

大家好,非常高兴在今天的峰会能与大家一起分享Apache PyFlink的核心技术部分。
首先,还是简单的自我介绍一下,我是孙金城,花名 金竹,来自阿里巴巴,从2016年开始一直投入在开源建设中,目前是Apache Flink PMC成员,Apache Beam Committer和Apache IoTDB的PMC成员。同时也是Apache 软件基金会的成员,Apache Member。平时也喜欢写一些技术类博客和录制一下视频课程,也欢迎大家关注我的公众号。

今天我们有4个部分的内容分享,首先我们快速了解一下PyFlink的使命愿景,然后重点介绍PyFlink的核心技术点,最后是和大家快速介绍PyFlink的未来规划和现有的应用案例。那么我们开始今天的第一部分,PyFlink的使命愿景。
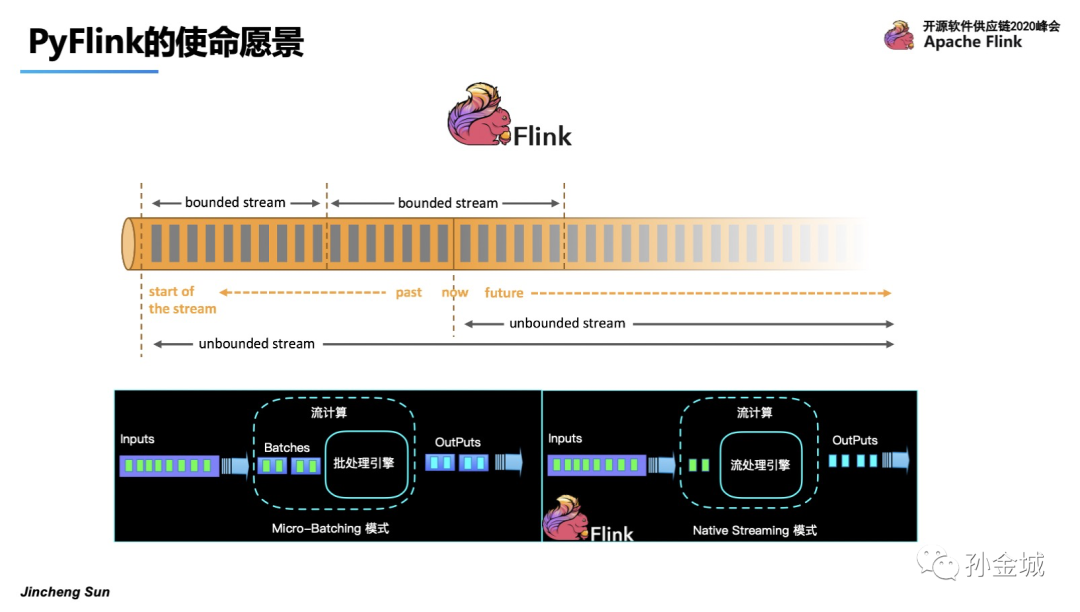
首先,Apache Flink 是一个有状态的分布式流式计算框架。可以作用在有限和无限的数据集合之上。
那么业界对有限和无限数据集合上进行流式计算处理,有2种典型的架构,一个是Micro-Batching的模式,也就是将流看成是批的特例。那么另一种就是Apache Flink的架构模式,纯流的架构模式,将批看成是流的特例。纯流的设计将计算的延时做到了极致。
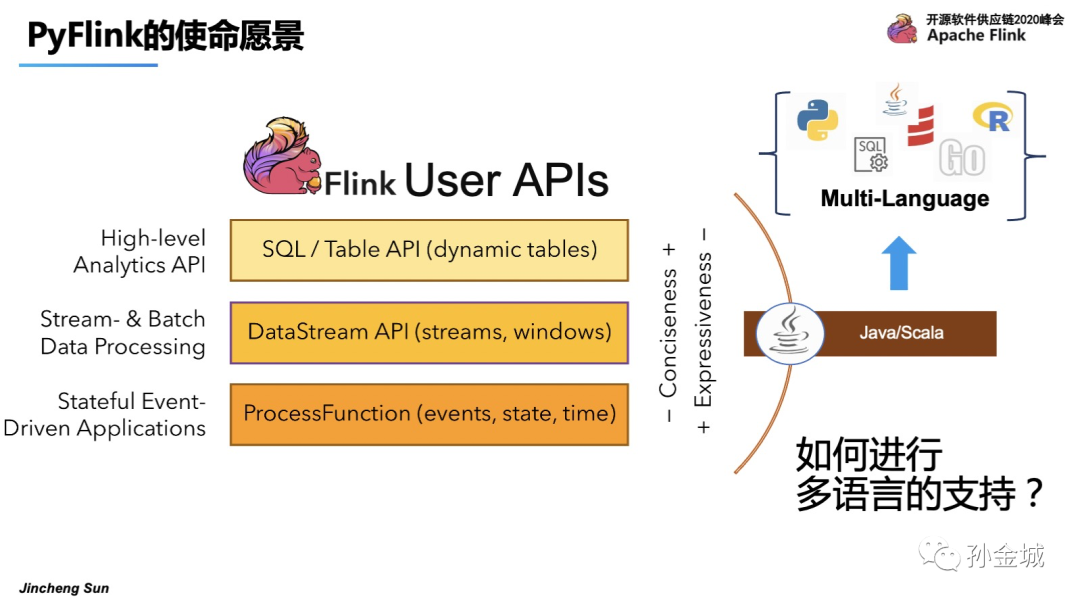
那么Flink这种分布式亚秒级延时的能力如何暴露给用户呢?Flink提供了SQL,DataStream和ProcessFunction多层API供用户选择,但是非常遗憾的是只能提供给Java用户群体。
那么,如果将Flink的能力进行放大,面向更多的用户群体将是一件非常有意义的事情,那么如何在在Flink上进行多语言的支持呢?增加哪些语言的支持呢?
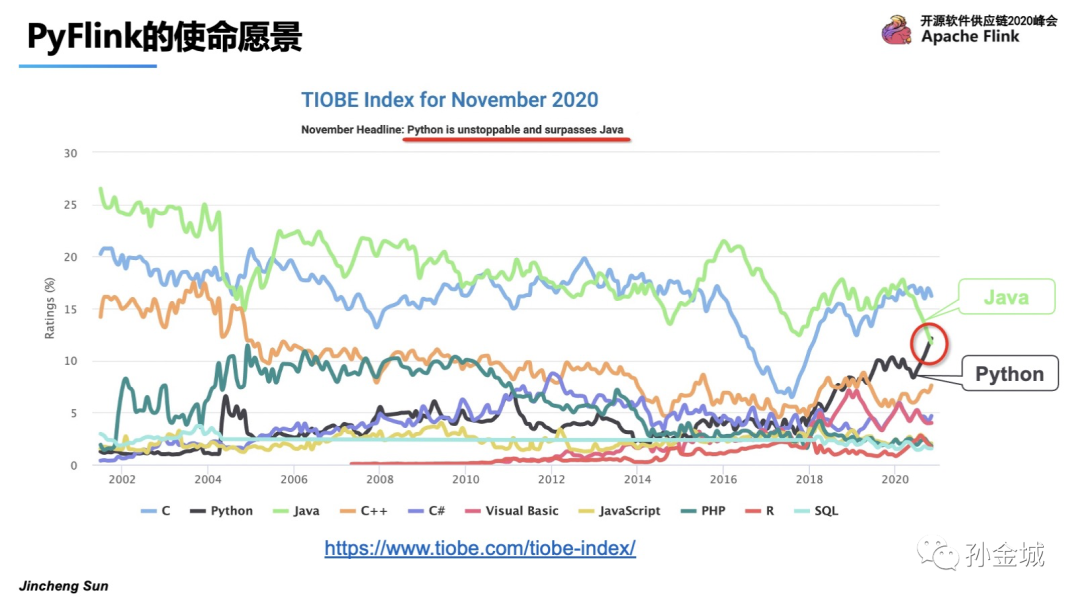
我们在进行PyFlink的工作之前进行了一些调研,我们发现Python语言在2020年的活跃程度超过了Java语言,并且是一个持续上升的趋势。
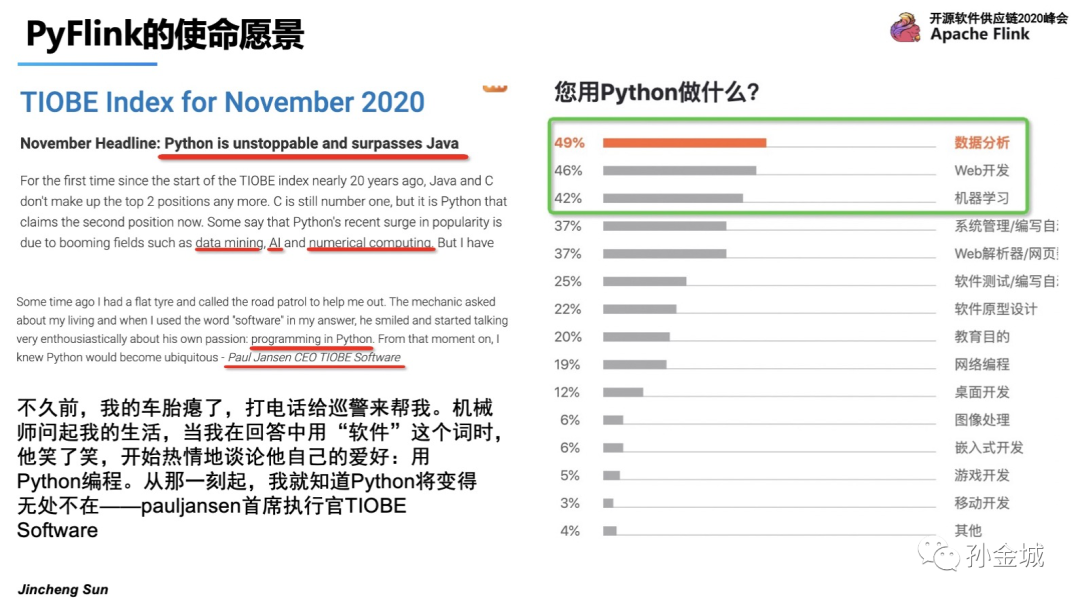
那么我们再进一步了解,为什么Python语言如此备受关注,大家都利用Python语言完成怎样的工作呢?带着这些问题,随着AI的崛起,Python不仅仅广泛应用在数据分析和web开发领域,更多的也在AI/机器学习领域也有广泛应用。更有趣的一件事是,连公路巡警的爱好都变成了Python编程,8/9岁的小孩也在用Python做趣味游戏。这足以见证Python的受欢迎程度。所以将Python作为Flink多语言支持最重要的开发语言。
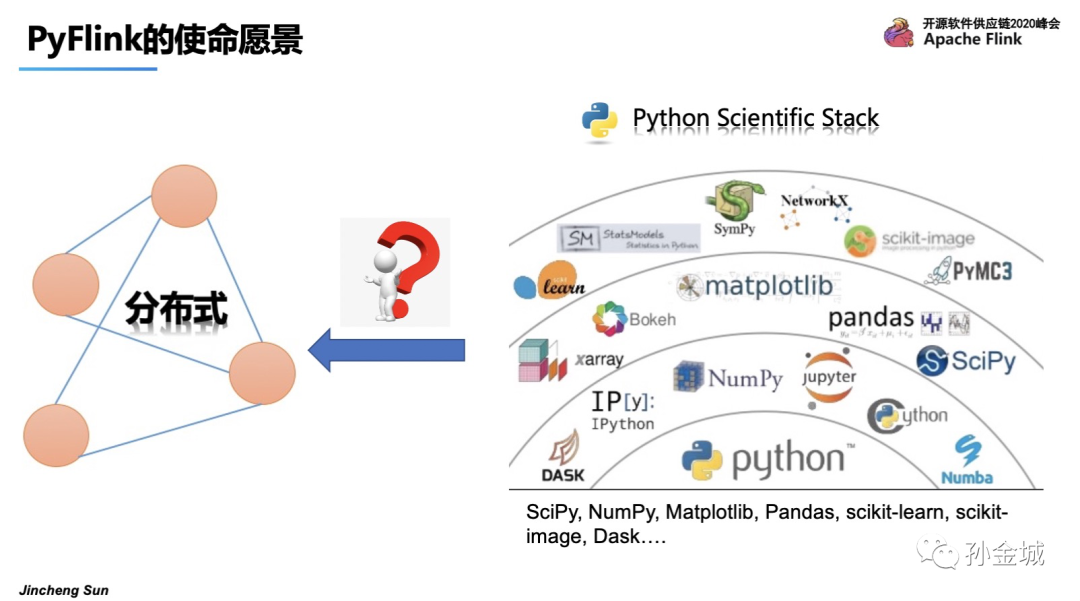
Python非常受欢迎,并且Python有非常成熟的生态发展,但是这里有一个典型的问题,那就是这些生态库大多是单机模式,在大数据时代的今天,Python生态面临的一个典型问题就是:
如何支持海量数据的处理,如何提供分布式能力?

所以,面对Flink能力需要面向更多的用户群体,Python又是最受欢迎的语言,Python就成为了Flink多语言支持的第一个语言。同时面对Python语言的分布式能力的匮乏,PyFlink的使命也是要将Python生态具备分布处理能力。所以,Pyflink的使命就是Flink能力输出到Python用户,并令Python生态具备分布式化能力。

好的,接下来我们看看PyFlink如何完成自己的使命,有哪些核心的技术细节。

首先,Flink能力输出到Python用户最核心问题显而易见是Python VM和Java VM的握手,他们之间要建立通讯,这是PyFlink首要解决的问题。
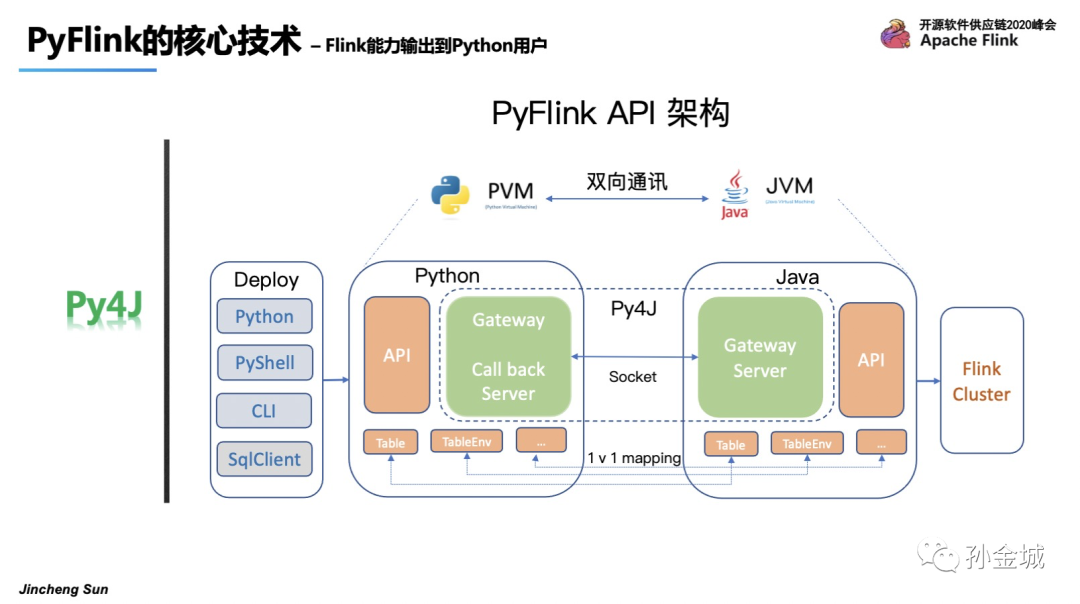
面对PVM和JVM通讯问题,我们选择了Py4J,在PythonVM启动一个Gateway,并且Java VM启动一个Gateway Server用于接受Python的请求,同时在Python API里面提供和Java API一样的对象,比如 TableENV, Table,等等。这样Python在写Python API的时候本质是在调用Java API,同时还有作业部署问题,我们可以用Python命令,Python shell和CLI等多种方式进行作业提交。
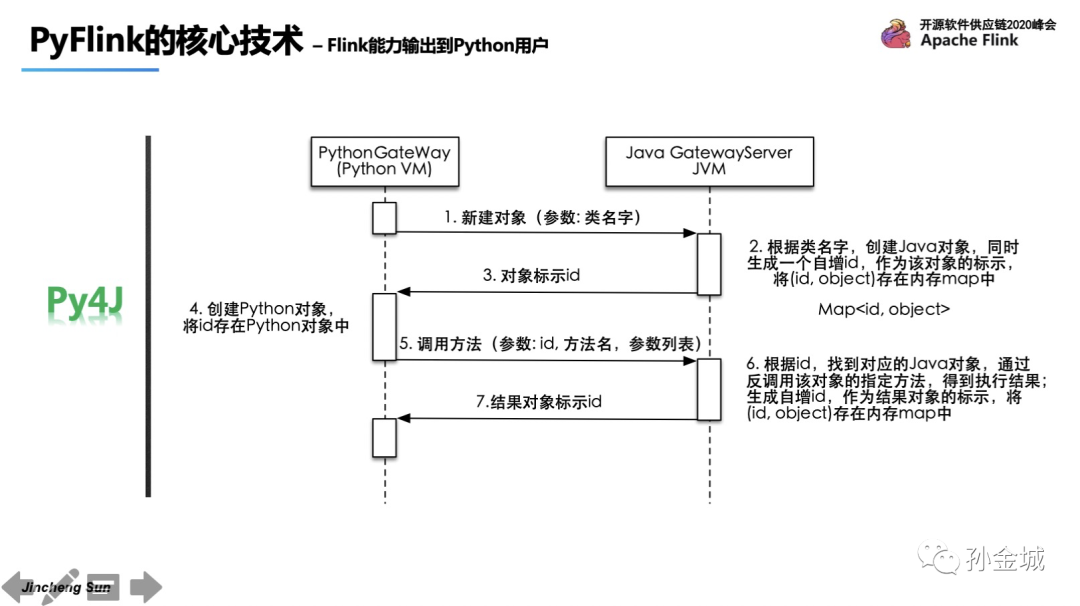
那么Py4J和JVM交互的原理是什么呢?其实最核心的机制是在Python端每创建一个对象,都会对应的在Java端创建一个Java对象,并生成一个对象ID,Java端利用Map保存对象ID和对象。同时将对象ID返回Python端,Python端基于对象ID和方法参数进行操作本质上都是在操作Java对象。
 那么基于这样的架构有怎样的优势呢?第一个就是简单,并确保Python API语义和Java API的一致性,第二点,Python 作业可以达到和Java一样的极致性能,在刚刚结束的阿里双11狂欢节中,创造了峰值40亿的处理能力。
那么基于这样的架构有怎样的优势呢?第一个就是简单,并确保Python API语义和Java API的一致性,第二点,Python 作业可以达到和Java一样的极致性能,在刚刚结束的阿里双11狂欢节中,创造了峰值40亿的处理能力。
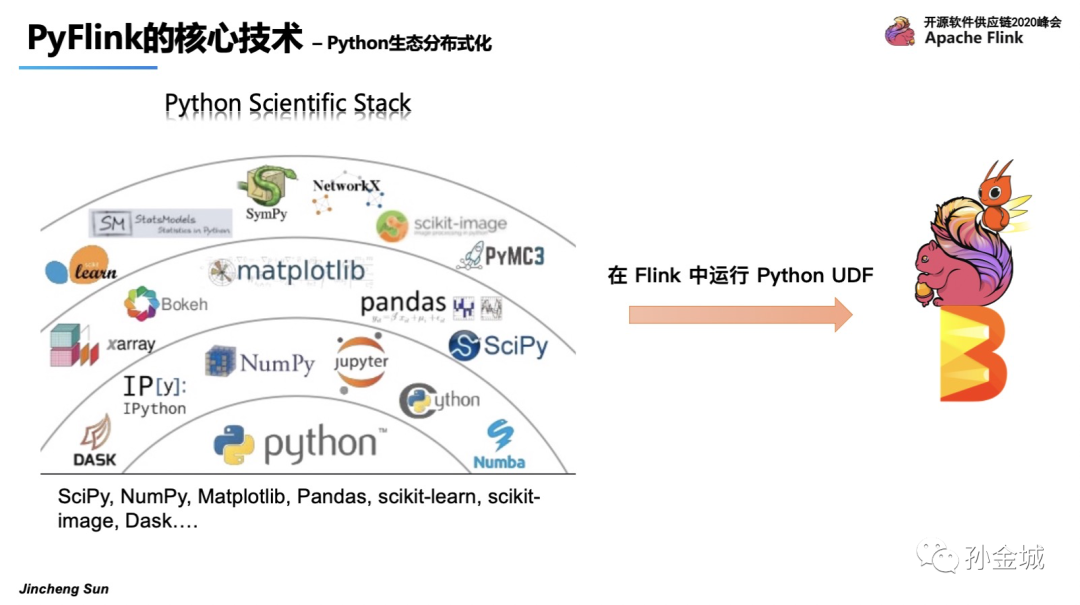
OK,在完成了现有Flink功能向Python用户的输出之后,接下来我们继续探讨,如何将Python生态功能引入Flink中,进而将Python 功能分布式化。如何达成?结合现有Flink Table API的现状和现有Python类库的特点,我们可以对现有所有的Python类库功能视为 用户自定义函数(UDF),集成到Flink中。这样我们就找到了集成Python生态到Flink中的手段是将其视为UDF,那么集成的核心问题是什么?没错,那就是Python UDF的执行问题。好,我们针对这个核心问题我们如何处理呢?
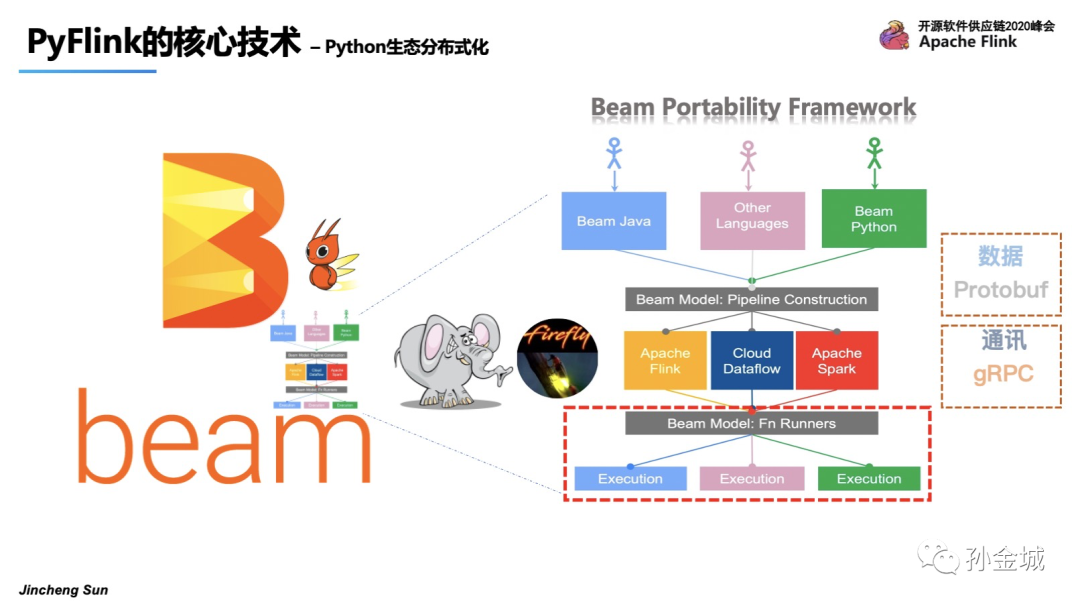
解决Python UDF执行问题可不仅仅是VM之间通讯的问题了,它涉及到Python执行环境的管理,业务数据在Java和Python之间的解析,Flink State Backend能力向Python的输出,Python UDF执行的监控等等,是一个非常复杂的问题。面对这样复杂的问题,我们选择了统一编程模型Apache Beam,Beam为了解决多语言和多引擎支持问题高度抽象了一个叫 Portability Framework 的架构,如下图,Beam目前可以支持Java/Go/Python等多种语言,其中图下方 Beam Fu Runners 和 Execution之间就解决了 引擎和UDF执行环境的问题。其核心是对利用Protobuf进行数据结构抽象,利用gRPC协议进行通讯,同时封装了核心的gRPC 服务。所以这时候Beam更像是一只萤火虫,照亮了PyFlink解决UDF执行问题之路。我们接下来看看Beam到底提供了哪些gRPC服务。
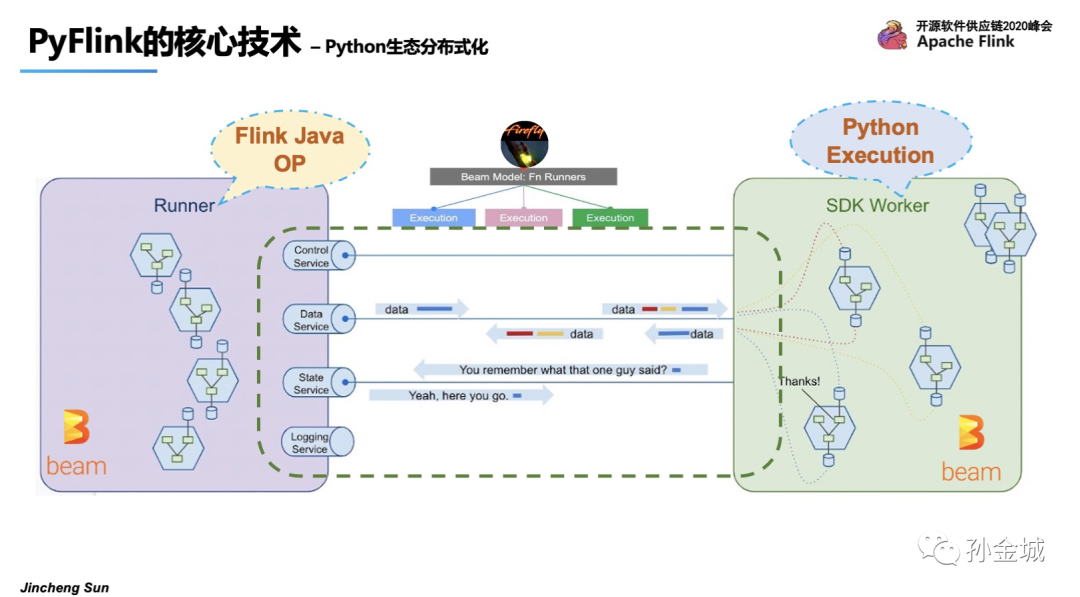
如图 Runner部分是Java的算子执行,SDK Worker部分是Python的执行环境,Beam已经抽象Control/Data/State/Logging等服务。并这些服务已经在Beam的Flink runner上稳定高效的运行了很久了。所以在PyFlink UDF执行上面我们可以站在巨人的肩膀上了:),这里我们发现Apache Beam 在API层面和在UDF的执行层面都有解决方案,而PyFlink在API层面采用了Py4J解决VM通讯问题,在UDF执行需求上采用了Beam的Protability Framework解决UDF执行环境问题。这也表明了PyFlink在技术选型上严格遵循以最小的代价达成既定目标的原则,在技术选型上永远会选择最合适的,最符合PyFlink长期发展的技术架构。
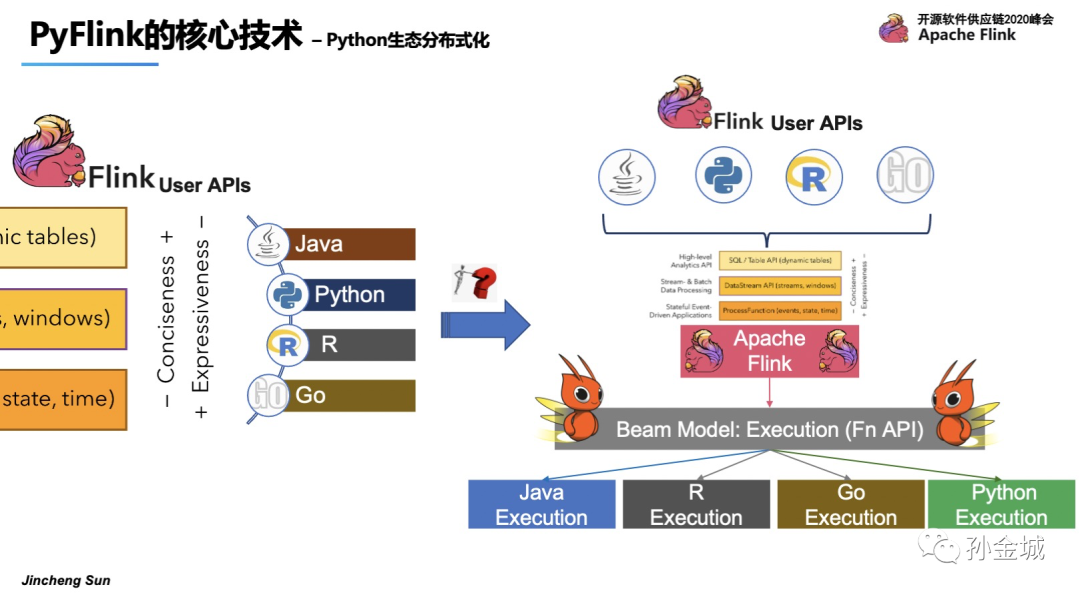
好,那么现在我们回答,Flink如何支持多语言呢?
在API层面,其他语言要搞定algin现有的Java语言API。
在语言的执行环境问题上面,Flink可以重用Beam提供的基础设施。换句话说,我们可以在Flink runner和fnapi级别上轻松地重用基本服务和数据结构。这将使Flink很容易支持多种语言。
下面的内容我们一起看看PyFlink的UDF架构设计。
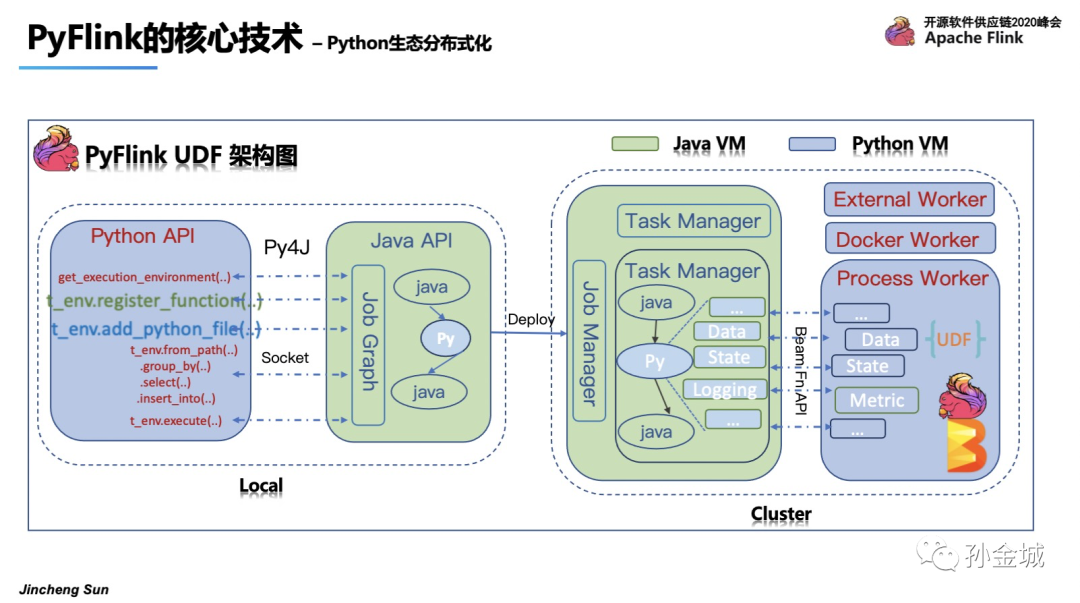
K,我们再整体看一下 PyFlink UDF的整体架构。在UDF的架构中我们我既要考虑Java VM和Python VM的通讯问题,又要考虑在编译阶段和在运行阶段的不同需求。
图中我们以绿色表示Java VM的行为,蓝色表示Python VM的行为。
首先我们看看编译阶段,也就是local的设计,在local的设计是纯API的mapping调用,我们仍然要过Py4J来解决通讯问题。也就是如图Python每执行一个API就会同步的调用Java所对应的API。对UDF的支持上,需要添加UDF注册的API,register_function,但仅仅是注册还不够,用户在自定义Python UDF的时候往往会依赖一些三方库,
所以我们还需要增加添加依赖的方法,那就是一系列的add方法,比如add_Python_file()。
在编写Python作业的同时,Java API也会同时被调用在提交作业之前,Java端会构建.JobGraph。然后通过CLI等多种方式将作业提交到集群进行运行。
我们再来看看运行时Python和Java的不同分工情况,首先在Java端与普通Java作业一样,JobMaster将作业分配给TaskManger,TaskManager会执行一个个Task,task里面就涉及到了Java和Python的算子执行。
在Python UDF的算子中我们会设计各种gRPC服务来完成Java VM和Python VM的各种通讯,比如 DataService 完成业务数据通讯,StateService完成Python UDF对Java Statebackend的调用,当然还有Logging和Metrics等其他服务。这些服务都是基于Beam的Fn API来构建的,最终在Python的Worker里面运行用户的UDF,运行结束之后再利用对应的gRPC服务将结果返回给Java端的PythonUDF算子。
当然Python的worker不仅仅是Process模式,可以是Docker模式甚至是External的服务集群。这种扩展机制,为后面PyFlink与Python生态的其他框架集成打下了坚实的基础。
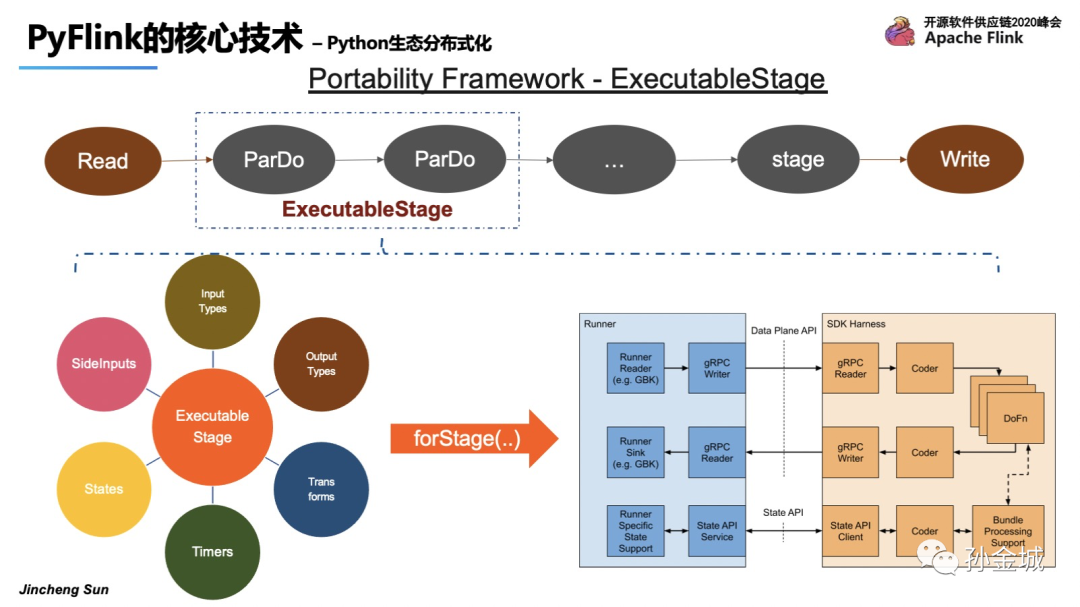
这里最重要的是如何使用beam的基础设施来执行Python UDF。我们来看看pyflink如何集成Beam的可移植性框架来执行Python UDF。一个场景的场景是对输入数据执行一系列转换并将结果写入另一个外部存储系统。我们知道Flink是用Java 开发的,但是,用户定义的转换逻辑是Python开发的。如图示例,假设ParDo使用了Python UDF,在Beam中引入了一个ExecutableStage,它包含了用户定义的Python函数的所有必要信息,如:输入/输出数据类型、用户定义函数的有效负载、用户定义函数中使用的状态和定时器等等。同时,Beam还提供了一个Java库,可用于管理特定语言的执行环境。”forStage()“将根据ExecutableStage中定义的信息生成执行用户定义函数所需的进程,就是SDK harness部分,这样建立runner与SDK Harness之间就建立起了通讯连接。

Beam的SDK harness支持执行多种功能,例如ParDo、Flatten等; 不同的函数有不同的执行模式,因此SDK harness定义了一个特定的操作类来执行它。但是我们怎样才能清楚地定义beam中每个函数的执行逻辑呢?Beam提供了非常灵活的插件机制,也就是为每种类型的函数定义一个URN,比如Input/output/parDo等。这样的插件机制也为Flink集成Beam框架提供了便利途径。
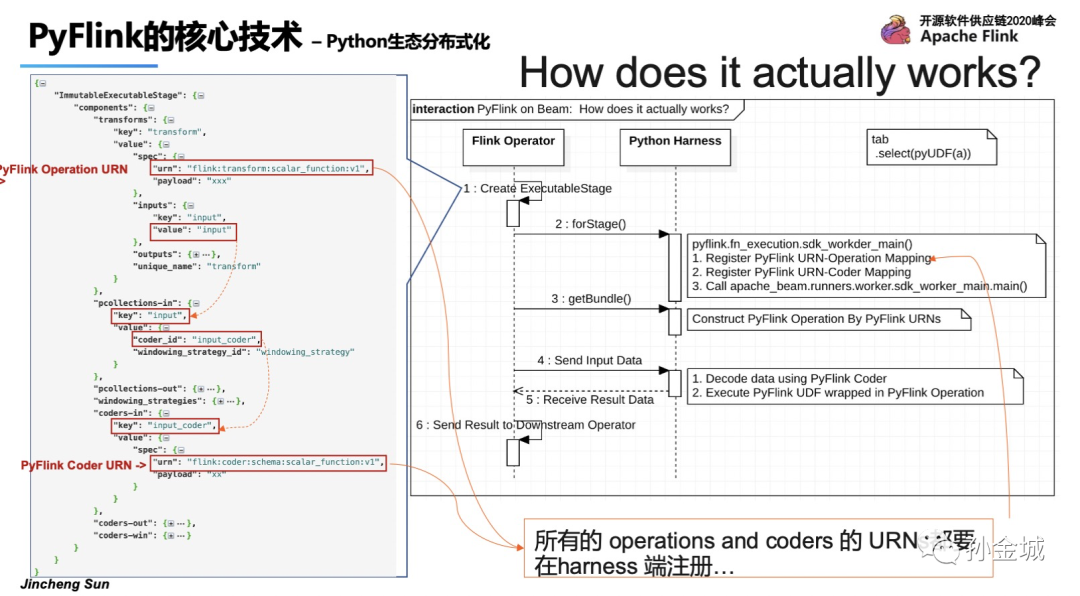
那么在PyFlink中使用Python SDK Harness的作原理如下:
在启动阶段,Python SDK Harness将为所有内置操作建立URN和操作映射。
在处理新包的初始化阶段,运行程序将把URN和函数一起发送到SDK Harness。SDK Harness可以根据给定的URN构造相应的操作。然后使用该操作来执行输入的数据和对应的用户定义函数逻辑。
我们看到如图我们定义各种URN,包括input/output,coder等等。

OK,那么注册URN也非常简单,就是我们添加了一些用于创建自定义操作和Coder的函数。这些函数用Beam的python sdk工具包中定义的decorator进行装饰。decorator包含两个参数:URN和一个基于protobuf的自定义参数。

OK,支持了Python UDF之后,我们还将Pandas的与PyFlink进行了集成,我们可以非常便利的在PyFlink中定义PandasUDF,同时我们还提供了frompandas和topandas的api支持Flink和Pandas间的操作转换。
同时我们在udf的执行性能上也不断的优化,在1.11的版本相对于1.10有30倍的性能提升。

OK,接下来我们快速看看PyFlink的未来规划。
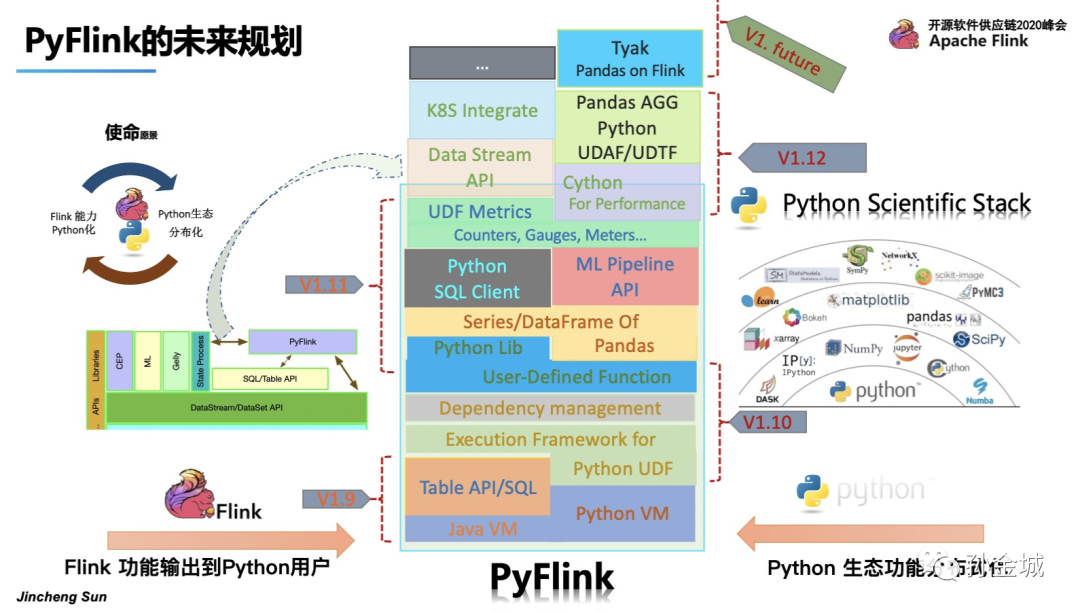
PyFlink的发展始终要以本心驱动,我们要围绕将现有Flink功能输出到Python用户,将Python生态功能集成到Flink当中为目标。
首先解决Python VM和Java VM的通讯问题,
然后将现有的Table API功能暴露给Python用户,提供Python Table API,
这也就是Flink 1.9中所进行的工作,
接下来我们要为将Python功能集成到Flink做准备就是集成Apache Beam,提供Python UDF的执行环境,
并增加Python 对其他类库依赖的管理功能,
为用户提供User-defined-Funciton的接口定义,支持Python UDF,
这就是Flink 1.10所做的工作。
为了进一步扩大Python生态的分布式功能,PyFlink将提供Pandas的Series和DataFram的支持,也就是用户可以在PyFlink中直接使用Pandas的UDF。
同时为增强用户的易用性,让用户有更多的方式使用PyFlink,后续增加在Sql Client中使用Python UDF。
面对Python用户的机器学习问题,增加Python 的 ML pipeline API。
监控Python UDF的执行情况对,对实际的生产业务非常关键,所以PyFlink会增加Python UDF的Metric管理. 这就是在Flink1.11中的工作。
同时我们还需要对性能不断有优化,对Datastream和已经k8s等提供支持,这些在PyFlink 1.12中提供给大家。
后续还会不断将Flink现有功能推向Python生态,将Python 生态的强大功能不断集成到Flink当中,进而完成Python生态分布化的初衷。
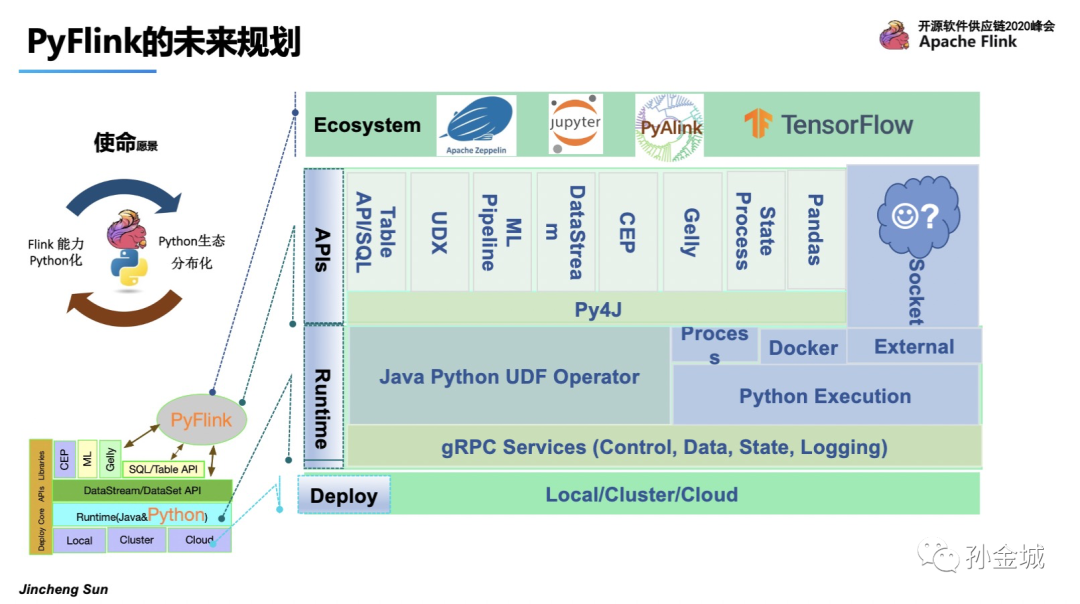
当然,PyFlink同样会注重生态的集成,如与Zeppelin,jupyter,PyAlink等集成工作的推进。

最后,快速看一下PyFlink的应用案例。

PyFlink可以应用在事件驱动/数据分析/ETL/机器学习等多种场景中。目前也有很多的投产用户。
比如,比特币大陆,聚美优品等等。目前PyFlink已经趋于成熟,非常适合大家选择Flink快速构建分布式计算系统的切入开发语言。

目前PyFlink功能趋于完备,当然也会有更多的工作要做,但无论如何,我相信后续会慢慢成熟起来!我将会在2020年12月份开始将精力投入到IoT领域,开启一段新的探索~
作者介绍
孙金城,51CTO社区编辑,Apache Flink PMC 成员,Apache Beam Committer,Apache IoTDB PMC 成员,ALC Beijing 成员,Apache ShenYu 导师,Apache 软件基金会成员。关注技术领域流计算和时序数据存储。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


