
在文本转图像上卷了大半年之后,Meta、谷歌等科技巨头又将目光投向了一个新的战场:文本转视频。
上周,Meta 公布了一个能够生成高质量短视频的工具——Make-A-Video,利用这款工具生成的视频非常具有想象力。

当然,谷歌也不甘示弱。刚刚,该公司 CEO Sundar Pichai 亲自安利了他们在这一领域的最新成果:两款文本转视频工具——Imagen Video 与 Phenaki。前者主打视频品质,后者主要挑战视频长度,可以说各有千秋。

下面这个洗盘子的泰迪熊就是用 Imagen Video 生成的,可以看到,画面的分辨率和连贯性都有一定的保障。

Imagen Video:给出文本提示,生成高清视频
生成式建模在最近的文本到图像 AI 系统中取得了重大进展,比如 DALL-E 2、Imagen、Parti、CogView 和 Latent Diffusion。特别地,扩散模型在密度估计、文本到语音、图像到图像、文本到图像和 3D 合成等多种生成式建模任务中取得了巨大成功。
谷歌想要做的是从文本生成视频。以往的视频生成工作集中于具有自回归模型的受限数据集、具有自回归先验的潜变量模型以及近来的非自回归潜变量方法。扩散模型也已经展示出了出色的中等分辨率视频生成能力。
在此基础上,谷歌推出了 Imagen Video,它是一个基于级联视频扩散模型的文本条件视频生成系统。给出文本提示,Imagen Video 就可以通过一个由 frozen T5 文本编码器、基础视频生成模型、级联时空视频超分辨率模型组成的系统来生成高清视频。

论文地址:https://imagen.research.google/video/paper.pdf
在论文中,谷歌详细描述了如何将该系统扩展为一个高清文本转视频模型,包括某些分辨率下选择全卷积时空超分辨率模型以及选择扩散模型的 v 参数化等设计决策。谷歌还将以往基于扩散的图像生成研究成果成功迁移到了视频生成设置中。
谷歌发现,Imagen Video 能够将以往工作生成的 24fps 64 帧 128×128 视频提升至 128 帧 1280×768 高清视频。此外,Imagen Video 还具有高度的可控性和世界知识,能够生成多样化艺术风格的视频和文本动画,还具备了 3D 对象理解能力。
让我们再来欣赏一些 Imagen Video 生成的视频,比如开车的熊猫:

遨游太空的木船:

更多生成视频请参阅:https://imagen.research.google/video/
方法与实验
整体而言,谷歌的视频生成框架是七个子视频扩散模型的级联,它们相应执行文本条件视频生成、空间超分辨率和时间超分辨率。借助整个级联,Imagen Video 能够以每秒 24 帧的速度生成 128 帧 1280×768 的高清视频(约 1.26 亿像素)。
与此同时,在渐进式蒸馏的帮助下,Imagen Video 的每个子模型中仅使用八个扩散步骤就能生成高质量视频。这将视频生成时间加快了大约 18 倍。
下图 6 展示了 Imagen Video 的整个级联 pipeline,包括 1 个 frozen 文本编码器、1 个基础视频扩散模型以及 3 个空间超分辨率(SSR)和 3 个时间超分辨率(TSR)模型。这七个视频扩散模型共有 116 亿参数。
在生成过程中,SSR 模型提高了所有输入帧的空间分辨率,同时 TSR 模型通过在输入帧之间填充中间帧来提高时间分辨率。所有模型同时生成一个完整的帧块,这样 SSR 模型不会遭受明显的伪影。
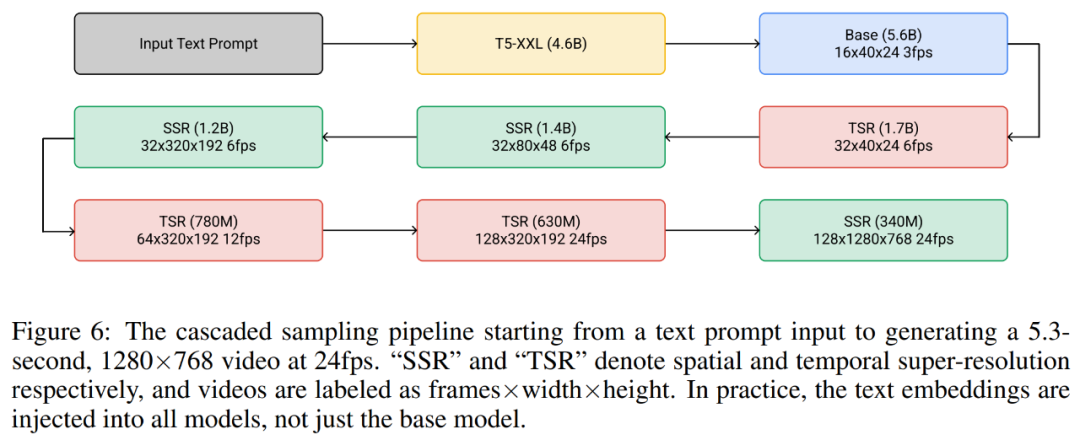
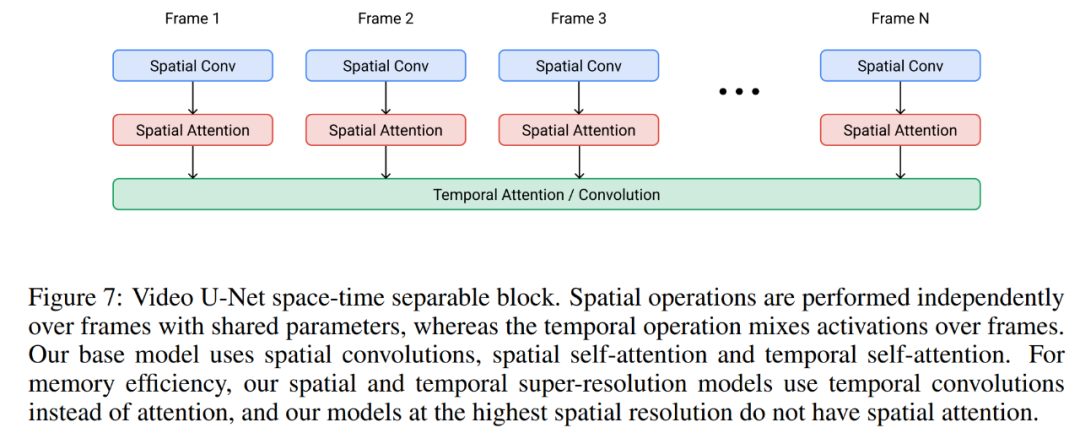
Imagen Video 构建在视频 U-Net 架构之上,具体如下图 7 所示。
在实验中,Imagen Video 在公开可用的 LAION-400M 图像文本数据集、1400 万个视频文本对和 6000 万个图像文本对上进行训练。结果正如上文所述,Imagen Video 不仅能够生成高清视频,还具备一些纯从数据中学习的非结构化生成模型所没有的独特功能。
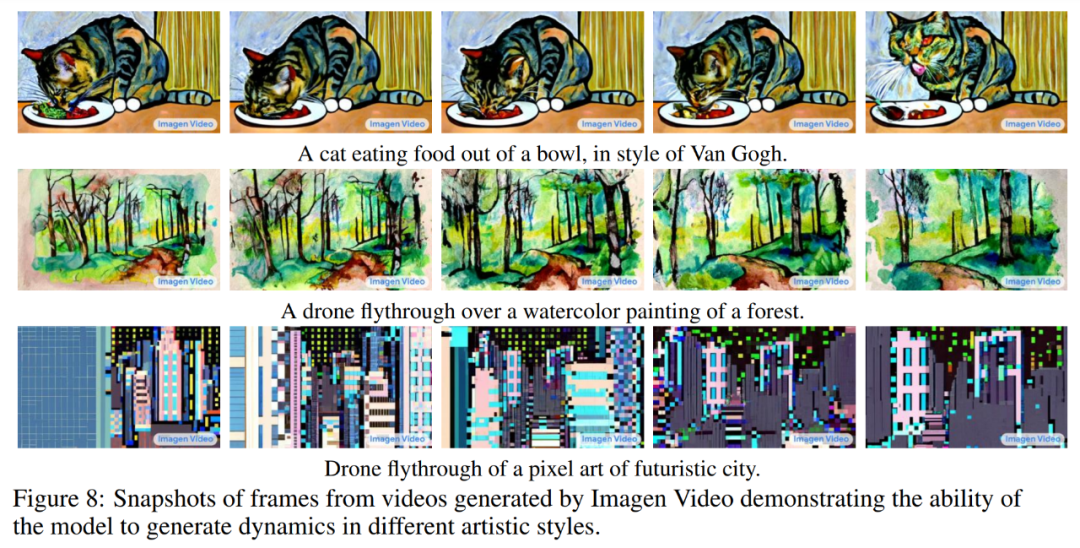
下图 8 展示了 Imagen Video 能够生成具有从图像信息中学得的艺术风格的视频,例如梵高绘画风格或水彩画风格的视频。
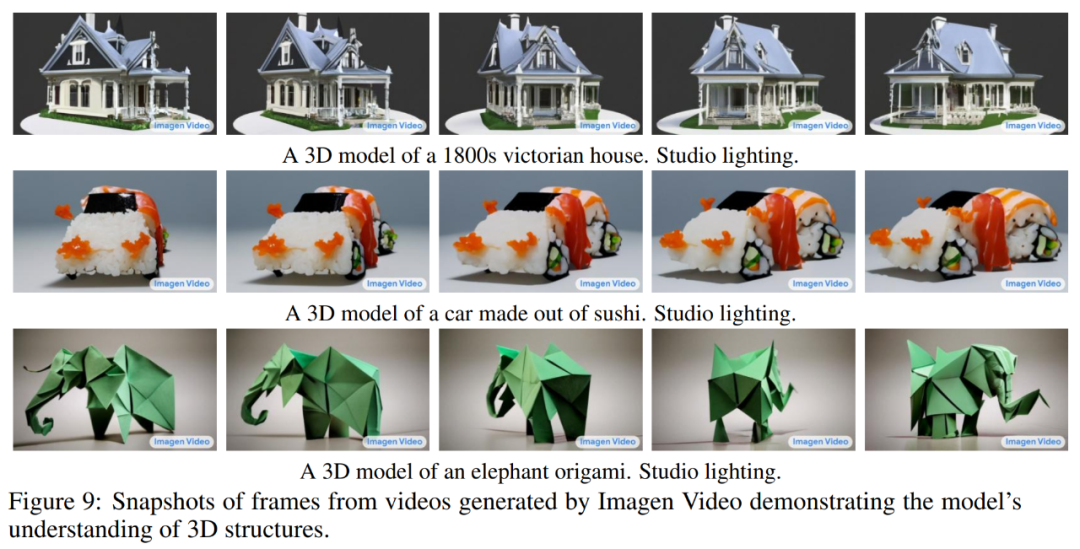
下图 9 展示了 Imagen Video 对 3D 结构的理解能力,它能够生成旋转对象的视频,同时物体的大致结构也能保留。
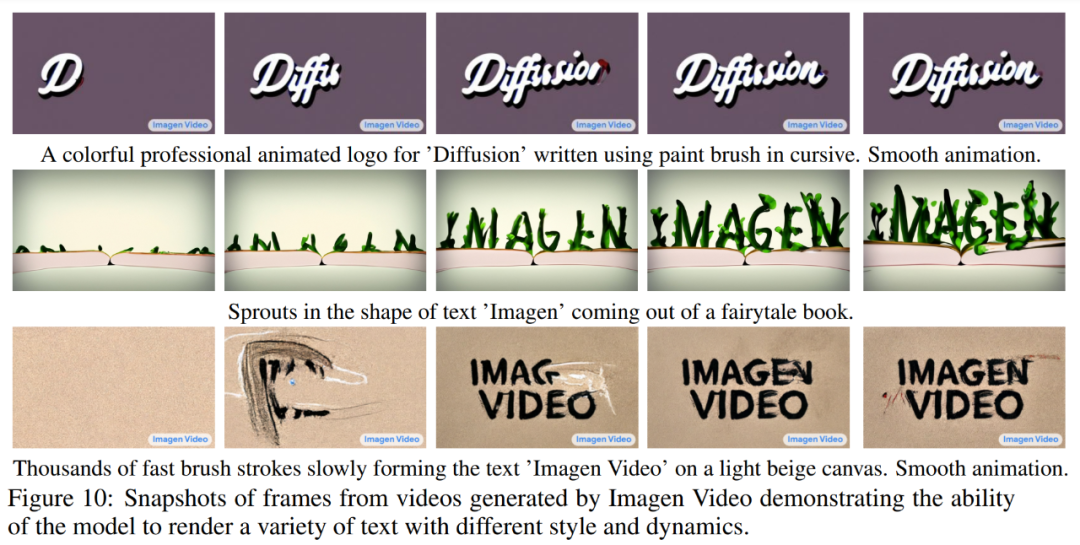
下图 10 展示了 Imagen Video 能够可靠地生成各种动画样式的文本,其中一些使用传统工具很难来制作。
更多实验细节请参阅原论文。
Phenaki:你讲故事我来画
我们知道,虽然从本质上讲,视频就是一系列图像,但生成一个连贯的长视频并没有那么容易,因为在这项任务中,可用的高质量数据非常少,而且任务本身的计算需求又很大。
更麻烦的是,像之前那种用于图像生成的简短文本 prompt 通常不足以提供对视频的完整描述,视频需要的是一系列 prompt 或故事。理想情况下,一个视频生成模型必须能够生成任意长度的视频,并且要能根据某个时刻 t 的 prompt 变化调节生成的视频帧。只有具备这样的能力,模型生成的作品才能称之为「视频」,而不是「移动的图像」,并开启在艺术、设计和内容创作方面的现实创意应用之路。
谷歌等机构的研究人员表示,「据我们所知,基于故事的条件视频生成之前从未被探索过,这是第一篇朝着该目标迈进的早期论文。」

- 论文链接:https://pub-bede3007802c4858abc6f742f405d4ef.r2.dev/paper.pdf
- 项目链接:https://phenaki.github.io/#interactive
由于没有基于故事的数据集可以拿来学习,研究人员没有办法简单地依靠传统深度学习方法(简单地从数据中学习)完成这些任务。因此,他们专门设计了一个模型来完成这项任务。
这个新的文本转视频模型名叫 Phenaki,它使用了「文本转视频」和「文本转图像」数据联合训练。该模型具有以下能力:
1、在开放域 prompt 的条件下生成时间上连贯的多样化视频,即使该 prompt 是一个新的概念组合(见下图 3)。生成的视频可以长达几分钟,即使该模型训练所用的视频只有 1.4 秒(8 帧 / 秒)

2、根据一个故事(即一系列 prompt)生成视频,如下图 1 和图 5 所示:


从以下动图中我们可以看到 Phenaki 生成视频的连贯性和多样性:


要实现这些功能,研究人员无法依赖现有的视频编码器,因为这些编码器要么只能解码固定大小的视频,要么独立编码帧。为了解决这个问题,他们引入了一种新的编码器 – 解码器架构——C-ViViT。
C-ViViT 可以:
- 利用视频中的时间冗余来提高每帧模型的重构质量,同时将视频 token 的数量压缩 40% 或更多;
- 在给定因果结构的情况下,允许编码和解码可变长度视频。
PHENAKI 模型架构
受之前自回归文本转图像、文本转视频研究的启发,Phenaki 的设计主要包含两大部分(见下图 2):一个将视频压缩为离散嵌入(即 token)的编码器 – 解码器模型和一个将文本嵌入转换为视频 token 的 transformer 模型。
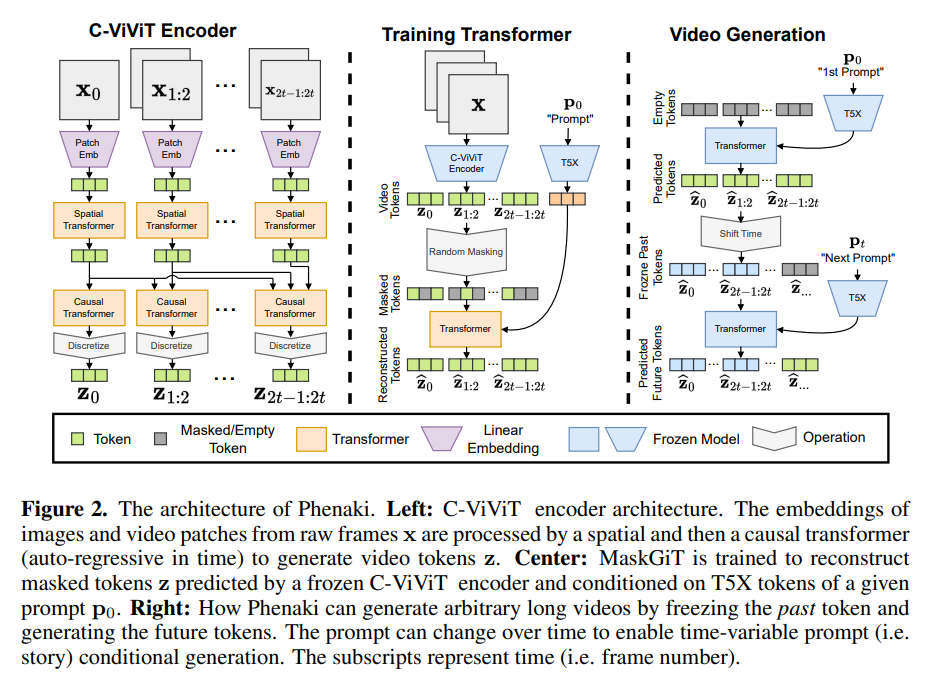
获取视频的压缩表示是从文本生成视频的主要挑战之一。之前的工作要么使用 per-frame 图像编码器,如 VQ-GAN,要么使用固定长度视频编码器,如 V ideoVQVAE。前者允许生成任意长度的视频,但在实际使用中,视频必须要短,因为编码器不能及时压缩视频,并且 token 在连续帧中是高度冗余的。后者在 token 数量上更加高效,但它不允许生成任意长度的视频。
在 Phenaki 中,研究者的目标是生成可变长度的视频,同时尽可能压缩视频 token 的数量,这样就可以在当前的计算资源限制下使用 Transformer 模型。为此,他们引入了 C-ViViT,这是 ViViT 的一种因果变体,为视频生成进行了额外的架构更改,它可以在时间和空间维度上压缩视频,同时保持时间上的自回归。该功能允许生成任意长度的自回归视频。
为了得到文本嵌入,Phenaki 还用到了一个预训练的语言模型——T5X。
具体细节请参见原论文。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


