
下图所示为线程池的实现原理:调用方不断地向线程池中提交任务;线程池中有一组线程,不断地 从队列中取任务,这是一个典型的生产者—消费者模型。,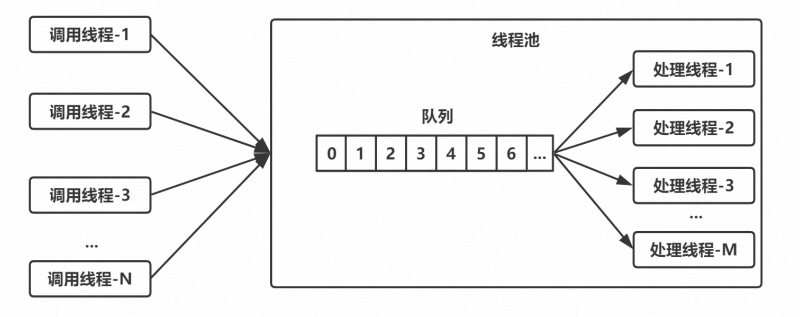 ,要实现这样一个线程池,有几个问题需要考虑:,1. 队列设置多长?如果是无界的,调用方不断地往队列中放任务,可能导致内存耗尽。如果是有 界的,当队列满了之后,调用方如何处理?,2. 线程池中的线程个数是固定的,还是动态变化的?,3. 每次提交新任务,是放入队列?还是开新线程?,4. 当没有任务的时候,线程是睡眠一小段时间?还是进入阻塞?如果进入阻塞,如何唤醒?,针对问题4,有3种做法:,1. 不使用阻塞队列,只使用一般的线程安全的队列,也无阻塞/唤醒机制。当队列为空时,线程 池中的线程只能睡眠一会儿,然后醒来去看队列中有没有新任务到来,如此不断轮询。,2. 不使用阻塞队列,但在队列外部、线程池内部实现了阻塞/唤醒机制。,3. 使用阻塞队列。,很显然,做法3最完善,既避免了线程池内部自己实现阻塞/唤醒机制的麻烦,也避免了做法1的睡 眠/轮询带来的资源消耗和延迟。正因为如此,接下来要讲的
,要实现这样一个线程池,有几个问题需要考虑:,1. 队列设置多长?如果是无界的,调用方不断地往队列中放任务,可能导致内存耗尽。如果是有 界的,当队列满了之后,调用方如何处理?,2. 线程池中的线程个数是固定的,还是动态变化的?,3. 每次提交新任务,是放入队列?还是开新线程?,4. 当没有任务的时候,线程是睡眠一小段时间?还是进入阻塞?如果进入阻塞,如何唤醒?,针对问题4,有3种做法:,1. 不使用阻塞队列,只使用一般的线程安全的队列,也无阻塞/唤醒机制。当队列为空时,线程 池中的线程只能睡眠一会儿,然后醒来去看队列中有没有新任务到来,如此不断轮询。,2. 不使用阻塞队列,但在队列外部、线程池内部实现了阻塞/唤醒机制。,3. 使用阻塞队列。,很显然,做法3最完善,既避免了线程池内部自己实现阻塞/唤醒机制的麻烦,也避免了做法1的睡 眠/轮询带来的资源消耗和延迟。正因为如此,接下来要讲的
ThreadPoolExector/ScheduledThreadPoolExecutor都是基于阻塞队列来实现的,而不是一般的队列, 至此,各式各样的阻塞队列就要派上用场了,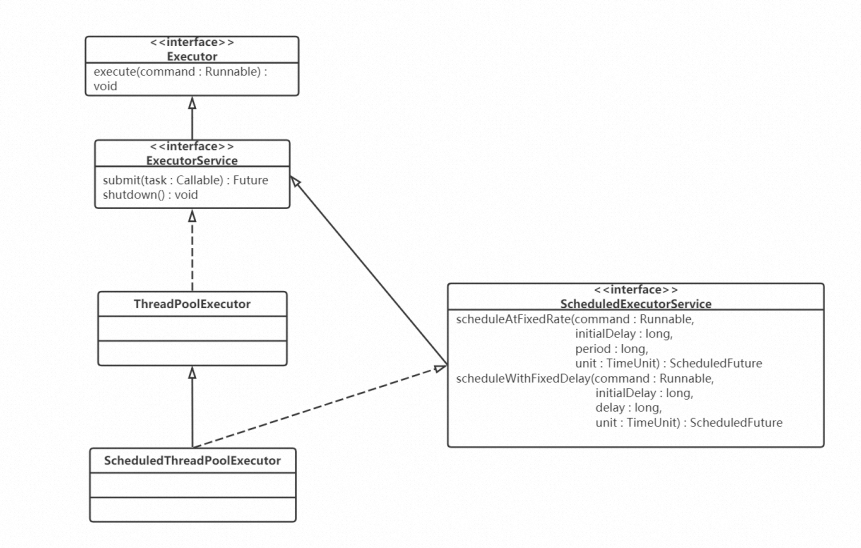 ,在这里,有两个核心的类: ThreadPoolExector 和
,在这里,有两个核心的类: ThreadPoolExector 和
ScheduledThreadPoolExecutor ,后者不仅 可以执行某个任务,还可以周期性地执行任务。,向线程池中提交的每个任务,都必须实现 Runnable 接口,通过最上面的 Executor 接口中的 execute(Runnable command) 向线程池提交任务。,然后,在ExecutorService 中,定义了线程池的关闭接口 shutdown() ,还定义了可以有返回值 的任务,也就是 Callable ,后面会详细介绍。,基于线程池的实现原理,下面看一下ThreadPoolExector的核心数据结构。,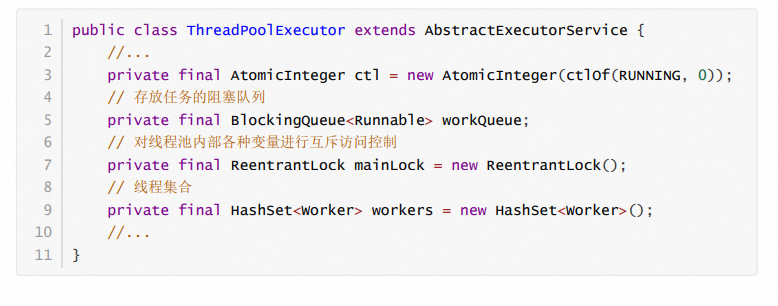 ,每一个线程是一个Worker对象。Worker是ThreadPoolExector的内部类,核心数据结构如下:,
,每一个线程是一个Worker对象。Worker是ThreadPoolExector的内部类,核心数据结构如下:, ,由定义会发现,Worker继承于AQS,也就是说Worker本身就是一把锁。这把锁有什么用处呢?用于线程池的关闭、线程执行任务的过程中。,ThreadPoolExecutor在其构造方法中提供了几个核心配置参数,来配置不同策略的线程池。,
,由定义会发现,Worker继承于AQS,也就是说Worker本身就是一把锁。这把锁有什么用处呢?用于线程池的关闭、线程执行任务的过程中。,ThreadPoolExecutor在其构造方法中提供了几个核心配置参数,来配置不同策略的线程池。,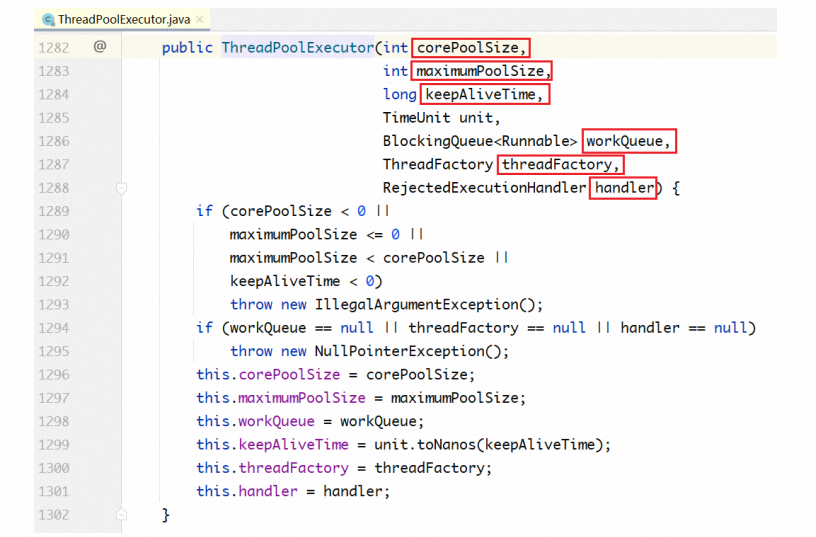 ,上面的各个参数,解释如下:,1. corePoolSize:在线程池中始终维护的线程个数。,2. maxPoolSize:在corePooSize已满、队列也满的情况下,扩充线程至此值。,3. keepAliveTime/TimeUnit:maxPoolSize 中的空闲线程,销毁所需要的时间,总线程数收缩 回corePoolSize。,4. blockingQueue:线程池所用的队列类型。,5. threadFactory:线程创建工厂,可以自定义,有默认值
,上面的各个参数,解释如下:,1. corePoolSize:在线程池中始终维护的线程个数。,2. maxPoolSize:在corePooSize已满、队列也满的情况下,扩充线程至此值。,3. keepAliveTime/TimeUnit:maxPoolSize 中的空闲线程,销毁所需要的时间,总线程数收缩 回corePoolSize。,4. blockingQueue:线程池所用的队列类型。,5. threadFactory:线程创建工厂,可以自定义,有默认值
Executors.defaultThreadFactory(),6. RejectedExecutionHandler:corePoolSize已满,队列已满,maxPoolSize 已满,最后的拒 绝策略。,下面来看这6个配置参数在任务的提交过程中是怎么运作的。在每次往线程池中提交任务的时候,有 如下的处理流程:,步骤一:判断当前线程数是否大于或等于corePoolSize。如果小于,则新建线程执行;如果大于, 则进入步骤二。,步骤二:判断队列是否已满。如未满,则放入;如已满,则进入步骤三。,步骤三:判断当前线程数是否大于或等于maxPoolSize。如果小于,则新建线程执行;如果大于, 则进入步骤四。,步骤四:根据拒绝策略,拒绝任务。,总结一下:首先判断corePoolSize,其次判断blockingQueue是否已满,接着判断maxPoolSize, 最后使用拒绝策略。 很显然,基于这种流程,如果队列是无界的,将永远没有机会走到步骤三,也即maxPoolSize没有 使用,也一定不会走到步骤四。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


