
我们将使用lazypredict库,它允许我们只用一行代码在我们的数据集上实现许多机器学习模型,本文将演示lazypredict的快速使用。
步骤1、使用以下命令安装lazypredict 库:
pip install lazypredict
步骤2、导入pandas库,以加载我们的机器学习数据集。
数据集链接:https ://raw.githubusercontent.com/tirthajyoti/Machine-Learning-with-Python/master/Datasets/Mall_Customers.csv
import pandas as pd
df=pd.read_csv("Mall_Customers.csv")
步骤3、查看机器学习数据集前几行。
df.head()
步骤4、拆分训练集和测试集。这里 Y 变量是 Spending Score 列,而其余列是 X 变量。
from sklearn.model_selection import train_test_split
x=df.loc[:,df.columns!='Spending Score (1-100)']
y=df['Spending Score (1-100)']
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3)
步骤5、让我们导入之前安装的lazypredict库,lazypredict里面有两个类,一个是Classification类,一个是Regression类。
import lazypredict
from lazypredict.Supervised import LazyRegressor
from lazypredict.Supervised import LazyClassifier
导入后,我们将使用 LazyRegressor,因为我们正在处理回归问题,如果您处理的分类问题,这两种类型的问题都需要类似的步骤。
multiple_ML_model=LazyRegressor(verbose=0,ignore_warnings=True,predictions=True)
models,predictions=multiple_ML_model.fit(x_train,x_test,y_train,y_test)
在这里,prediction = True意味着您想要获得每个模型的准确性并想要对每个模型进行预测。
模型的变量包含每个模型的准确度,以及其他一些重要的信息。
models
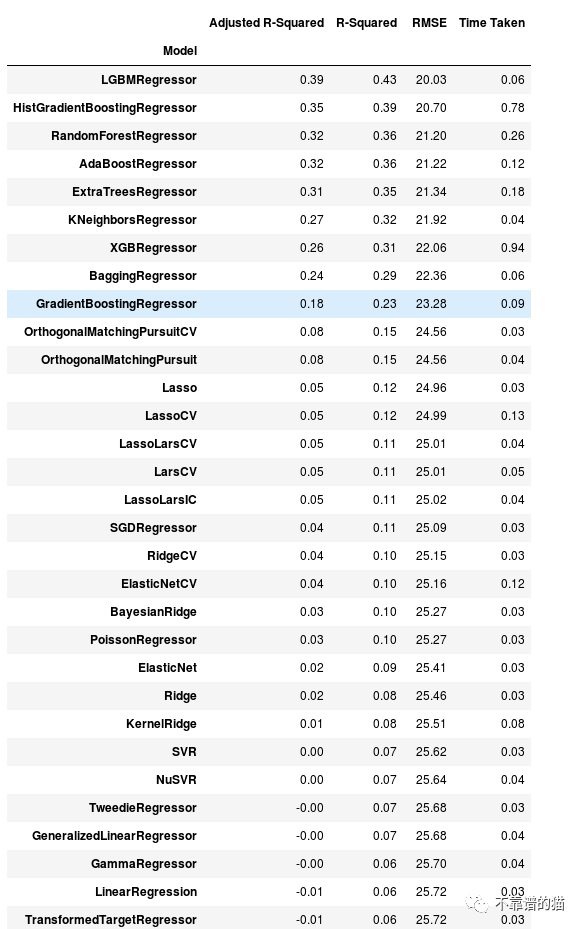
如您所见,它已经在我的回归问题上实现了42 个 机器学习模型,本指南更侧重于如何测试许多模型而不是提高它们的准确性。
查看每个机器学习模型的预测如下:
predictions
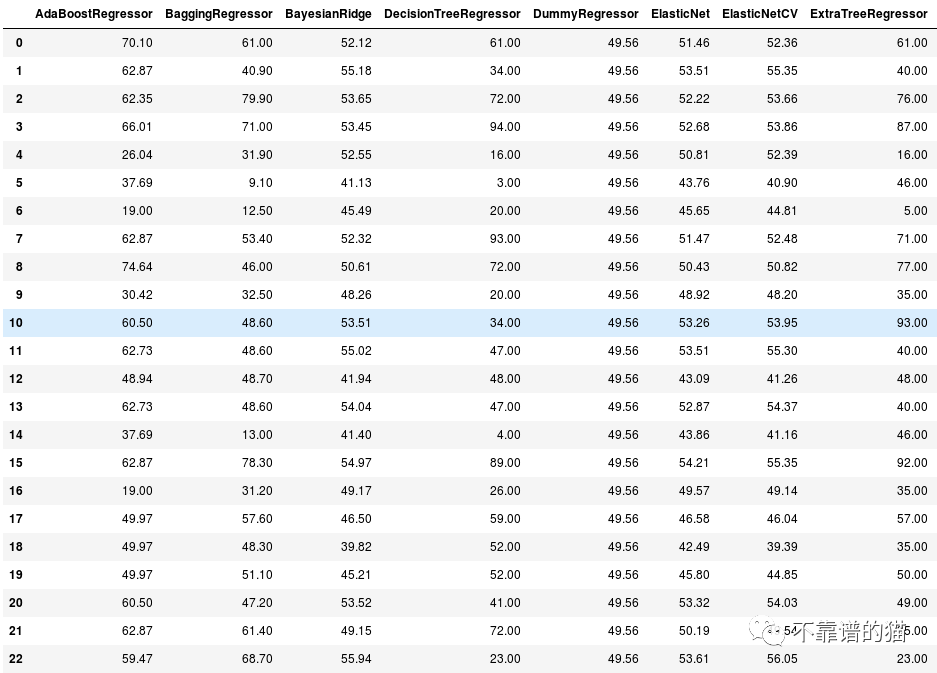
您可以使用这些预测来创建混淆矩阵。
如果您正在处理分类问题,这就是您使用lazypredict 库的方式。
multiple_ML_model=LazyClassifier(verbose=0,ignore_warnings=True,predictions=True)
models,predictions=multiple_ML_model.fit(x_train,x_test,y_train,y_test)
要记住的关键点:
- 该库仅用于测试目的,为您提供有关哪种模型在您的数据集上表现良好的信息。
- 因为我将要使用的库需要的是特定版本,所以建议使用一个单独环境。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


