
Yann LeCun开怼谷歌研究:目标传播早就有了,你们创新在哪里?
日前,学术圈图灵奖得主Yann LeCun对谷歌的一项研究发起了质疑。
前段时间,谷歌 AI在其新研究《LocoProp: Enhancing BackProp via Local Loss Optimization》中提出了一种用于多层神经网络的通用层级损失构造框架LocoProp,该框架在仅使用一阶优化器的同时实现了接近二阶方法的性能。
更具体来讲,该框架将一个神经网络重新构想为多层的模块化组合,其中每个层都使用自己的权重正则化器、目标输出和损失函数,最终同时实现了性能和效率。
谷歌在基准模型和数据集上实验验证了其方法的有效性,缩小了一阶和二阶优化器之间的差距。此外,谷歌研究者表示他们的局部损失构造方法是首次将平方损失用作局部损失。

图源:@Google AI
对于谷歌的这项研究,一些人的评价是棒极了、有趣。不过,也有一些人表达出了不同的看法,其中包括图灵奖得主Yann LeCun。
他认为,我们现在称为目标传播(target prop)的版本有很多,有些可以追溯至1986年。所以,谷歌的这个LocoProp与它们有什么区别呢?
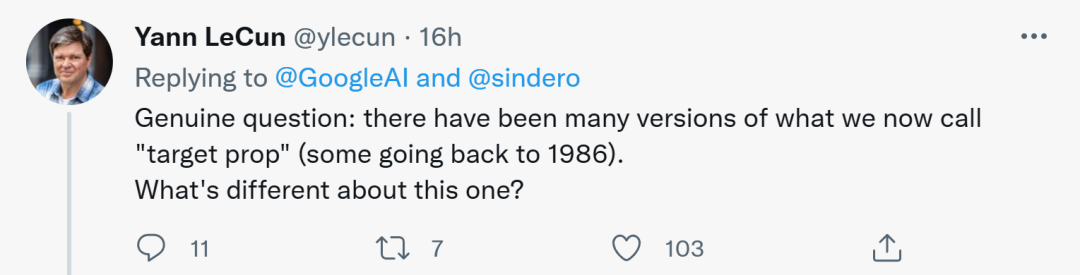
图源:@Yann LeCun
对于LeCun的这种疑问,即将成为UIUC助理教授的Haohan Wang表示赞同。他表示,有时真的惊讶为什么有些作者认为这么简单的想法是历史首创。或许他们做出了一些与众不同的事情,但宣传团队却迫不及待地出来声称一切……
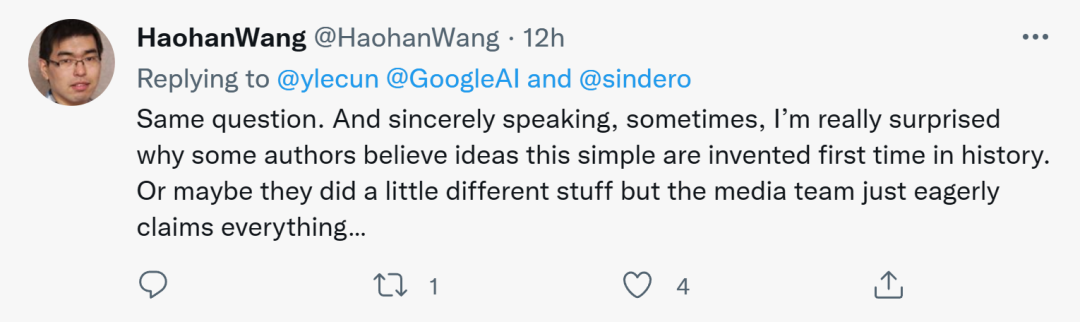
图源:@HaohanWang
不过,有人对 LeCun「不感冒」,认为他是出于竞争的考虑提出疑问,甚至「引战」。LeCun 对此进行了回复,声称自已的疑问无关竞争,并举例自己实验室的前成员Marc’Aurelio Ranzato、Karol Gregor、koray kavukcuoglu等都曾使用过一些版本的目标传播,如今他们都在谷歌DeepMind工作。
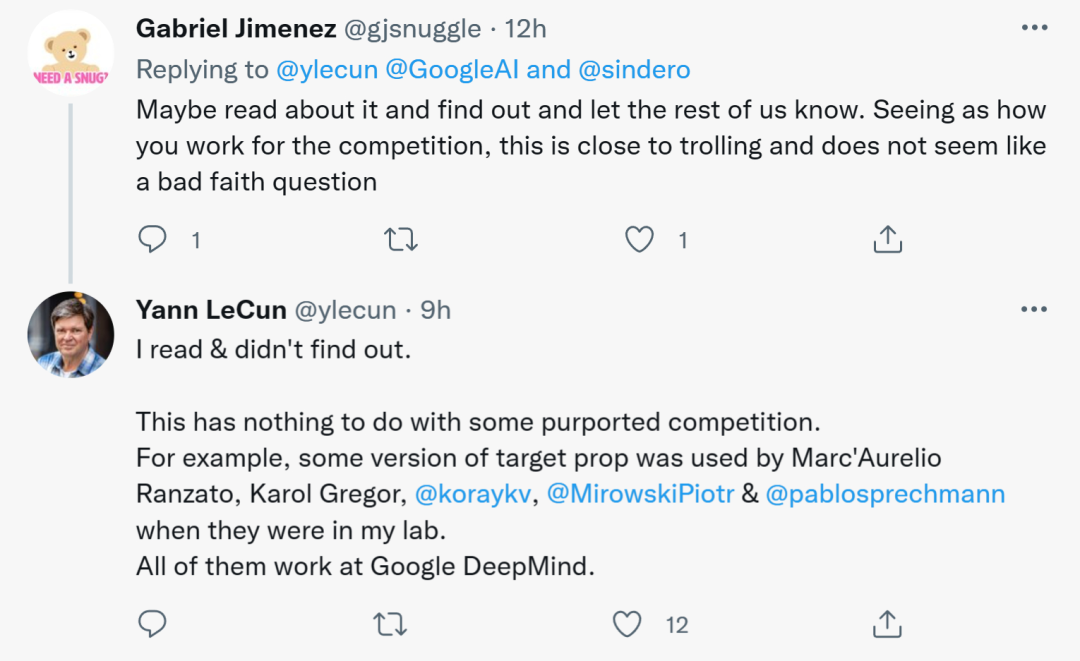
图源:@Gabriel Jimenez@Yann LeCun
更有人调侃起了Yann LeCun,「当无法击败Jürgen Schmidhuber,就成为他吧。」
Yann LeCun到底说的对不对呢?我们先来看谷歌这项研究到底讲了啥,有没有突出创新呢?
谷歌LocoProp:用局部损失优化增强反向传播
这项研究由来自谷歌的 Ehsan Amid 、 Rohan Anil、 Manfred K. Warmuth 三位研究者合作完成。

论文地址:https://proceedings.mlr.press/v151/amid22a/amid22a.pdf
本文认为,深度神经网络(DNN)成功的关键因素有两个:模型设计和训练数据,但很少有研究者讨论更新模型参数的优化方法。我们在训练训练DNN时涉及最小化损失函数,该函数用来预测真实值和模型预测值之间的差异,并用反向传播进行参数更新。
最简单的权值更新方法是随机梯度下降,即在每一个step中,权值相对于梯度负方向移动。此外,还有高级的优化方法,如动量优化器、AdaGrad等。这些优化器通常被称为一阶方法,因为它们通常只使用一阶导数的信息来修改更新方向。
还有更高级的优化方法如Shampoo 、K-FAC等已被证明可以提高收敛性,减少迭代次数,这些方法能够捕获梯度的变化。利用这些额外的信息,高阶优化器可以通过考虑不同参数组之间的相关性来发现训练模型更有效的更新方向。缺点是,计算高阶更新方向比一阶更新在计算上更昂贵。
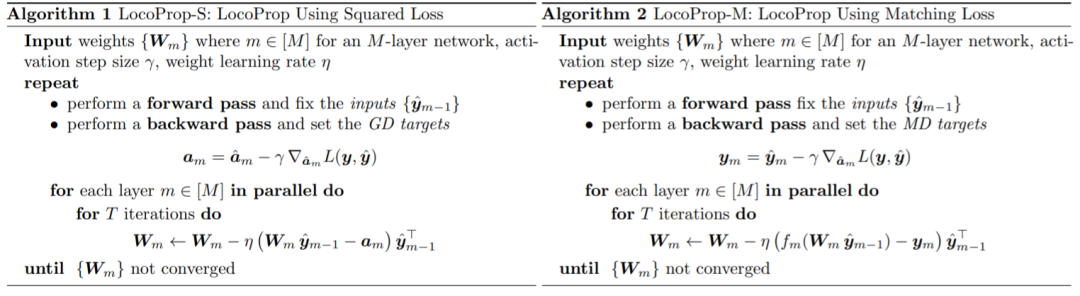
谷歌在论文中引入了一个训练DNN模型的框架:LocoProp,其将神经网络构想为层的模块化组合。一般来说,神经网络的每一层对输入进行线性变换,然后是非线性的激活函数。在该研究中,网络每一层被分配了自己的权重正则化器、输出目标和损失函数。每一层的损失函数被设计成与该层的激活函数相匹配。使用这种形式,训练给定的小batch局部损失可以降到最低,在各层之间迭代并行地进行。
谷歌使用这种一阶优化器进行参数更新,从而避免了高阶优化器所需的计算成本。
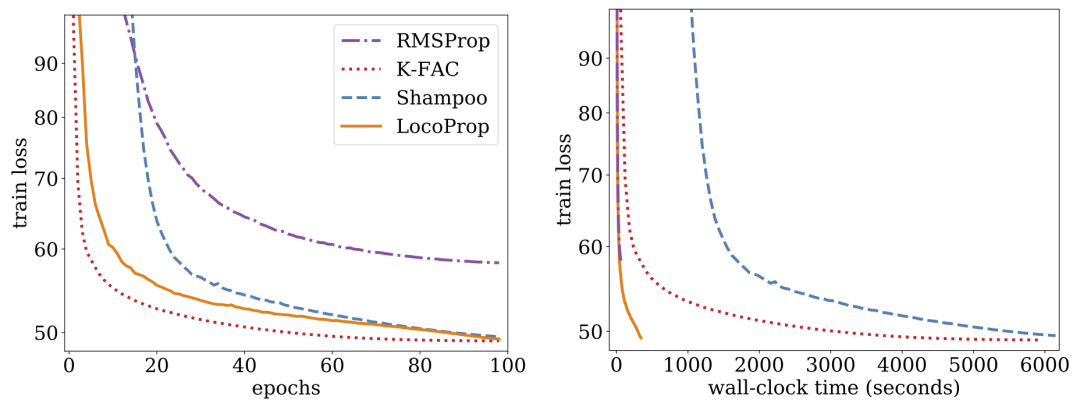
研究表明 LocoProp 在深度自动编码器基准测试中优于一阶方法,并且在没有高内存和计算要求的情况下与高阶优化器(如 Shampoo 和 K-FAC)性能相当。
LocoProp:通过局部损失优化增强反向传播
通常神经网络被视为复合函数,其将每一层的输入转换为输出表示。LocoProp 在将网络分解为层时采用了这种观点。特别是,LocoProp 不是更新层的权重以最小化输出的损失函数,而是应用特定于每一层的预定义局部损失函数。对于给定的层,选择损失函数以匹配激活函数,例如,将为具有 tanh 激活的层选择 tanh 损失。此外,正则化项确保更新后的权重不会偏离当前值太远。

与反向传播类似,LocoProp应用前向传递来计算激活。在反向传递中,LocoProp为每一层的的神经元设置目标。最后,LocoProp将模型训练分解为跨层的独立问题,其中多个局部更新可以并行应用于每层的权值。
谷歌在深度自动编码器模型中进行了实验,这是评估优化算法性能的常用基准。他们对多个常用的一阶优化器进行广泛的优化,包括 SGD、具有动量的SGD 、AdaGrad、RMSProp、Adam,以及高阶优化器,包括Shampoo 、K-FAC,并将结果与LocoProp比较。研究结果表明,LocoProp方法的性能明显优于一阶优化器,与高阶优化器相当,同时在单个GPU上运行时速度明显更快。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


