
译者 | 朱先忠
审校 | 孙淑娟

红葡萄园(作者:Vincent van Gogh)
据《纽约时报》报道,数据中心90%的能源被浪费,这是因为公司收集的大部分数据从未被分析或以任何形式使用。更具体地说,这被称为“暗数据(Dark Data)”。
“暗数据”是指通过各种计算机网络操作获取的数据,但不以任何方式用于得出见解或进行决策。组织收集数据的能力可能超过其分析数据的吞吐量。在某些情况下,组织甚至可能不知道正在收集数据。IBM估计,大约90%的传感器和模数转换产生的数据从未被使用。——维基百科上的“暗数据”定义
从机器学习的角度来看,这些数据对于得出任何见解都没有用处的关键原因之一是缺乏标签。这使得无监督学习算法对于挖掘这些数据的潜力非常有吸引力。
生成对抗网络
2014年,Ian Goodfello等人提出了一种通过对抗过程估计生成模型的新方法。它涉及同时训练两个独立的模型:一个生成器模型试图建模数据分布,另一个鉴别器试图通过生成器将输入分类为训练数据或假数据。
该论文在现代机器学习领域树立了一块非常重要的里程碑,为无监督学习开辟了新的途径。2015年,深度卷积Radford等人发布的GAN论文通过应用卷积网络的原理成功地生成了2D图像,从而继续构建了论文中的这一思想。
通过本文,我试图解释上述论文中论述的关键组件,并使用PyTorch框架来实现它们。
GAN哪些地方引人注目?
为了理解GAN或DCGAN(深度卷积生成对抗网络:Deep Convolutional Generative Adversarial Networks)的重要性,首先让我们来了解一下是什么使它们如此流行。
1. 由于大部分真实数据未标记,GAN的无监督学习特性使其非常适合此类用例。
2. 生成器和鉴别器对于具有有限标记数据的用例起到非常好的特征提取器的作用,或者生成附加数据以改进二次模型训练,因为它们可以生成假样本而不是使用增强技术。
3. GANs提供了最大似然技术的替代方法。它们的对抗性学习过程和非启发式成本函数使得它们对强化学习非常有吸引力。
4. 关于GAN的研究非常有吸引力,其结果引起了关于ML/DL影响的广泛争论。例如,Deepfake是GAN的一种应用,它可以将人的面部覆盖在目标人身上,这在本质上是非常有争议的,因为它有可能被用于邪恶的目的。
5. 最后一点也是最重要的一点是,使用这种网络很酷,该领域的所有新研究都令人着迷。
整体架构
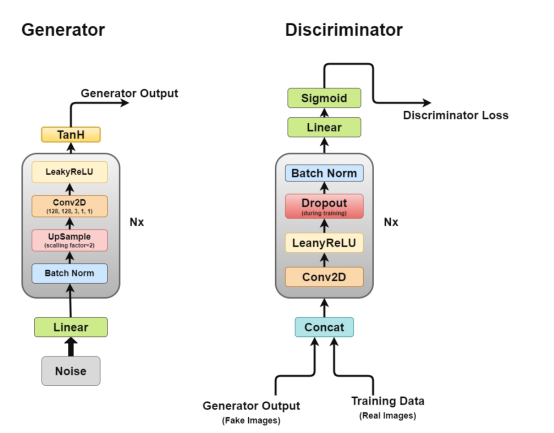
深度卷积GAN的架构
正如我们前面所讨论的,我们将通过DCGAN进行工作,DCGAN试图实现GAN的核心思想,用于生成逼真图像的卷积网络。
DCGAN由两个独立的模型组成:一个生成器(G)尝试将随机噪声向量建模为输入并尝试学习数据分布以生成假样本,另一个鉴别器(D)获取训练数据(真实样本)和生成的数据(假样本),并尝试对它们进行分类。这两种模型之间的斗争就是我们所说的对抗性训练过程,一方的损失是另一方的利益。
生成器
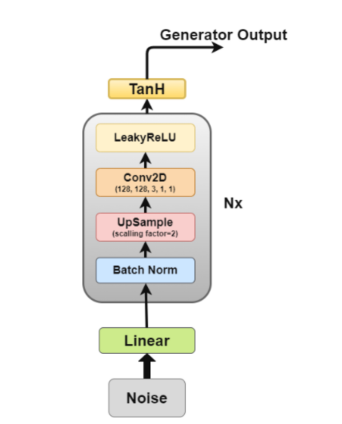
生成器架构图
生成器是我们最感兴趣的部分,因为它是一个生成假图像以试图欺骗鉴别器的生成器。
现在,让我们更详细地了解一下生成器的架构。
- 线性层:将噪声矢量输入到完全连接层中,然后将其输出变形为4D张量。
- 批量归一化层:通过将输入归一化为零均值和单位方差来稳定学习,这避免了梯度消失或爆炸等训练问题,并允许梯度流过网络。
- 上采样层:根据我对论文的解释,其中提到使用上采样(upsampling),然后在其上应用简单的卷积层,而不是使用卷积转置层进行上采样。但我见过一些人使用卷积转置,所以具体应用策略由你自己作决定。
- 二维卷积层:当我们对矩阵进行上采样时,我们以1的步长将其通过卷积层,并使用相同的填充,使其能够从上采样数据中学习。
- ReLU层:本文提到使用ReLU代替LeakyReLU作为生成器,因为它允许模型快速饱和并覆盖训练分布的颜色空间。
- TanH激活层:本文建议我们使用TanH激活函数来计算生成器输出,但没有详细说明为什么。如果我们不得不作一下猜测的话,这是因为TanH的性质允许模型更快收敛。
其中,层2至层5构成核心生成器块,可以重复N次以获得所需的输出图像形状。
下面是我们如何在PyTorch中实现它的关键代码(完整源码见地址https://github.com/akash-agni/ReadThePaper/blob/main/DCGAN/dcgan.py)。
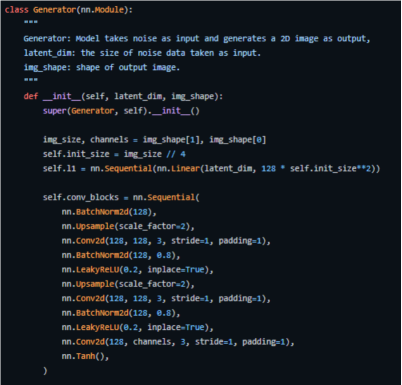
使用PyTorch框架的生成器实现关键代码
鉴别器
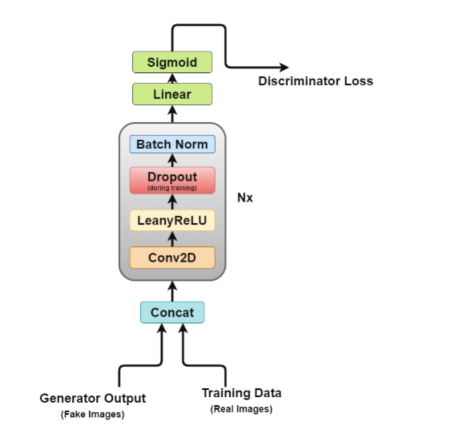
鉴别器架构图
从图中易见,鉴别器更像是一个图像分类网络,只是做了一些小的调整。例如,它没有使用任何池层进行下采样,而是使用了一种称为跨距卷积层(stride convolutional layer)的特殊卷积层,允许它学习自己的下采样。
下面,让我们更详细地了解一下鉴别器架构。
- Concat层:该层将假图像和真实图像组合在一个批次中,以提供给鉴别器,但这也可以单独完成,仅用于获得生成器损耗。
- 卷积层:我们在这里使用跨距卷积(stride convolution),它允许我们在一次训练中对图像进行下采样并学习滤波器。
- LeakyReLU层:正如论文所提到的,与原始GAN论文的最大输出函数相比,它发现Leakyrelus对于鉴别器非常有用,因为它允许更容易的训练。
- Dropout层:仅用于训练,有助于避免过度拟合。该模型有记忆真实图像数据的倾向,在这一点上训练可能崩溃,因为鉴别器不能再被生成器“愚弄”了。
- 批量归一化层:论文提到,它在每个鉴别器块(第一个除外)的末尾应用批量归一化。论文提到的原因是,在每个层上应用批量归一化会导致样本振荡和模型不稳定。
- 线性层:一个完全连接层,从通过应用的2D批次归一化层中获取一个重新定义形状的向量。
- Sigmoid激活层:因为我们正在处理鉴别器输出的二进制分类,所以做出了Sigmoidd层逻辑选择。
在该架构中,层2至层5构成鉴别器的核心块,可以重复N次计算以使模型对于每个训练数据更复杂。
下面是我们如何在PyTorch中实现它(完整源码见地址https://github.com/akash-agni/ReadThePaper/blob/main/DCGAN/dcgan.py)。
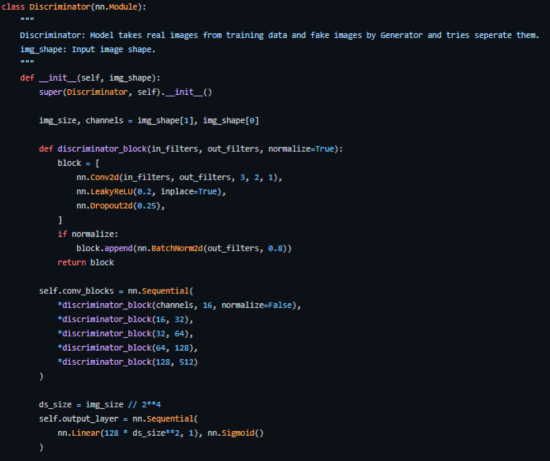
用PyTorch实现的鉴别器关键代码部分
对抗训练
我们训练鉴别器(D)以最大化将正确标签分配给训练样本和来自生成器(G)的样本的概率,这可以通过最小化log(D(x))来完成。我们同时训练G以最小化log(1 − D(G(z))),其中z代表噪声向量。换句话说,D和G都是使用值函数V (G, D)来玩以下两人极小极大博弈(two-player minimax game):
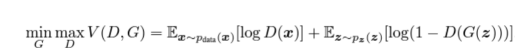
对抗性成本函数计算公式
在实际应用环境中,上述方程可能无法为G提供足够的梯度来很好地学习。在学习的早期,当G较差时,D可以以高置信度拒绝样本,因为它们与训练数据明显不同。在这种情况下,log(1 − D(G(z)))函数达到饱和。我们不是训练G以最小化log(1 − D(G(z))),而是训练G以最大化logD(G(z))。该目标函数能够生成动态G和D的相同的固定点,但在学习早期却提供了更强的梯度计算。——arxiv论文
由于我们同时训练两个模型,这可能会很棘手,而GAN是出了名的难以训练,我们将在后面讨论的已知问题之一称为模式崩溃(mode collapse)。
论文建议使用学习率为0.0002的Adam优化器,如此低的学习率表明GAN倾向于非常快地发散。它还使用值为0.5和0.999的一阶和二阶动量来进一步加速训练。模型初始化为正态加权分布,平均值为零,标准差为0.02。
下面展示的是我们如何为此实现一个训练循环(完整源码见https://github.com/akash-agni/ReadThePaper/blob/main/DCGAN/dcgan.py)。
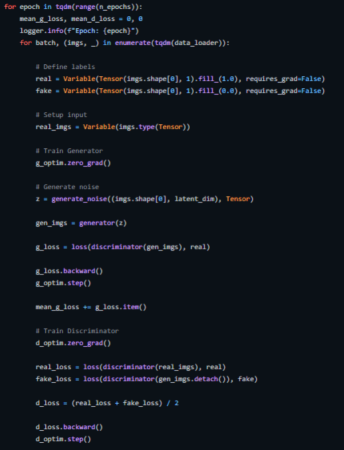
DCGAN的训练循环
模式崩溃(Mode Collapse)
理想情况下,我们希望生成器生成各种输出。例如,如果它生成人脸,它应该为每个随机输入生成一个新的人脸。但是,如果发生器产生足够好的似是而非的输出从而能够欺骗鉴别器的话,它可能会一次又一次地产生相同的输出。
最终,生成器会对单个鉴别器进行过度优化,并在一小组输出结果之间旋转(rotate),这种情况称为“模式崩溃”。
以下方法可用于纠正该情况。
- Wasserstein损失函数法(Wasserstein loss):Wasserstin损失函数通过让您将鉴别器训练到最优而无需担心梯度消失,从而减轻模式崩溃。如果鉴别器没有陷入局部极小值,它会学习拒绝生成器稳定的输出。因此,生成器必须尝试新的东西。
- 展开GAN法(Unrolled GANs):展开GAN使用生成器损失函数,该函数不仅包含当前鉴别器的分类,还包含未来鉴别器版本的输出。因此,生成器不能针对单个鉴别器进行过度优化。
应用
- 风格转换:面部修饰应用程序现在都在大肆宣传。其中,面部老化、哭脸和名人脸变形等只是当前社交媒体上已经广泛流行的一部分应用程序而已。
- 视频游戏:3D对象的纹理生成和基于图像的场景生成只是帮助视频游戏行业更快开发更大游戏的一部分应用程序。
- 电影行业:CGI(计算机合成图像)已经成为模型电影的一大组成部分,凭借GAN带来的潜力,电影制作人现在可以实现比以往更大的梦想。
- 语音生成:一些公司正在使用GAN来改进文本到语音的应用,通过使用它们来生成更真实的语音。
- 图像恢复:使用GANs对受损图像进行去噪和恢复,对历史图像进行着色,并通过生成缺失帧来改进旧视频,以提高帧率。
结论
总之,本文上面提到的有关GAN和DCGAN的论文简直称的上是一篇里程碑式的论文,因为它在无监督学习方面开辟了一条新的途径。其中提出的对抗式训练方法为训练模型提供了一种新的方法,该模型紧密模拟真实世界的学习过程。因此,了解一下这个领域是如何发展的将是一件非常有趣的事情。
最后,您可以在我的GitHub源码仓库上找到本文示例工程完整的实现源码。
译者介绍
朱先忠,51CTO社区编辑,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Implementing Deep Convolutional GAN,作者:Akash Agnihotri
© 版权声明
文章版权归作者所有,未经允许请勿转载。


