
联邦学习是机器学习中一个非常火热的领域,指多方在不传递数据的情况下共同训练模型。随着联邦学习的发展,联邦学习系统也层出不穷,例如 FATE, FedML, PaddleFL, TensorFlow-Federated 等等。然而,大部分联邦学习系统不支持树模型的联邦学习训练。相比于神经网络,树模型具有训练快,可解释性强,适合表格型数据的特点。树模型在金融,医疗,互联网等领域有广泛的应用场景,比如用来做广告推荐、股票预测等等。
决策树的代表性模型为 Gradient Boosting Decision Tree (GBDT)。由于一棵树的预测能力有限,GBDT 通过 boosting 的方法串行训练多棵树,通过每棵树用来拟合当前预测值和标签值的残差的方式,最终达到一个好的预测效果。代表性的 GBDT 系统有 XGBoost, LightGBM, CatBoost, ThunderGBM,其中 XGBoost 多次被 KDD cup 的冠军队伍所使用。然而,这些系统都不支持联邦学习场景下的 GBDT 训练。近日,来自新加坡国立大学和清华大学的研究者提出了一种专注于训练树模型的联邦学习新系统 FedTree。

- 论文地址:https://github.com/Xtra-Computing/FedTree/blob/main/FedTree_draft_paper.pdf
- 项目地址:https://github.com/Xtra-Computing/FedTree
FedTree 系统介绍FedTree 架构图如图 1 所示,共有 5 个模块: 接口,环境,框架,隐私保护以及模型。
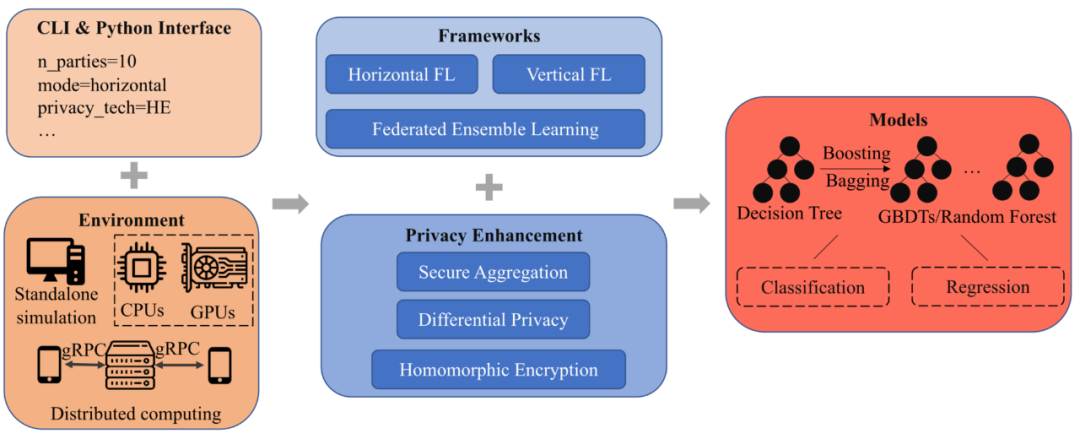
图 1: FedTree 系统架构图
接口:FedTree 支持两种接口:命令行接口和 Python 接口。用户只需给定参数(参与方数量,联邦场景等),就可以用一行命令来运行 FedTree 进行训练。FedTree 的 Python 接口和 scikit-learn 兼容,可以调用 fit() 和 predict() 来进行训练和预测。
环境:FedTree 支持在单机上模拟部署联邦学习,和在多机上部署分布式联邦学习。在单机环境上,FedTree 支持将数据进行划分成多个子数据集,每个子数据集作为一个参与方进行训练。在多机环境上,FedTree 支持将每个机器作为一个参与方,机器之间 通过 gRPC 进行通信。同时,除了 CPU 以外,FedTree 支持使用 GPU 来加速训练。
框架:FedTree 支持横向和纵向联邦学习场景下 GBDT 的训练。横向场景下,不同参与方有着不同的训练样本和相同的特征空间。纵向场景下,不同参与方有着不同的特征空间和相同的训练样本。为了保证性能,在这两种情境下,多有参与方都共同参与每个节点的训练。除此之外,FedTree 还支持集成学习,参与方并行地训练树之后再进行聚合,以此减少参与方之间的通信开销。
隐私:由于训练过程中传递的梯度可能会泄露训练数据的信息,FedTree 提供不同的隐私保护方法来进一步保护梯度信息,包括同态加密 (HE) 和安全聚合 (SA)。同时,FedTree 提供了差分隐私来保护最终训练得到的模型。
模型:以训练一棵树为基础,FedTree 通过 boosting/bagging 的方法支持训练 GBDT/random forest。通过设置不同的损失函数,FedTree 训练得到的模型支持多种任务,包括分类和回归。
实验表 1 总结了不同系统在 a9a, breast 和 credit 上的 AUC 和 abalone 上的 RMSE,FedTree 的模型效果和用所有数据训练 GBDT(XGBoost, ThunderGBM)以及 FATE 中的 SecureBoost (SBT) 几乎一致。而且,隐私保护策略 SA 和 HE 并不会影响模型性能。

表 1: 不同系统的模型效果比较
表 2 总结了不同系统每棵树的训练时间(单位:秒),可以看到 FedTree 相比于 FATE 快了很多,在横向联邦学习场景下能达到 100 倍以上的加速比。

表 2: 不同系统每棵树的训练时间比较
更多研究细节请参考 FedTree 论文原文。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


