并行和并发都是指多个任务同时执行的概念,但是它们之间有着明显的区别。,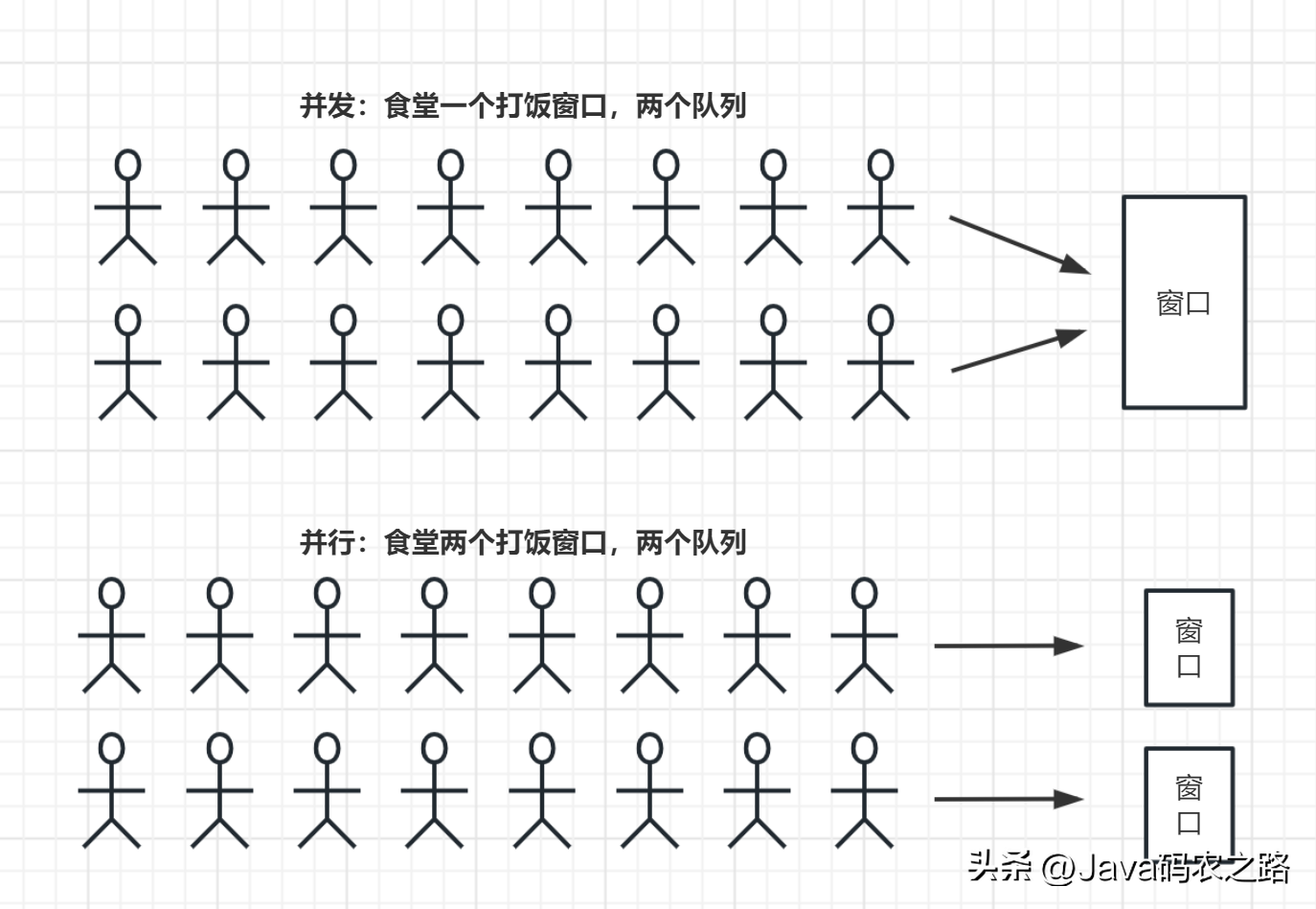 ,总的来说,虽然并行和并发都是多任务处理的方式,但是并行是采用多核处理器等硬件实现任务同步执行,而并发则是通过操作系统的调度算法来合理地分配系统资源,使得多个任务看上去同时执行。,进程和线程是操作系统中的概念,用于描述程序运行时的执行实体。,进程:一个程序在执行过程中的一个实例,每个进程都有自己独立的地址空间,也就是说它们不能直接共享内存。进程的特点包括:,线程:进程中的一个执行单元,一个进程中可以包含多个线程,这些线程共享进程的内存空间。线程的特点包括:,
,总的来说,虽然并行和并发都是多任务处理的方式,但是并行是采用多核处理器等硬件实现任务同步执行,而并发则是通过操作系统的调度算法来合理地分配系统资源,使得多个任务看上去同时执行。,进程和线程是操作系统中的概念,用于描述程序运行时的执行实体。,进程:一个程序在执行过程中的一个实例,每个进程都有自己独立的地址空间,也就是说它们不能直接共享内存。进程的特点包括:,线程:进程中的一个执行单元,一个进程中可以包含多个线程,这些线程共享进程的内存空间。线程的特点包括:,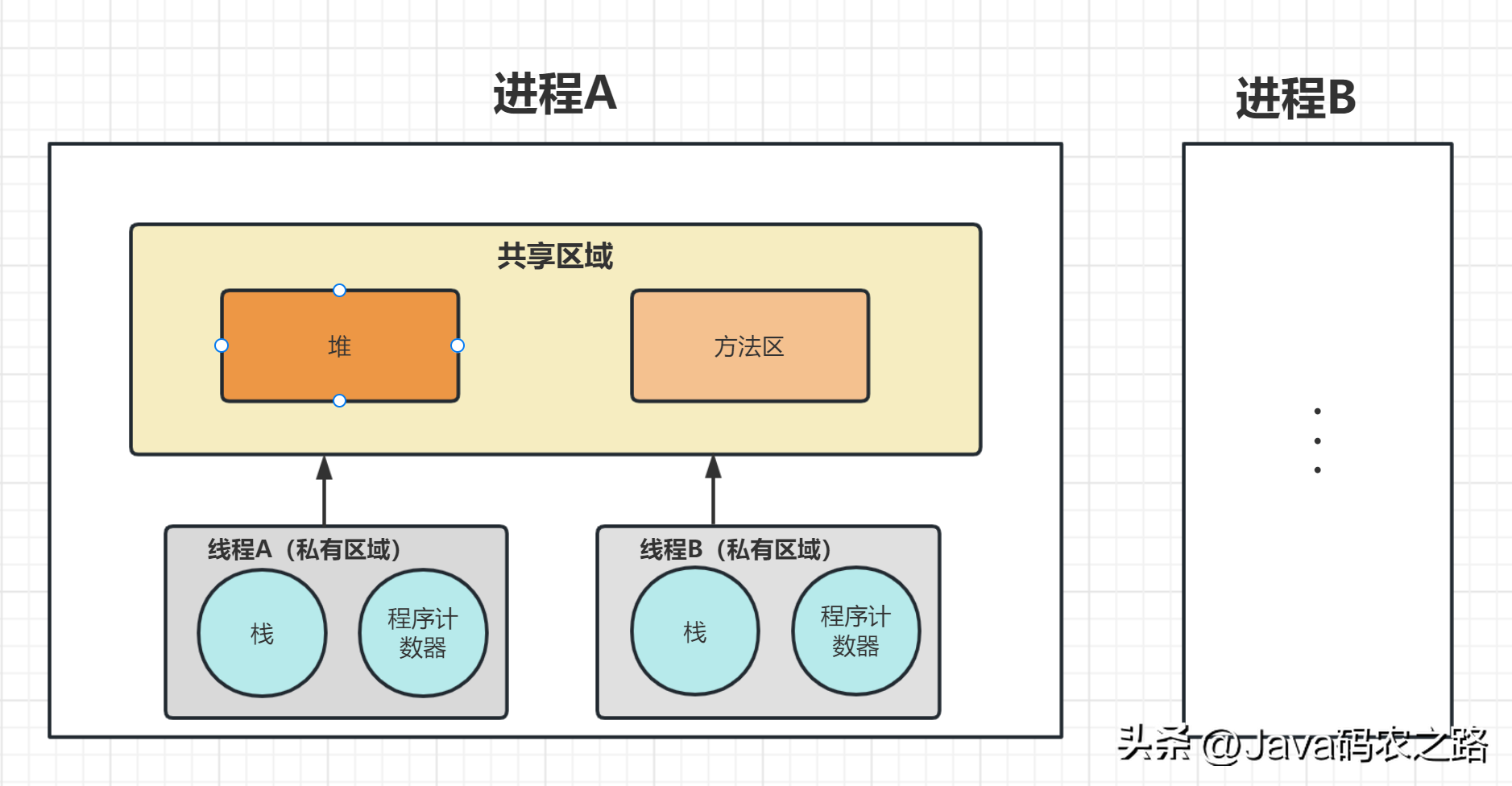 ,线程相比于进程,线程的创建和销毁开销较小,上下文切换开销也较小,因此线程是实现多任务并发的一种更加轻量级的方式。,Java中创建线程主要有三种方式:,
,线程相比于进程,线程的创建和销毁开销较小,上下文切换开销也较小,因此线程是实现多任务并发的一种更加轻量级的方式。,Java中创建线程主要有三种方式:,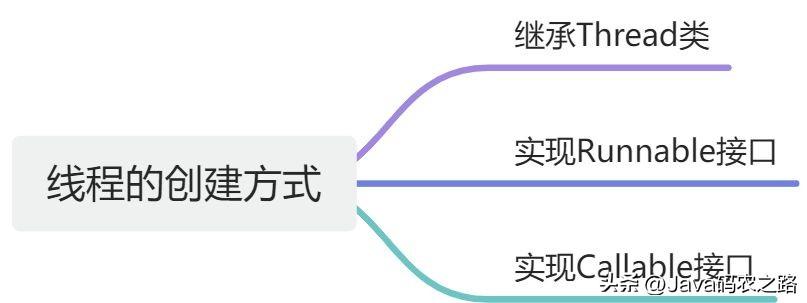 ,JVM执行start方法,会先创建一个线程,由创建出来的新线程去执行thread的run方法,这才起到多线程的效果。,start()和run()的主要区别如下:,
,JVM执行start方法,会先创建一个线程,由创建出来的新线程去执行thread的run方法,这才起到多线程的效果。,start()和run()的主要区别如下:,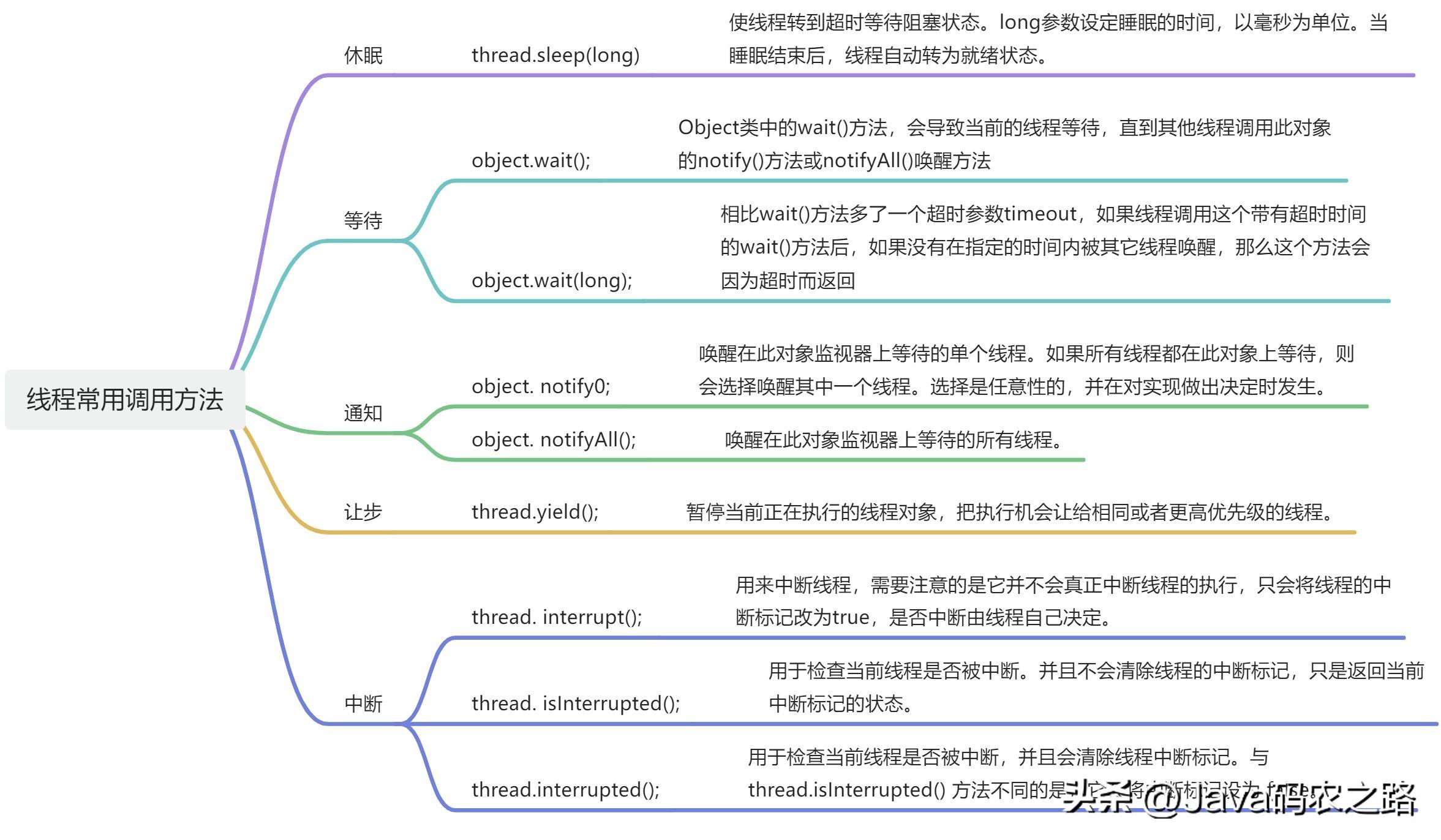 ,
, ,线程在自身的生命周期中, 并不是固定地处于某个状态,而是随着代码的执行在不同的状态之间进行切换,如下图:,
,线程在自身的生命周期中, 并不是固定地处于某个状态,而是随着代码的执行在不同的状态之间进行切换,如下图:,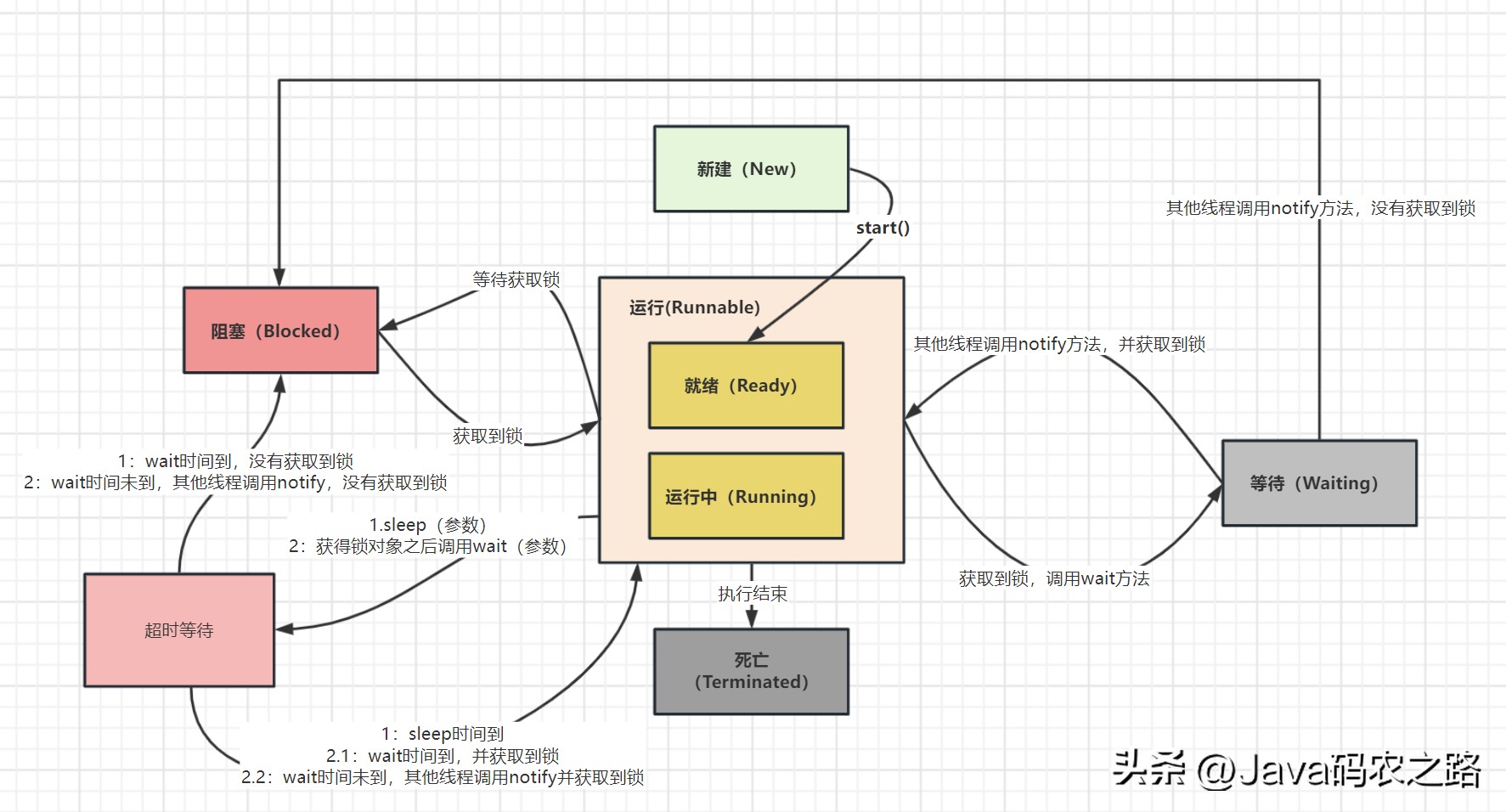 ,线程上下文切换指的是在多线程运行时,操作系统从当前正在执行的线程中保存其上下文(包括当前线程的寄存器、程序指针、栈指针等状态信息),并将这些信息恢复到另一个等待执行的线程中,从而实现线程之间的切换。,
,线程上下文切换指的是在多线程运行时,操作系统从当前正在执行的线程中保存其上下文(包括当前线程的寄存器、程序指针、栈指针等状态信息),并将这些信息恢复到另一个等待执行的线程中,从而实现线程之间的切换。,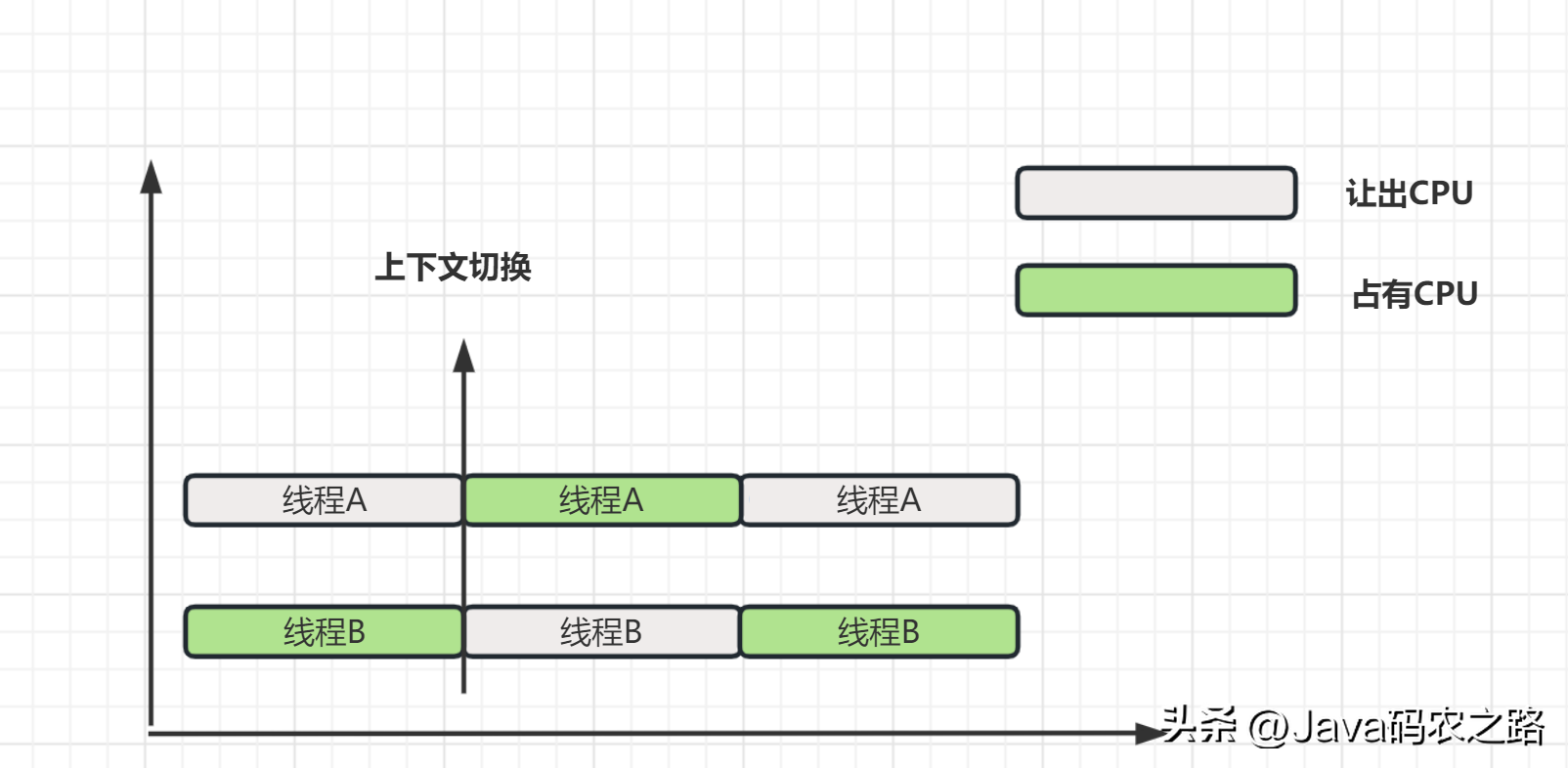 ,
,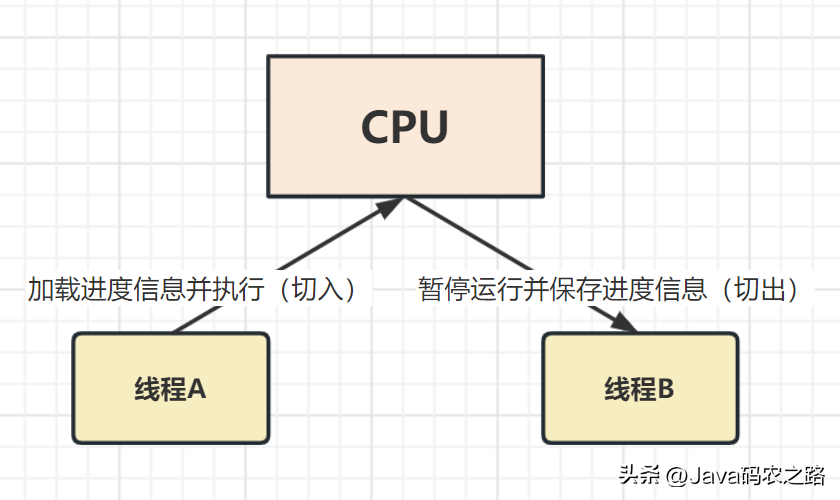 ,
,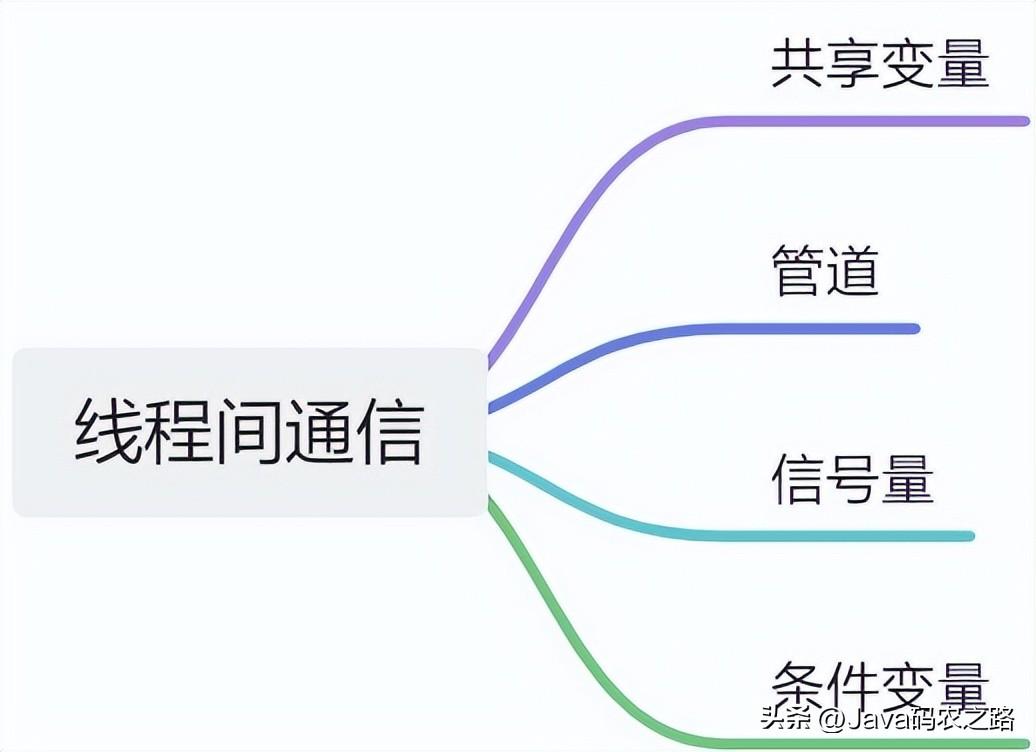 ,线程间通信是指在多线程编程中,各个线程之间共享信息或者协同完成某一任务的过程。常用的线程间通信方式有以下几种:,ThreadLocal也就是线程本地变量。如果你创建了一个ThreadLocal变量,那么访问这个变量的每个线程都会有这个变量的一个本地拷贝,多个线程操作这个变量的时候,实际是操作自己本地内存里面的变量,从而起到线程隔离的作用,避免了线程安全问题。,
,线程间通信是指在多线程编程中,各个线程之间共享信息或者协同完成某一任务的过程。常用的线程间通信方式有以下几种:,ThreadLocal也就是线程本地变量。如果你创建了一个ThreadLocal变量,那么访问这个变量的每个线程都会有这个变量的一个本地拷贝,多个线程操作这个变量的时候,实际是操作自己本地内存里面的变量,从而起到线程隔离的作用,避免了线程安全问题。,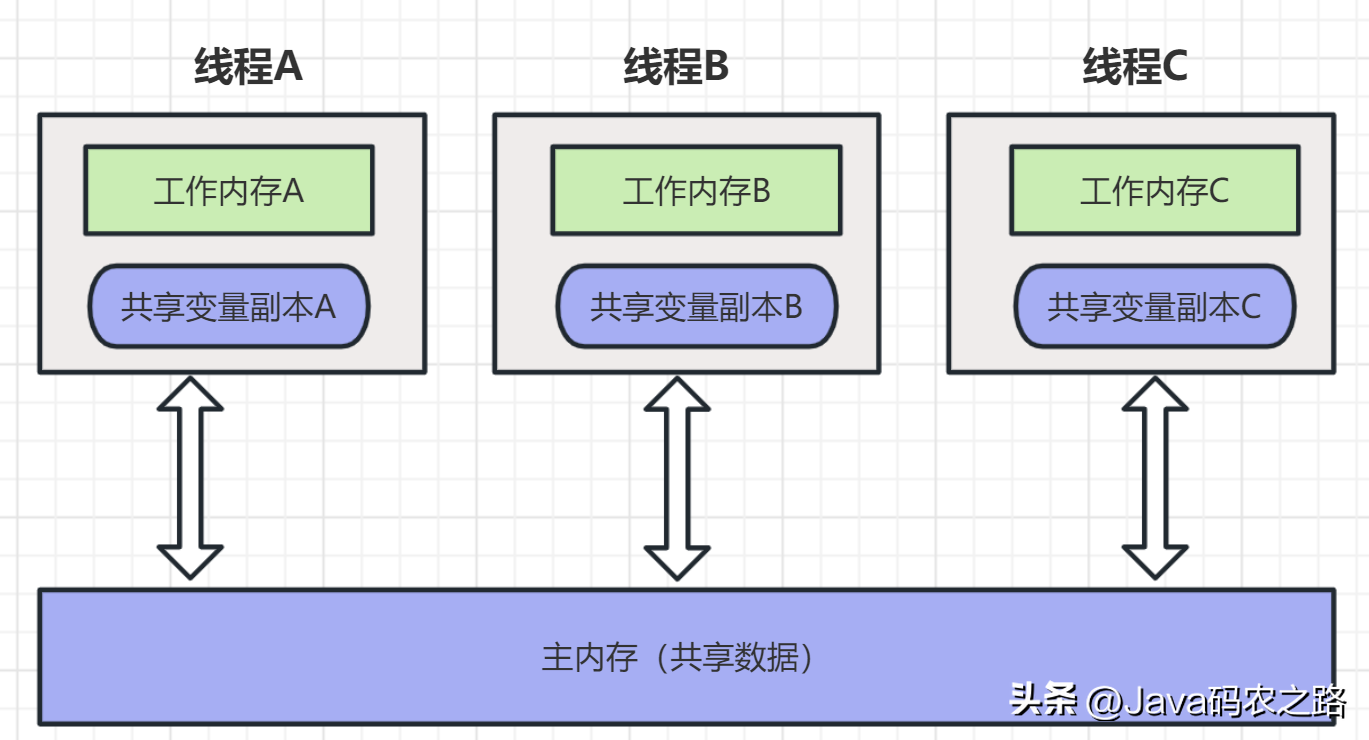 ,ThreadLocal是整个线程的全局变量,不是整个程序的全局变量。,
,ThreadLocal是整个线程的全局变量,不是整个程序的全局变量。,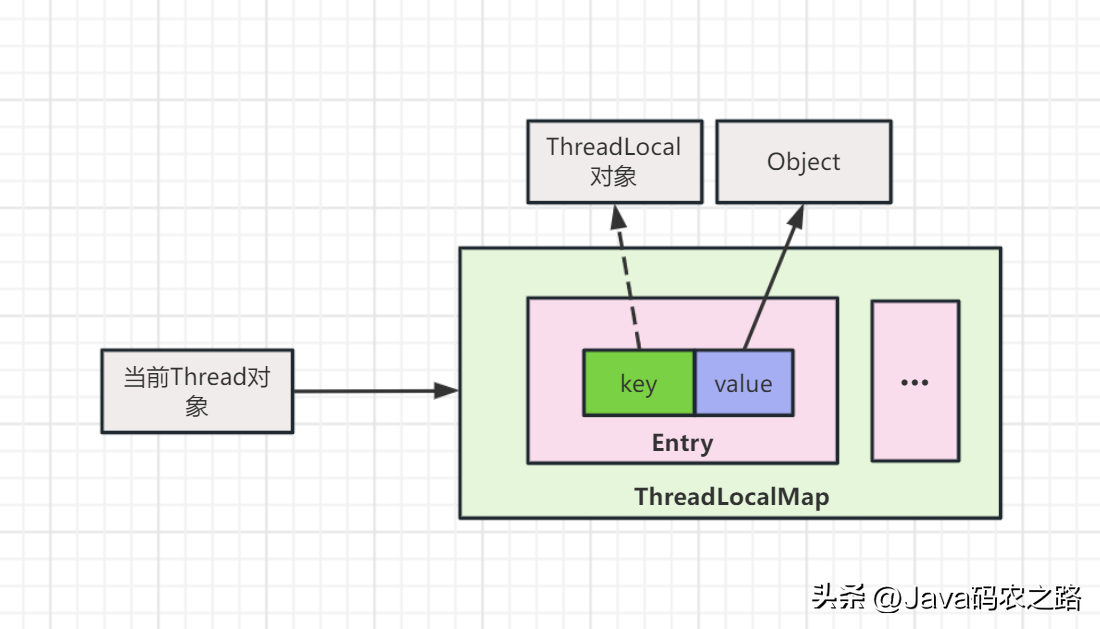 ,实现方式观察ThreadLocal的set方法:,如果在线程池中使用ThreadLocal会造成内存泄漏,因为当ThreadLocal对象使用完之后,应该要把设置的key,value,也就是Entry对象进行回收,但线程池中的线程不会回收,而线程对象是通过强引用指向ThreadLocalMap,ThreadLocalMap也是通过强引用指向Entry对象,线程不被回收,Entry对象也就不会被回收,从而出现内存泄漏。,解决办法是在使用了ThreadLocal对象之后,手动调用ThreadLocal的remove方法,手动清除Entry对象。,
,实现方式观察ThreadLocal的set方法:,如果在线程池中使用ThreadLocal会造成内存泄漏,因为当ThreadLocal对象使用完之后,应该要把设置的key,value,也就是Entry对象进行回收,但线程池中的线程不会回收,而线程对象是通过强引用指向ThreadLocalMap,ThreadLocalMap也是通过强引用指向Entry对象,线程不被回收,Entry对象也就不会被回收,从而出现内存泄漏。,解决办法是在使用了ThreadLocal对象之后,手动调用ThreadLocal的remove方法,手动清除Entry对象。,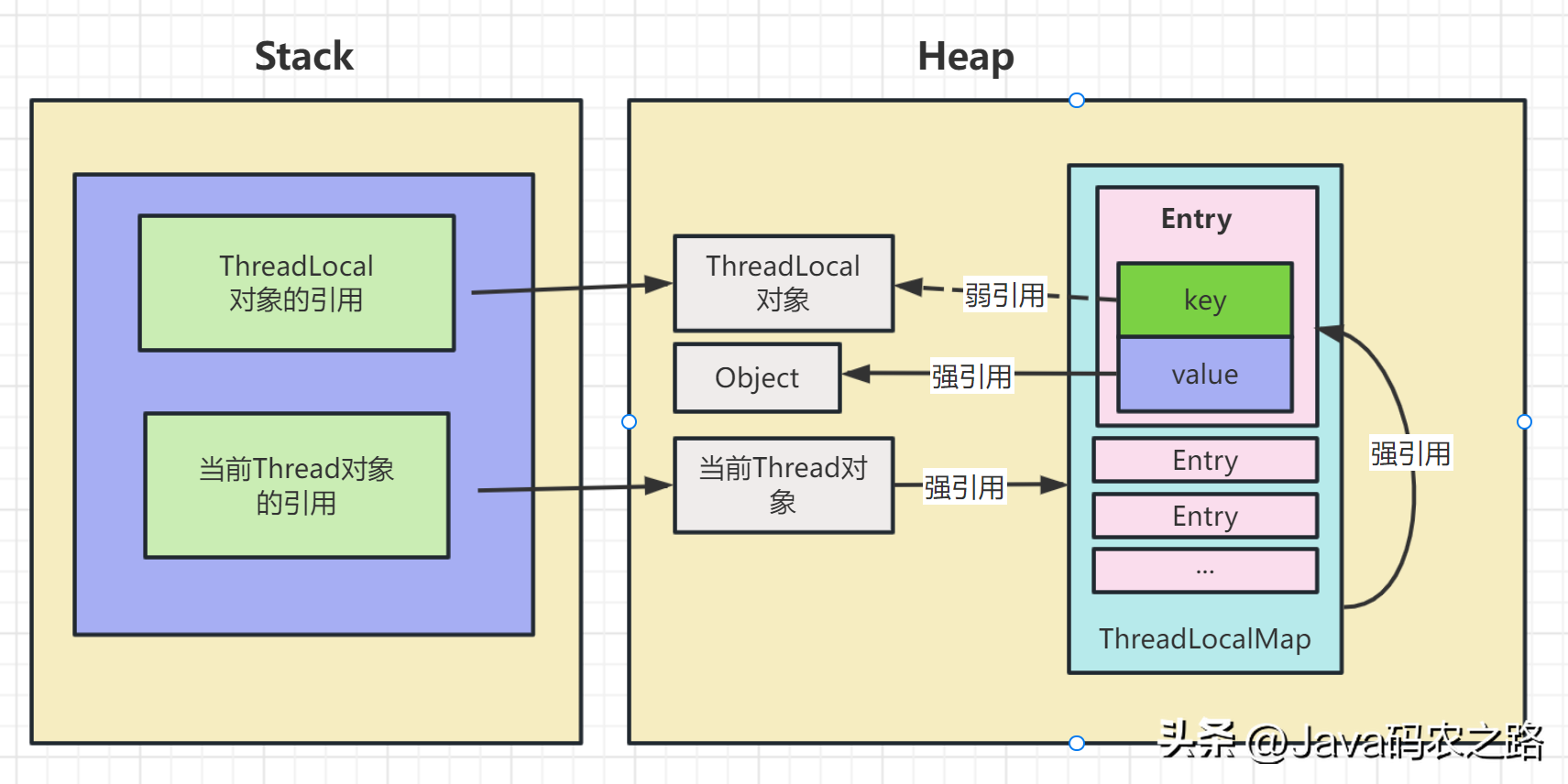 ,ThreadLocalMap虽然被称为Map,但是其实它是没有实现Map接口的,不过结构还是和HashMap比较类似的,主要关注的是两个要素:元素数组和散列方法。,
,ThreadLocalMap虽然被称为Map,但是其实它是没有实现Map接口的,不过结构还是和HashMap比较类似的,主要关注的是两个要素:元素数组和散列方法。,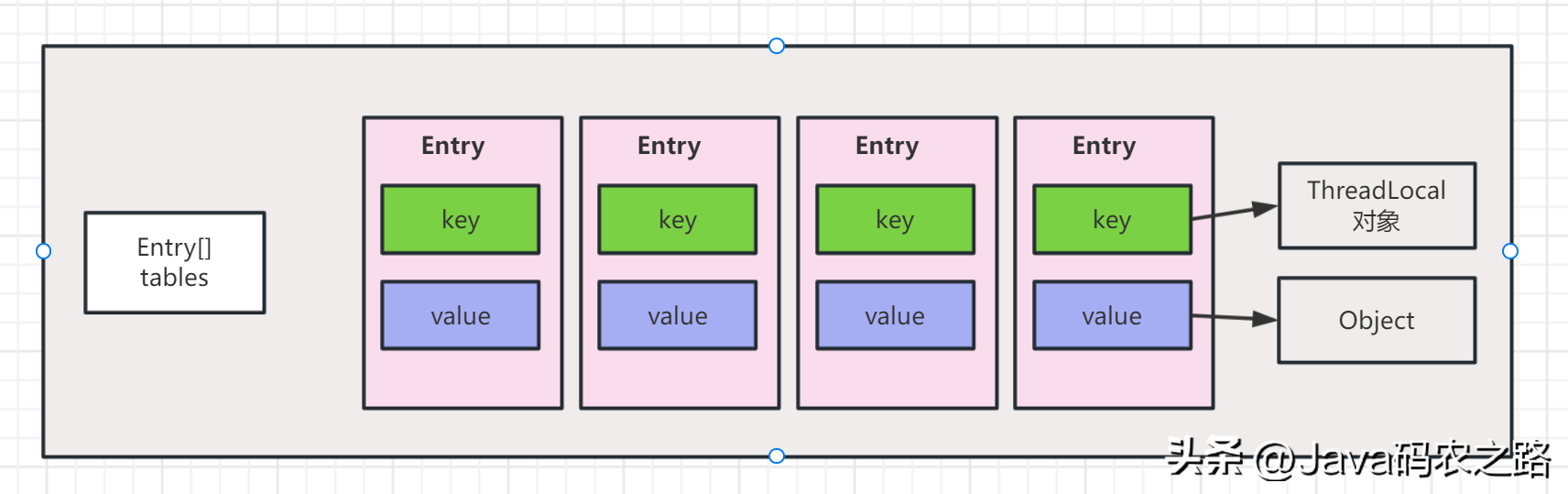 ,补充一点每创建一个ThreadLocal对象,它就会新增0x61c88647,这个值很特殊,它是斐波那契数也叫黄金分割数。这样带来的好处就是hash分布非常均匀。,我们可能都知道HashMap使用了链表来解决冲突,也就是所谓的链地址法。,ThreadLocalMap内部使用的是开放地址法来解决 Hash冲突的问题。具体来说,当发生Hash冲突时,ThreadLocalMap会将当前插入的元素从冲突位置开始依次往后遍历,直到找到一个空闲的位置,然后把该元素放在这个空闲位置。这样即使出现了Hash冲突,不会影响到已经插入的元素,而只是会影响到新的插入操作。,
,补充一点每创建一个ThreadLocal对象,它就会新增0x61c88647,这个值很特殊,它是斐波那契数也叫黄金分割数。这样带来的好处就是hash分布非常均匀。,我们可能都知道HashMap使用了链表来解决冲突,也就是所谓的链地址法。,ThreadLocalMap内部使用的是开放地址法来解决 Hash冲突的问题。具体来说,当发生Hash冲突时,ThreadLocalMap会将当前插入的元素从冲突位置开始依次往后遍历,直到找到一个空闲的位置,然后把该元素放在这个空闲位置。这样即使出现了Hash冲突,不会影响到已经插入的元素,而只是会影响到新的插入操作。,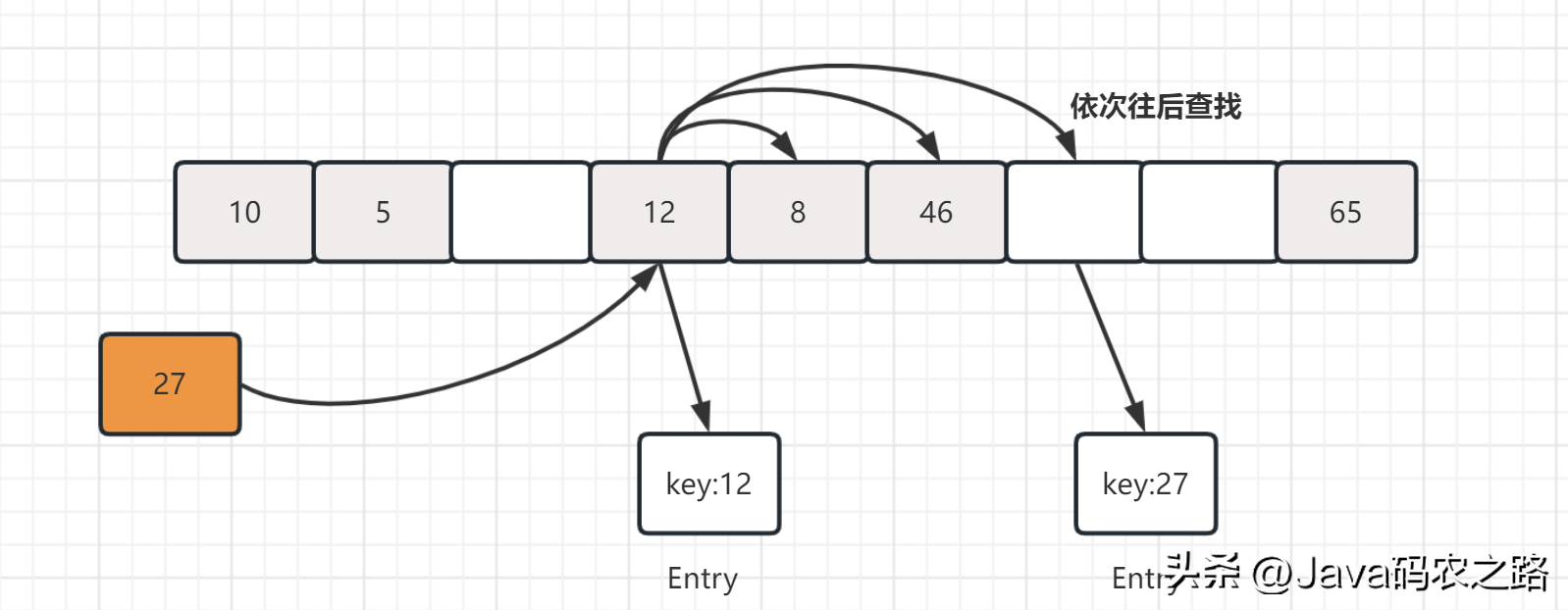 ,查找的时候,先根据ThreadLocal对象的hash值找到对应的位置,然后比较该槽位Entry对象中的key是否和get的key一致,如果不一致就依次往后查找。,ThreadLocalMap 的扩容机制和 HashMap 类似,也是在元素数量达到阈值(默认为数组长度的 2/3)时进行扩容。具体来说,在 set() 方法中,如果当前元素数量已经达到了阈值,就会调用 rehash() 方法,rehash()会先去清理过期的Entry,然后还要根据条件判断size >= threshold – threshold / 4 也就是size >= threshold * 3/4来决定是否需要扩容:,发现需要扩容时调用resize()方法,resize()方法首先将数组长度翻倍,然后创建一个新的数组newTab。接着遍历旧数组oldTab中的所有元素,散列方法重新计算位置,开放地址解决冲突,然后放到新的newTab,遍历完成之后,oldTab中所有的entry数据都已经放入到newTab中了,然后table引用指向newTab.,
,查找的时候,先根据ThreadLocal对象的hash值找到对应的位置,然后比较该槽位Entry对象中的key是否和get的key一致,如果不一致就依次往后查找。,ThreadLocalMap 的扩容机制和 HashMap 类似,也是在元素数量达到阈值(默认为数组长度的 2/3)时进行扩容。具体来说,在 set() 方法中,如果当前元素数量已经达到了阈值,就会调用 rehash() 方法,rehash()会先去清理过期的Entry,然后还要根据条件判断size >= threshold – threshold / 4 也就是size >= threshold * 3/4来决定是否需要扩容:,发现需要扩容时调用resize()方法,resize()方法首先将数组长度翻倍,然后创建一个新的数组newTab。接着遍历旧数组oldTab中的所有元素,散列方法重新计算位置,开放地址解决冲突,然后放到新的newTab,遍历完成之后,oldTab中所有的entry数据都已经放入到newTab中了,然后table引用指向newTab.,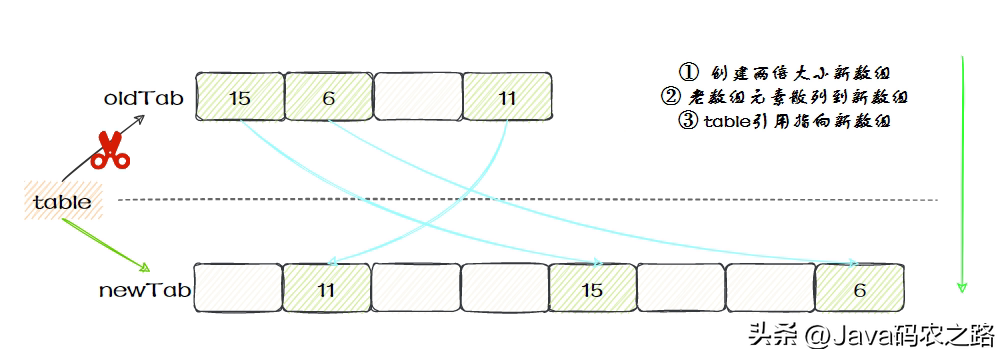 ,需要注意的是,新数组的长度始终是2的整数次幂,并且扩容后新数组的长度始终大于旧数组的长度。这是为了保证哈希函数计算出的位置在新数组中仍然有效。,在Java多线程编程中,父子线程之间的数据传递和共享问题一直是一个非常重要的议题。如果不处理好数据的传递和共享,会导致多线程程序的性能下降或者出现线程安全问题。ThreadLocal是Java提供的一种解决方案,可以非常好地解决父子线程数据共享和传递的问题。,那么它是如何实现通信的了?在Thread类中存在InheritableThreadLocal变量,简单的说就是使用InheritableThreadLocal来进行传递,当父线程的InheritableThreadLocal不为空时,就会将这个值传到当前子线程的InheritableThreadLocal。,Java 内存模型(Java Memory Model)是一种规范,用于描述 Java 虚拟机(JVM)中多线程情况下,线程之间如何协同工作,如何共享数据,并保证多线程的操作在各个线程之间的可见性、有序性和原子性。,具体定义如下:,Java内存模型的抽象图:,
,需要注意的是,新数组的长度始终是2的整数次幂,并且扩容后新数组的长度始终大于旧数组的长度。这是为了保证哈希函数计算出的位置在新数组中仍然有效。,在Java多线程编程中,父子线程之间的数据传递和共享问题一直是一个非常重要的议题。如果不处理好数据的传递和共享,会导致多线程程序的性能下降或者出现线程安全问题。ThreadLocal是Java提供的一种解决方案,可以非常好地解决父子线程数据共享和传递的问题。,那么它是如何实现通信的了?在Thread类中存在InheritableThreadLocal变量,简单的说就是使用InheritableThreadLocal来进行传递,当父线程的InheritableThreadLocal不为空时,就会将这个值传到当前子线程的InheritableThreadLocal。,Java 内存模型(Java Memory Model)是一种规范,用于描述 Java 虚拟机(JVM)中多线程情况下,线程之间如何协同工作,如何共享数据,并保证多线程的操作在各个线程之间的可见性、有序性和原子性。,具体定义如下:,Java内存模型的抽象图:,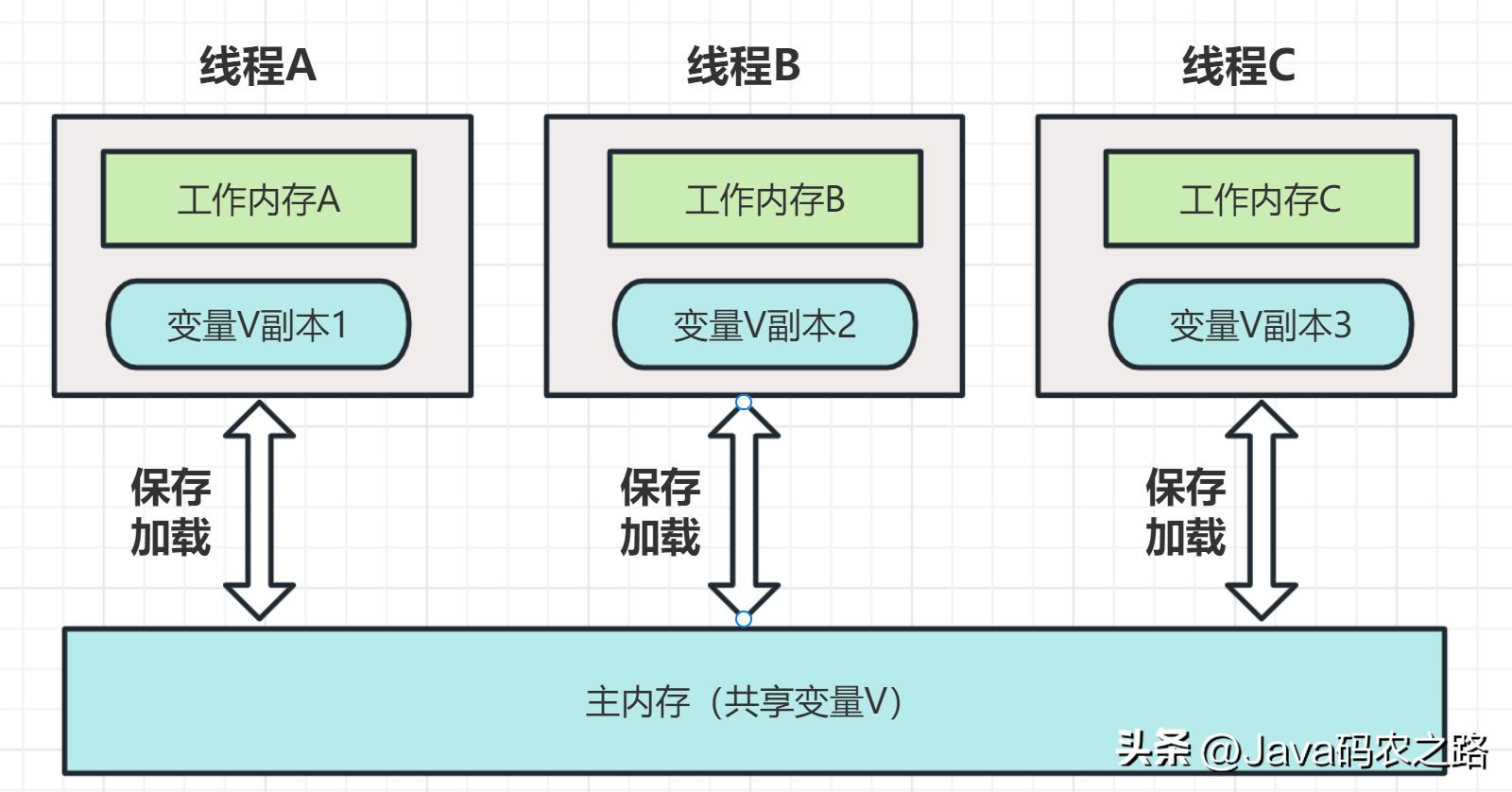 ,在这个抽象的内存模型中,在两个线程之间的通信(共享变量状态变更)时,会进行如下两个步骤:,原子性、有序性、可见性是并发编程中非常重要的基础概念,JMM的很多技术都是围绕着这三大特性展开。,线程切换会带来原子性问题,示例:,上面展示语句中,除了语句1是原子操作,其它两个语句都不是原子性操作,下面我们来分析一下语句2,其实语句2在执行的时候,包含三个指令操作,对于上面的三条指令来说,如果线程 A 在指令 1 执行完后做线程切换,线程 A 和线程 B 按照下图的序列执行,那么我们会发现两个线程都执行了 count+=1 的操作,但是得到的结果不是我们期望的 2,而是 1。,
,在这个抽象的内存模型中,在两个线程之间的通信(共享变量状态变更)时,会进行如下两个步骤:,原子性、有序性、可见性是并发编程中非常重要的基础概念,JMM的很多技术都是围绕着这三大特性展开。,线程切换会带来原子性问题,示例:,上面展示语句中,除了语句1是原子操作,其它两个语句都不是原子性操作,下面我们来分析一下语句2,其实语句2在执行的时候,包含三个指令操作,对于上面的三条指令来说,如果线程 A 在指令 1 执行完后做线程切换,线程 A 和线程 B 按照下图的序列执行,那么我们会发现两个线程都执行了 count+=1 的操作,但是得到的结果不是我们期望的 2,而是 1。,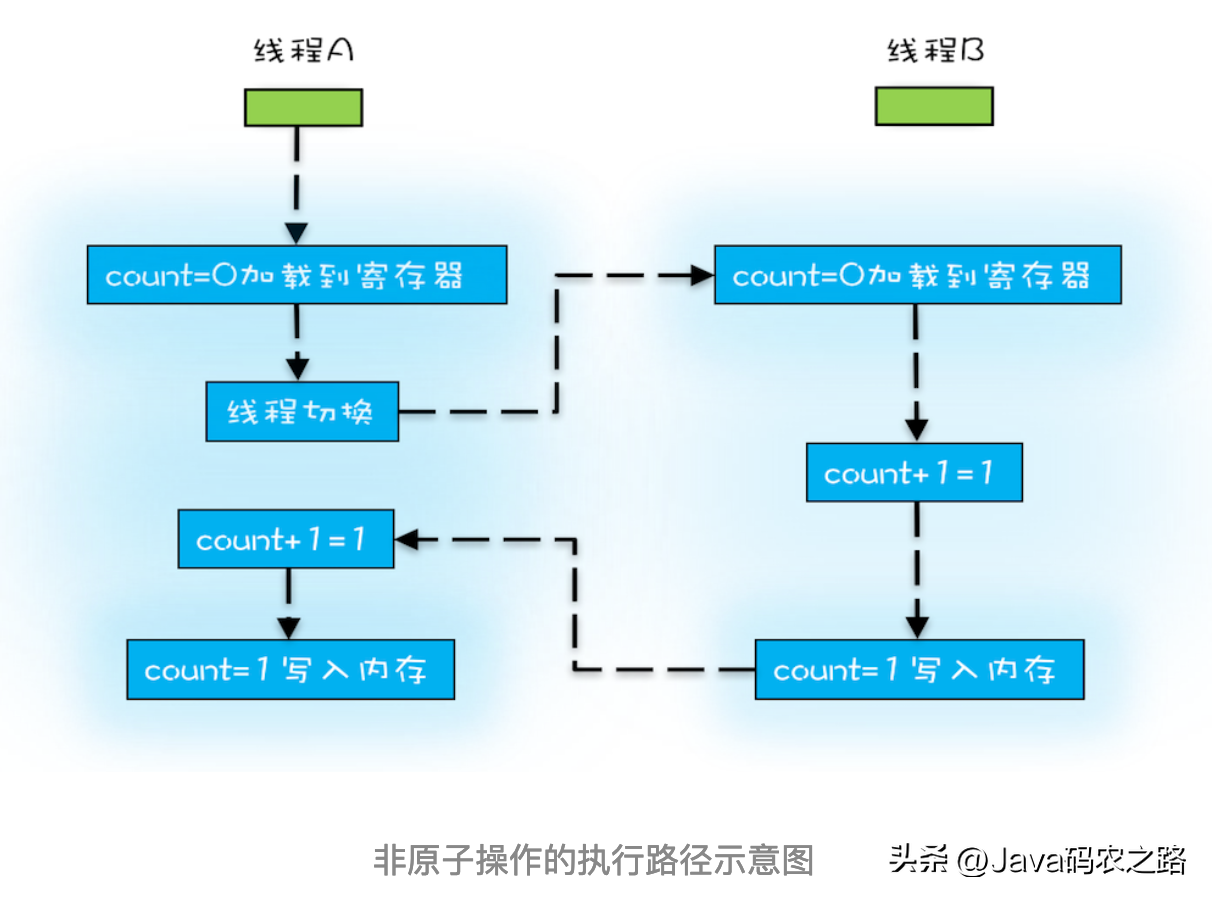 ,原子性、可见性、有序性都应该怎么保证呢?,在不影响单线程程序执行结果的前提下,计算机为了最大限度的发挥机器性能,对机器指令进行重排序优化。,
,原子性、可见性、有序性都应该怎么保证呢?,在不影响单线程程序执行结果的前提下,计算机为了最大限度的发挥机器性能,对机器指令进行重排序优化。, ,从Java源代码到最终实际执行的指令序列,会分别经历下面3种重排序:,
,从Java源代码到最终实际执行的指令序列,会分别经历下面3种重排序:,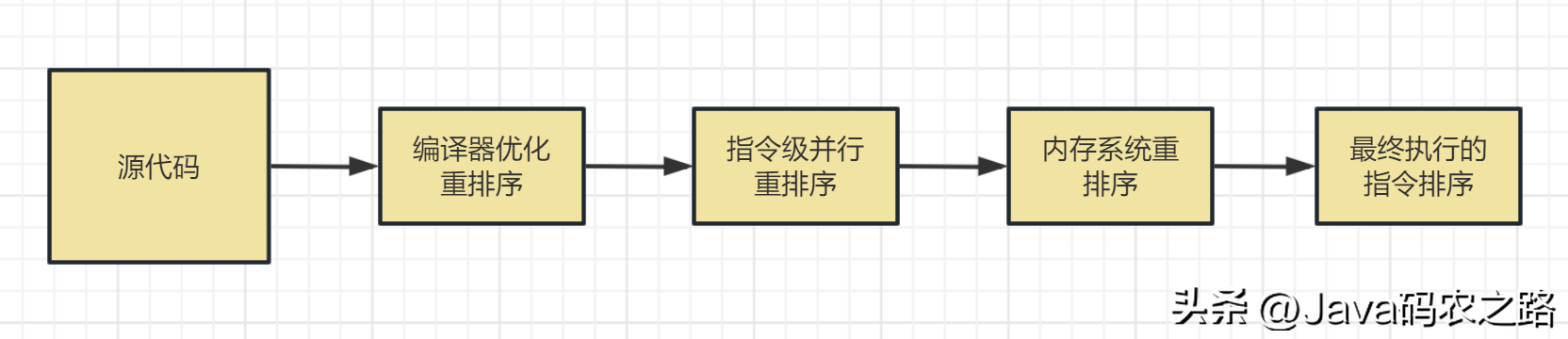 ,以双重校验锁单例模式为例子,Singleton instance=new Singleton();对应的JVM指令分为三步:分配内存空间–>初始化对象—>对象指向分配的内存空间,但是经过了编译器的指令重排序,第二步和第三步就可能会重排序。,
,以双重校验锁单例模式为例子,Singleton instance=new Singleton();对应的JVM指令分为三步:分配内存空间–>初始化对象—>对象指向分配的内存空间,但是经过了编译器的指令重排序,第二步和第三步就可能会重排序。,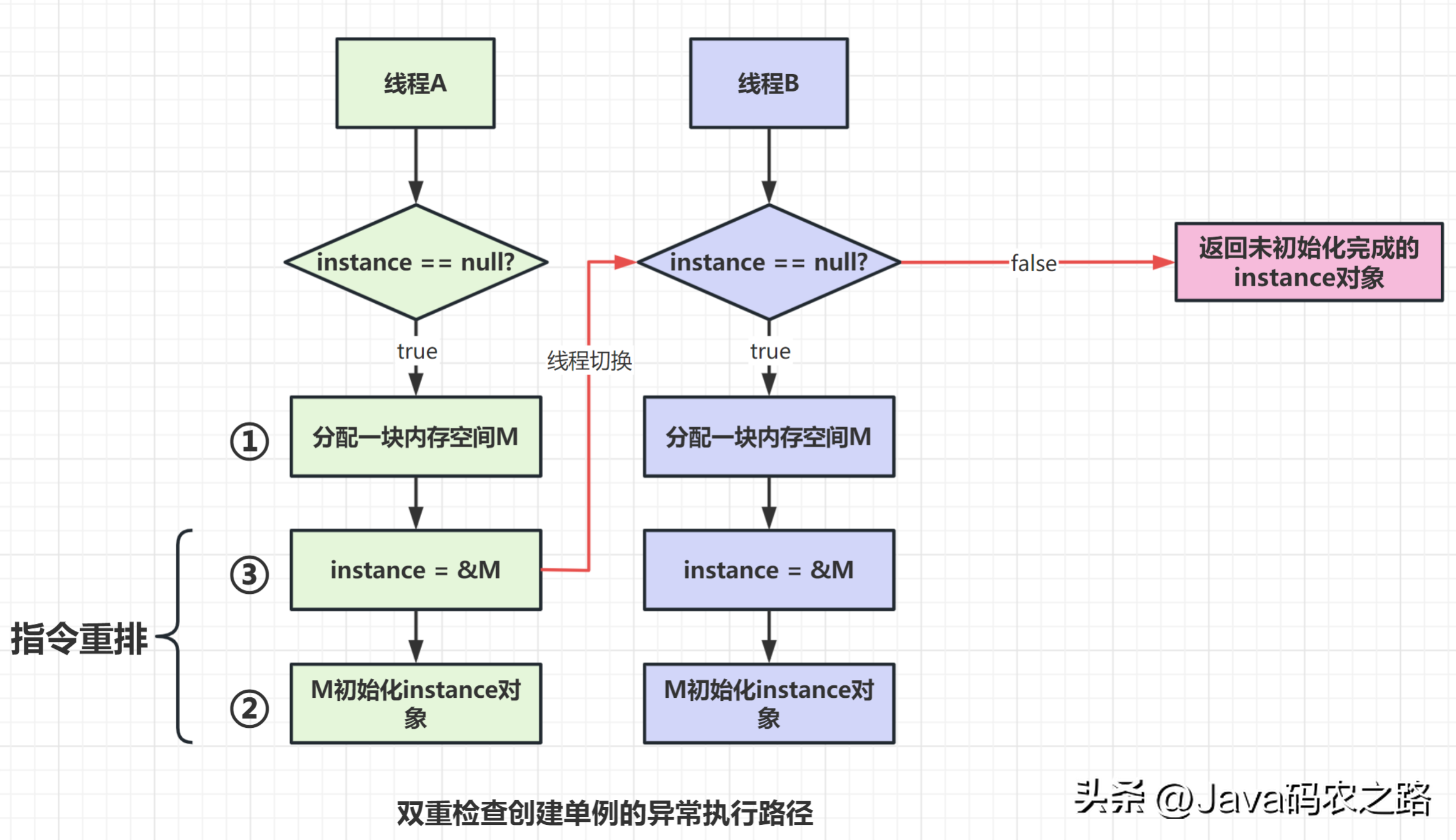 ,JMM属于语言级的内存模型,它确保在不同的编译器和不同的处理器平台之上,通过禁止特定类型的编译器重排序和指令级重排序,为程序员提供一致的内存可见性保证。,指令重排也是有一些限制的,有两个规则happens-before和as-if-serial来约束。,happens-before的定义:,happens-before的六大规则:,
,JMM属于语言级的内存模型,它确保在不同的编译器和不同的处理器平台之上,通过禁止特定类型的编译器重排序和指令级重排序,为程序员提供一致的内存可见性保证。,指令重排也是有一些限制的,有两个规则happens-before和as-if-serial来约束。,happens-before的定义:,happens-before的六大规则:,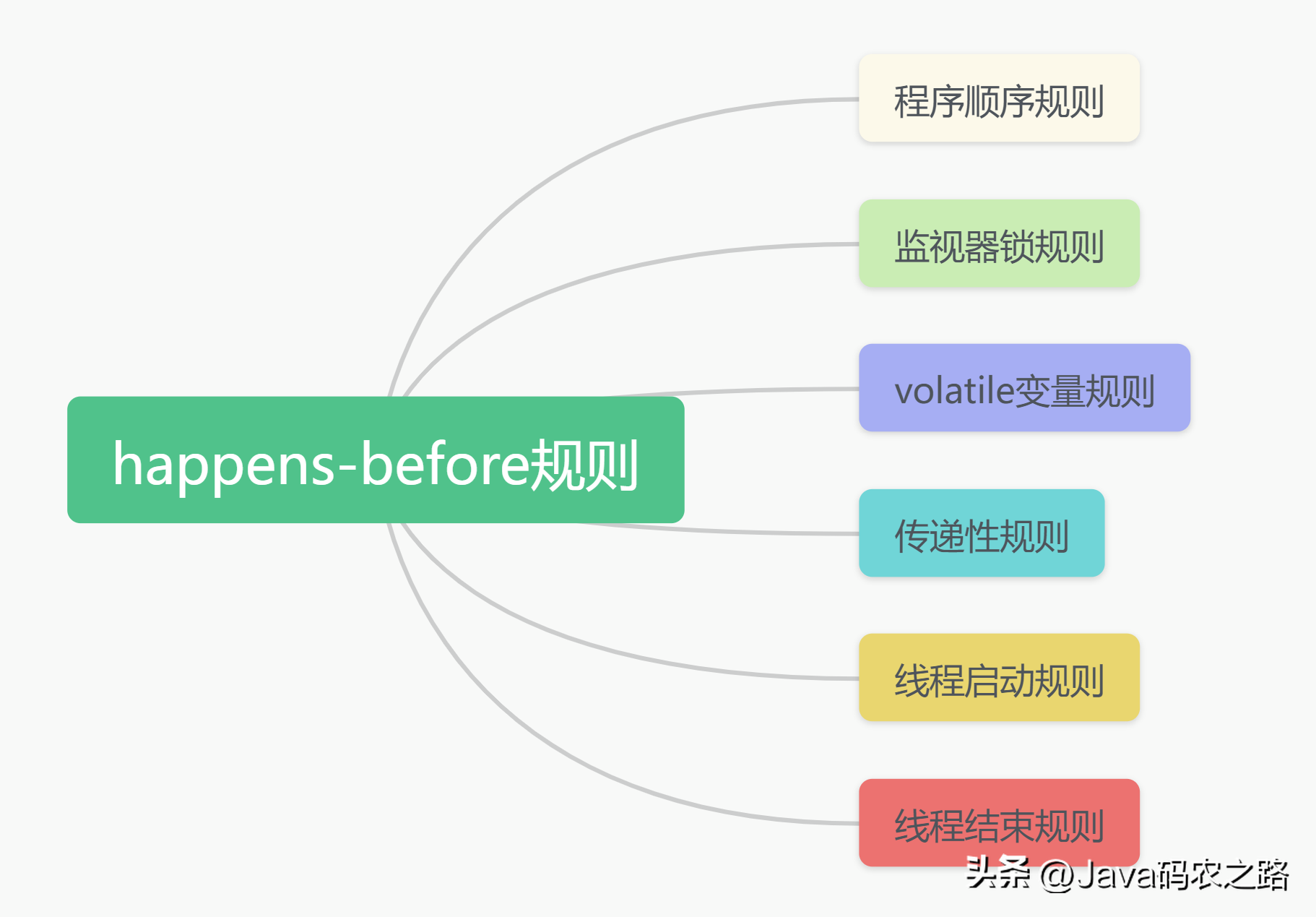 ,
, ,
, ,
,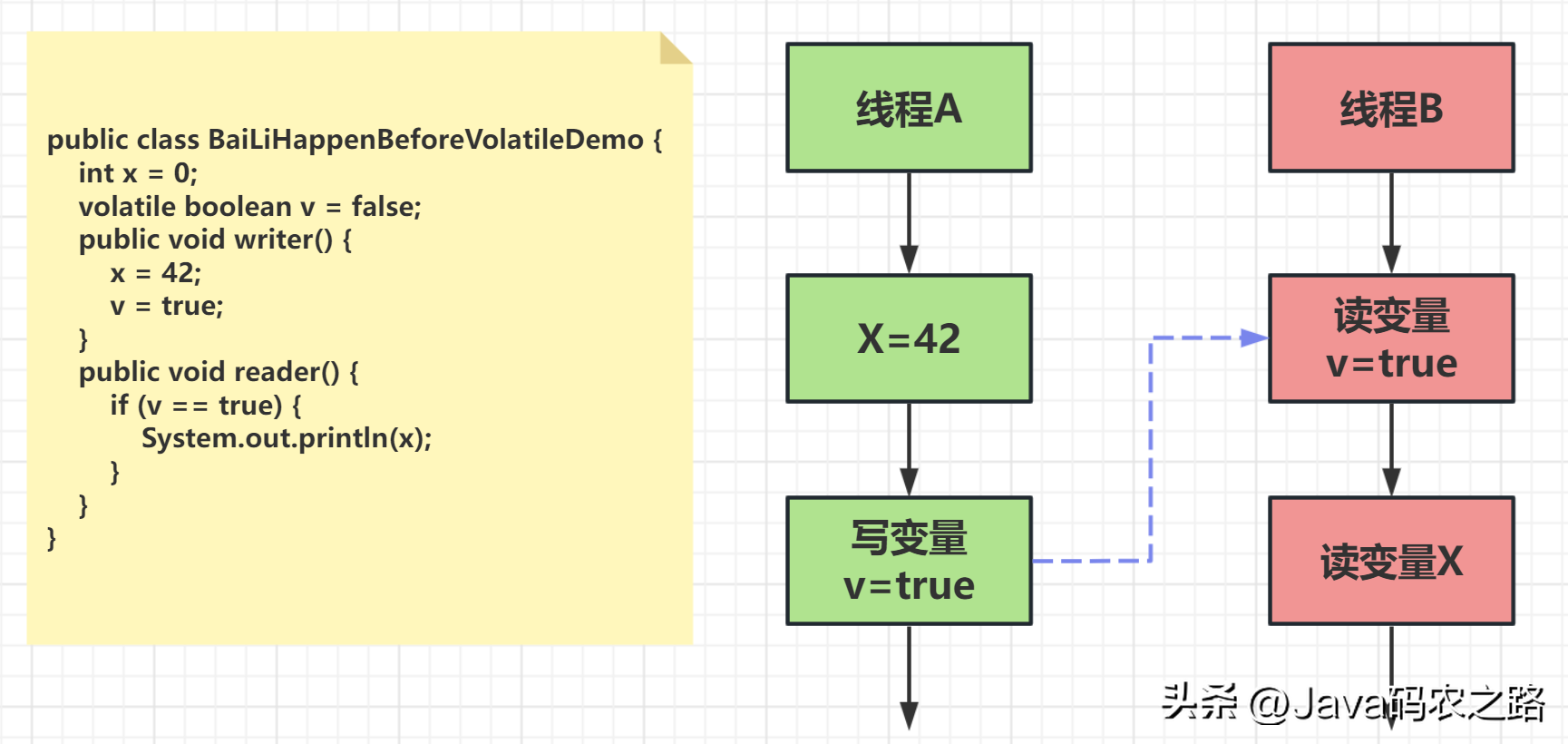 ,从图中,我们可以看到:,这意味着什么呢?如果线程 B 读到了“v=true”,那么线程A设置的“x=42”对线程B是可见的。也就是说,线程B能看到“x == 42“。,
,从图中,我们可以看到:,这意味着什么呢?如果线程 B 读到了“v=true”,那么线程A设置的“x=42”对线程B是可见的。也就是说,线程B能看到“x == 42“。, ,我们可以理解为:线程A启动线程B之后,线程B能够看到线程A在启动线程B之前的操作。,
,我们可以理解为:线程A启动线程B之后,线程B能够看到线程A在启动线程B之前的操作。, ,在Java语言里面,Happens-Before的语义本质上是一种可见性,A Happens-Before B 意味着A事件对B事件来说是可见的,并且无论A事件和B事件是否发生在同一个线程里。,as-if-serial是指无论如何重排序都不会影响单线程程序的执行结果。这个原则的核心思想是编译器和处理器等各个层面的优化,不能改变程序执行的意义。,
,在Java语言里面,Happens-Before的语义本质上是一种可见性,A Happens-Before B 意味着A事件对B事件来说是可见的,并且无论A事件和B事件是否发生在同一个线程里。,as-if-serial是指无论如何重排序都不会影响单线程程序的执行结果。这个原则的核心思想是编译器和处理器等各个层面的优化,不能改变程序执行的意义。,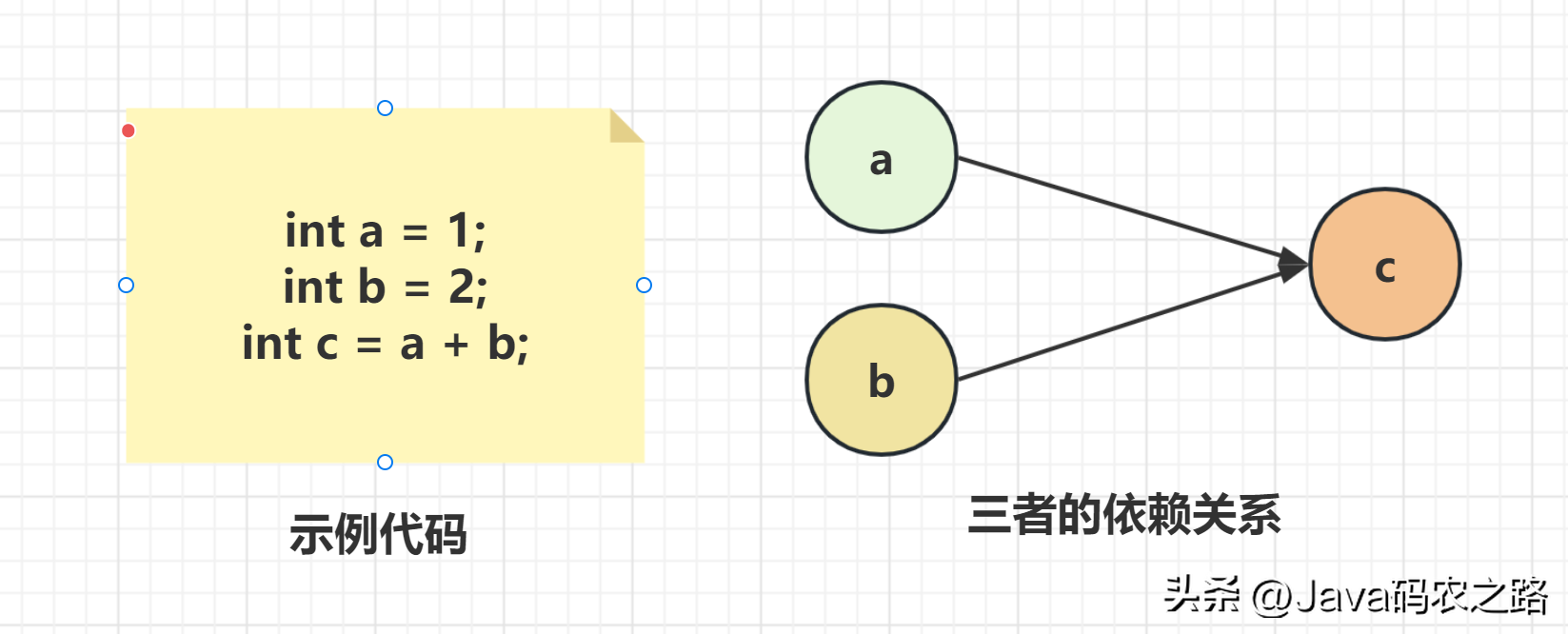 ,A和C之间存在数据依赖关系,同时B和C之间也存在数据依赖关系。因此在最终执行的指令序列中,C不能被重排序到A和B的前面(C排到A和B的前面,程序的结果将会被改变)。但A和B之间没有数据依赖关系,编译器和处理器可以重排序A和B之间的执行顺序。,所以最终,程序可能会有两种执行顺序:,
,A和C之间存在数据依赖关系,同时B和C之间也存在数据依赖关系。因此在最终执行的指令序列中,C不能被重排序到A和B的前面(C排到A和B的前面,程序的结果将会被改变)。但A和B之间没有数据依赖关系,编译器和处理器可以重排序A和B之间的执行顺序。,所以最终,程序可能会有两种执行顺序:,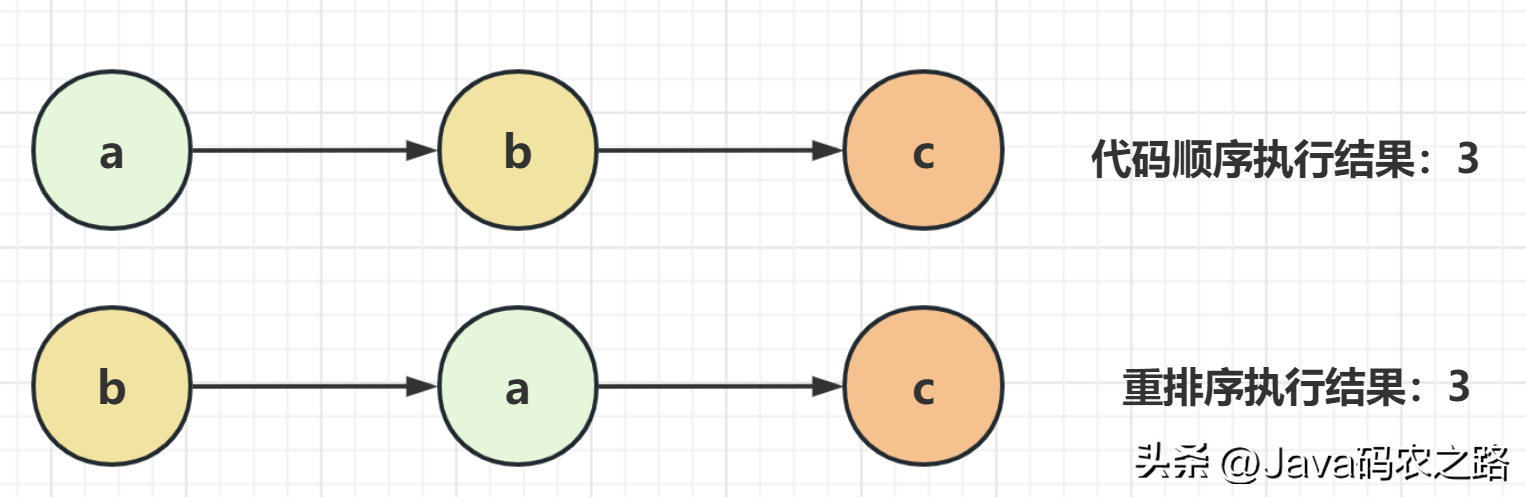 ,volatile有两个作用,保证可见性和有序性。,可见性:当一个变量被声明为 volatile 时,它会告诉编译器和CPU将该变量存储在主内存中,而不是线程的本地内存中。即每个线程读取的都是主内存中最新的值,避免了多线程并发下的数据不一致问题。,
,volatile有两个作用,保证可见性和有序性。,可见性:当一个变量被声明为 volatile 时,它会告诉编译器和CPU将该变量存储在主内存中,而不是线程的本地内存中。即每个线程读取的都是主内存中最新的值,避免了多线程并发下的数据不一致问题。,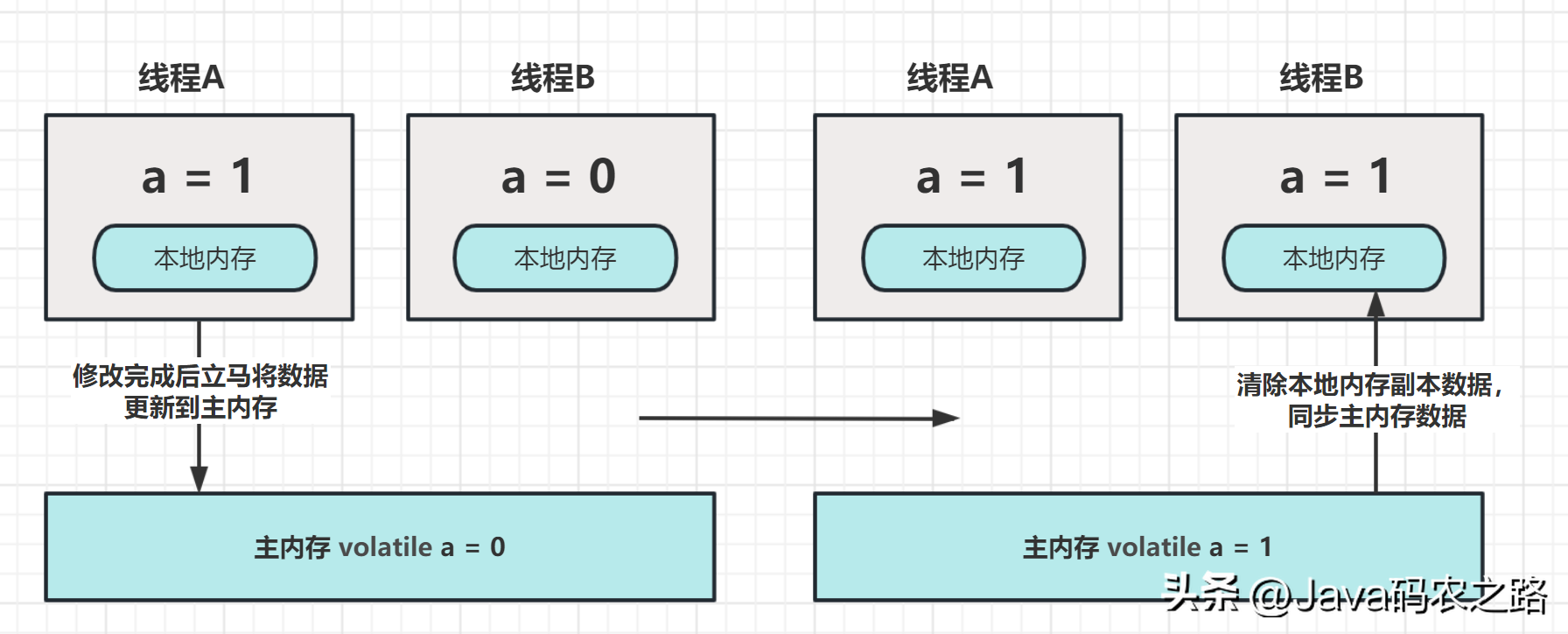 ,有序性:重排序可以分为编译器重排序和处理器重排序,valatile保证有序性,就是通过分别限制这两种类型的重排序。,
,有序性:重排序可以分为编译器重排序和处理器重排序,valatile保证有序性,就是通过分别限制这两种类型的重排序。,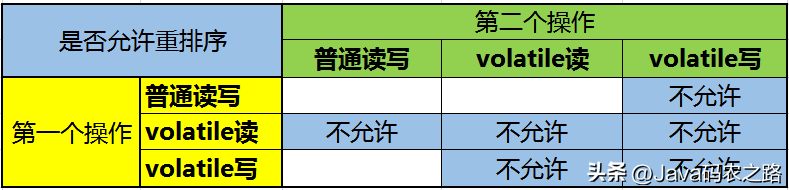 ,为了实现volatile的内存语义,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。,
,为了实现volatile的内存语义,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。,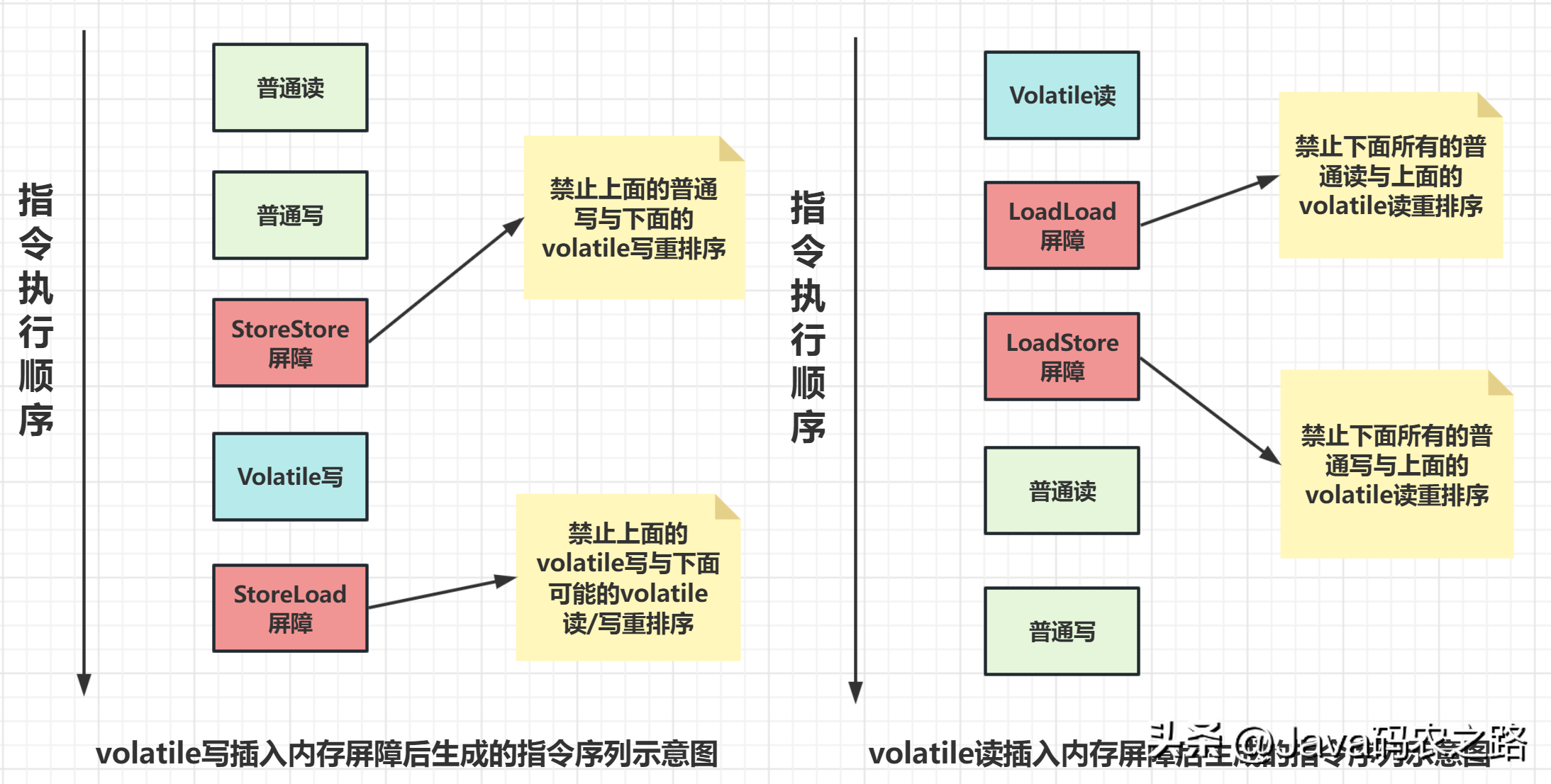 ,synchronized经常用的,用来保证代码的原子性。,synchronized主要有三种用法:,
,synchronized经常用的,用来保证代码的原子性。,synchronized主要有三种用法:, ,
, ,
, ,注意事项:,我们使用synchronized的时候,发现不用自己去lock和unlock,是因为JVM帮我们把这个事情做了。,
,注意事项:,我们使用synchronized的时候,发现不用自己去lock和unlock,是因为JVM帮我们把这个事情做了。, ,
,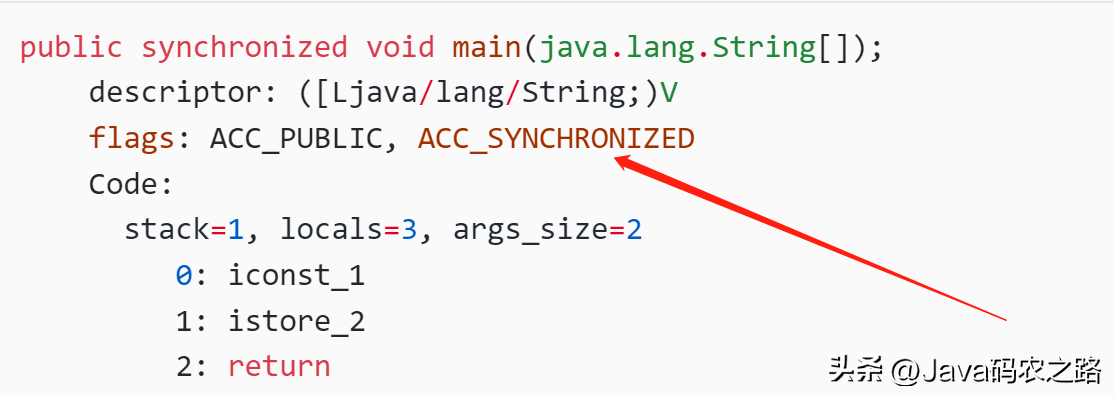 ,synchronized锁住的是什么呢?,实例对象结构里有对象头,对象头里面有一块结构叫Mark Word,Mark Word指针指向了monitor。,所谓的Monitor其实是一种同步机制,我们可以称为内部锁或者Monitor锁。,monitorenter、monitorexit或者ACC_SYNCHRONIZED都是基于Monitor实现的。,反编译class文件方法:,反编译一段synchronized修饰代码块代码,javap -c -s -v -l ***.class,可以看到相应的字节码指令。,synchronized怎么保证可见性?,synchronized怎么保证有序性?,synchronized同步的代码块,具有排他性,一次只能被一个线程拥有,所以synchronized保证同一时刻,代码是单线程执行的。,因为as-if-serial语义的存在,单线程的程序能保证最终结果是有序的,但是不保证不会指令重排。,所以synchronized保证的有序是执行结果的有序性,而不是防止指令重排的有序性。,synchronized怎么实现可重入的?,synchronized 是可重入锁,也就是说,允许一个线程二次请求自己持有对象锁的临界资源,这种情况称为可重入锁。,之所以是可重入的。是因为 synchronized 锁对象有个计数器,当一个线程请求成功后,JVM会记下持有锁的线程,并将计数器计为1。此时其他线程请求该锁,则必须等待。而该持有锁的线程如果再次请求这个锁,就可以再次拿到这个锁,同时计数器会递增。,当线程执行完毕后,计数器会递减,直到计数器为0才释放该锁。,可以从锁的实现、性能、功能特点等几个维度去回答这个问题:,下面的表格列出了两种锁之间的区别:,
,synchronized锁住的是什么呢?,实例对象结构里有对象头,对象头里面有一块结构叫Mark Word,Mark Word指针指向了monitor。,所谓的Monitor其实是一种同步机制,我们可以称为内部锁或者Monitor锁。,monitorenter、monitorexit或者ACC_SYNCHRONIZED都是基于Monitor实现的。,反编译class文件方法:,反编译一段synchronized修饰代码块代码,javap -c -s -v -l ***.class,可以看到相应的字节码指令。,synchronized怎么保证可见性?,synchronized怎么保证有序性?,synchronized同步的代码块,具有排他性,一次只能被一个线程拥有,所以synchronized保证同一时刻,代码是单线程执行的。,因为as-if-serial语义的存在,单线程的程序能保证最终结果是有序的,但是不保证不会指令重排。,所以synchronized保证的有序是执行结果的有序性,而不是防止指令重排的有序性。,synchronized怎么实现可重入的?,synchronized 是可重入锁,也就是说,允许一个线程二次请求自己持有对象锁的临界资源,这种情况称为可重入锁。,之所以是可重入的。是因为 synchronized 锁对象有个计数器,当一个线程请求成功后,JVM会记下持有锁的线程,并将计数器计为1。此时其他线程请求该锁,则必须等待。而该持有锁的线程如果再次请求这个锁,就可以再次拿到这个锁,同时计数器会递增。,当线程执行完毕后,计数器会递减,直到计数器为0才释放该锁。,可以从锁的实现、性能、功能特点等几个维度去回答这个问题:,下面的表格列出了两种锁之间的区别:,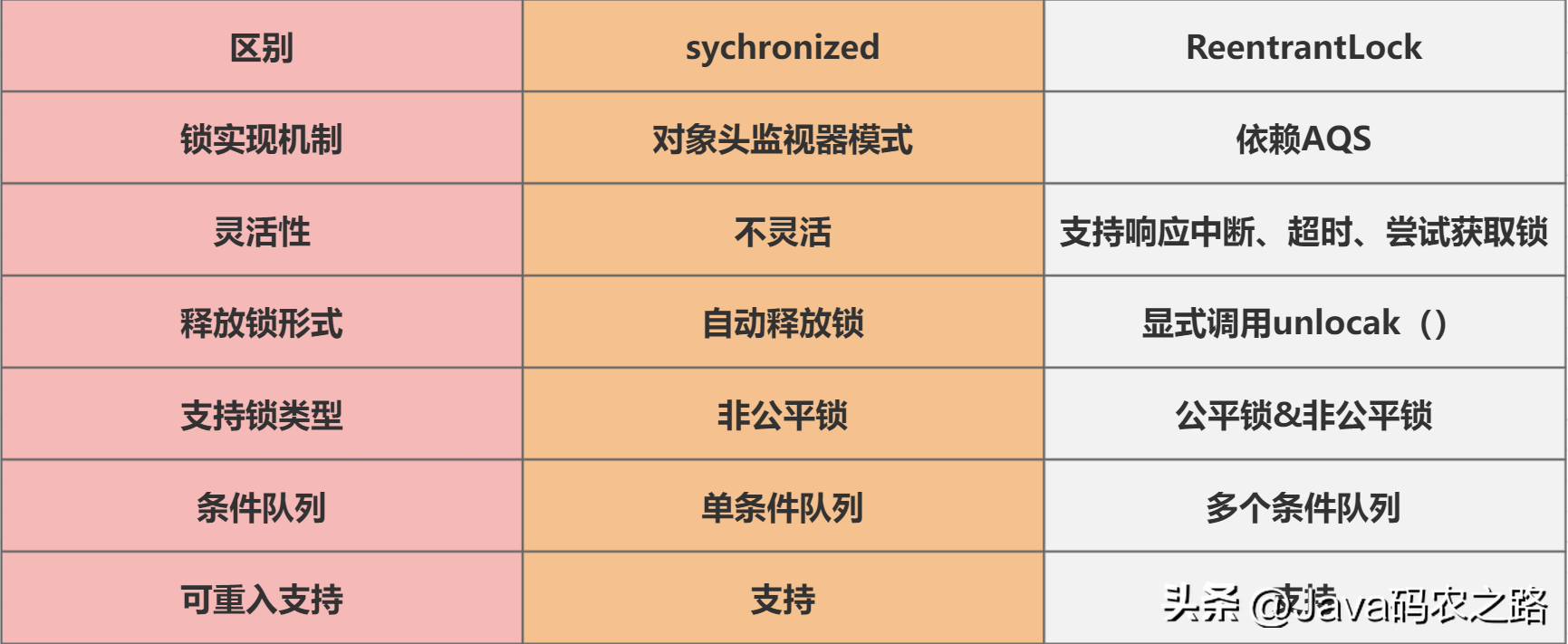 ,ReentrantLock是一种可重入的排它锁,主要用来解决多线程对共享资源竞争的问题;它提供了比synchronized关键字更加灵活的锁机制。其实现原理主要涉及以下三个方面:,ReentrantLock内部维护了一个Sync对象(AbstractQueuedSynchronizer类的子类),Sync持有锁、等待队列等状态信息,实际上 ReentrantLock的大部分功能都是由Sync来实现的。,当一个线程调用ReentrantLock的lock()方法时,会先尝试CAS操作获取锁,如果成功则返回;否则,线程会被放入等待队列中,等待唤醒重新尝试获取锁。,如果一个线程已经持有了锁,那么它可以重入这个锁,即继续获取该锁而不会被阻塞。ReentrantLock通过维护一个计数器来实现重入锁功能,每次重入计数器加1,每次释放锁计数器减1,当计数器为0时,锁被释放。,当一个线程调用ReentrantLock的unlock()方法时,会将计数器减1,如果计数器变为了0,则锁被完全释放。如果计数器还大于0,则表示有其他线程正在等待该锁,此时会唤醒等待队列中的一个线程来获取锁。,总结:,ReentrantLock的实现原理主要是基于CAS操作和等待队列来实现。它通过Sync对象来维护锁的状态,支持重入锁和公平锁等特性,提供了比synchronized更加灵活的锁机制,是Java并发编程中常用的同步工具之一。,ReentrantLock可以通过构造函数的参数来控制锁的公平性,如果传入 true,就表示该锁是公平的;如果传入 false,就表示该锁是不公平的。,new ReentrantLock()构造函数默认创建的是非公平锁 NonfairSync,
,ReentrantLock是一种可重入的排它锁,主要用来解决多线程对共享资源竞争的问题;它提供了比synchronized关键字更加灵活的锁机制。其实现原理主要涉及以下三个方面:,ReentrantLock内部维护了一个Sync对象(AbstractQueuedSynchronizer类的子类),Sync持有锁、等待队列等状态信息,实际上 ReentrantLock的大部分功能都是由Sync来实现的。,当一个线程调用ReentrantLock的lock()方法时,会先尝试CAS操作获取锁,如果成功则返回;否则,线程会被放入等待队列中,等待唤醒重新尝试获取锁。,如果一个线程已经持有了锁,那么它可以重入这个锁,即继续获取该锁而不会被阻塞。ReentrantLock通过维护一个计数器来实现重入锁功能,每次重入计数器加1,每次释放锁计数器减1,当计数器为0时,锁被释放。,当一个线程调用ReentrantLock的unlock()方法时,会将计数器减1,如果计数器变为了0,则锁被完全释放。如果计数器还大于0,则表示有其他线程正在等待该锁,此时会唤醒等待队列中的一个线程来获取锁。,总结:,ReentrantLock的实现原理主要是基于CAS操作和等待队列来实现。它通过Sync对象来维护锁的状态,支持重入锁和公平锁等特性,提供了比synchronized更加灵活的锁机制,是Java并发编程中常用的同步工具之一。,ReentrantLock可以通过构造函数的参数来控制锁的公平性,如果传入 true,就表示该锁是公平的;如果传入 false,就表示该锁是不公平的。,new ReentrantLock()构造函数默认创建的是非公平锁 NonfairSync,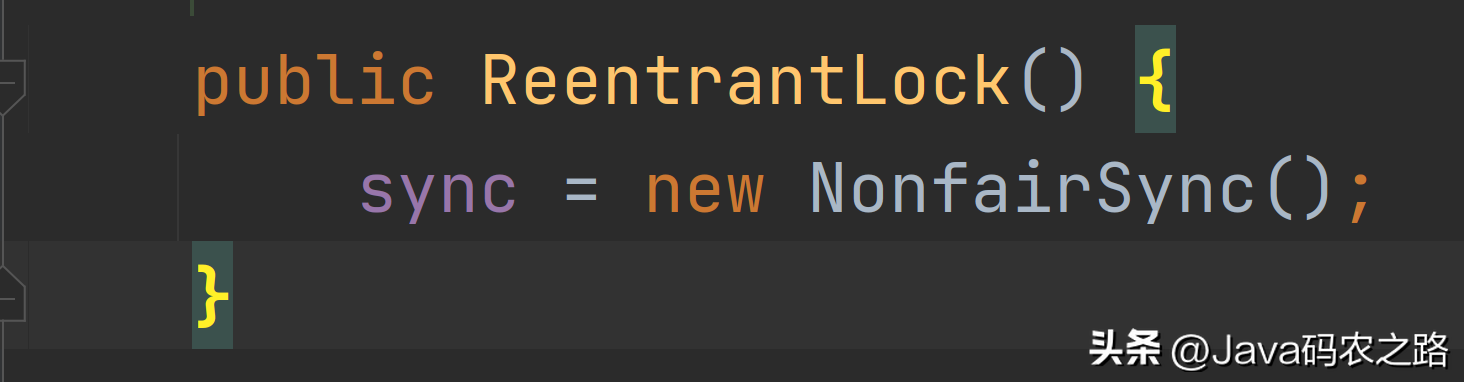 ,同时也可以在创建锁构造函数中传入具体参数创建公平锁 FairSync,
,同时也可以在创建锁构造函数中传入具体参数创建公平锁 FairSync, ,FairSync、NonfairSync 代表公平锁和非公平锁,两者都是 ReentrantLock 静态内部类,只不过实现不同锁语义。,非公平锁和公平锁的区别:,
,FairSync、NonfairSync 代表公平锁和非公平锁,两者都是 ReentrantLock 静态内部类,只不过实现不同锁语义。,非公平锁和公平锁的区别:,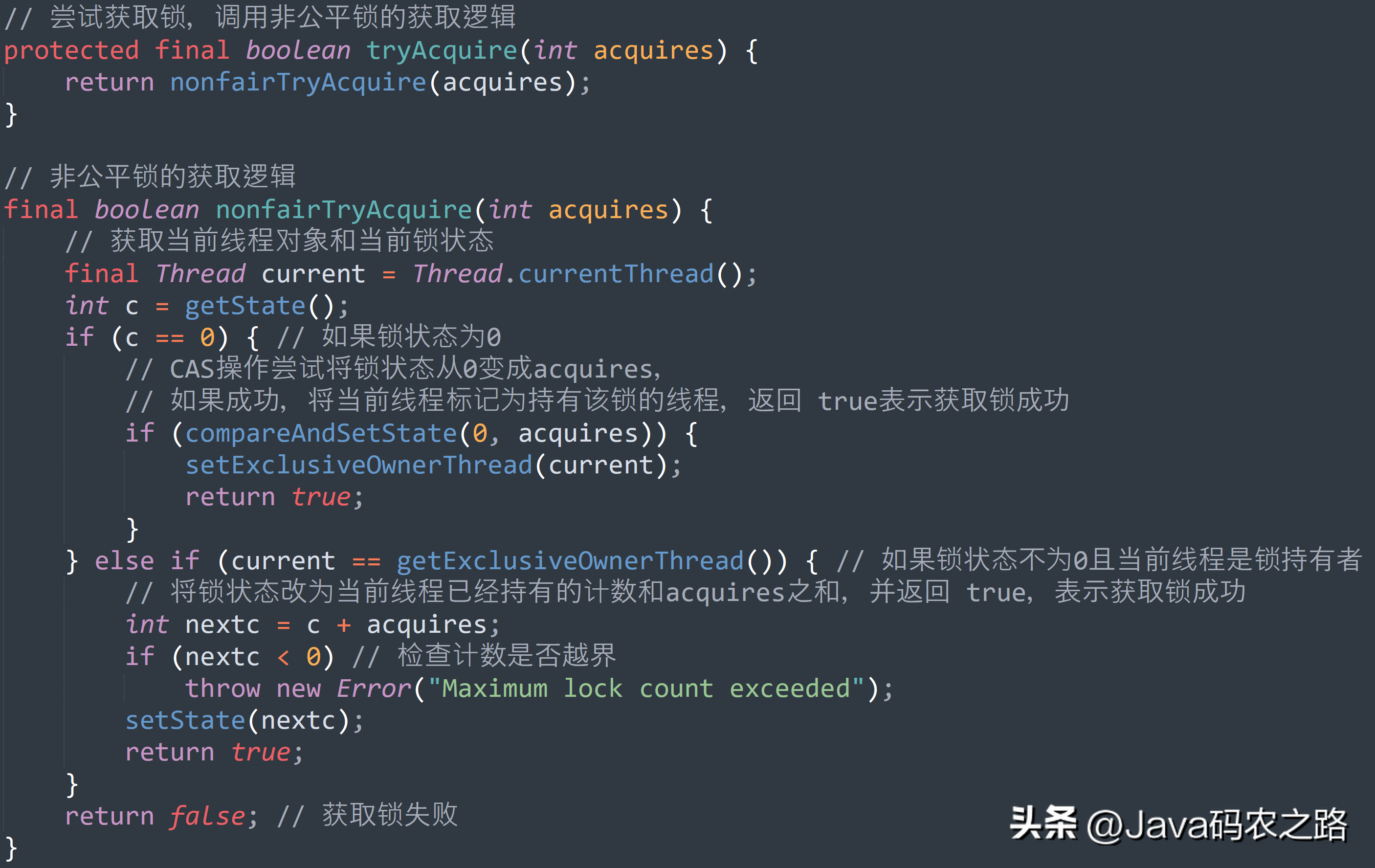 ,CAS叫做CompareAndSwap,比较并交换,主要是通过处理器的指令来保证操作的原子性的。,CAS 操作包含三个参数:共享变量的内存地址(V)、预期原值(A)和新值(B),当且仅当内存地址 V 的值等于 A 时,才将 V 的值修改为 B;否则,不会执行任何操作。,在多线程场景下,使用 CAS 操作可以确保多个线程同时修改某个变量时,只有一个线程能够成功修改。其他线程需要重试或者等待。这样就避免了传统锁机制中的锁竞争和死锁等问题,提高了系统的并发性能。,CAS的经典三大问题:,
,CAS叫做CompareAndSwap,比较并交换,主要是通过处理器的指令来保证操作的原子性的。,CAS 操作包含三个参数:共享变量的内存地址(V)、预期原值(A)和新值(B),当且仅当内存地址 V 的值等于 A 时,才将 V 的值修改为 B;否则,不会执行任何操作。,在多线程场景下,使用 CAS 操作可以确保多个线程同时修改某个变量时,只有一个线程能够成功修改。其他线程需要重试或者等待。这样就避免了传统锁机制中的锁竞争和死锁等问题,提高了系统的并发性能。,CAS的经典三大问题:, ,ABA问题,ABA 问题是指一个变量从A变成B,再从B变成A,这样的操作序列可能会被CAS操作误判为未被其他线程修改过。例如线程A读取了某个变量的值为 A,然后被挂起,线程B修改了这个变量的值为B,然后又修改回了A,此时线程A恢复执行,进行CAS操作,此时仍然可以成功,因为此时变量的值还是A。,怎么解决ABA问题?,每次修改变量,都在这个变量的版本号上加1,这样,刚刚A->B->A,虽然A的值没变,但是它的版本号已经变了,再判断版本号就会发现此时的A已经被改过了。,比如使用JDK5中的AtomicStampedReference类或JDK8中的LongAdder类。这些原子类型不仅包含数据本身,还包含一个版本号,每次进行操作时都会更新版本号,只有当版本号和期望值都相等时才能执行更新,这样可以避免 ABA 问题的影响。,循环性能开销,自旋CAS,如果一直循环执行,一直不成功,会给CPU带来非常大的执行开销。,怎么解决循环性能开销问题?,可以使用自适应自旋锁,即在多次操作失败后逐渐加长自旋时间或者放弃自旋锁转为阻塞锁;,只能保证一个变量的原子操作,CAS 保证的是对一个变量执行操作的原子性,如果需要对多个变量进行复合操作,CAS 操作就无法保证整个操作的原子性。,怎么解决只能保证一个变量的原子操作问题?,
,ABA问题,ABA 问题是指一个变量从A变成B,再从B变成A,这样的操作序列可能会被CAS操作误判为未被其他线程修改过。例如线程A读取了某个变量的值为 A,然后被挂起,线程B修改了这个变量的值为B,然后又修改回了A,此时线程A恢复执行,进行CAS操作,此时仍然可以成功,因为此时变量的值还是A。,怎么解决ABA问题?,每次修改变量,都在这个变量的版本号上加1,这样,刚刚A->B->A,虽然A的值没变,但是它的版本号已经变了,再判断版本号就会发现此时的A已经被改过了。,比如使用JDK5中的AtomicStampedReference类或JDK8中的LongAdder类。这些原子类型不仅包含数据本身,还包含一个版本号,每次进行操作时都会更新版本号,只有当版本号和期望值都相等时才能执行更新,这样可以避免 ABA 问题的影响。,循环性能开销,自旋CAS,如果一直循环执行,一直不成功,会给CPU带来非常大的执行开销。,怎么解决循环性能开销问题?,可以使用自适应自旋锁,即在多次操作失败后逐渐加长自旋时间或者放弃自旋锁转为阻塞锁;,只能保证一个变量的原子操作,CAS 保证的是对一个变量执行操作的原子性,如果需要对多个变量进行复合操作,CAS 操作就无法保证整个操作的原子性。,怎么解决只能保证一个变量的原子操作问题?, ,
,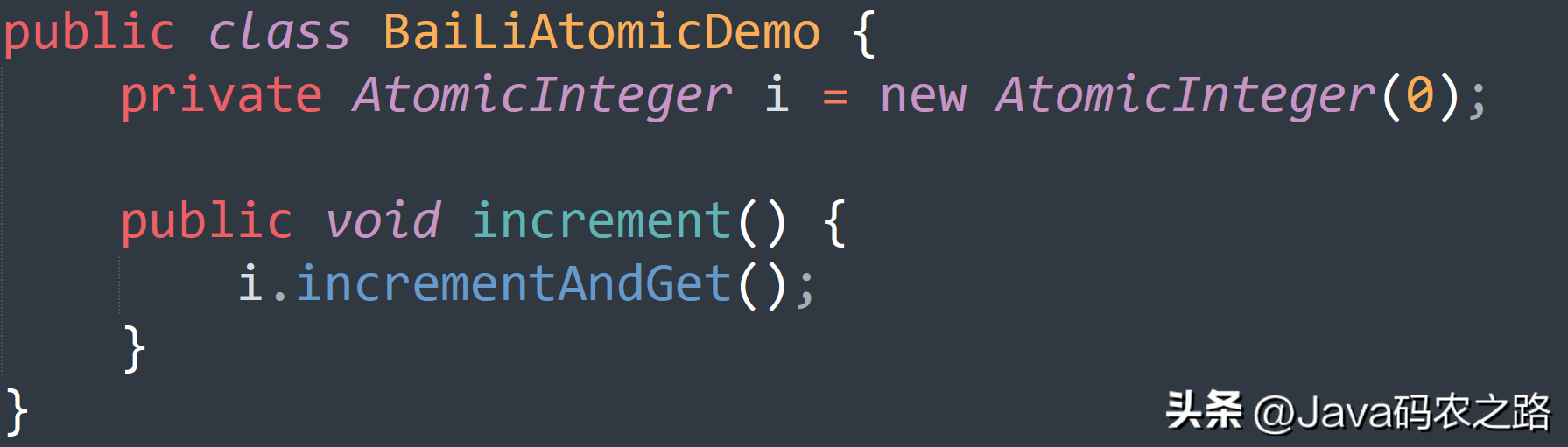 ,这里使用 AtomicInteger 类来保证 i++ 操作的原子性。,
,这里使用 AtomicInteger 类来保证 i++ 操作的原子性。,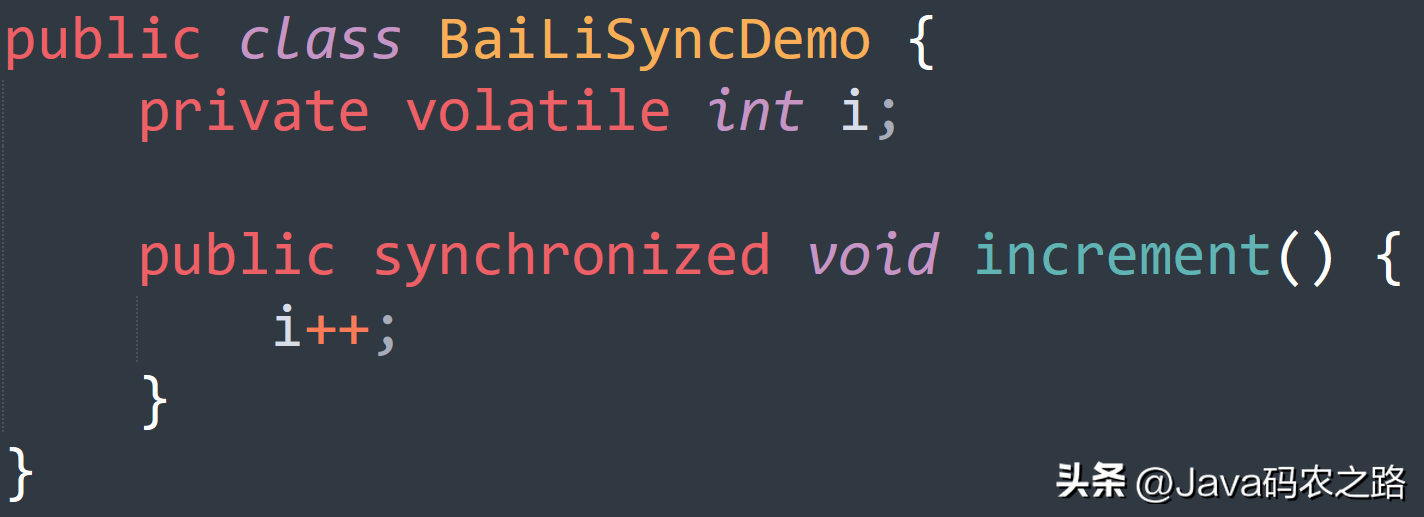 ,这里使用 synchronized 方法来保证 increment() 方法的原子性,从而保证 i++ 操作的结果正确。,
,这里使用 synchronized 方法来保证 increment() 方法的原子性,从而保证 i++ 操作的结果正确。, ,这里使用 ReentrantLock 类的 lock() 和 unlock() 方法来保护 i++操作的原子性。,一句话概括:使用CAS实现。,在AtomicInteger中,CAS操作的流程如下:,
,这里使用 ReentrantLock 类的 lock() 和 unlock() 方法来保护 i++操作的原子性。,一句话概括:使用CAS实现。,在AtomicInteger中,CAS操作的流程如下:,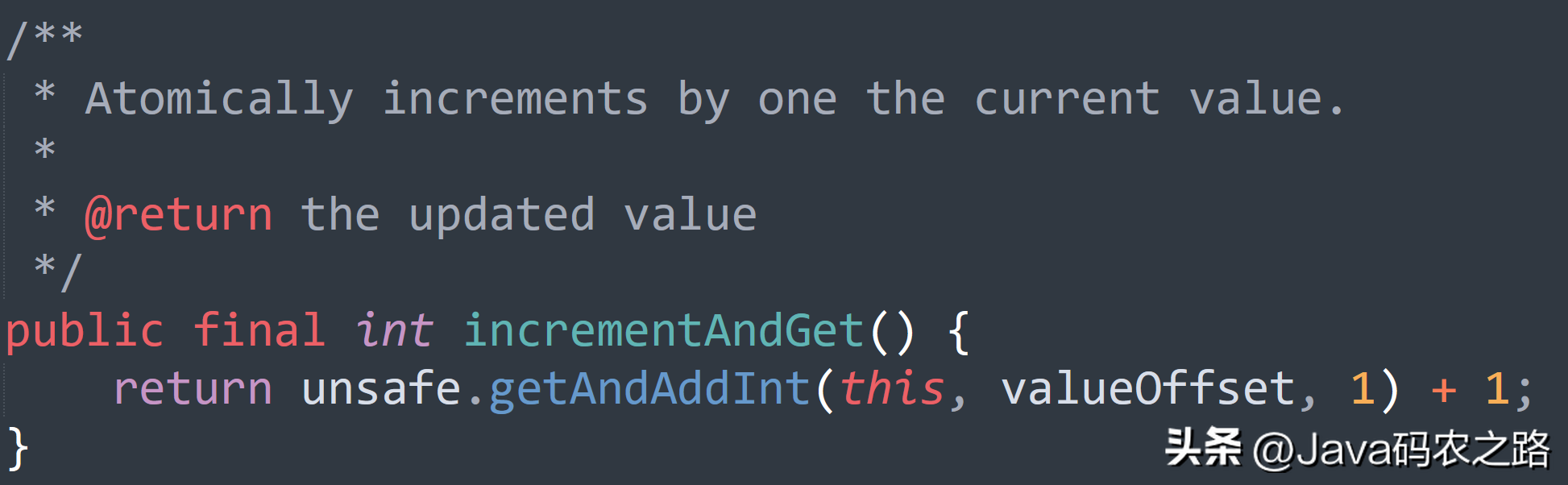 ,
,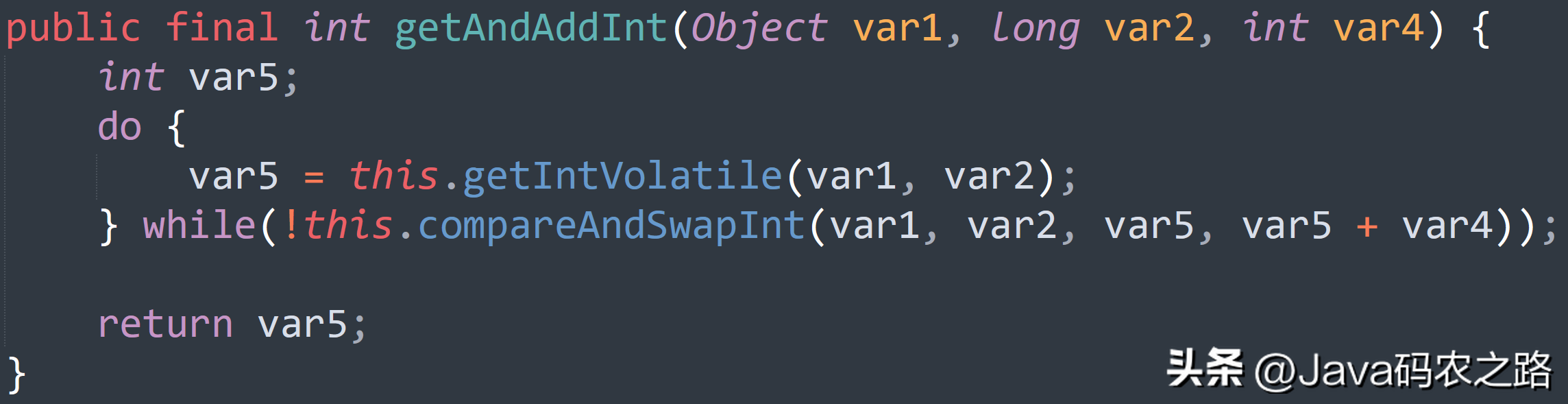 ,总结:,在 CAS 操作中,由于只有一个线程可以成功修改共享变量的值,因此可以保证操作的原子性,即多线程同时修改AtomicInteger变量时也不会出现竞态条件。这样就可以在多线程环境下安全地对AtomicInteger进行整型变量操作。其它的原子操作类基本都是大同小异。,死锁是指两个或两个以上的线程在执行过程中,因争夺资源而造成的互相等待的现象,在无外力作用的情况下,这些线程会一直相互等待而无法继续运行下去。,
,总结:,在 CAS 操作中,由于只有一个线程可以成功修改共享变量的值,因此可以保证操作的原子性,即多线程同时修改AtomicInteger变量时也不会出现竞态条件。这样就可以在多线程环境下安全地对AtomicInteger进行整型变量操作。其它的原子操作类基本都是大同小异。,死锁是指两个或两个以上的线程在执行过程中,因争夺资源而造成的互相等待的现象,在无外力作用的情况下,这些线程会一直相互等待而无法继续运行下去。,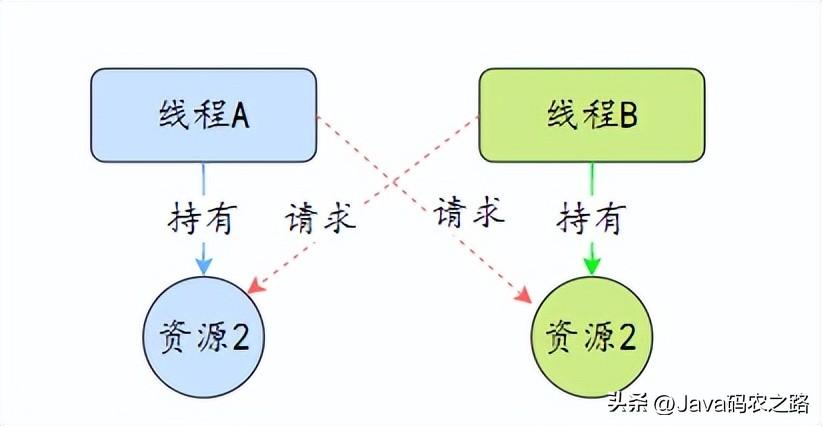 ,那么为什么会产生死锁呢?死锁的产生必须具备以下四个条件:,
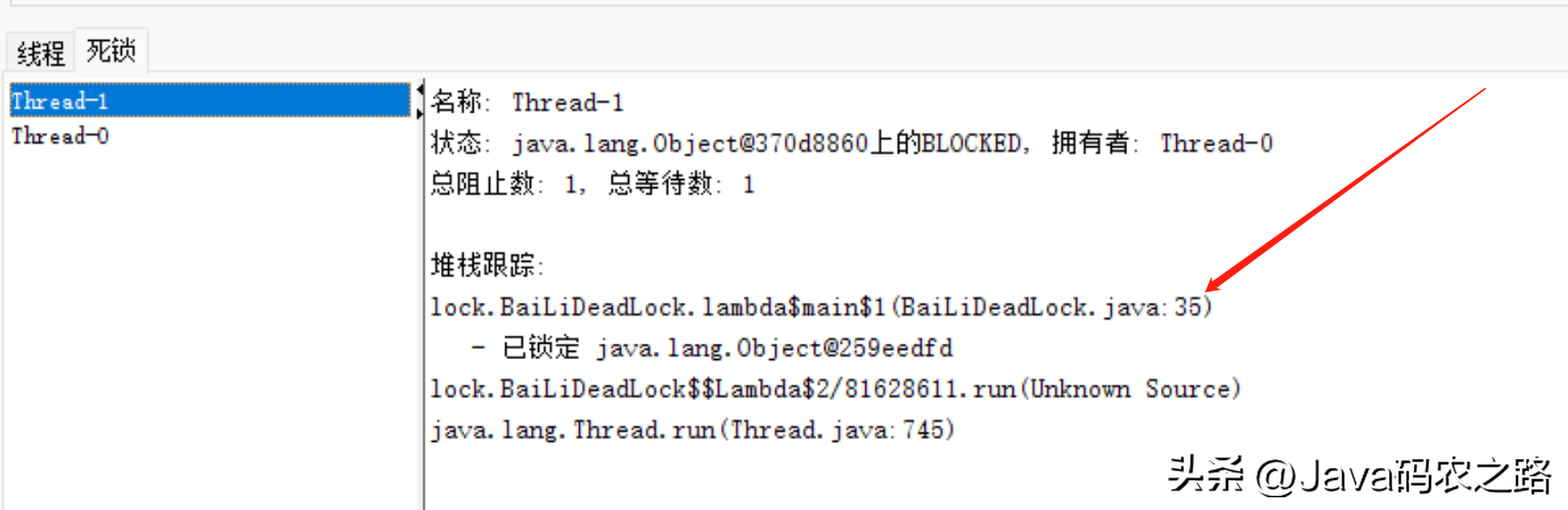
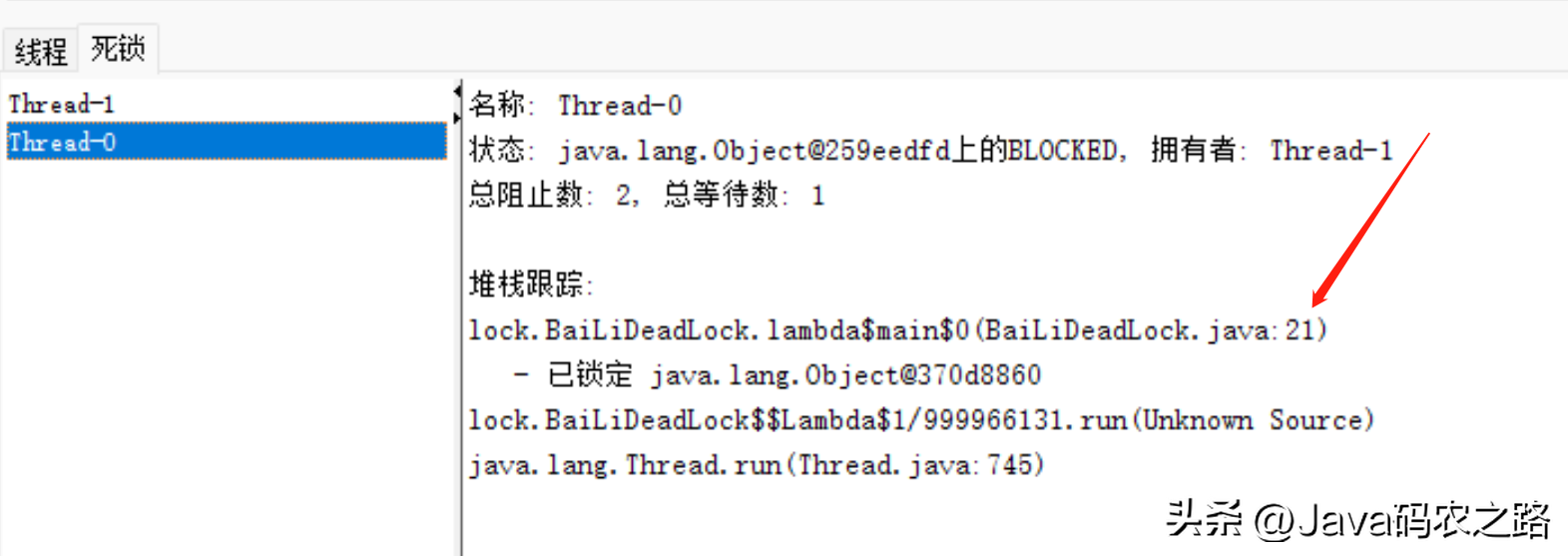
,那么为什么会产生死锁呢?死锁的产生必须具备以下四个条件:,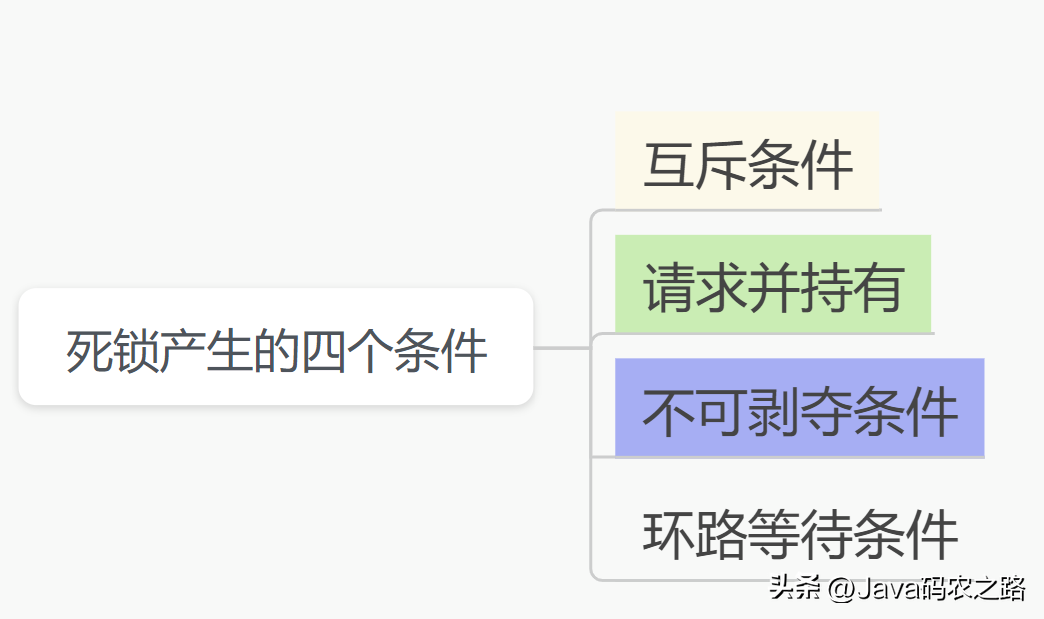 ,该如何避免死锁呢?答案是至少破坏死锁发生的一个条件。,可以使用jdk自带的命令行工具排查:,基本就可以看到死锁的信息。,还可以利用图形化工具,比如JConsole(JConsole工具在JDK的bin目录中)。出现线程死锁以后,点击JConsole线程面板的检测到死锁按钮,将会看到线程的死锁信息。,演示样例如下:,1.新建连接,找到相应的线程,点击连接,2.选择线程标签,点击检测死锁。查看死锁线程信息,
,该如何避免死锁呢?答案是至少破坏死锁发生的一个条件。,可以使用jdk自带的命令行工具排查:,基本就可以看到死锁的信息。,还可以利用图形化工具,比如JConsole(JConsole工具在JDK的bin目录中)。出现线程死锁以后,点击JConsole线程面板的检测到死锁按钮,将会看到线程的死锁信息。,演示样例如下:,1.新建连接,找到相应的线程,点击连接,2.选择线程标签,点击检测死锁。查看死锁线程信息,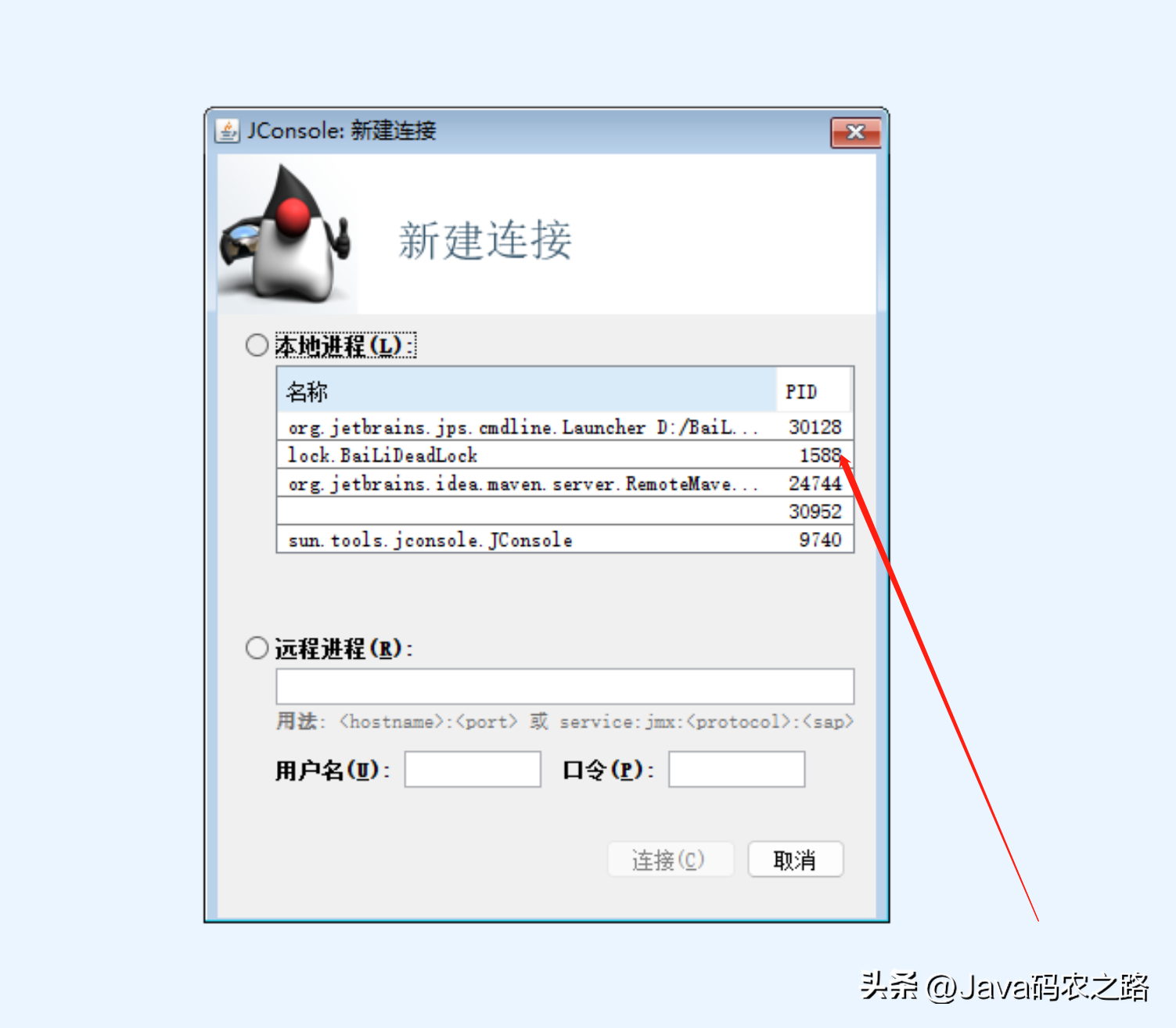 ,
,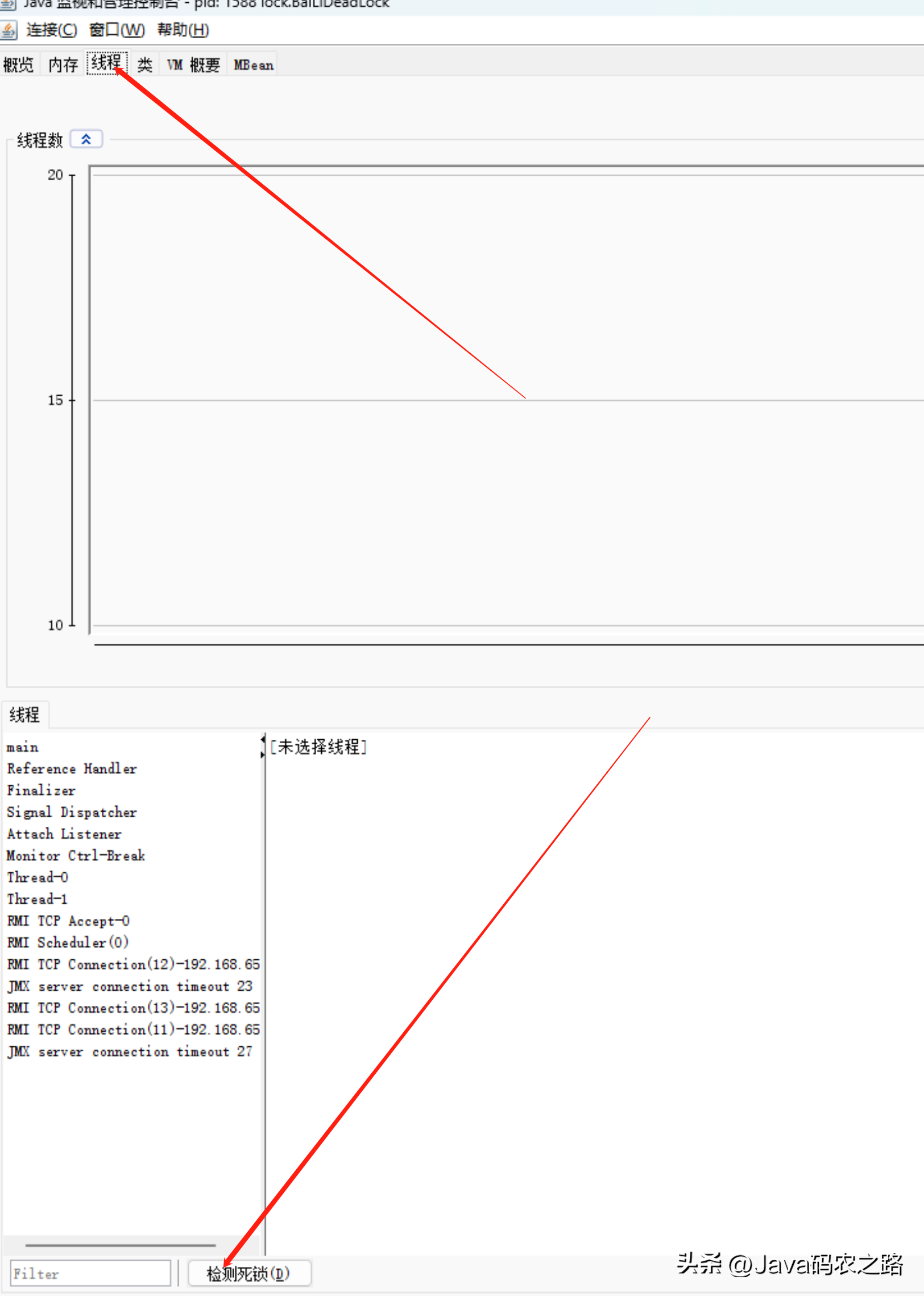 ,
, ,
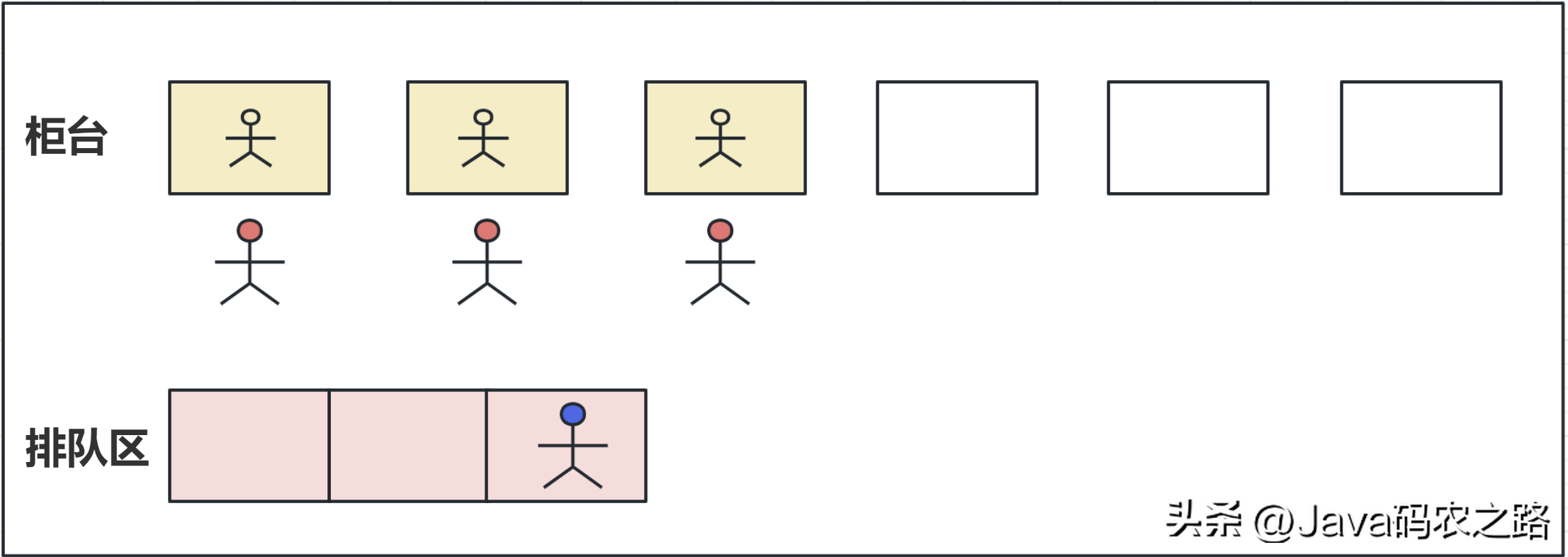
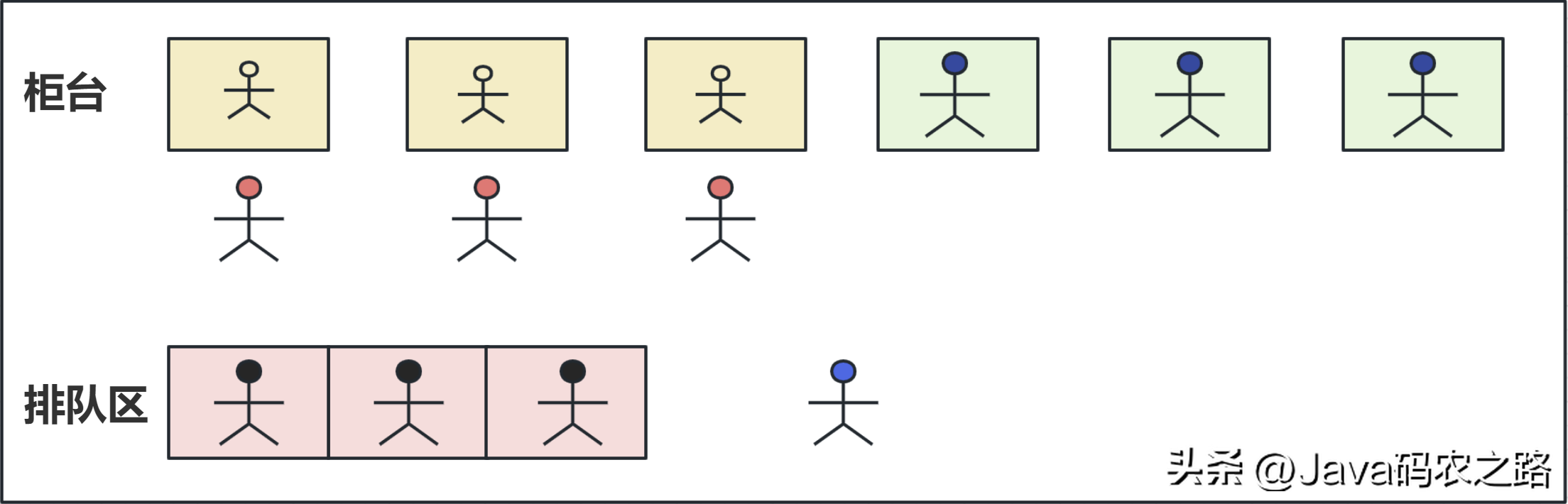
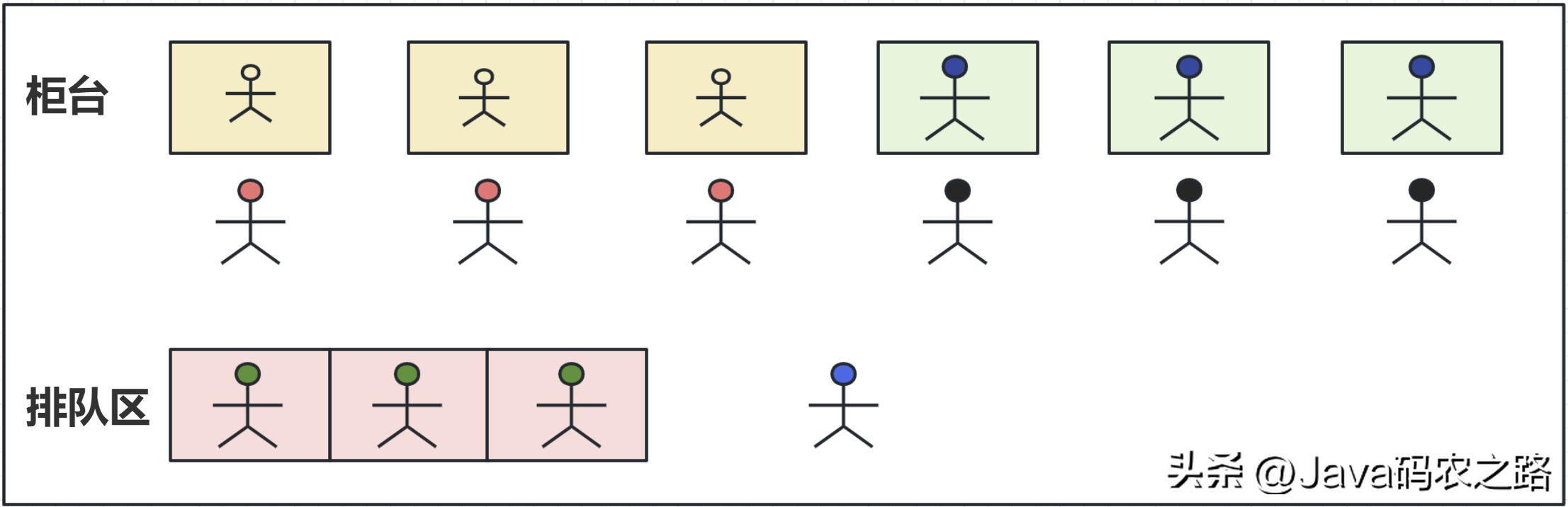
, ,线程池是一种用于管理和复用线程的机制,它提供了一种执行大量异步任务的方式,并且可以在多个任务之间合理地分配和管理系统资源。,线程池的主要优点包括:,用一个通俗的比喻:,有一个银行营业厅,总共有六个窗口,现在有三个窗口坐着三个营业员小姐姐在营业。小天去办业务,可能会遇到什么情况呢?,
,线程池是一种用于管理和复用线程的机制,它提供了一种执行大量异步任务的方式,并且可以在多个任务之间合理地分配和管理系统资源。,线程池的主要优点包括:,用一个通俗的比喻:,有一个银行营业厅,总共有六个窗口,现在有三个窗口坐着三个营业员小姐姐在营业。小天去办业务,可能会遇到什么情况呢?, ,
, ,
, ,
, ,上面的这个流程几乎就跟JDK线程池的大致流程类似。,所以我们线程池的工作流程也比较好理解了:,
,上面的这个流程几乎就跟JDK线程池的大致流程类似。,所以我们线程池的工作流程也比较好理解了:,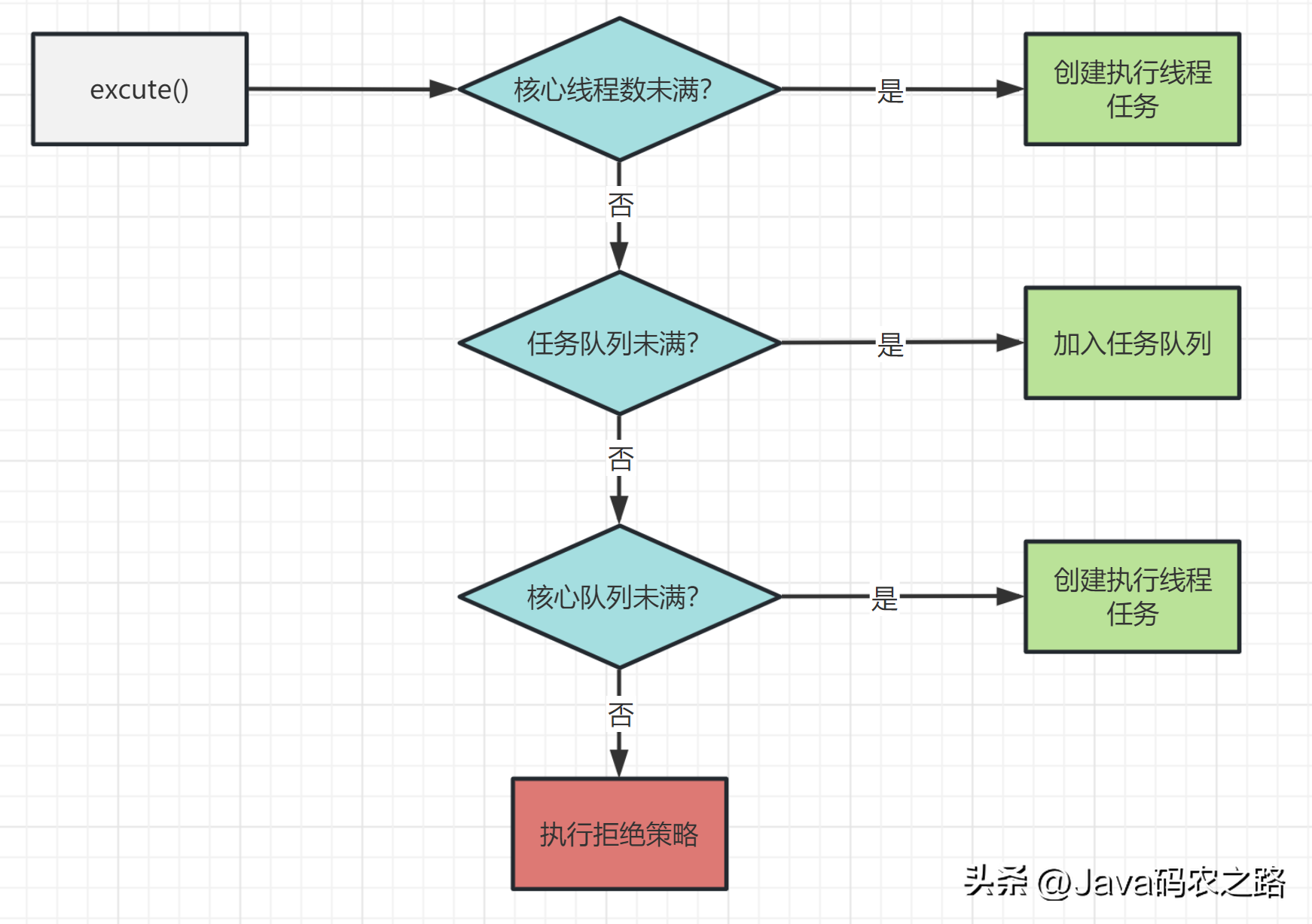 ,
,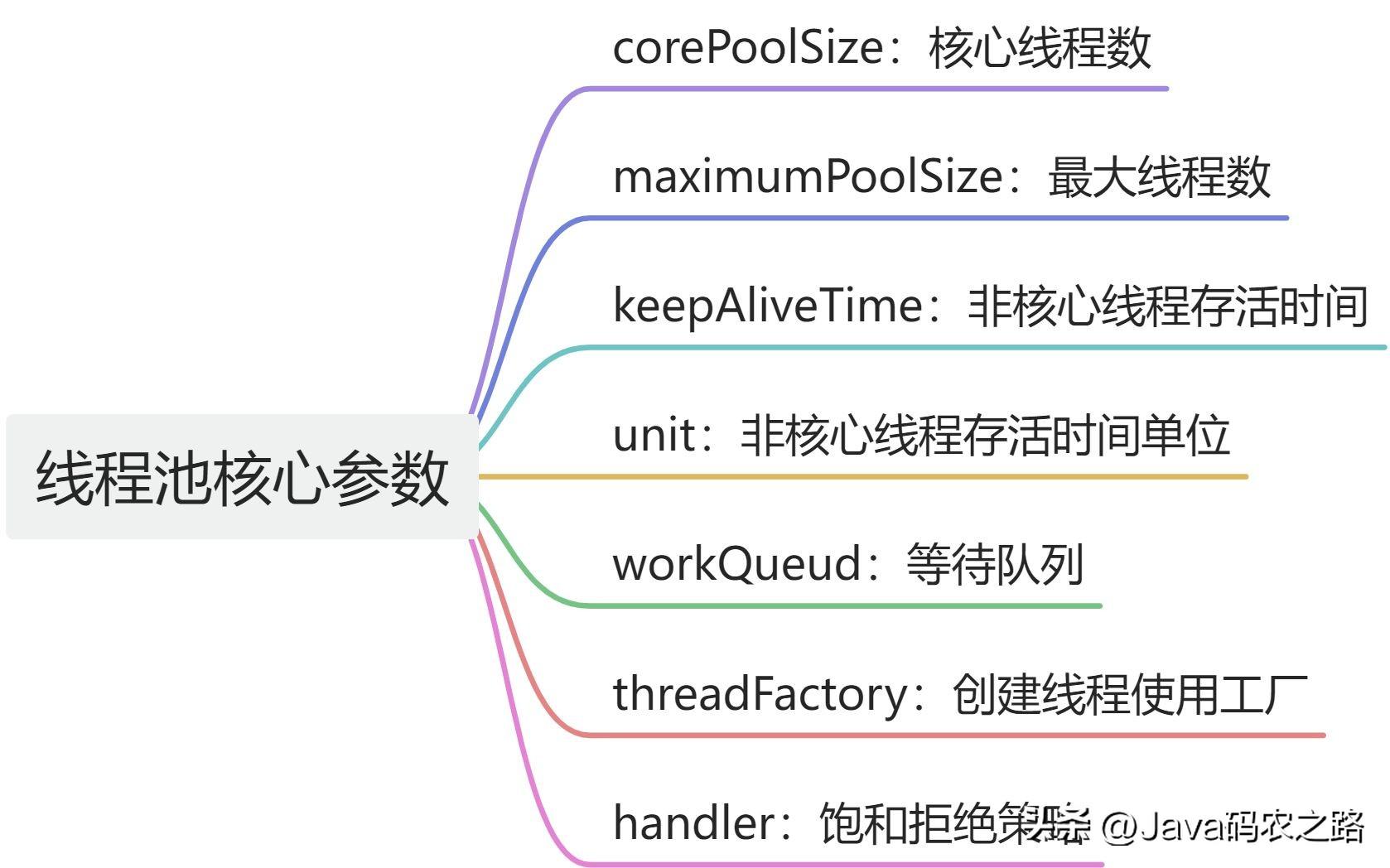 ,线程池有七大参数,我们重点关注corePoolSize、maximumPoolSize、workQueue、handler 可以帮助我们更好地理解和优化线程池的性能,此值是用来初始化线程池中核心线程数,当线程池中线程数< corePoolSize时,系统默认是添加一个任务才创建一个线程池。当线程数 = corePoolSize时,新任务会追加到workQueue中。,maximumPoolSize表示允许的最大线程数 = (非核心线程数+核心线程数),当BlockingQueue也满了,但线程池中总线程数 < maximumPoolSize时候就会再次创建新的线程。,非核心线程 =(maximumPoolSize – corePoolSize ) ,非核心线程闲置下来不干活最多存活时间。,线程池中非核心线程保持存活的时间的单位,线程池等待队列,维护着等待执行的Runnable对象。当运行当线程数= corePoolSize时,新的任务会被添加到workQueue中,如果workQueue也满了则尝试用非核心线程执行任务,等待队列应该尽量用有界的。,创建一个新线程时使用的工厂,可以用来设定线程名、是否为daemon线程等等。,corePoolSize、workQueue、maximumPoolSize都不可用的时候执行的饱和策略。,在线程池中,当提交的任务数量超过了线程池的最大容量,线程池就需要使用拒绝策略来处理无法处理的新任务。Java 中提供了 4 种默认的拒绝策略:,除了这些默认的策略之外,我们也可以自定义自己的拒绝策略,实现RejectedExecutionHandler接口即可。,
,线程池有七大参数,我们重点关注corePoolSize、maximumPoolSize、workQueue、handler 可以帮助我们更好地理解和优化线程池的性能,此值是用来初始化线程池中核心线程数,当线程池中线程数< corePoolSize时,系统默认是添加一个任务才创建一个线程池。当线程数 = corePoolSize时,新任务会追加到workQueue中。,maximumPoolSize表示允许的最大线程数 = (非核心线程数+核心线程数),当BlockingQueue也满了,但线程池中总线程数 < maximumPoolSize时候就会再次创建新的线程。,非核心线程 =(maximumPoolSize – corePoolSize ) ,非核心线程闲置下来不干活最多存活时间。,线程池中非核心线程保持存活的时间的单位,线程池等待队列,维护着等待执行的Runnable对象。当运行当线程数= corePoolSize时,新的任务会被添加到workQueue中,如果workQueue也满了则尝试用非核心线程执行任务,等待队列应该尽量用有界的。,创建一个新线程时使用的工厂,可以用来设定线程名、是否为daemon线程等等。,corePoolSize、workQueue、maximumPoolSize都不可用的时候执行的饱和策略。,在线程池中,当提交的任务数量超过了线程池的最大容量,线程池就需要使用拒绝策略来处理无法处理的新任务。Java 中提供了 4 种默认的拒绝策略:,除了这些默认的策略之外,我们也可以自定义自己的拒绝策略,实现RejectedExecutionHandler接口即可。,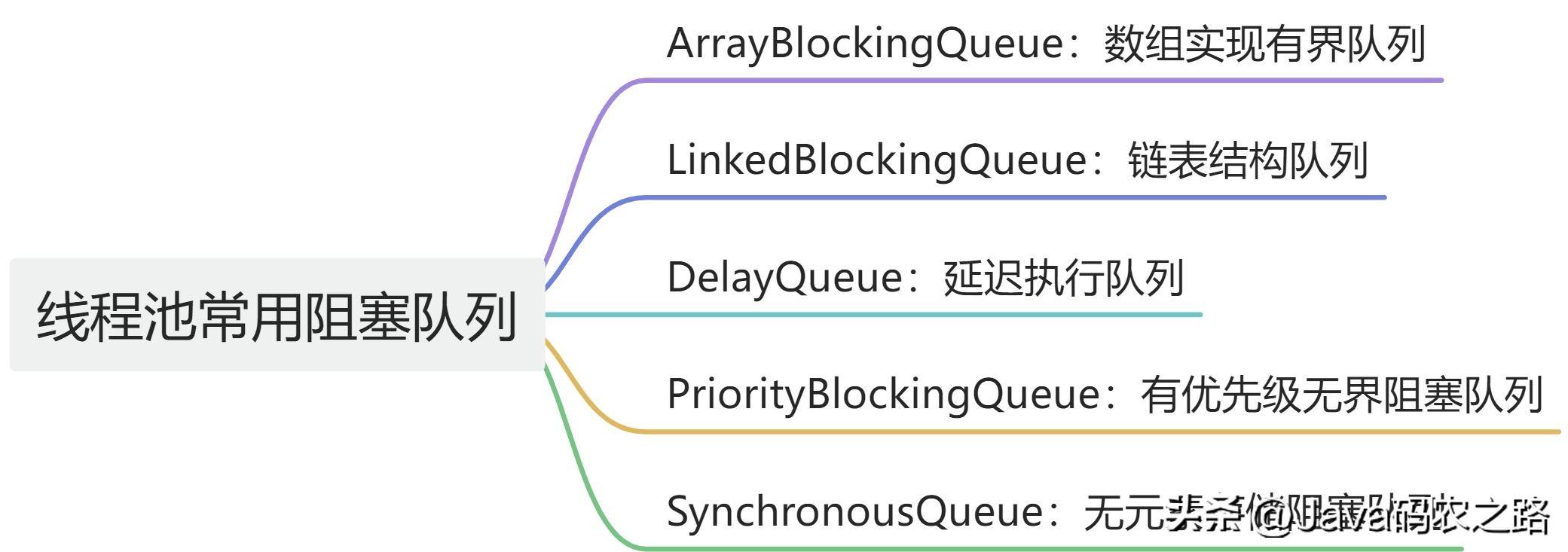 ,在Java中,线程池中一般有两种方法来提交任务:execute() 和 submit(),
,在Java中,线程池中一般有两种方法来提交任务:execute() 和 submit(),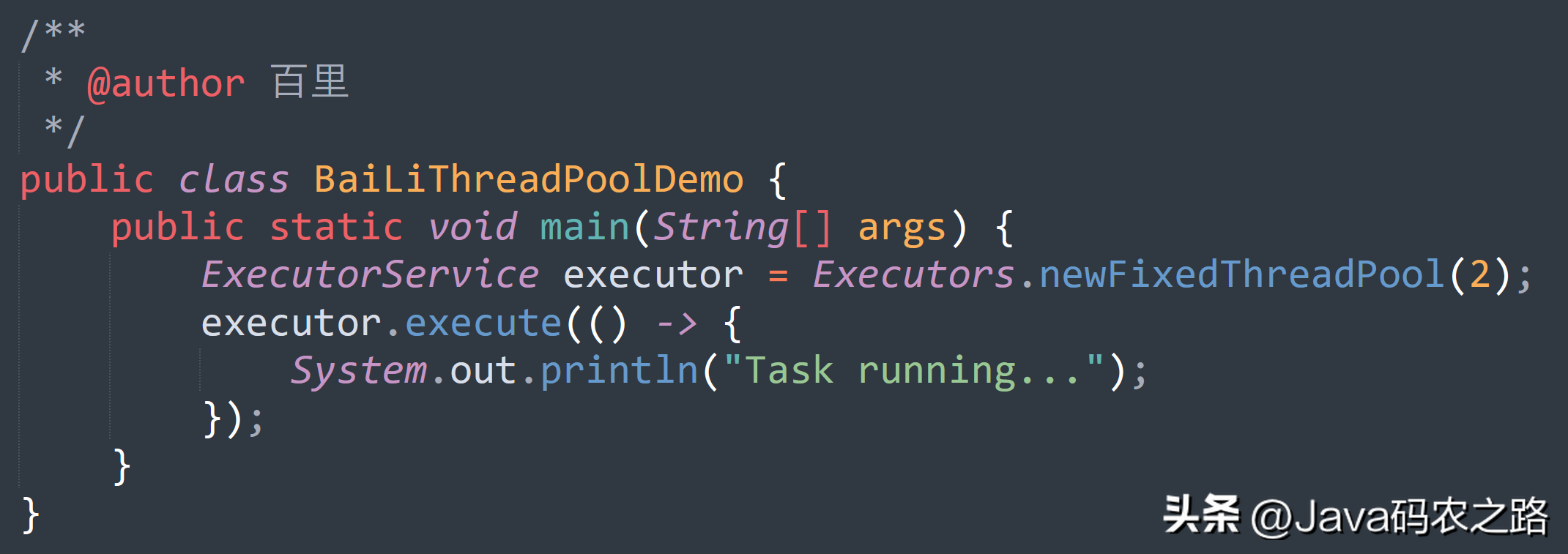 ,
,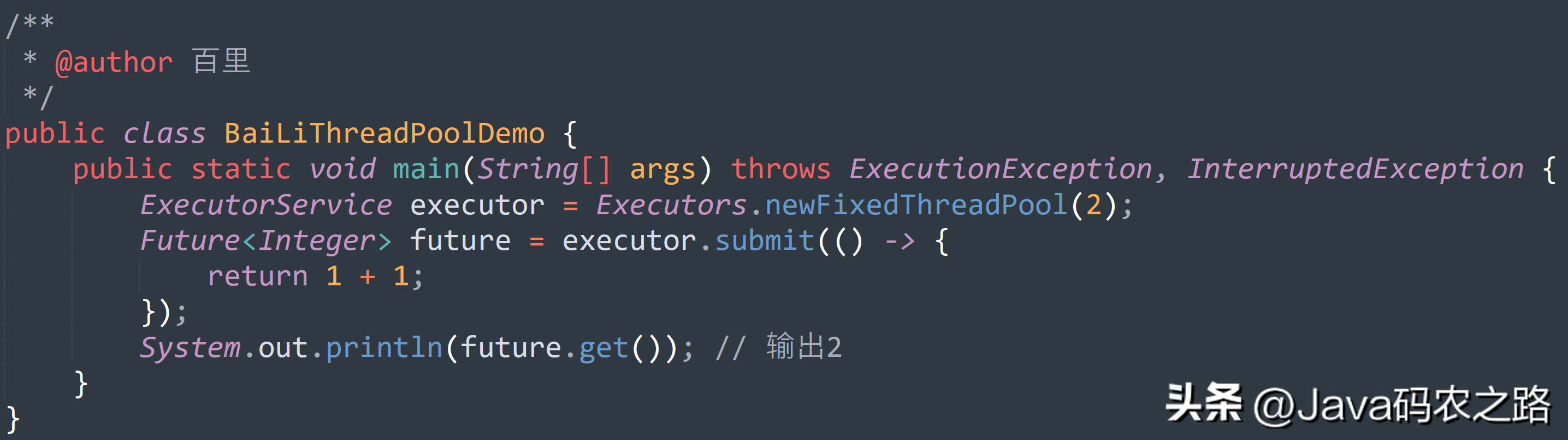 ,可以通过调用线程池的shutdown或shutdownNow方法来关闭线程池。它们的原理是遍历线程池中的工作线程,然后逐个调用线程的interrupt方法来中断线程,所以无法响应中断的任务可能永远无法终止。,shutdown:将线程池状态置为shutdown,并不会立即停止:,shutdownNow:将线程池状态置为stop。一般会立即停止,事实上不一定:,shutdown 和shutdownnow区别如下:,在Java中,常见的线程池类型主要有四种,都是通过工具类Excutors创建出来的。,
,可以通过调用线程池的shutdown或shutdownNow方法来关闭线程池。它们的原理是遍历线程池中的工作线程,然后逐个调用线程的interrupt方法来中断线程,所以无法响应中断的任务可能永远无法终止。,shutdown:将线程池状态置为shutdown,并不会立即停止:,shutdownNow:将线程池状态置为stop。一般会立即停止,事实上不一定:,shutdown 和shutdownnow区别如下:,在Java中,常见的线程池类型主要有四种,都是通过工具类Excutors创建出来的。, ,需要注意阿里巴巴《Java开发手册》里禁止使用这种方式来创建线程池。,
,需要注意阿里巴巴《Java开发手册》里禁止使用这种方式来创建线程池。,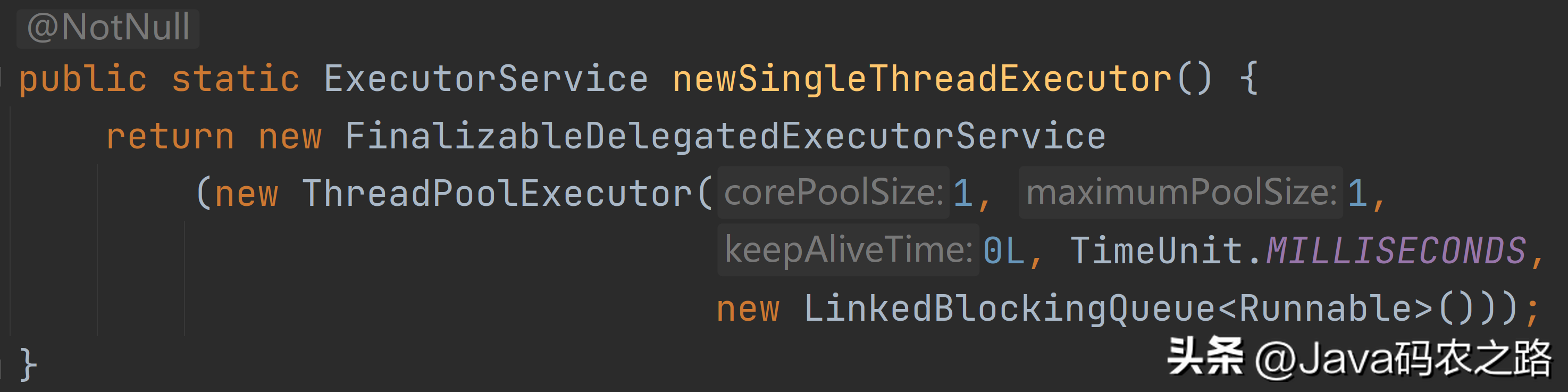 ,线程池特点:,
,线程池特点:,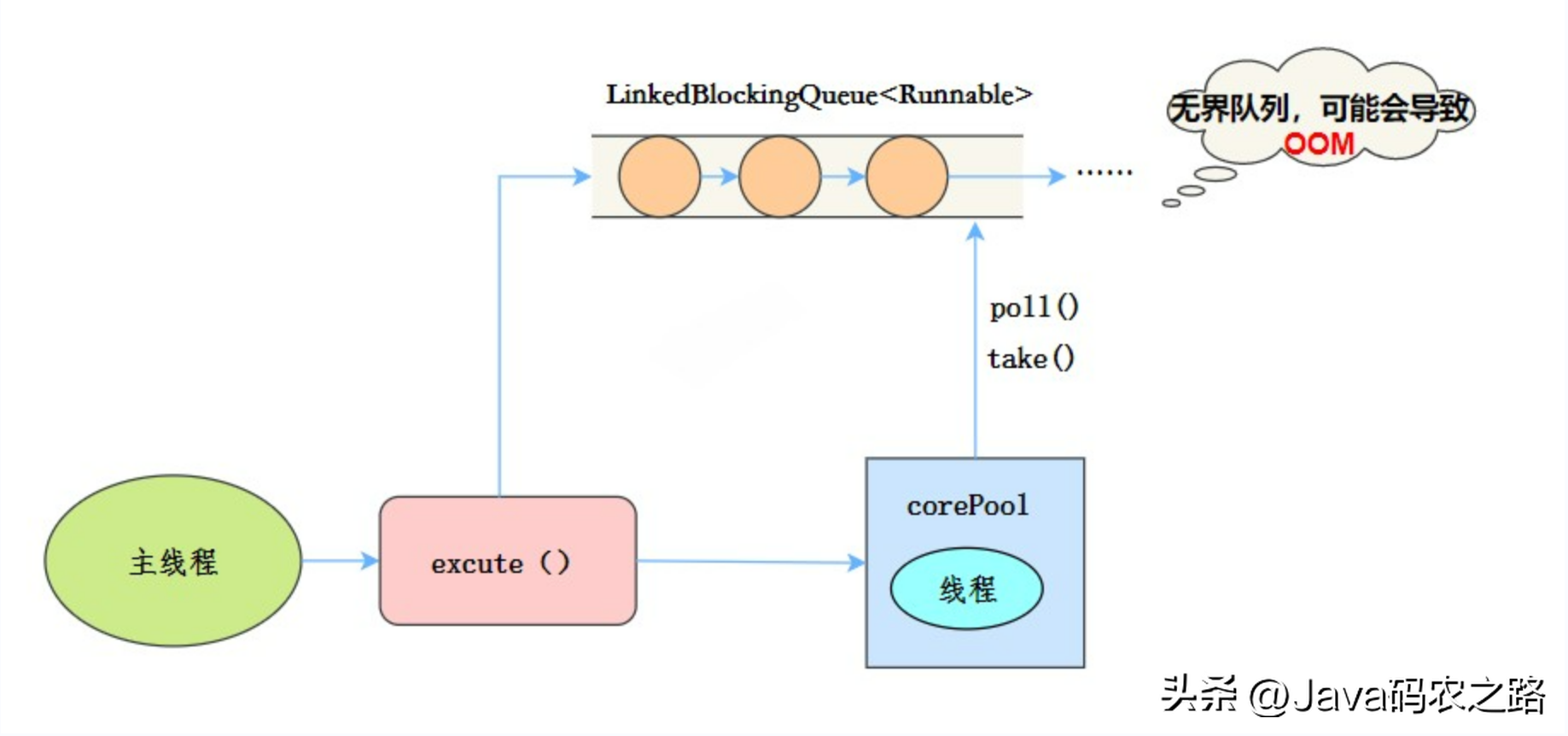 ,工作流程:,使用场景:,适用于串行执行任务的场景,一个任务一个任务地执行。,
,工作流程:,使用场景:,适用于串行执行任务的场景,一个任务一个任务地执行。, ,线程池特点:,
,线程池特点:,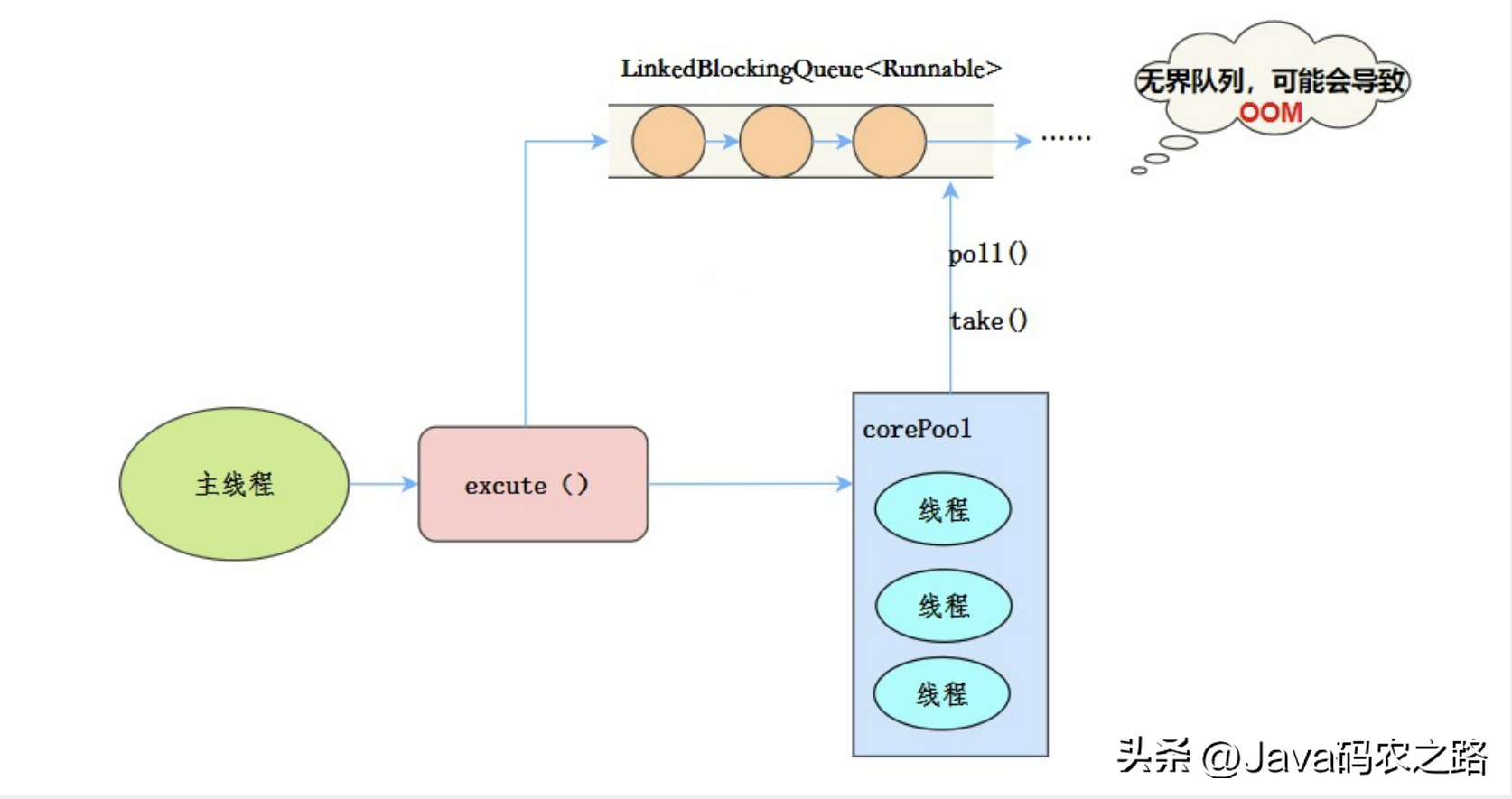 ,工作流程:,使用场景:,FixedThreadPool 适用于处理CPU密集型的任务,确保CPU在长期被工作线程使用的情况下,尽可能的少的分配线程,即适用执行长期的任务。,
,工作流程:,使用场景:,FixedThreadPool 适用于处理CPU密集型的任务,确保CPU在长期被工作线程使用的情况下,尽可能的少的分配线程,即适用执行长期的任务。, ,线程池特点:,当提交任务的速度大于处理任务的速度时,每次提交一个任务,就必然会创建一个线程。极端情况下会创建过多的线程,耗尽 CPU 和内存资源。由于空闲 60 秒的线程会被终止,长时间保持空闲的 CachedThreadPool 不会占用任何资源。,
,线程池特点:,当提交任务的速度大于处理任务的速度时,每次提交一个任务,就必然会创建一个线程。极端情况下会创建过多的线程,耗尽 CPU 和内存资源。由于空闲 60 秒的线程会被终止,长时间保持空闲的 CachedThreadPool 不会占用任何资源。,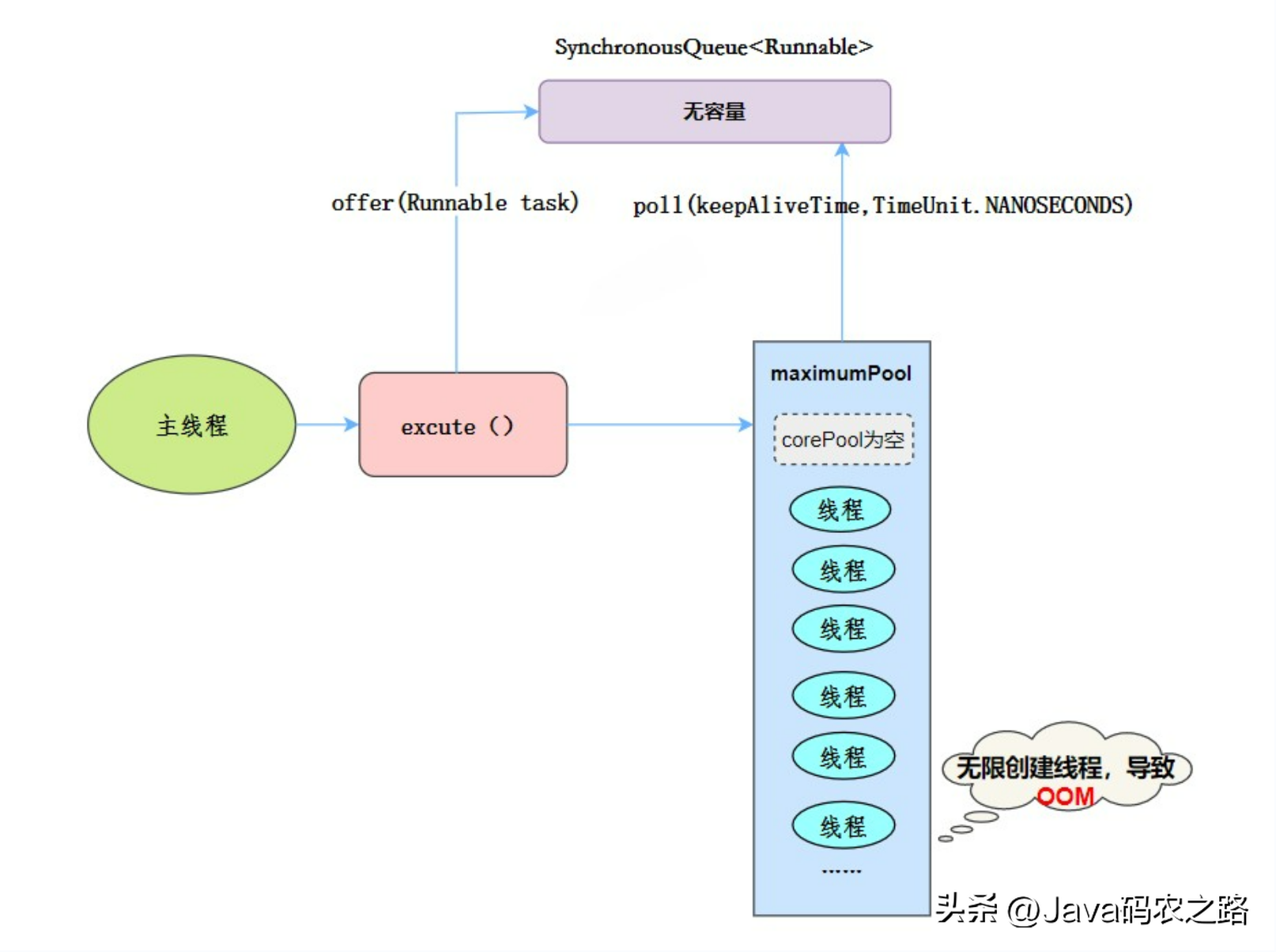 ,工作流程:,使用场景:,用于并发执行大量短期的小任务。,
,工作流程:,使用场景:,用于并发执行大量短期的小任务。, ,线程池特点:,
,线程池特点:,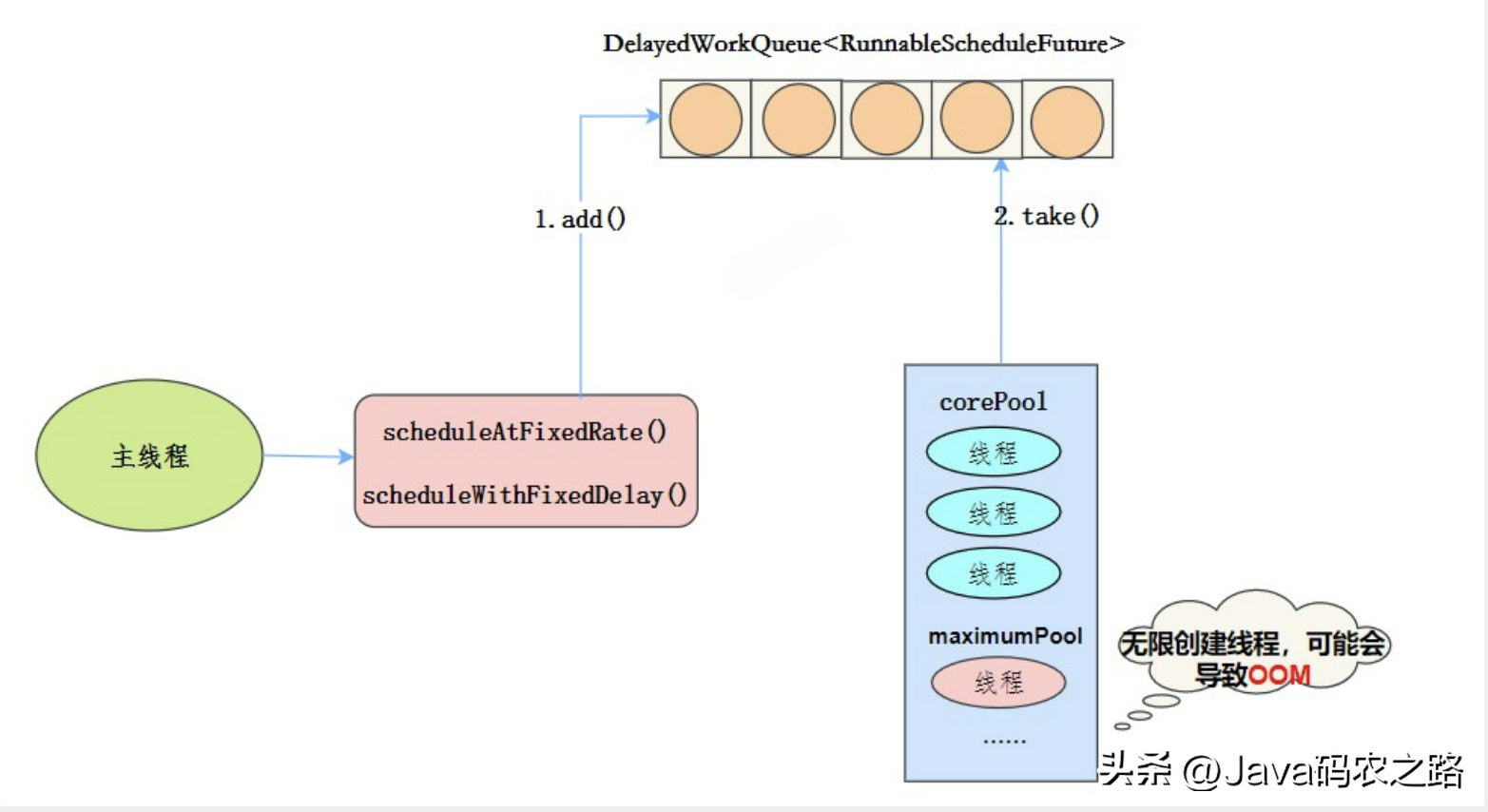 ,
,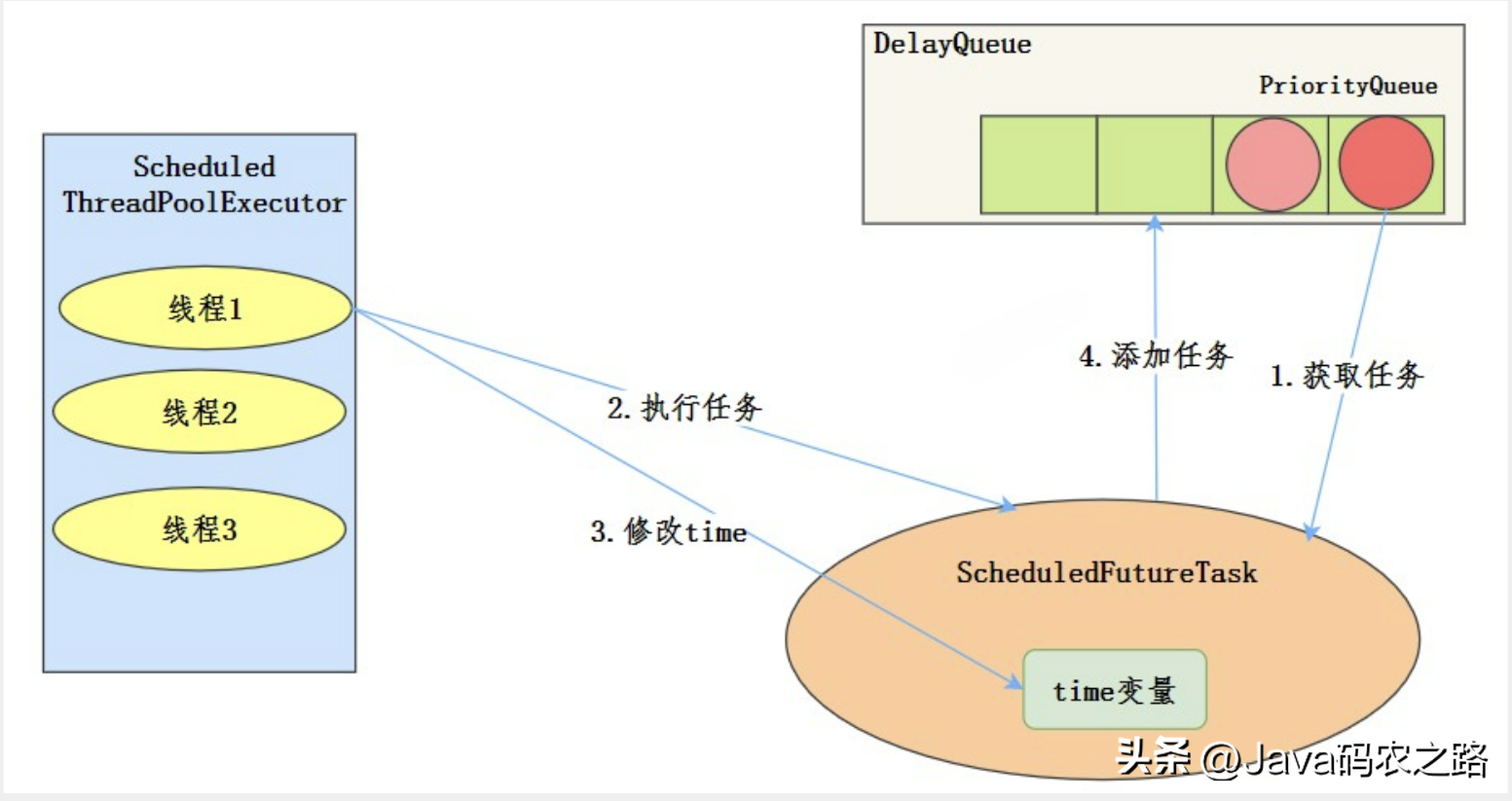 ,工作流程:,使用场景:,周期性执行任务的场景,需要限制线程数量的场景。,在使用线程池处理任务的时候,任务代码可能抛出RuntimeException,抛出异常后,线程池可能捕获它,也可能创建一个新的线程来代替异常的线程,我们可能无法感知任务出现了异常,因此我们需要考虑线程池异常情况。,常见的异常处理方式:,
,工作流程:,使用场景:,周期性执行任务的场景,需要限制线程数量的场景。,在使用线程池处理任务的时候,任务代码可能抛出RuntimeException,抛出异常后,线程池可能捕获它,也可能创建一个新的线程来代替异常的线程,我们可能无法感知任务出现了异常,因此我们需要考虑线程池异常情况。,常见的异常处理方式:, ,1.try-catch捕获异常,2.使用Thread.UncaughtExceptionHandler处理异常,3.重写ThreadPoolExecutor.afterExcute处理异常,4.使用future.get处理异常,线程池有这几个状态:RUNNING,SHUTDOWN,STOP,TIDYING,TERMINATED,线程池各个状态切换图:,
,1.try-catch捕获异常,2.使用Thread.UncaughtExceptionHandler处理异常,3.重写ThreadPoolExecutor.afterExcute处理异常,4.使用future.get处理异常,线程池有这几个状态:RUNNING,SHUTDOWN,STOP,TIDYING,TERMINATED,线程池各个状态切换图:,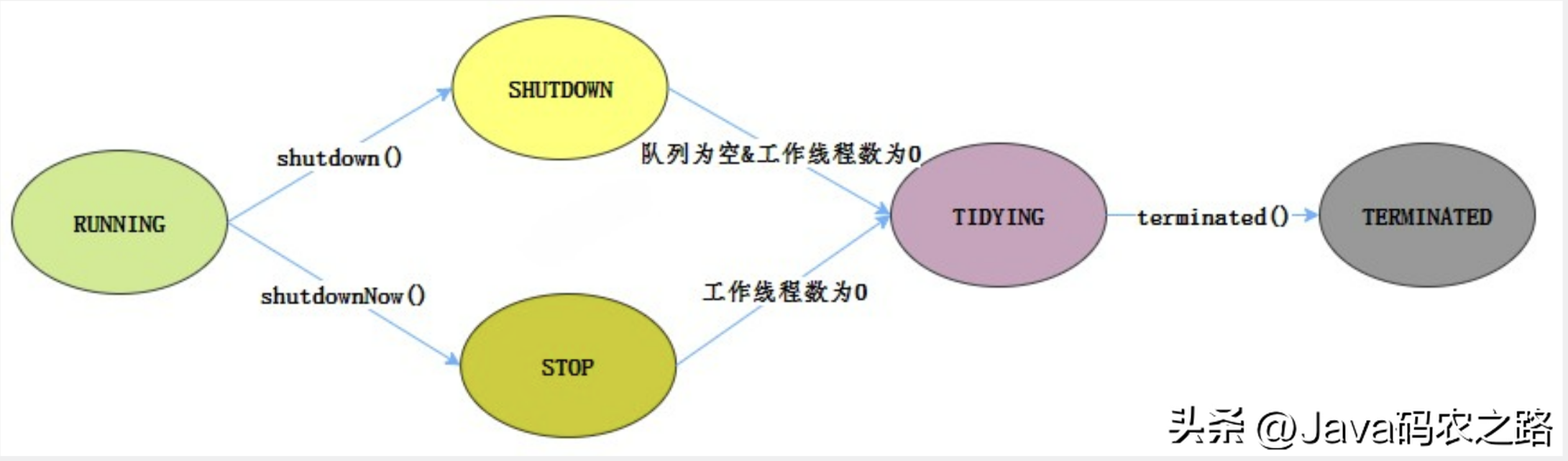 ,RUNNING,SHUTDOWN,STOP,TIDYING,TERMINATED,单机线程池是一种常见的多线程编程方式,它可以用于异步执行任务,提高应用程序的性能和并发能力。在单机线程池中,所有任务都由同一个线程处理,因此如果该线程在执行任务时突然断电,则会出现以下问题:,如果单机线程池在执行任务时突然遇到断电等异常情况,应该尽快采取以下措施:,NIO(Java Non-blocking I/O)是一种 I/O 技术,其核心原理是基于事件驱动的方式进行操作。,NIO 的工作原理:基于缓冲区、通道和选择器的组合,通过高效地利用系统资源,以支持高并发和高吞吐量的数据处理。相比传统的 I/O 编程方式,Java NIO 提供了更为灵活和高效的编程方式。,NIO三大核心组件: Channel(通道)、Buffer(缓冲区)、Selector(选择器)。,Selector、Channel 和 Buffer 的关系图如下:,
,RUNNING,SHUTDOWN,STOP,TIDYING,TERMINATED,单机线程池是一种常见的多线程编程方式,它可以用于异步执行任务,提高应用程序的性能和并发能力。在单机线程池中,所有任务都由同一个线程处理,因此如果该线程在执行任务时突然断电,则会出现以下问题:,如果单机线程池在执行任务时突然遇到断电等异常情况,应该尽快采取以下措施:,NIO(Java Non-blocking I/O)是一种 I/O 技术,其核心原理是基于事件驱动的方式进行操作。,NIO 的工作原理:基于缓冲区、通道和选择器的组合,通过高效地利用系统资源,以支持高并发和高吞吐量的数据处理。相比传统的 I/O 编程方式,Java NIO 提供了更为灵活和高效的编程方式。,NIO三大核心组件: Channel(通道)、Buffer(缓冲区)、Selector(选择器)。,Selector、Channel 和 Buffer 的关系图如下:,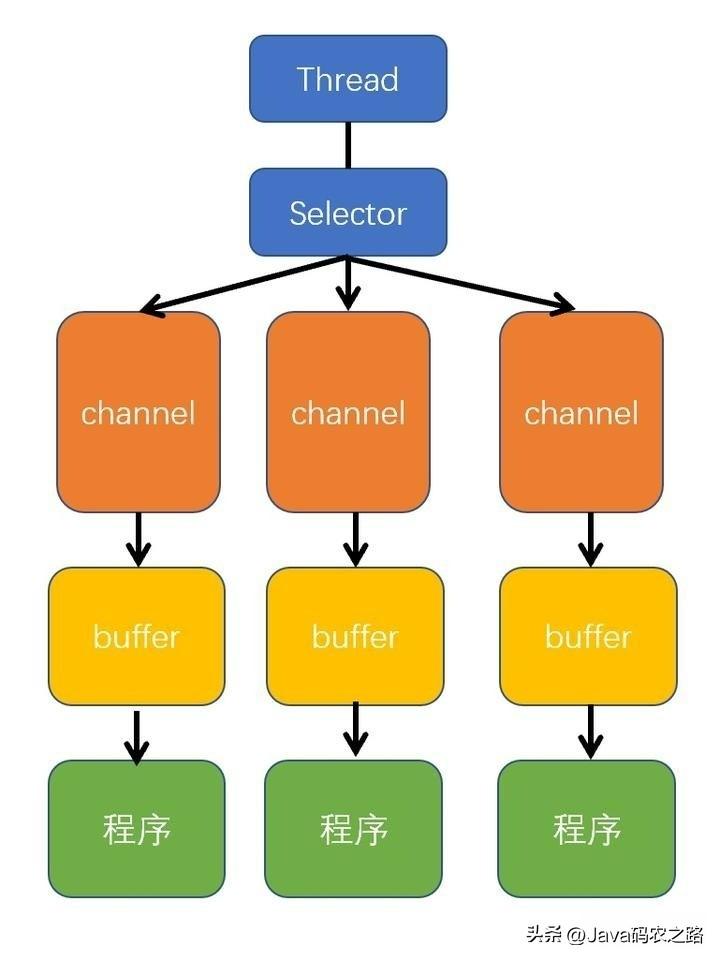 ,通俗理解NIO原理:,NIO 是可以做到用一个线程来处理多个操作的。假设有 10000 个请求过来,根据实际情况,可以分配 50 或者 100 个线程来处理。不像之前的阻塞 IO 那样,非得分配 10000 个。,零拷贝(Zero-Copy)是一种 I/O 操作优化技术,可以快速高效地将数据从文件系统移动到网络接口,而不需要将其从内核空间复制到用户空间。,传统I/O操作过程:,传统 I/O 的工作方式是,数据读取和写入是从用户空间到内核空间来回复制,而内核空间的数据是通过操作系统层面的 I/O 接口从磁盘读取或写入。代码通常如下,一般会需要两个系统调用:,代码很简单,虽然就两行代码,但是这里面发生了不少的事情:,
,通俗理解NIO原理:,NIO 是可以做到用一个线程来处理多个操作的。假设有 10000 个请求过来,根据实际情况,可以分配 50 或者 100 个线程来处理。不像之前的阻塞 IO 那样,非得分配 10000 个。,零拷贝(Zero-Copy)是一种 I/O 操作优化技术,可以快速高效地将数据从文件系统移动到网络接口,而不需要将其从内核空间复制到用户空间。,传统I/O操作过程:,传统 I/O 的工作方式是,数据读取和写入是从用户空间到内核空间来回复制,而内核空间的数据是通过操作系统层面的 I/O 接口从磁盘读取或写入。代码通常如下,一般会需要两个系统调用:,代码很简单,虽然就两行代码,但是这里面发生了不少的事情:,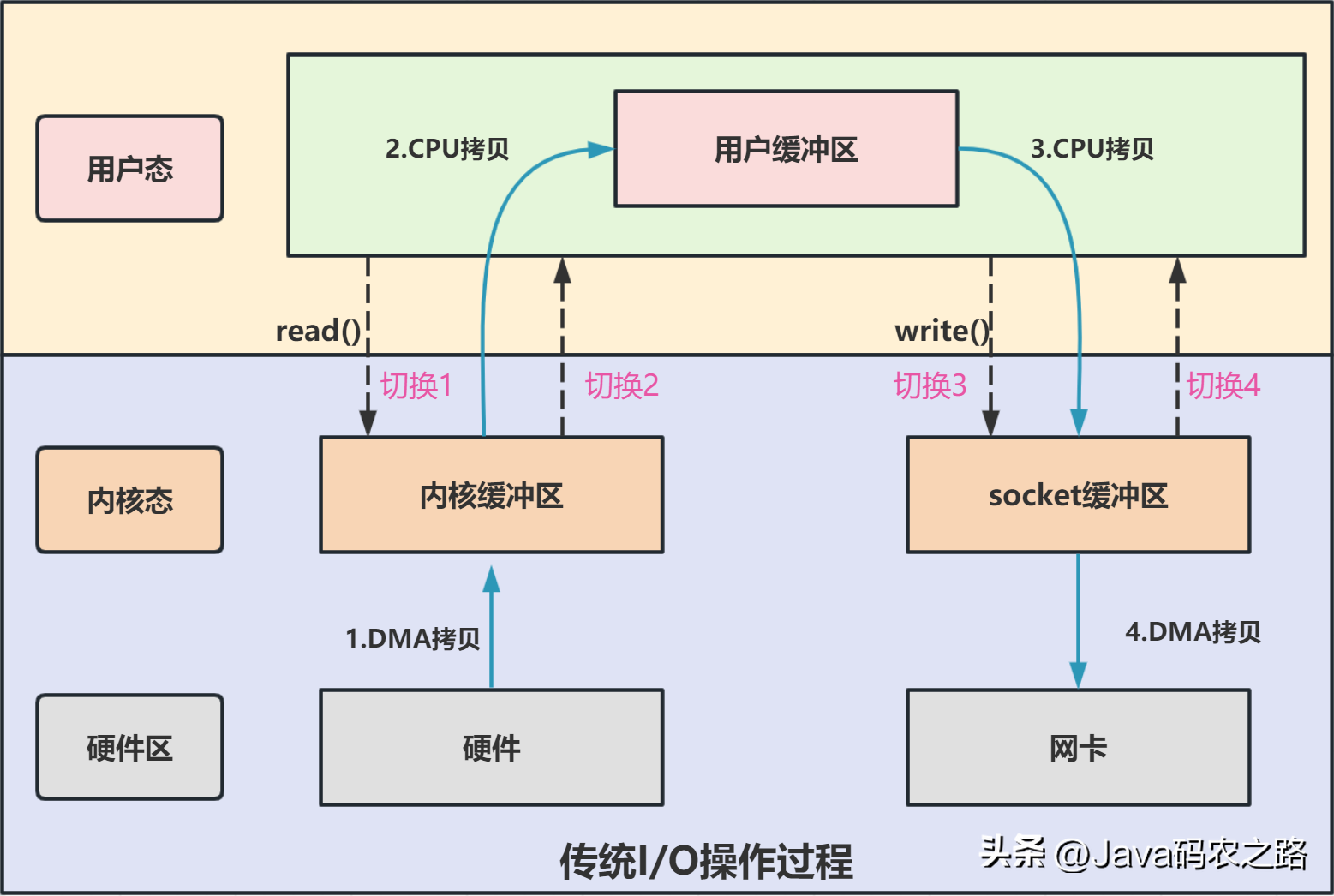 ,从流程图可以看出,传统IO的读写流程,包括了4次上下文切换(4次用户态和内核态的切换),4次数据拷贝(两次CPU拷贝以及两次的DMA拷贝),这种简单又传统的文件传输方式,存在冗余的上文切换和数据拷贝,在高并发系统里是非常糟糕的,多了很多不必要的开销,会严重影响系统性能。,所以,要想提高文件传输的性能,就需要减少「用户态与内核态的上下文切换」和「内存拷贝」的次数。,零拷贝主要是用来解决操作系统在处理 I/O 操作时,频繁复制数据的问题。关于零拷贝主要技术有MMap+Write、SendFile等几种方式。,Mmap+Wirte实现零拷贝:,
,从流程图可以看出,传统IO的读写流程,包括了4次上下文切换(4次用户态和内核态的切换),4次数据拷贝(两次CPU拷贝以及两次的DMA拷贝),这种简单又传统的文件传输方式,存在冗余的上文切换和数据拷贝,在高并发系统里是非常糟糕的,多了很多不必要的开销,会严重影响系统性能。,所以,要想提高文件传输的性能,就需要减少「用户态与内核态的上下文切换」和「内存拷贝」的次数。,零拷贝主要是用来解决操作系统在处理 I/O 操作时,频繁复制数据的问题。关于零拷贝主要技术有MMap+Write、SendFile等几种方式。,Mmap+Wirte实现零拷贝:,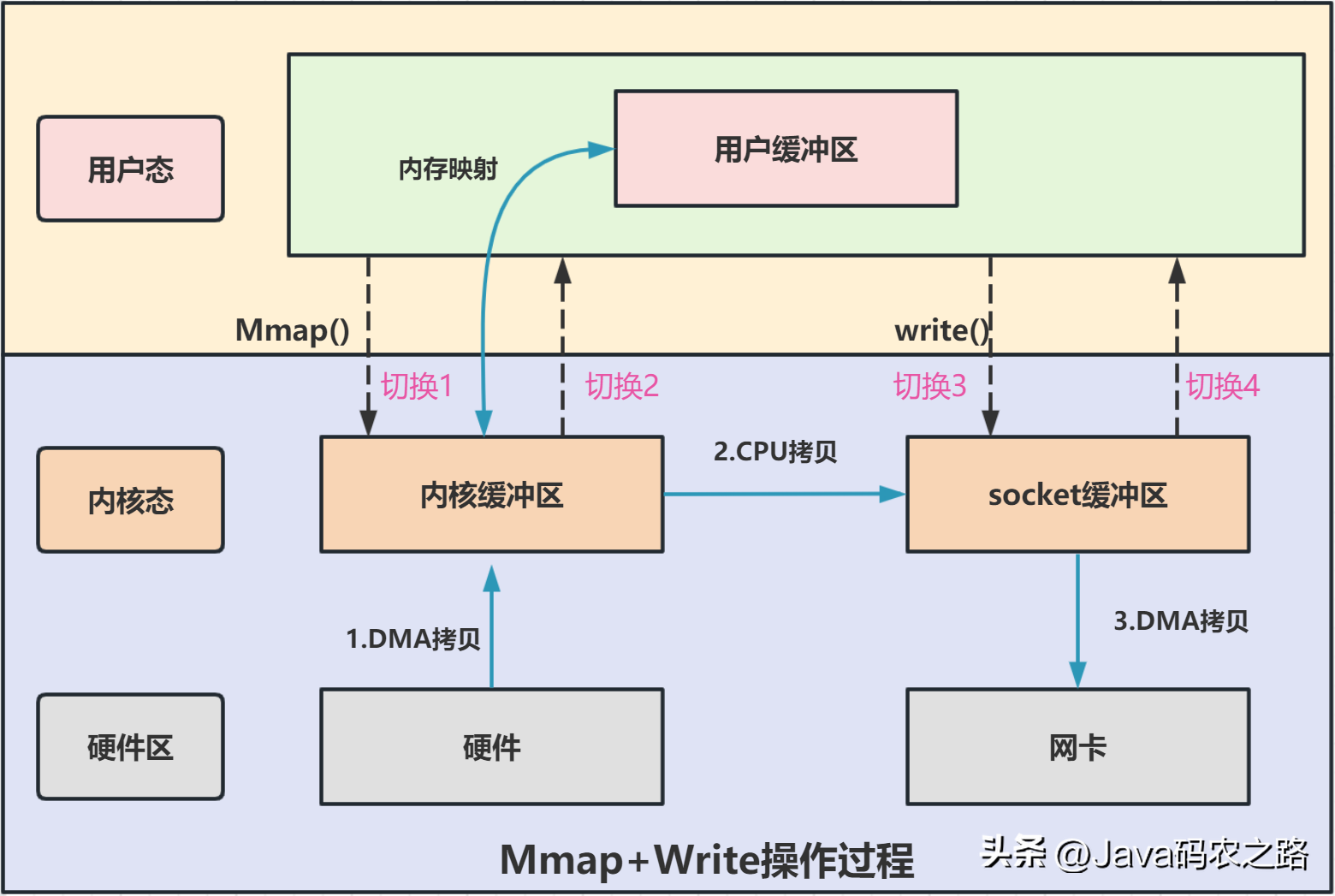 ,可以发现,mmap+write实现的零拷贝,I/O发生了4次用户空间与内核空间的上下文切换,以及3次数据拷贝。其中3次数据拷贝中,包括了2次DMA拷贝和1次CPU拷贝。,SendFile实现零拷贝:,
,可以发现,mmap+write实现的零拷贝,I/O发生了4次用户空间与内核空间的上下文切换,以及3次数据拷贝。其中3次数据拷贝中,包括了2次DMA拷贝和1次CPU拷贝。,SendFile实现零拷贝:,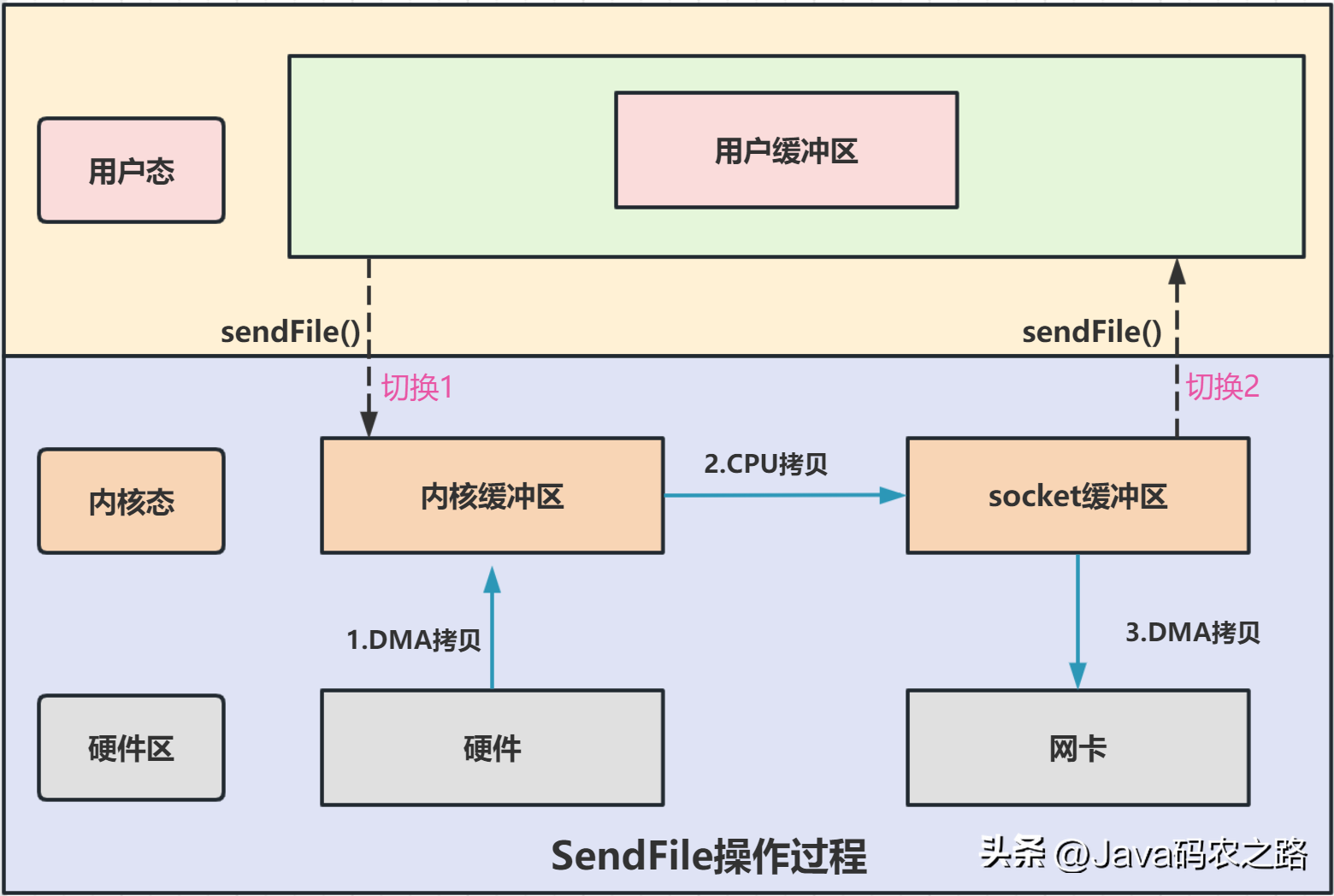 ,可以发现,sendfile实现的零拷贝,I/O发生了2次用户空间与内核空间的上下文切换,以及3次数据拷贝。其中3次数据拷贝中,包括了2次DMA拷贝和1次CPU拷贝。,
,可以发现,sendfile实现的零拷贝,I/O发生了2次用户空间与内核空间的上下文切换,以及3次数据拷贝。其中3次数据拷贝中,包括了2次DMA拷贝和1次CPU拷贝。,
© 版权声明
文章版权归作者所有,未经允许请勿转载。


