
以Transformer为核心的自回归注意力类程序始终难以跨过规模化这道难关。为此,DeepMind/谷歌最近建立新项目,提出一种帮助这类程序有效瘦身的好办法。
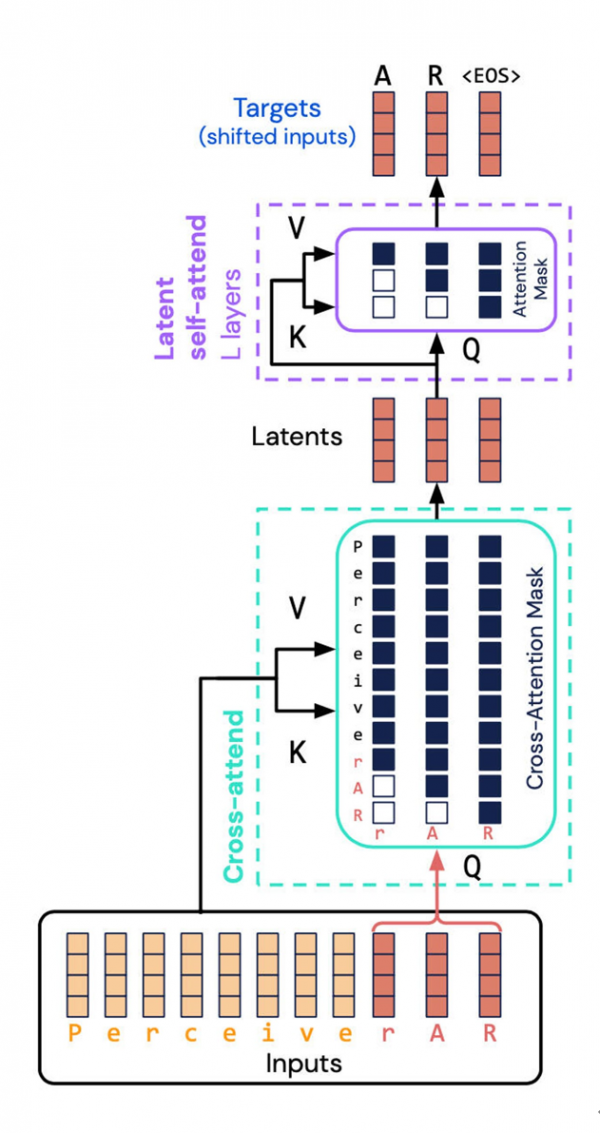
DeepMind与Google Brain打造的Perceiver AR架构回避了一大严重占用资源的任务——将输入与输出的组合性质计算至潜在空间。相反,他们向潜在空间引入了“因果掩蔽”,由此实现了典型Transformer的自回归顺序。
人工智能/深度学习领域最令人印象深刻的发展趋势之一,就是模型体量越来越大。该领域的专家表示,由于规模往往与效能直接挂钩,所以这股体量膨胀的浪潮恐怕还将持续下去。
但项目规模越来越大,消耗的资源自然也越来越多,这就导致深度学习引发了社会伦理层面的新问题。这一困境,已经得到《自然》等主流科学期刊的关注。
也正因为如此,我们恐怕又要回归“效率”这个老字眼——AI程序,到底还没有进一步提效的空间?
DeepMind及Google Brain部门的科学家们,最近对自己去年推出的神经网络Perceiver进行了一番改造,希望能提升其对算力资源的使用效率。
新程序被命名为Perceiver AR。这里的AR源自自回归“autoregressive”,也是如今越来越多深度学习程序的又一发展方向。自回归是一种让机器将输出作为程序新输入的技术,属于递归操作,借此构成多个元素相互关联的注意力图。
谷歌在2017年推出的大受欢迎的神经网络Transformer,也同样具有这种自回归特性。事实上,后来出现的GPT-3以及Perceiver的首个版本都延续了自回归的技术路线。
在Perceiver AR之前,今年3月推出的Perceiver IO是Perceiver的第二个版本,再向前追溯就是去年这个时候发布的Perceiver初版了。
最初的Perceiver创新点,在于采用Transformer并做出调整,使其能够灵活吸纳各种输入,包括文本、声音和图像,由此脱离对特定类型输入的依赖。如此一来,研究人员即可利用多种输入类型开发相应的神经网络。
作为时代大潮中的一员,Perceiver跟其他模型项目一样,也都开始使用自回归注意力机制将不同输入模式和不同任务域混合起来。此类用例还包括谷歌的Pathways、DeepMind的Gato,以及Meta的data2vec。
到今年3月,初版Perceiver的缔造者Andrew Jaegle及其同事团队又发布了“IO”版本。新版本增强了Perceiver所支持的输出类型,实现了包含多种结构的大量输出,具体涵盖文本语言、光流场、视听序列乃至符号无序集等等。Perceiver IO甚至能够生成《星际争霸2》游戏中的操作指令。
在这次的最新论文中,Perceiver AR已经能够面向长上下文实现通用自回归建模。但在研究当中,Jaegle及其团队也遇到了新的挑战:模型应对各类多模式输入和输出任务时,该如何实现扩展。
问题在于,Transformer的自回归质量,以及任何同样构建输入到输出注意力图的程序,都需要包含多达数十万个元素的巨量分布规模。
这就是注意力机制的致命弱点所在。更准确地说,需要关注一切才能建立起注意力图的概率分布。
正如Jaegle及其团队在论文中提到,当输入当中需要相互比较的事物数量的增加,模型对算力资源的吞噬也将愈发夸张:
这种长上下文结构与Transformer的计算特性之间相互冲突。Transformers会反复对输入执行自注意力操作,这会导致计算需求同时随输入长度而二次增长,并随模型深度而线性增加。输入数据越多,观察数据内容所对应的输入标记就越多,输入数据中的模式也变得愈发微妙且复杂,必须用更深的层对所产生的模式进行建模。而由于算力有限,因此Transformer用户被迫要么截断模型输入(防止观察到更多远距模式),要么限制模型的深度(也就剥夺了它对复杂模式进行建模时的表达能力)。
实际上,初版Perceiver也曾经尝试过提高Transformers的效率:不直接执行注意力,而是对输入的潜在表示执行注意力。如此一来,即可“(解耦)处理大型输入数组的算力要求同大深度网络所对应的算力要求”。
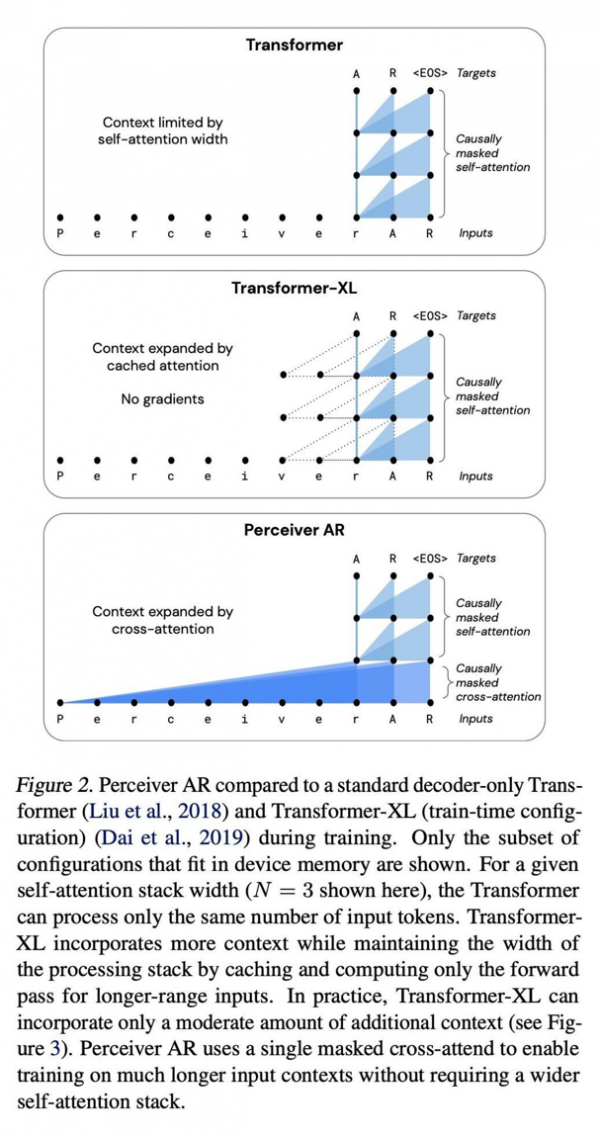
Perceiver AR与标准Transformer深度网络、增强型Transformer XL间的比较。
在潜在部分中,输入表示经过了压缩,因此成为一种效率更高的注意力引擎。这样,“对于深度网络,大部分计算就实际发生在自注意力堆栈上”,而无需对无数输入执行操作。
但挑战仍然存在,因为潜在表示不具备顺序概念,所以Perceiver无法像Transformer那样生成输出。而顺序在自回归中至关重要,每个输出都应该是它之前输入的产物,而非之后的产物。
研究人员们写道,“但由于每个潜在模型都关注所有输入,而不管其位置如何,所以对于要求每个模型输出必须仅依赖其之前输入的自回归生成来说,Perceiver将无法直接适用。”
而到了Perceiver AR这边,研究团队更进一步,将顺序插入至Perceiver当中,使其能够实现自动回归功能。
这里的关键,就是对输入和潜在表示执行所谓“因果掩蔽”。在输入侧,因果掩蔽会执行“交叉注意”,而在潜在表示这边则强制要求程序只关注给定符号之前的事物。这种方法恢复了Transformer的有向性,且仍能显著降低计算总量。
结果就是,Perceiver AR能够基于更多输入实现与Transformer相当的建模结果,但性能得以极大提高。
他们写道,“Perceiver AR可以在合成复制任务中,完美识别并学习相距至少 100k个标记的长上下文模式。”相比之下,Transformer的硬限制为2048个标记,标记越多则上下文越长,程序输出也就越复杂。
与广泛使用纯解码器的Transformer和Transformer-XL架构相比,Perceiver AR的效率更高,而且能够根据目标预算灵活改变测试时实际使用的算力资源。
论文写道,在同等注意力条件下,计算Perceiver AR的挂钟时间要明显更短,且能够要同等算力预算下吸纳更多上下文(即更多输入符号):
Transformer的上下文长度限制为2048个标记,相当于只支持6个层——因为更大的模型和更长的上下文需要占用巨量内存。使用同样的6层配置,我们可以将Transformer-XL内存的总上下文长度扩展至8192个标记。Perceiver AR则可将上下文长度扩展至65k个标记,如果配合进一步优化,甚至有望突破100k。
所有这一切,都令计算变得更加灵活:“我们能够更好地控制给定模型在测试过程中产生的计算量,并使我们能够在速度与性能间稳定求取平衡。”
Jaegle及其同事还写道,这种方法适用于任意输入类型,并不限于单词符号。例如可以支持图像中的像素:
只要应用了因果掩蔽技术,相同过程就适用于任何可以排序的输入。例如,通过对序列中每个像素的R、G、B颜色通道进行有序或乱序解码,即可按光栅扫描顺序为图像的RGB通道排序。
作者们发现Perceiver中蕴藏着巨大潜力,并在论文中写道,“Perceiver AR是长上下文通用型自回归模型的理想候选方案。”
但要想追求更高的计算效率,还需要解决另一个额外的不稳定因素。作者们指出,最近研究界也在尝试通过“稀疏性”(即限制部分输入元素被赋予重要性的过程)来减少自回归注意力的算力需求。
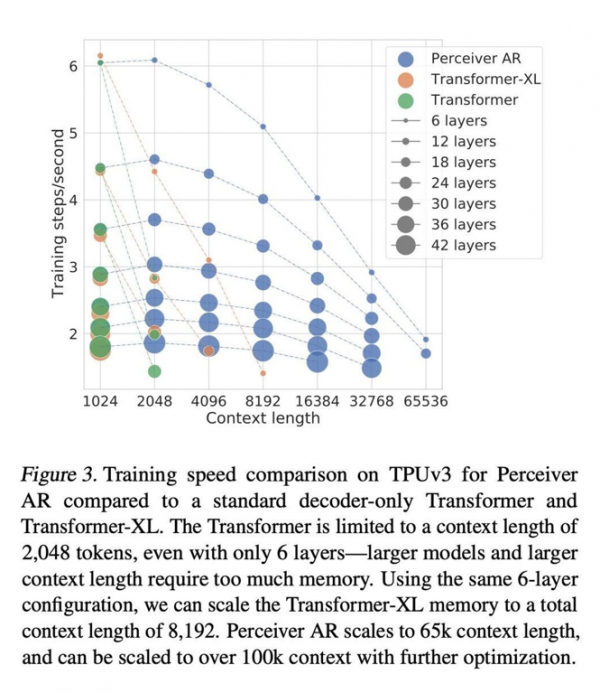
在相同的挂钟时间内,Perceiver AR能够在层数相同的情况下运行更多来自输入的符号,或者在输入符号运行数量相同的情况下显著缩短计算时长。作者认为,这种出色的灵活性有望为大型网络找到一种通用的提效方法。
但稀疏性也有自己的缺点,主要就是过于死板。论文写道,“使用稀疏性方法的缺点在于,必须以手动调整或者启发式方法创建这种稀疏性。这些启发式方法往往只适用于特定领域,而且往往很难调整。”OpenAI与英伟达在2019年发布的Sparse Transformer就属于稀疏性项目。
他们解释道,“相比之下,我们的工作并不需要在注意力层上强制手动创建稀疏模式,而是允许网络自主学习哪些长上下文输入更需要关注、更需要通过网络进行传播。”
论文还补充称,“最初的交叉注意力操作减少了序列中的位置数量,可以被视为一种稀疏学习形式。”
以这种方式学习到的稀疏性本身,也许会在未来几年内成为深度学习模型工具包中的又一强大利器。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


