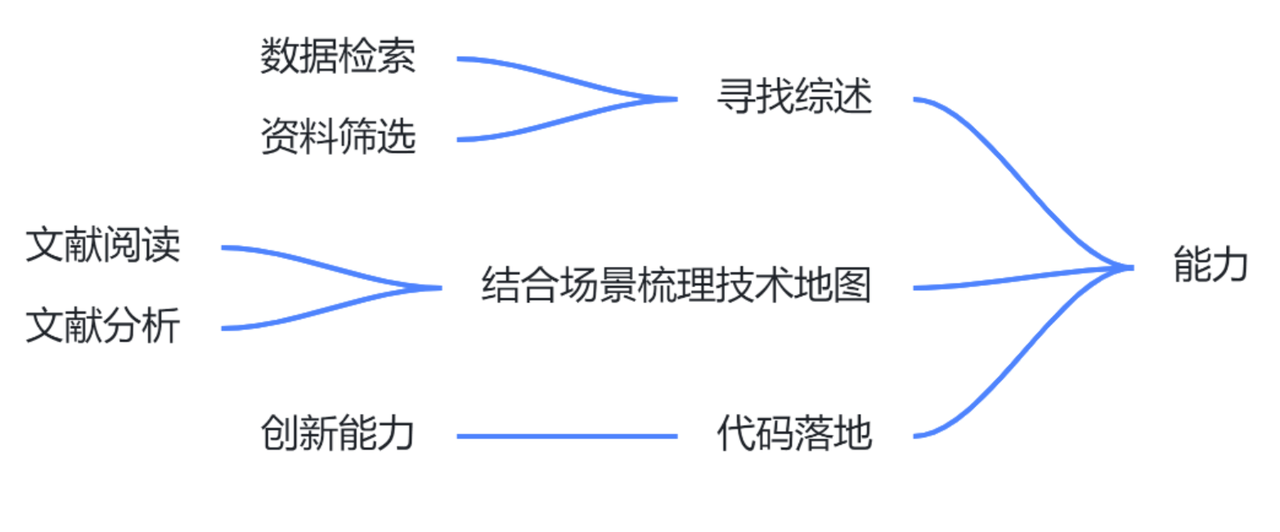
数据检索的能力
你到底要用什么样的关键词和查所程序去保证你已经找出所有相关的文献?这是第一个大的挑战。
资料筛选的能力
你如何可以只读论文的题目、摘要、简介和结论,而还没有完全看懂内文,就准确地判断出这篇论文中是否有值得你进一步参考的内容,以便快速地把需要仔细读完的论文从数百篇降低到几篇?
期刊论文的阅读能力
自己从无组织的知识中检索、筛选、组织知识的能力。
期刊论文的分析能力
对一切既有进行精确批判的能力一个严格训练过的合格硕士,他做事的时候应该是不需要有人在背后替他做检证,他自己就应该要有能力分析自己的优、缺点,主动向上级或平行单位要求支持。其实,至少要能够完成这个能力,才勉强可以说你是有「独立自主的判断能力」。
创新的能力
硕士毕业生却应该要有能力创造知识。
3、论文阅读
- 这一部分彭教授的方法构建对一个领域的认知时是基于大量的文献,然后以找到三个问题的答案为目的去阅读梳理该领域的技术的,我们俱乐部是采用
先阅读综述的方式可以快速的在综述中完成这一部分,当然在实在找不到相关综述的情况下,我们可以采用彭教授的梳理方式。但与此同时我们可以在阅读综述时,寻找彭教授所说的三个问题的答案,这样效率会更加高。
彭教授方法:
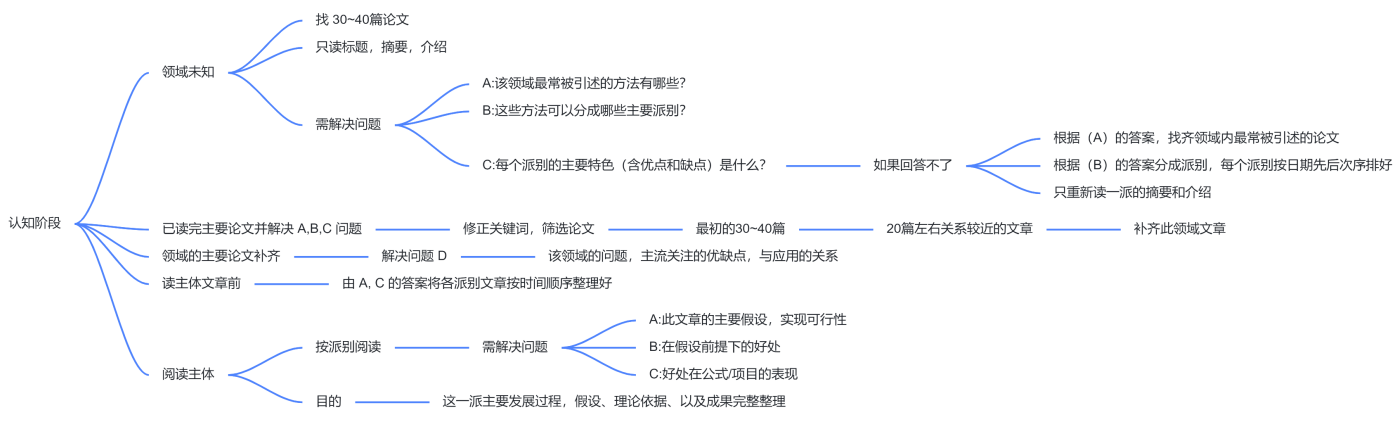
- 俱乐部方法:
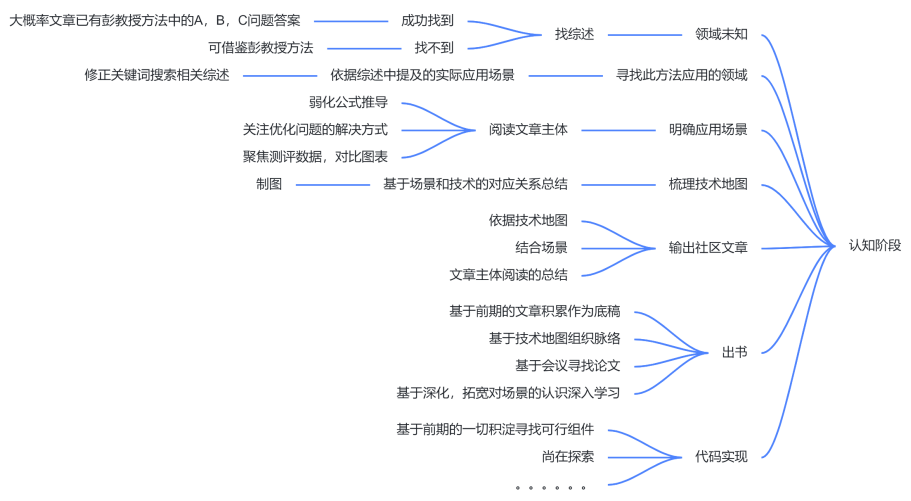
Part Ⅰ
摘要/介绍 部分
- 必须要学会只看Abstract和Introduction便可以判断出这篇论文的重点和你的研究有没有直接关连,从而决定要不要把它给读完。(以后不管是做事或做学术研究,都比别人有能力从更广泛的文献中挑出最值得参考的资料。)
- 功能 :
- 问题背景起源。
- 前人已有主要贡献。
- 前人未解问题。
- 此背景下本论文的想解决的问题及重要性。
- 操作步骤:
- 目的:初学学生,了解以前研究的概况。
- 题目可能相关的论文收集个 30~40 篇 <=> 读综述,更加简便。
- 只读 Abstract 和 Introduction,不读 Main Body(本文),必要时参考 examples 和 Conclusions。
- 直到你能回答下面这三个问题:(综述可以给你答案)。
- 在这领域内最常被引述的方法有哪些?(问题A)[技术地图]。
- 这些方法可以分成哪些主要派别?(问题B)[技术地图]。
- 每个派别的主要特色(含优点和缺点)是什么?(问题C)。
- 回答不了(问题C)。
- step 1: 根据(问题A)的答案,找齐领域内最常被引述的论文。
- step 2: 根据(问题B)的答案分成派别,每个派别按日期先后次序排好。
- step 3: 只重新读一派的 Abstract 和Introduction。
- 必要时简略参考内文,目的读懂 Introduction 内与这派有关的陈述,而不需要真的看懂所有内文。
- 照日期先后读,读的时候只企图回答一个问题:这一派的创意与主要诉求是什么?
- 这样,你逐派逐派地把每一派的 Abstract 和 Introduction 给读完,总结出这一派主要的诉求、方法特色和优点(每一篇论文都会说出自己的优点,仔细读就不会漏掉)。
- 其次,你再把这些论文拿出来,但是只读 Introduction,认真回答下述问题:「每篇论文对其它派别有什么批评?」然后你把读到的重点逐一记录到各派别的「缺点」栏内。
- 通过以上程序,你就应该可以掌握到(问题A)、(问题B)、和(问题C)三个问题的答案。这时你对该领域内主要方法、文献之间的关系算是相当熟捻了,但是你还是只仔细读完 Abstract和 Introduction 而已,内文则只是笼统读过。
硕士生必须学会选择性的阅读,而且必须锻炼出他选择时的准确度以及选择的速度,不要浪费时间在学用不着的细节知识!多吸收「点子」比较重要,而不是细部的知识。「这对俱乐部同样适用」。
Part Ⅱ
修正关键词,筛选论文
- 目前已经掌握此领域主要论文,测试keywords不恰当与否,修正 keywords 再搜寻,补齐此领域的主要文献,原来 30~40 篇论文中关系较远的论文筛选掉,只保留 20 篇左右确定跟关系较近的文献。如果有把握,可以删除一两个你不想用的派别(要有充分的理由),只保留两、三个派别(也要有充分的理由)继续做完以下工作。
Part Ⅲ
利用(问题C)每个派别的主要特色(含优点和缺点)是什么? 的答案,再进一步回答一个问题:
- 这个领域内大家认为重要的关键问题有哪些?
- 有哪些特性是大家重视的优点?有哪些特性是大家在意的缺点?
- 这些优点与缺点通常在哪些应用场合时会比较被重视?在哪些应用场合时比较不会被重视?
- 目的:整理出这个领域(研究题目)主要应用场合,以及这些应用场合上该注意的事项。【技术地图】
- 最后,在你真正开始念论文的 main body 之前。
- 你应该要先根据 :
- (问题A)在这领域内最常被引述的方法有哪些?和(问题C)每个派别的主要特色(优点和缺点)是什么?的答案。
- 把各派别内的论文整理在同一个档案夹里,并照时间先后次序排好。
- 然后依照这些派别与你的研究方向的关系远近,一个派别一个派别地逐一把各派一次念完一派的 main bodies。
对于俱乐部我们可能是锚定了具体的应用场景后根据场景进行 Main body 的阅读而不是上述过程。
Part Ⅳ
阅读主体(也对应三个问题)-(多要结合文中图表去理解)
a. 这篇论文的主要假设是什么(在什么条件下它是有效的),并且评估一下这些假设在现现条 件下有多容易(或多难)成立。愈难成立的假设,愈不好用,参考价值也愈低。
b. 在这些假设下,这篇论文主要有什么好处。
c. 这些好处主要表现在哪些公式的哪些项目的简化上。
至于整篇论文详细的推导过程,你不需要懂。除了三、五个关键的公式(最后在应用上要使用 的公式,你可以从这里评估出这个方法使用上的 方便程度或计算效率*,以及在非理想情境下这些公式使用起来的可靠度或稳定性)之外,其它公式都不懂也没关系,公式之间的恒等式推导过程可以完全略过去。假如你要看公式,重点是看公式推导过程中引入的假设条件,而不是恒等式的转换。
目的:这一派的主要发展过程,主要假设、主要理论依据、以及主要的成果做一个完整的整理。
- 根据(问题D)的答案以及这一派的主要假设,进一步回答下一个问题:
这一派主要的缺点有哪些。【我们团队目前觉得这一点可能不必要】 - 最后,根据(A)、(B)、(C)、(D)的答案综合整理出:这一派最适合什么时候使用,最不适合什么场合使用。
- 一定要同时有方法特性表与应用场合特性分析表放在 一起后,才能判断一个方法的适用性。
4、阅读论文的原则

- 读论文带着问题读,只图回答你要回答的问题。
- 选择性阅读,一定要逐渐由粗而细地一层一层去了解。上面所规划的读论文的次序,就是由粗而细,每读完一轮,你对知识就增加一层。根据这一层知识就可以问出下一层更细致的问题,再根据这些更细致的问题去重读,就可以理解到更多的内容。因此,一定是一整批一起读懂到某个层次,而不是逐篇逐篇地整篇一次读懂。
- 第一轮读完后,可以根据第一轮所获得的知识判断出哪些论文与你的议题不相关,不相关的就不需要再读下去了。这样才可以从广泛的论文里逐层准确地筛选出你真正非懂不可的部分。不要读不会用到的东西,白费的力气必须被极小化!其实,绝大部分论文都只需要了解它的主要观念(这往往比较容易),而不需要了解它的详细推导过程(这反而比较费时)。
- 其次,一整批一起读还有一个好处:同一派的观念,有的作者说得较易懂,有的说得不清楚。整批读略过一次之后,就可以规划出一个你以为比较容易懂的阅读次序,而不要硬碰硬地在那里撞墙壁。你可以从甲论文帮你弄懂以论文的一个段落,没人说读懂甲论文只能靠甲论文的信息。所以,整批阅读很像在玩跳棋,你要去规划出你自己阅读时的「最省力路径」。
5、办法实操
- 现在,假设我们已经在前文方法的基础上留下了一篇合适文献,如何对其进行合理有效地解析是即将面临的关键问题。为方便起见,接下来以我们曾经捧读过的《FSST: Fast Random Access String Compression》一文为例,对彭明辉教授的实行办法作一个上手实操,回顾优化自身的同时更供参考。

一、从概要判断关联性
- 首当其冲的 Abstract 说明全文的主要贡献、方法特色与主要内容:

- 主要贡献:提出了一种叫做“快速静态符号表”的轻量级字符串压缩方案。
- 方法特色:在文本数据上的压缩、解压速度与 LZ4 等方法相似或更好,压缩比更高。
- 主要内容:支持随机访问单个压缩后的字符串,可以延迟对数据的解压和查询等。
- 至此,可能还无法确切了解“静态符号表”的含义,但它的特点价值却足够高(LZ4 以极快的压、解压速度而著称),这是其亮点,因而足以有理由支撑我们继续阅读下去。
“Introduction 的功能是介绍问题的背景和起源,交代前人在这个题目上已经有过的主要贡献,说清楚前人留下来的未解问题,以及在这个背景下这篇论文的想解决的问题和它的重要性。”

- Introduction 这一部分信息量较大,是对全文组织内容的串联,应当细致入微地多过几遍。仅以其中截取的片段为实例:首先介绍了字符串在当下的广泛背景 —— 字符串经常在数据库中被用作各种数据的万能表示类型。再引出现实问题 —— 但字符串的唯一性与数据库中字符串通常只有百十 byte 大小的特点,致使传统的、依靠压缩多次完全重复字符串方式实现压缩的字典压缩算法无法很好地发挥效用,这要求字符串的输入大小需要达到几 kb 以上时才能满足,二者之间由此产生了矛盾,并举例 LZ4 算法进行了粗略论证。其次,传统的按块排序的通用字符串压缩算法也无法很好地满足数据库对单个字符串属性实现随机访问的需求。

- 另外,我们还会注意作者多次强调到这样一个核心技术实现的字眼 ——AVX512 SIMD。如果曾经了解过,会知道它是由 Intel 所推出的新一代独有加速指令集架构,这时,去搜索引擎具体深入下再合适不过了。不难获取到这样一些信息:Intel 平台独占、流行于 HPC、能耗比较高……由此,可初步推断 FSST 或许
不会具备可观的通用性。 - 至此,开头所述选项大致都已找到了答案可补充,同时完成了判断关联性的目的,并可结合自身研究方向的需求定为“中等”级别。
二、着重主体创新与优缺点
“在你第一次有系统地念某派别的论文 main bodies 时,你只需要念懂:这篇论文的主要假设是什么(在什么条件下它是有效的),并且评估一下这些假设在现实条件下有多容易(或多难)成立。愈难成立的假设,愈不好用,参考价值也愈低。在这些假设下,这篇论文主要有什么好处。这些好处主要表现在哪些公式的哪些项目的简化上。”

- 在阐述 FSST 的实现过程时,作者首先指明了“字符串”这样一种数据类型的特点:尽管每个单独的字符串可能很短、几乎没有冗余,但一个列的字符串通常有共同的子字符串,如下图 URL 类数据集所示:

- 所以,FSST 的创新点就在,其识别经常出现的子字符串符号,并将它们替换为短的、固定大小的代码。再者,符号表在解压过程中保持静态,这意味着在解压某个单个字符串的时候不必依赖同一个压缩块中的其他关联字符串;但 LZ4 一类的算法会在压缩与解压期间修改字符串内部状态。
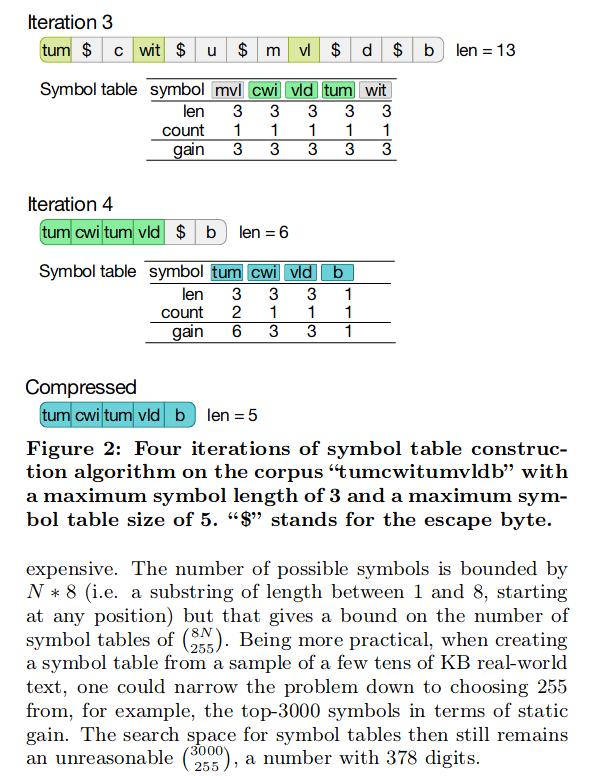
- 与此同时,在正文中我们不乏也会看到上图类似的内容。其实,这即是彭明辉教授所述的“恒等式转换”,如果浪费时间在研究恒等式是如何推导出来的方向上,是意义不大的。重要的是关注公式推导过程中引入的假设条件,而非恒等式转换。
- 后文相关内容可参考【ELT.ZIP】OpenHarmony啃论文俱乐部——快速随机访问字符串压缩。
三、归纳问题、技术、场景
- 这里的方法与应用场合特性表即对应我们俱乐部常常所强调的问题、技术、场景。问题,描述了对象的什么结构的什么层面存在的不足或是缺陷,导致无法适应于当下的需求;技术,为了满足这样一种需求而产生,具备其独有的优势;场景,在何时、何种场合下会出现这种需求,需求量多还是少,技术解决需求量的多少决定了论文的含金量。
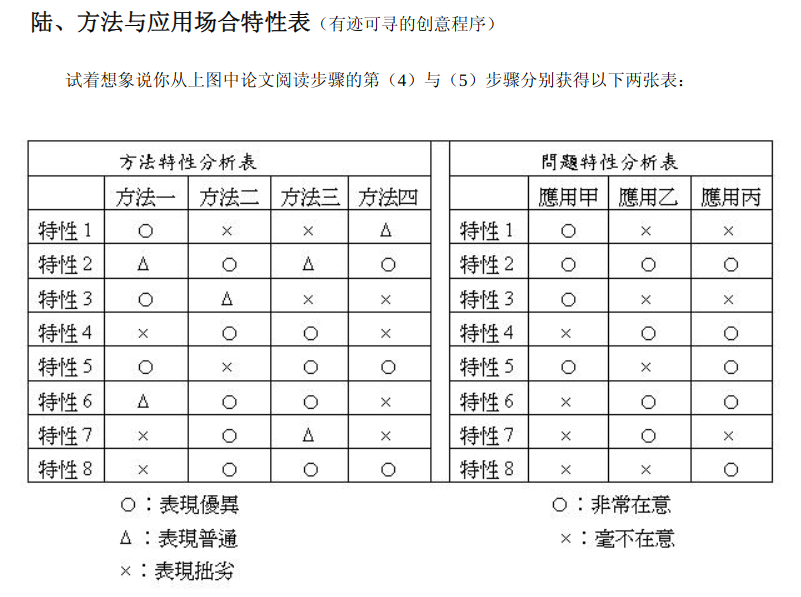
- 结合上文,不难分析出本文的问题是现有的压缩算法无法很好地压缩字符串,技术是FSST快速静态符号表方案,场景是数据库系统、信息检索、网络云存储、文本分析等。
方法没有好坏,只有相对优缺点点;只有当方法的特性与应用场合的特性不合时,才能下结论说这方法「不适用」;二当方法的特性与应用场合的特性吻合时,则下结论说这方法「很适用」。因此,一定要同时有方法特性表与应用场合特性分析表放在一起后,才能判断一个方法的适用性。
- 更有意义的是,这样一个过程把突破瓶颈所需的创意简化成了一种有迹可循的工作,把冷酷无情的科研演化成了轻松愉快的奋斗日记。
文章相关附件可以点击下面的原文链接前往下载:
© 版权声明
文章版权归作者所有,未经允许请勿转载。