扩散模型大火之后,很多人将注意力放到了如何利用更有效的 prompt 生成自己想要的图像。在对于一些 AI 作画模型的不断尝试中,人们甚至总结出了让 AI 好好出图的关键词经验:

也就是说,如果掌握了正确的 AI 话术,作图质量提升效果将非常明显(参见:《「羊驼打篮球」怎么画?有人花了 13 美元逼 DALL·E 2 亮出真本事 》)。
此外,还有一部分研究者在往另一个方向努力:如何动动嘴皮子就把一幅画改成我们想要的样子。
前段时间,我们报道了一项来自谷歌研究院等机构的研究。只要说出你想让一幅图变成什么样子,它就能基本满足你的要求,生成照片级的图像,例如让一只小狗坐下:

这里给模型的输入描述是「一只坐下的狗」,但是按照人们的日常交流习惯,最自然的描述应该是「让这只狗坐下」。有研究者认为这是一个应该优化的问题,模型应该更符合人类的语言习惯。
最近,来自 UC 伯克利的研究团队提出了一种根据人类指令编辑图像的新方法 InstructPix2Pix:给定输入图像和告诉模型要做什么的文本描述,模型就能遵循描述指令来编辑图像。

论文地址:https://arxiv.org/pdf/2211.09800.pdf
例如,要把画中的向日葵换成玫瑰,你只需要直接对模型说「把向日葵换成玫瑰」:

为了获得训练数据,该研究将两个大型预训练模型——语言模型 (GPT-3) 和文本到图像生成模型 (Stable Diffusion) 结合起来,生成图像编辑示例的大型成对训练数据集。研究者在这个大型数据集上训练了新模型 InstructPix2Pix,并在推理时泛化到真实图像和用户编写的指令上。
InstructPix2Pix 是一个条件扩散模型,给定一个输入图像和一个编辑图像的文本指令,它就能生成编辑后的图像。该模型直接在前向传播(forward pass)中执行图像编辑,不需要任何额外的示例图像、输入 / 输出图像的完整描述或每个示例的微调,因此该模型仅需几秒就能快速编辑图像。
尽管 InstructPix2Pix 完全是在合成示例(即 GPT-3 生成的文本描述和 Stable Diffusion 生成的图像)上进行训练的,但该模型实现了对任意真实图像和人类编写文本的零样本泛化。该模型支持直观的图像编辑,包括替换对象、更改图像风格等等。

方法概览
研究者将基于指令的图像编辑视为一个监督学习问题:首先,他们生成了一个包含文本编辑指令和编辑前后图像的成对训练数据集(图 2a-c),然后在这个生成的数据集上训练了一个图像编辑扩散模型(图 2d)。尽管训练时使用的是生成的图像和编辑指令,但模型仍然能够使用人工编写的任意指令来编辑真实的图像。下图 2 是方法概述。

生成一个多模态训练数据集
在数据集生成阶段,研究者结合了一个大型语言模型(GPT-3)和一个文本转图像模型(Stable Diffusion)的能力,生成了一个包含文本编辑指令和编辑前后对应图像的多模态训练数据集。这一过程包含以下步骤:
- 微调 GPT-3 以生成文本编辑内容集合:给定一个描述图像的 prompt,生成一个描述要进行的更改的文本指令和一个描述更改后图像的 prompt(图 2a);
- 使用文本转图像模型将两个文本 prompt(即编辑之前和编辑之后)转换为一对对应的图像(图 2b)。
InstructPix2Pix
研究者使用生成的训练数据来训练一个条件扩散模型,该模型基于 Stable Diffusion 模型,可以根据书面指令编辑图像。
扩散模型学习通过一系列估计数据分布分数(指向高密度数据的方向)的去噪自编码器来生成数据样本。Latent diffusion 通过在预训练的具有编码器和解码器的变分自编码器的潜空间中操作来提高扩散模型的效率和质量。
对于一个图像 x,扩散过程向编码的 latent 中添加噪声,它产生一个有噪声的 latent z_t,其中噪声水平随时间步 t∈T 而增加。研究者学习一个网络,它在给定图像调节 C_I 和文本指令调节 C_T 的情况下,预测添加到带噪 latent z_t 中的噪声。研究者将以下 latent 扩散目标最小化:
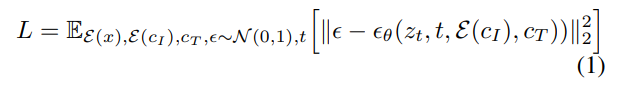
此前,曾有研究(Wang et al.)表明,对于图像翻译(image translation)任务,尤其是在成对训练数据有限的情况下,微调大型图像扩散模型优于从头训练。因此在新研究中,作者使用预训练的 Stable Diffusion checkpoint 初始化模型的权重,利用其强大的文本到图像生成能力。
为了支持图像调节,研究人员向第一个卷积层添加额外的输入通道,连接 z_t 和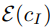 。扩散模型的所有可用权重都从预训练的 checkpoint 初始化,同时在新添加的输入通道上运行的权重被初始化为零。作者在这里重用最初用于 caption 的相同的文本调节机制,而没有将文本编辑指令 c_T 作为输入。
。扩散模型的所有可用权重都从预训练的 checkpoint 初始化,同时在新添加的输入通道上运行的权重被初始化为零。作者在这里重用最初用于 caption 的相同的文本调节机制,而没有将文本编辑指令 c_T 作为输入。
实验结果
在下面这些图中,作者展示了他们新模型的图像编辑结果。这些结果针对一组不同的真实照片和艺术品。新模型成功地执行了许多具有挑战性的编辑,包括替换对象、改变季节和天气、替换背景、修改材料属性、转换艺术媒介等等。




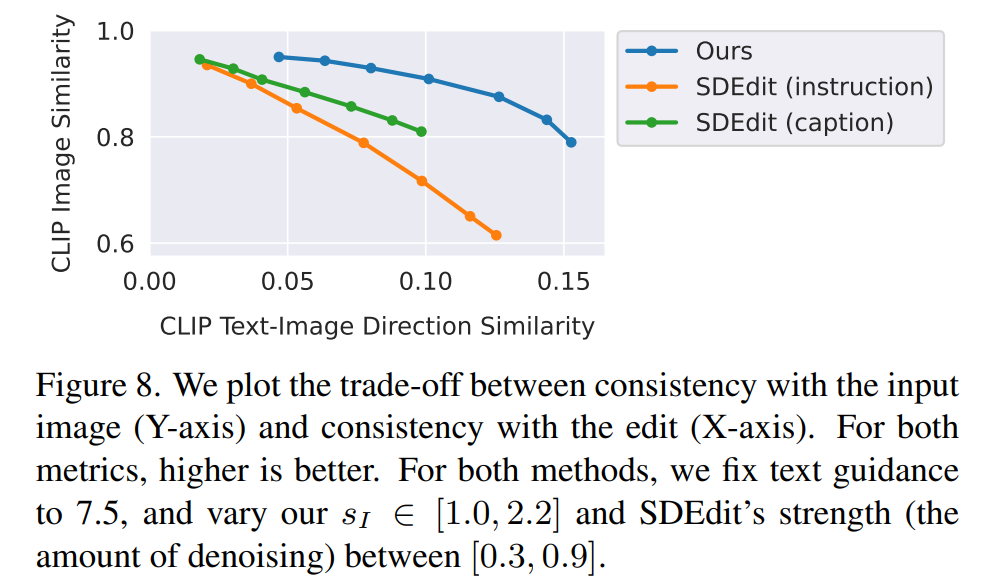
研究人员将新方法与最近的一些技术,如 SDEdit、Text2Live 等进行了比较。新模型遵循编辑图像的说明,而其他方法(包括基准方法)需要对图像或编辑层进行描述。因此在比较时,作者对后者提供「编辑后」的文本标注代替编辑说明。作者还把新方法和 SDEdit 进行定量比较,使用两个衡量图像一致性和编辑质量的指标。最后,作者展示了生成训练数据的大小和质量如何影响模型性能的消融结果。

© 版权声明
文章版权归作者所有,未经允许请勿转载。