
译者 | 布加迪
审校 | 孙淑娟
Imputer

如果您的数据集中有一些缺失值,您可能会删除缺失值行甚至列。强烈建议不使用这种方法,因为这会减少数据的大小,而且数据分析可能偏离事实。相反,我们应该使用不受缺失值影响的机器学习算法,或者使用Imputer来填充缺失的信息。
Imputer是用于填充数据集中缺失值的估算器。对于数值,它使用mean、median和constant。对于分类值,它使用most frequently used和constant value。您还可以训练模型来预测缺失的标签。
我们在该教程中将学习Scikit-learn的SimpleImputer、IterativeImputer和KNNImputer。我们还将创建一个管道来插补分类和数字特征,并将它们馈入到机器学习模型中。
如何使用Scikit-learn的Imputer?
scikit-learn的插补函数为我们提供了一个易于填充的选项,只需几行代码。我们可以整合这些Imputer,创建管道,以重现结果,并改进机器学习开发过程。
开始入手
我们将使用Deepnote环境,它类似Jupyter Notebook,不过在云端。
从Kaggle下载和解压缩数据。必须安装Kaggle Python软件包,并使用API下载spaceship-titanic 数据集。最后,将数据解压缩到数据集文件夹中。
%%capture
!pip install kaggle
!kaggle competitions download -c spaceship-titanic
!unzip -d ./dataset spaceship-titanic
接下来,我们将导入所需的Python软件包,用于数据摄取、插补和创建转换管道。
import numpy as np
import pandas as pd
from sklearn.impute import SimpleImputer
from sklearn.experimental import enable_iterative_Imputer
from sklearn.impute import IterativeImputer,KNNImputer
from sklearn.pipeline import FeatureUnion,make_pipeline,Pipeline
from sklearn.compose import ColumnTransformer
Spaceship Titanic数据集是Kaggle入门预测竞赛的一部分。它由训练、测试和提交CSV文件组成。我们将使用train.csv,它含有关于太空飞船的乘客信息。
pandas read_csv()函数读取train.csv,然后显示数据框。
df = pd.read_csv("dataset/train.csv")
df
图1
数据分析
我们在本节中将探索缺失值的列,但首先我们需要检查数据集的形状。它有8693行和14列。
df.shape
>>> (8693, 14)
我们现在将根据列显示缺失值计数和百分比。为了在数据框中显示它,我们将创建一个包含缺失值的新数据框,并将样式渐变应用于NA Count列。
NA = pd.DataFrame(data=[df.isna().sum().tolist(), ["{:.2f}".format(i)+'%' \
for i in (df.isna().sum()/df.shape[0]*100).tolist()]],
columns=df.columns, index=['NA Count', 'NA Percent']).transpose()
NA.style.background_gradient(cmap="Pastel1_r", subset=['NA Count'])
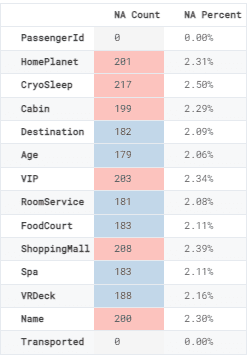
图2
除了PassengerID和Transported外,每一列都有缺失值。
数值插补
我们将使用缺失列中的信息,并将其分为分类列和数值列。我们以不同的方式对待它们。
若是数值插补,我们将选择Age列,并显示数字缺失值。它将帮助我们验证之前和之后的结果。
all_col = df.columns
cat_na = ['HomePlanet', 'CryoSleep','Destination','VIP']
num_na = ['Age','RoomService', 'FoodCourt', 'ShoppingMall', 'Spa', 'VRDeck']
data1 = df.copy()
data2 = df.copy()
data1['Age'].isna().sum()
>>> 179
data1.Age[0:5]
>>> 0 39.0
>>> 1 24.0
>>> 2 58.0
>>> 3 33.0
>>> 4 16.0
接下来,我们将使用sklearn的SimpleImputer,将其运用于Age列。它将用列的Average值替换缺失的数据。
正如我们所见,Age列中没有缺失值。
imp = SimpleImputer(strategy='mean')
data1['Age'] = imp.fit_transform(data1['Age'].values.reshape(-1, 1) )
data1['Age'].isna().sum()
>>> 0
如果是数值列,您可以使用constant、mean和median策略;如果是分类列,您可以使用most_frequent和constant策略。
分类插补
如果是分类插补,我们将使用包含201个缺失值的HomePlanet列。
data1['HomePlanet'].isna().sum()
>>> 201
data1.HomePlanet[0:5]
>>> 0 Europa
>>> 1 Earth
>>> 2 Europa
>>> 3 Europa
>>> 4 Earth
为了填充分类缺失值,我们将使用带有most_frequent策略的SimpleImputer。
mp = SimpleImputer(strategy="most_frequent")
data1['HomePlanet'] = imp.fit_transform(data1['HomePlanet'].values.reshape(-1, 1))
我们已经填充了HomePlanet列中的所有缺失值。
data1['HomePlanet'].isna().sum()
>>> 0
多变量Imputer
在单变量Imputer中,缺失值使用相同的特征来计算,而在多变量Imputer中,算法使用整个可用特征维度集来预测缺失值。
我们将一次性插补数值列;正如我们所见,它们都有150多个缺失值。
data2[num_na].isna().sum()
>>> Age 179
>>> RoomService 181
>>> FoodCourt 183
>>> ShoppingMall 208
>>> Spa 183
>>> VRDeck 188
我们将使用具有10 max_iter的IterativeImputer来估计和填充数值列中的缺失值。该算法将在进行值估计时考虑所有列。
imp = IterativeImputer(max_iter=10, random_state=0)
data2[num_na] = imp.fit_transform(data2[num_na])
data2[num_na].isna().sum()
>>> Age 0
>>> RoomService 0
>>> FoodCourt 0
>>> ShoppingMall 0
>>> Spa 0
>>> VRDeck 0
为机器学习插补分类和数值
为什么选择Scikit-learn的Imputer?除了Imputer外,该机器学习框架还提供特征转换、数据操作、管道和机器学习算法。它们都顺利整合。只需几行代码,您就可以对任何数据集进行插补、规范化、转换和训练模型。
我们在本节将学习如何将Imputer集成到机器学习项目中以获得更好的结果。
- 首先,我们将从sklearn导入相关函数。
- 然后,我们将删除不相关的列以创建X和Y变量。我们的目标列是“Transported”。
- 之后,我们将它们分成训练集和测试集。
from sklearn.preprocessing import LabelEncoder, StandardScaler, OrdinalEncoder
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
X,y = df.drop(['Transported','PassengerId','Name','Cabin'],axis = 1) , df['Transported']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=100, random_state=0)
要创建数值和分类转换数据管道,我们将使用sklearn的Pipeline函数。
如果是numeric_transformer,我们使用了:
- 具有2个n_neighbors和统一权重的KNNImputer。
- 在第二步中,我们使用了默认配置的StandardScaler。
如果是categorical_transformer,我们使用了:
- 具有most_frequent策略的SimpleImputer。
- 在第二步中,我们使用了OrdinalEncoder,将类别转换为数字。
numeric_transformer = Pipeline(steps=[
('Imputer', KNNImputer(n_neighbors=2, weights="uniform")),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('Imputer', SimpleImputer(strategy='most_frequent')),
('onehot', OrdinalEncoder())])
现在,我们将使用ColumnTransformer处理和转换训练特征。如果是numeric_transformer,我们为它提供了数值列列表;如果是categorical_transformer,我们将使用分类列列表。
注意:我们只是在准备管道和transformer。我们还没有处理任何数据。
preprocessor = ColumnTransformer(
remainder = 'passthrough',
transformers=[
('numeric', numeric_transformer, num_na),
('categorical', categorical_transformer, cat_na)
])
最后,我们将创建一个转换管道,含有processor和用于二进制分类任务的 DecisionTreeClassifier。该管道将先处理和转换数据,然后训练分类器模型。
transform = Pipeline(
steps=[
("processing", preprocessor),
("DecisionTreeClassifier", DecisionTreeClassifier()),
]
)
这时候神奇的一幕发生了。我们将在transform管道上拟合训练数据集。之后,我们将使用测试数据集评估我们的模型。
我们在默认配置下获得了75%的准确率。效果不错!
model = transform.fit(X_train,y_train)
model.score(X_test, y_test)
>>> 0.75
接下来,我们将对测试数据集进行预测,并创建结构化分类报告。
from sklearn.metrics import classification_report
prediction = model.predict(X_test)
print(classification_report(prediction, y_test))
正如我们所见,True类和False类有稳定的分数。
precision recall f1-score support
False 0.70 0.74 0.72 43
True 0.80 0.75 0.77 57
accuracy 0.75 100
macro avg 0.75 0.75 0.75 100
weighted avg 0.75 0.75 0.75 100
结论
为了获得更准确的数据,科学家们使用深度学习方法来插补缺失值。同样,您必须决定构建一个系统需要多少时间和资源,以及它带来什么价值。在大多数情况下,Scikit-learn的Imputers提供了更大的价值,我们只需要几行代码来插补整个数据集。
我们在这篇博文中了解了插补以及Scikit-learn库在估计缺失值方面的工作原理。我们还学习了单变量、多变量、分类和数值插补。我们在最后一部分使用了数据管道、列转换器和机器学习管道,以插补、转换、训练和评估我们的模型。
原文标题:Using Scikit-learn’s Imputer,作者:Abid Ali Awan
© 版权声明
文章版权归作者所有,未经允许请勿转载。


