赋予机器人对日常物体的 3D 理解是机器人应用中的一项重大挑战。
在未知环境中进行探索时,由于物体形状的多样性,现有的物体位姿估计方法仍然不能令人满意。

最近浙江大学、字节跳动人工智能实验室和香港中文大学的研究者联合提出了一个新的框架,用于从单个 RGB-D 图像进行类别级物体形状和位姿估计。

论文地址:https://arxiv.org/abs/2210.01112
项目链接:https://zju3dv.github.io/gCasp
为了处理类别内物体的形状变化,研究人员采用语义原始表示,将不同的形状编码到一个统一的隐空间中,这种表示是在观察到的点云和估计的形状之间建立可靠对应关系的关键。
然后通过设计的对刚体相似变换不变的形状描述子,解耦了物体的形状和位姿估计,从而支持任意位姿中目标物体的隐式形状优化。实验表明所提出的方法在公开数据集中实现了领先的位姿估计性能。
研究背景
在机器人的感知与操作领域,估计日常物体的形状和位姿是一项基本功能,并且具有多种应用,其中包括 3D 场景理解、机器人操作和自主仓储。
该任务的早期工作大多集中在实例级位姿估计上,这些工作主要通过将观察到的物体与给定的 CAD 模型对齐来获得物体位姿。
然而,这样的设置在现实世界的场景中是有限的,因为很难预先获得一个任意给定物体的确切模型。
为了推广到那些没见过但是在语义上熟悉的物体,类别级别物体位姿估计正在引起越来越多的研究关注,因为它可以潜在地处理真实场景中同一类别的各种实例。

现有的类别级位姿估计方法通常尝试预测一个类中实例的像素级归一化坐标,或者采用形变之后的参考先验模型来估计物体位姿。
尽管这些工作已经取得了很大的进步,但是当同一类别中存在较大的形状差异时,这些一次性预测方法仍然面临困难。
为了处理同一类内物体的多样性,一些工作利用神经隐式表示,通过迭代优化隐式空间中的位姿和形状来适应目标物体的形状,并获得了更好的性能。
在类别级物体位姿估计中有两个主要挑战,一是巨大的类内形状差异,二是现有的方法将形状和位姿的耦合在一起进行优化,这样容易导致优化问题更加复杂。
在这篇论文中,研究人员通过设计的对刚体相似变换不变的形状描述子,解耦了物体的形状和位姿估计,从而支持任意位姿中目标物体的隐式形状优化。最后再根据估计形状与观测之间的语义关联,求解出物体的尺度与位姿。
算法介绍
算法由三个模块组成,语义原语提取、生成式形状估计和物体位姿估计。
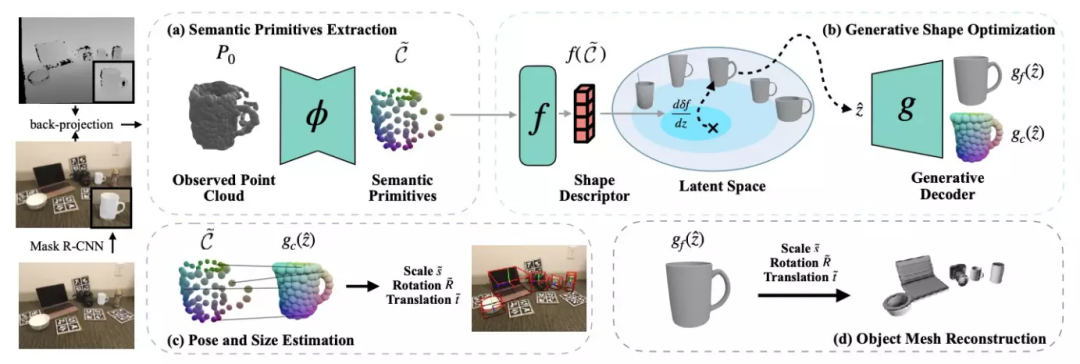
算法的输入是单张 RGB-D 图像,算法使用预先训练好的 Mask R-CNN 获得 RGB 图像的语义分割结果,然后根据相机内参反投影得到每个物体的点云。该方法主要对点云进行处理,最终求得每个物体的尺度与6DoF位姿。
语义原语提取
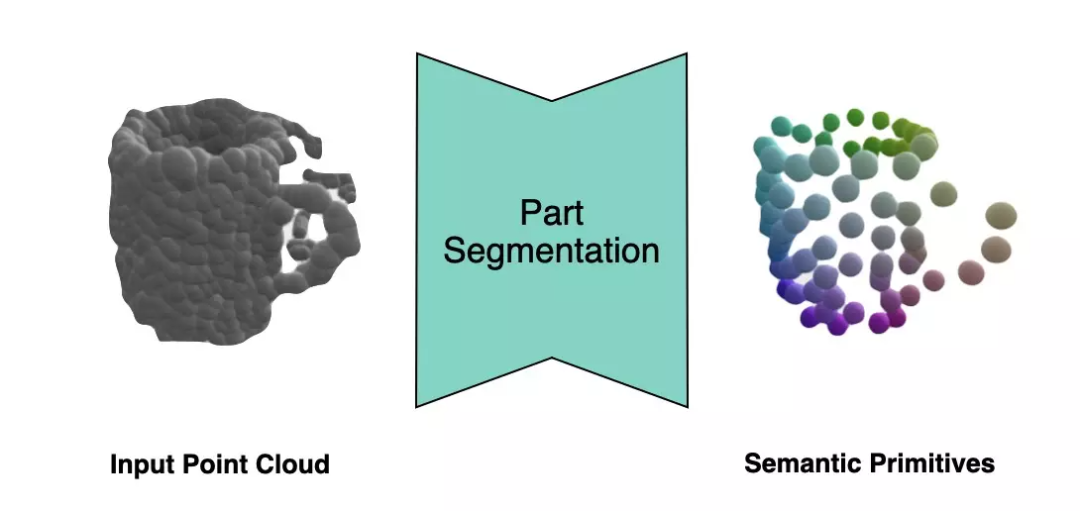
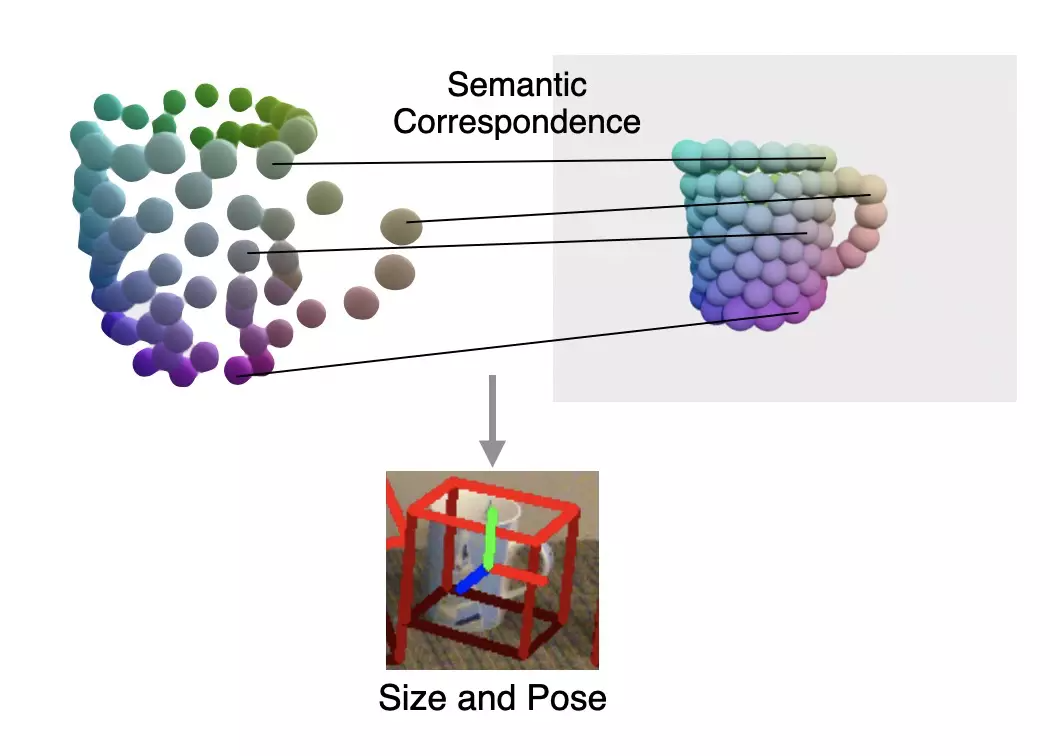
DualSDF[1] 中提出了一种针对同类物体的语义原语的表示方法。如下图左所示,在同一类物体中,每个实例都被分成了一定数量的语义原语,每个原语的标签对应着某类物体的特定部位。
为了从观测点云中提取物体的语义原语,作者利用了一个点云分割网络,将观测点云分割成了带有标签的语义原语。
生成式的形状估计
3D的生成模型(如DeepSDF)大多是在归一化的坐标系下运行的。
然而在真实世界观测中的物体与归一化坐标系之间会存在一个相似位姿变换(旋转、平移以及尺度)。
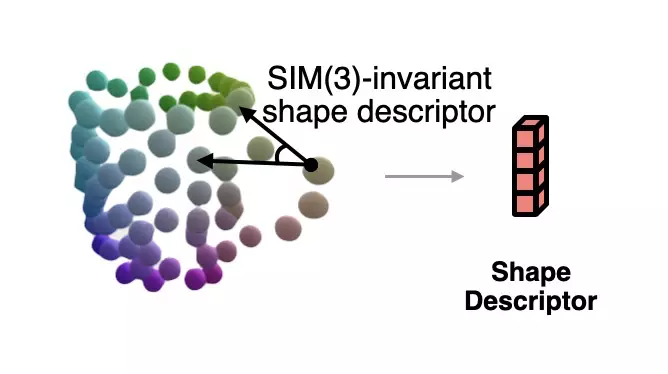
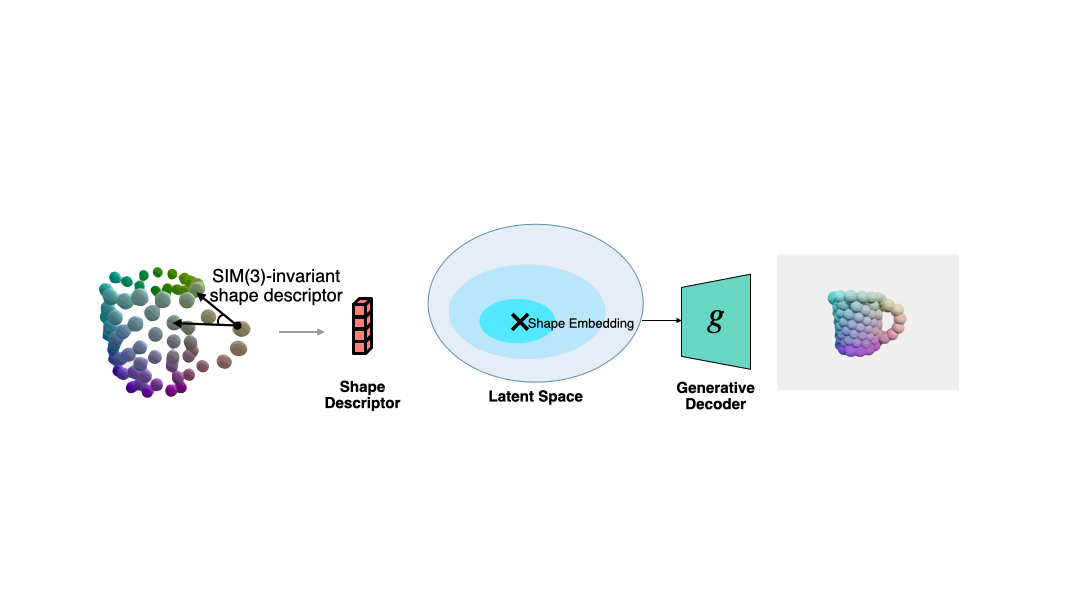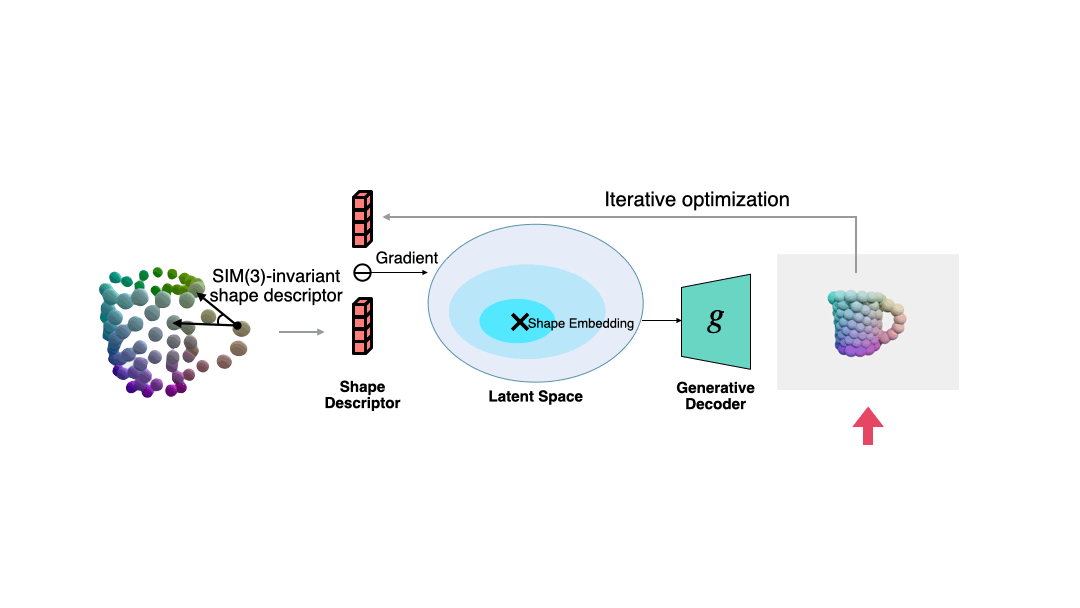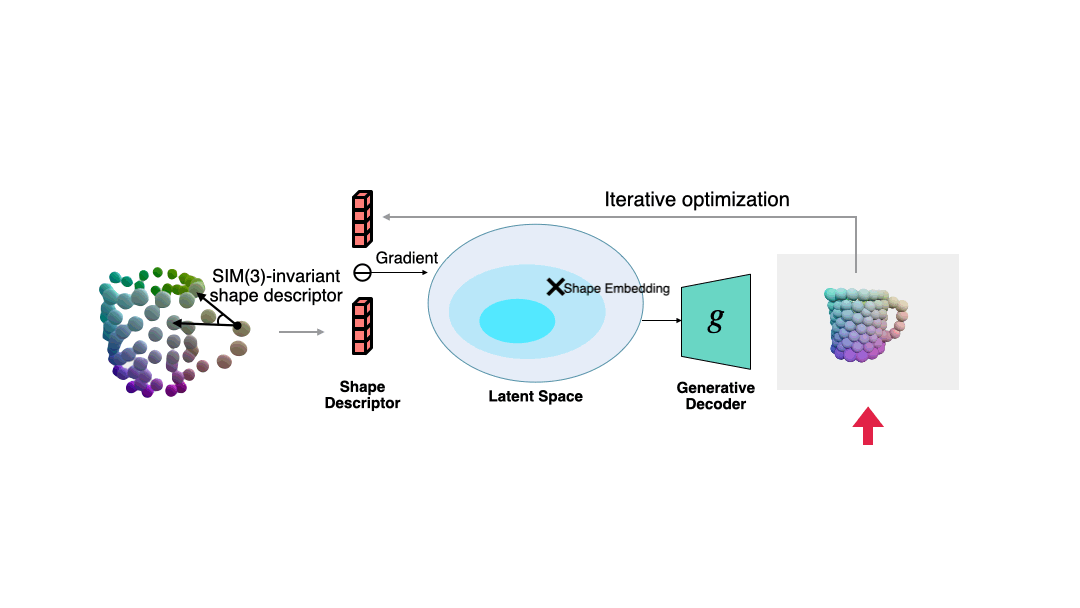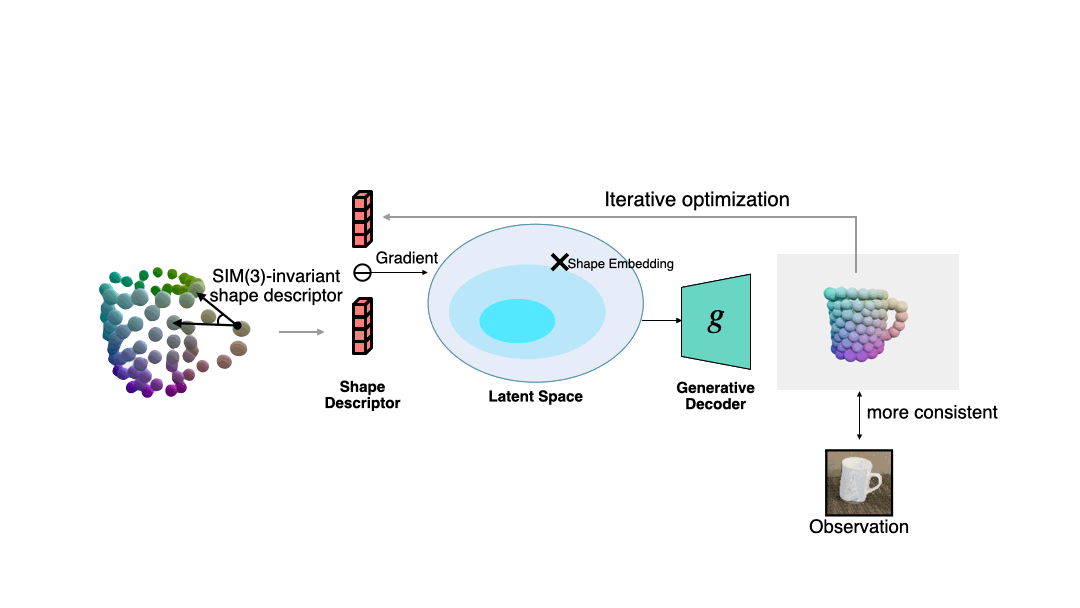
为了在位姿未知时来求解当前观测对应的归一化形状,作者基于语义原语表示,提出了一种对相似变换不变的形状描述子。
这种描述子如下图所示,它描述了不同原语构成的向量之间的夹角:
作者通过这个描述子来衡量当前观测与估计形状之间的误差,并通过梯度下降来使得估计形状与观测之间更加一致,过程如下图所示。
作者另外展示了更多的形状优化示例。

位姿估计
最后,通过观测点云与求解形状之间的语义原语对应关系,作者使用 Umeyama 算法求解了观测形状的位姿。
实验结果
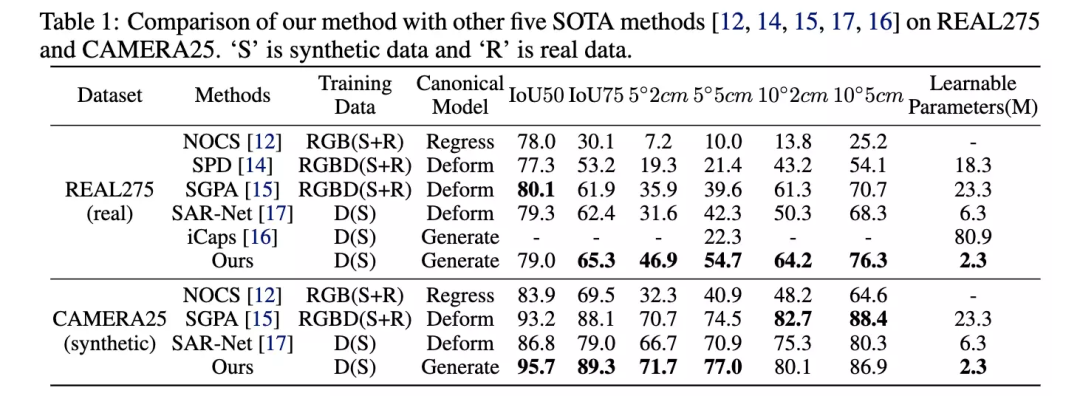
作者在 NOCS 提供的 REAL275(真实数据集) 和 CAMERA25(合成数据集) 数据集上进行了对比实验,与其他方法在位姿估计精度上进行了对比,所提出的方法在多项指标上远超其他方法。
同时,作者也对比了需要在 NOCS 提供的训练集上训练的参数量,作者需要最少的2.3M的参数量便达到了最先进水平。
© 版权声明
文章版权归作者所有,未经允许请勿转载。