Python性能分析,使用cProfile可视化并解决性能瓶颈问题
帕累托法则无处不在,它说:
“在大多数情况下,80%的结果来自于20%的原因。”
作为一名程序员,当代码运行速度不尽如人意时,就需要花费大量时间对代码进行相应的重构。但在许多情况下,所得到的速度提升并不值得花费的精力。
Python标准库已经提供了性能分析所需的工具,即cProfile。本文将向你展示如何使用cProfile,以可视化的方式快速识别代码中哪些部分计算开销最高,并且应该优先进行优化。
安装
cProfile
cProfile是我们将用来测量代码的各个部分所需时间的工具,它是Python标准库的一部分,因此无需安装。
QCachegrind
QCachegrind将负责可视化cProfile的输出结果,将能够快速观察到性能瓶颈所在。
MacOS 用户
请检查你是否已经安装了Homebrew。如果没有安装,请使用以下命令进行安装:
ruby -e “$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" < /dev/null 2> /dev/null然后你可以安装QCachegrind
brew install qcachegrind其他用户
对于其他操作系统的用户,推荐Pyprof2calltree工具。
Pyprof2calltree
Pyprof2calltree将使用cProfile收集的分析数据转换为QCachegrind可以读取的格式。
安装方法如下:
pip install pyprof2calltree方法
完成安装后,进入包含Python脚本的文件夹。

包含要优化的脚本的文件夹
测量
我们使用cProfile来测量脚本不同部分的运行时间,并将结果保存在一个名为medium_example.profile的文件中(可以选择使用任何名称,只要它是.profile文件):
python -m cProfile -o medium_example.profile 1_generate_ML_data.py正如你所看到的,medium_example.profile文件已添加到文件夹中:

该文件包含了运行脚本中所涉及的不同函数的运行时间。
可视化
现在,我们可以将cProfile的测量结果可视化:
pyprof2calltree -k -i medium_example.profile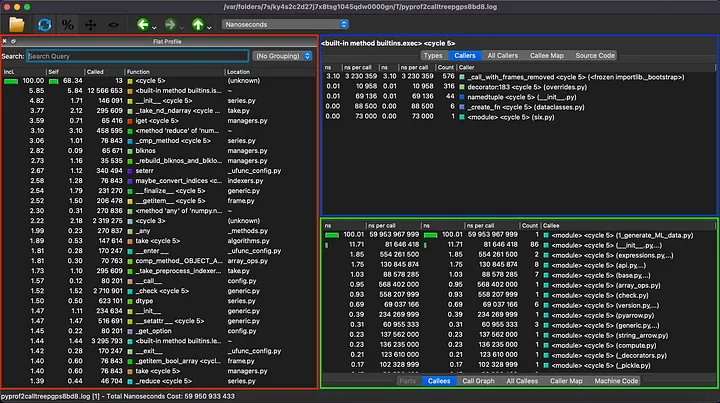
QCachegrind的用户界面包含了与所有相关函数的执行时间有关的信息:红色的是“Flat Profile”(左侧),蓝色的是“Callers”(右上方),绿色的是“Callees”(右下方)。
这个用户界面展示的内容较多。接下来本文会逐一解释所有这些内容的含义。
- “Flat Profile” 面板出现在左侧,按时间消耗的降序排列提供了完整的函数调用列表。“Incl.” 列显示每个函数消耗的总时间,考虑到其被调用者花费的时间。
- “Self” 列显示仅在函数本身内部花费的时间,不包括其被调用者花费的时间。
- “Called” 列显示函数被调用的次数,而“Function” 列则显示函数的名称,包括其命名空间。
- “Callers” 面板(右上方)显示调用所选函数的函数列表,以及在每个调用者函数中花费的时间。
- 另一方面,“Callees” 面板(右下方)显示由所选函数调用的函数列表,以及每个被调用者函数中花费的时间。通过优化这些被调用者函数,你可以提高所选函数的性能。
现在你知道如何解读用户界面,接下来展示如何使用它来找到性能瓶颈。
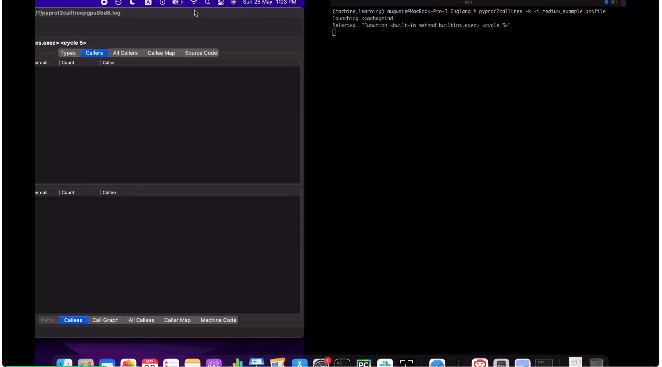
利用QCachegrind用户界面识别性能瓶颈
在“Flat Profile”面板的搜索栏中,输入builtins.exec,然后选择函数<Built-in method builtins.exec>。
在“Callees”面板中,选择应该占用所有(~100%)的执行时间的第一个函数。它是你之前执行的脚本的入口点。
然后,该函数会被移到“Callers”面板上,并刷新“Callees”面板显示其中调用的函数。
在本示例中,96.52%的执行时间来自函数generate_all_season_games_features。
如果想再深入一级,可以选择该函数。它再次被移到“Callers”面板上,而“Callees”面板则显示了被调用的函数。
看起来,42.73%的执行时间来自于generate_results_hometeam_current_season,而42.57%的执行时间来自于generate_resukts_awayteam_current_season。
由于它们对速度的影响相同,我可以选择处理其中的任意一个函数。
或者,如果需要的话,可以更深入地调查一级。
优化
建议从优化耗时最长的函数开始。所需的重构对代码来说将是非常具体的。以下是一些典型优化的示例:
- 将嵌套的for循环转换为单个for循环。
- 实现多进程。
- 使用向量化。
重复进行
当应用了第一个优化后,可以根据实际需要多次进行测量-可视化-优化周期,以达到符合要求的总运行时间。
结论
当涉及到优化代码时,遵循数据驱动的方法,能确保在不进行太多猜测和浪费时间的情况下,取得快速进展。
© 版权声明
文章版权归作者所有,未经允许请勿转载。