扩散模型( Diffusion Model )作为深度生成模型中的新 SOTA,已然在图像生成任务中超越了原 SOTA:例如 GAN,并且在诸多应用领域都有出色的表现,如计算机视觉,NLP、分子图建模、时间序列建模等。
近日,来自香港大学的罗平团队、腾讯 AI Lab 的研究者联合提出一种新框架 DiffusionDet,将扩散模型应用于目标检测。据了解,还没有研究可以成功地将扩散模型应用于目标检测,可以说这是第一个采用扩散模型进行目标检测的工作。
DiffusionDet 的性能如何呢?在 MS-COCO 数据集上进行评估,使用 ResNet-50 作为骨干,在单一采样 step 下,DiffusionDet 实现 45.5 AP,显著优于 Faster R-CNN (40.2 AP), DETR (42.0 AP),并与 Sparse R-CNN (45.0 AP)相当。通过增加采样 step 的数量,进一步将 DiffusionDet 性能提高到 46.2 AP。此外,在 LVIS 数据集上,DiffusionDet 也表现良好,使用 swing – base 作为骨干实现了 42.1 AP。

- 论文地址:https://arxiv.org/pdf/2211.09788.pdf
- 项目地址 https://github.com/ShoufaChen/DiffusionDet
该研究发现在传统的目标检测里,存在一个缺陷,即它们依赖于一组固定的可学习查询。然后研究者就在思考:是否存在一种简单的方法甚至不需要可学习查询就能进行目标检测?
为了回答这一问题,本文提出了 DiffusionDet,该框架可以直接从一组随机框中检测目标,它将目标检测制定为从噪声框到目标框的去噪扩散过程。这种从 noise-to-box 的方法不需要启发式的目标先验,也不需要可学习查询,这进一步简化了目标候选,并推动了检测 pipeline 的发展。
如下图 1 所示,该研究认为 noise-to-box 范式类似于去噪扩散模型中的 noise-to-image 过程,后者是一类基于似然的模型,通过学习到的去噪模型逐步去除图像中的噪声来生成图像。
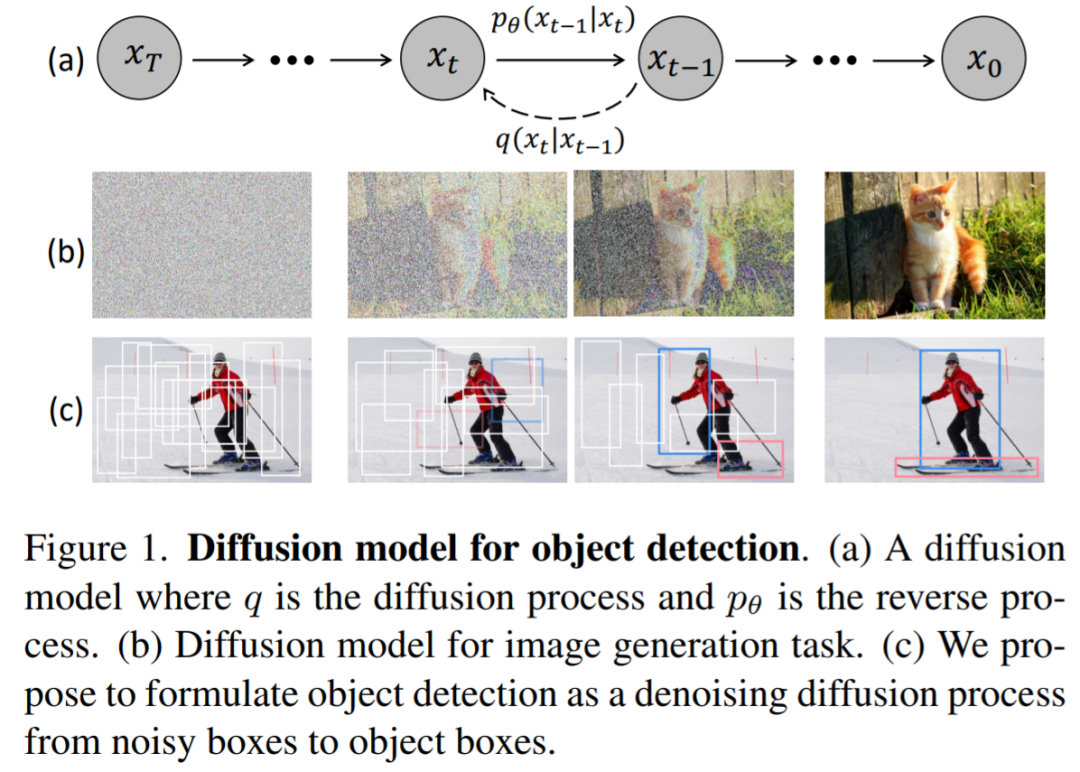
DiffusionDet 通过扩散模型解决目标检测任务,即将检测看作图像中 bounding box 位置 (中心坐标) 和大小 (宽度和高度) 空间上的生成任务。在训练阶段,将方差表(schedule)控制的高斯噪声添加到 ground truth box,得到 noisy box。然后使用这些 noisy box 从主干编码器(如 ResNet, Swin Transformer)的输出特征图中裁剪感兴趣区域(RoI)。最后,将这些 RoI 特征发送到检测解码器,该解码器被训练用来预测没有噪声的 ground truth box。在推理阶段,DiffusionDet 通过反转学习到的扩散过程生成 bounding box,它将噪声先验分布调整到 bounding box 上的学习分布。
方法概述
由于扩散模型迭代地生成数据样本,因此在推理阶段需要多次运行模型 f_θ。但是,在每一个迭代步骤中,直接在原始图像上应用 f_θ在计算上很困难。因此,研究者提出将整个模型分为两部分,即图像编码器和检测解码器,前者只运行一次以从原始输入图像 x 中提取深度特征表示,后者以该深度特征为条件,从噪声框 z_t 中逐步细化框预测。
图像编码器将原始图像作为输入,并为检测解码器提取其高级特征。研究者使用 ResNet 等卷积神经网络和 Swin 等基于 Transformer 的模型来实现 DiffusionDet。与此同时,特征金字塔网络用于为 ResNet 和 Swin 主干网络生成多尺度特征图。
检测解码器借鉴了 Sparse R-CNN,将一组 proposal 框作为输入,从图像编码器生成的特征图中裁剪 RoI 特征,并将它们发送到检测头以获得框回归和分类结果。此外,该检测解码器由 6 个级联阶段组成。
训练
在训练过程中,研究者首先构建了从真值框到噪声框的扩散过程,然后训练模型来反转这个过程。如下算法 1 提供了 DiffusionDet 训练过程的伪代码。
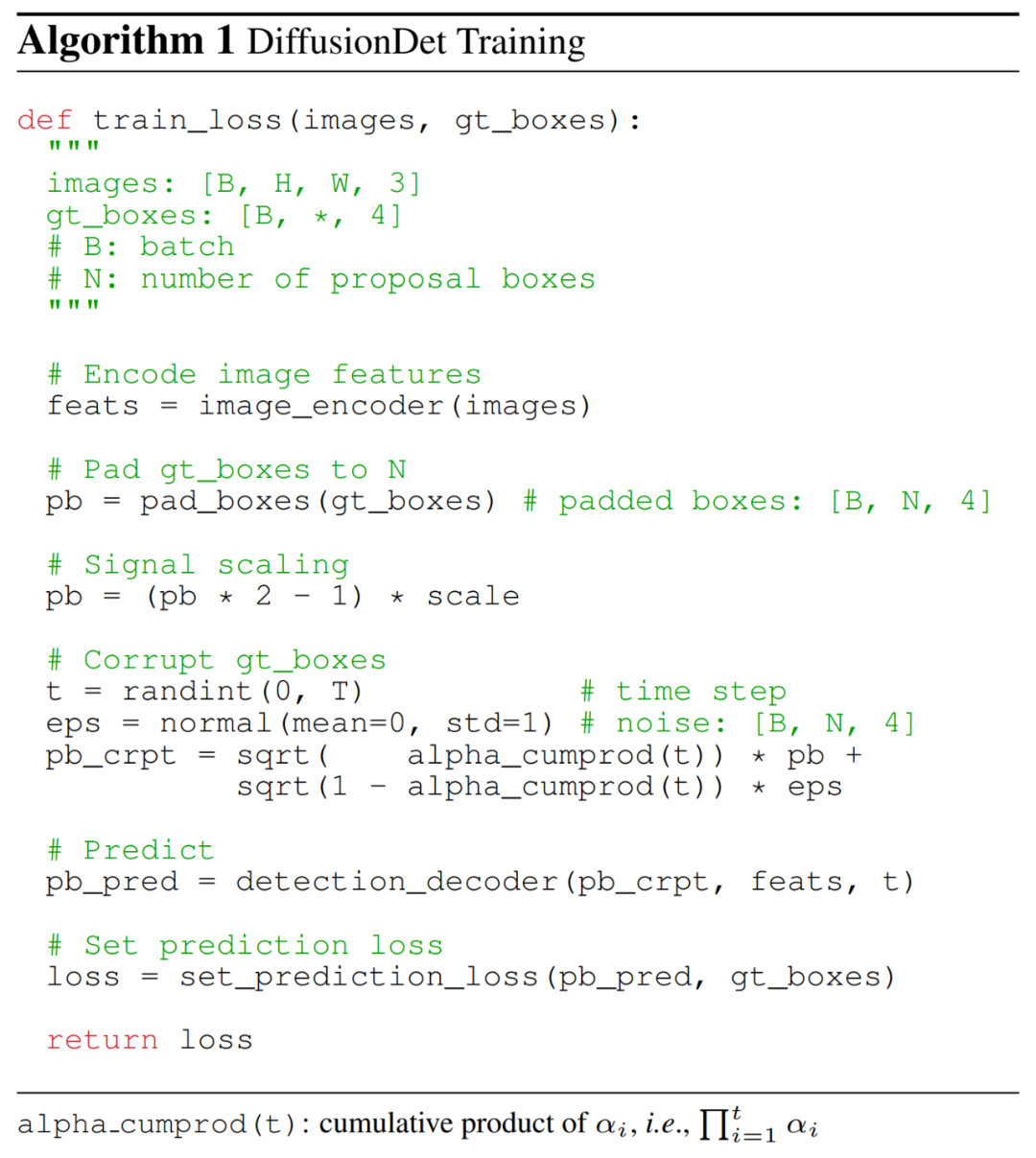
真值框填充。对于现代目标检测基准,感兴趣实例的数量通常因图像而异。因此,研究者首先将一些额外的框填充到原始真值框,这样所有的框被总计为一个固定的数字 N_train。他们探索了几种填充策略,例如重复现有真值框、连接随机框或图像大小的框。
框损坏。研究者将高斯噪声添加到填充的真值框。噪声尺度由如下公式(1)中的 α_t 控制,它在不同的时间步 t 中采用单调递减的余弦调度。
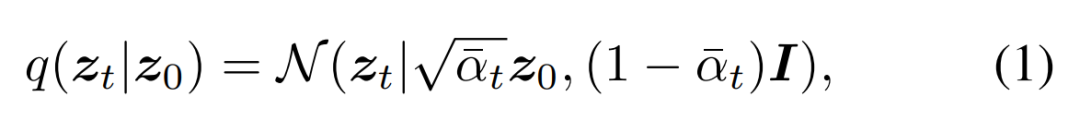
训练损失。检测解码器将 N_train 损坏框作为输入,预测 N_train 对类别分类和框坐标的预测。同时在 N_train 预测集上应用集预测损失(set prediction loss)。
推理
DiffusionDet 的推理过程是从噪声到目标框的去噪采样过程。从在高斯分布中采样的框开始,该模型逐步细化其预测,具体如下算法 2 所示。
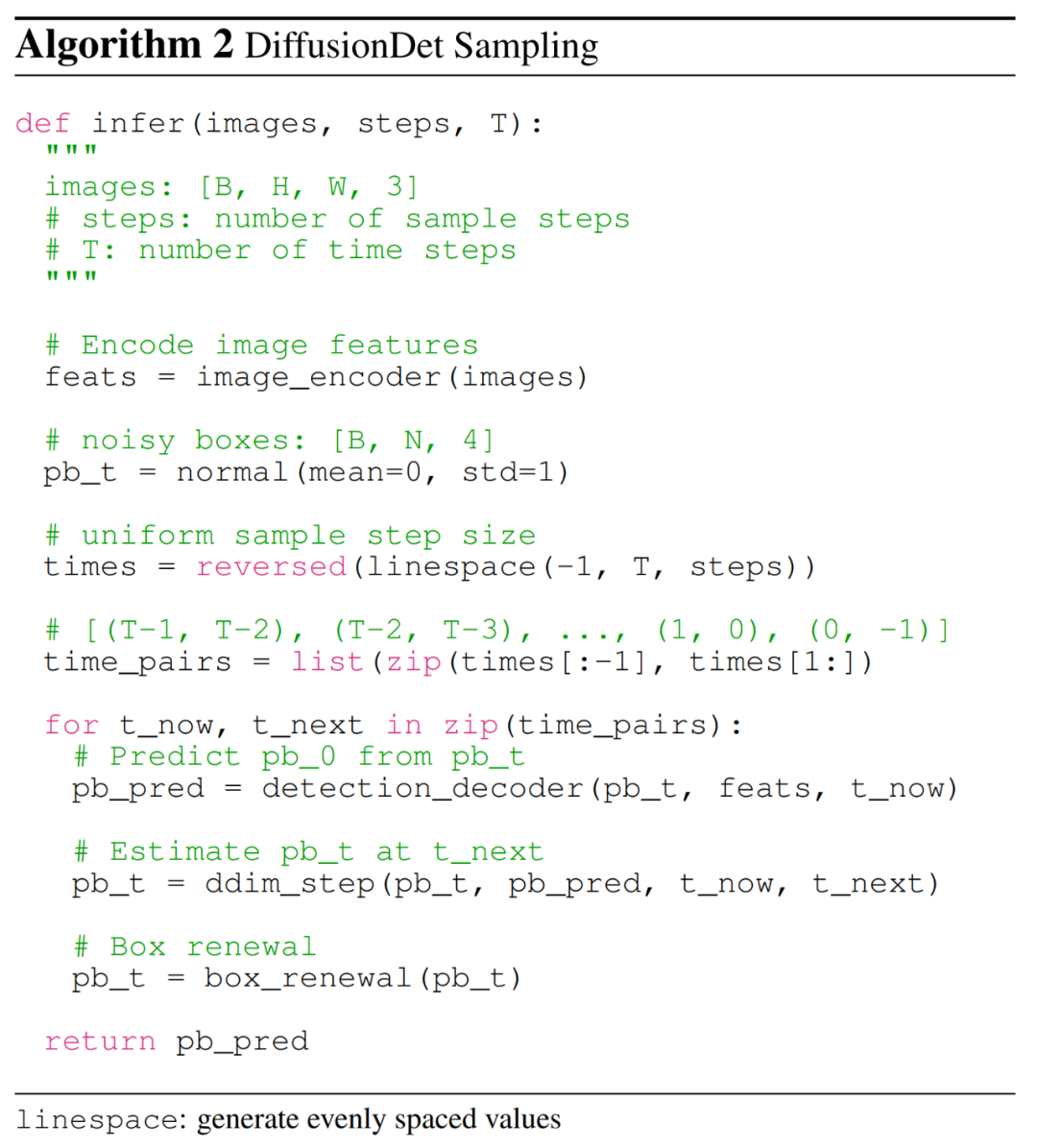
采样步骤。在每个采样步骤中,将上一个采样步骤中的随机框或估计框发送到检测解码器,以预测类别分类和框坐标。在获得当前步骤的框后,采用 DDIM 来估计下一步骤的框。
框更新。为了使推理更好地与训练保持一致,研究者提出了框更新策略,通过用随机框替换非预期的框以使它们恢复。具体来说,他们首先过滤掉分数低于特定阈值的非预期的框,然后将剩余的框与从高斯分布中采样的新随机框连接起来。
一次解决(Once-for-all)。得益于随机框设计,研究者可以使用任意数量的随机框和采样步骤来评估 DiffusionDet。作为比较,以往的方法在训练和评估期间依赖于相同数量的处理框,并且检测解码器在前向传递中仅使用一次。
实验结果
在实验部分,研究者首先展示了 DiffusionDet 的 Once-for-all 属性,然后将 DiffusionDet 与以往在 MS-COCO 和 LVIS 数据集上成熟的检测器进行比较。
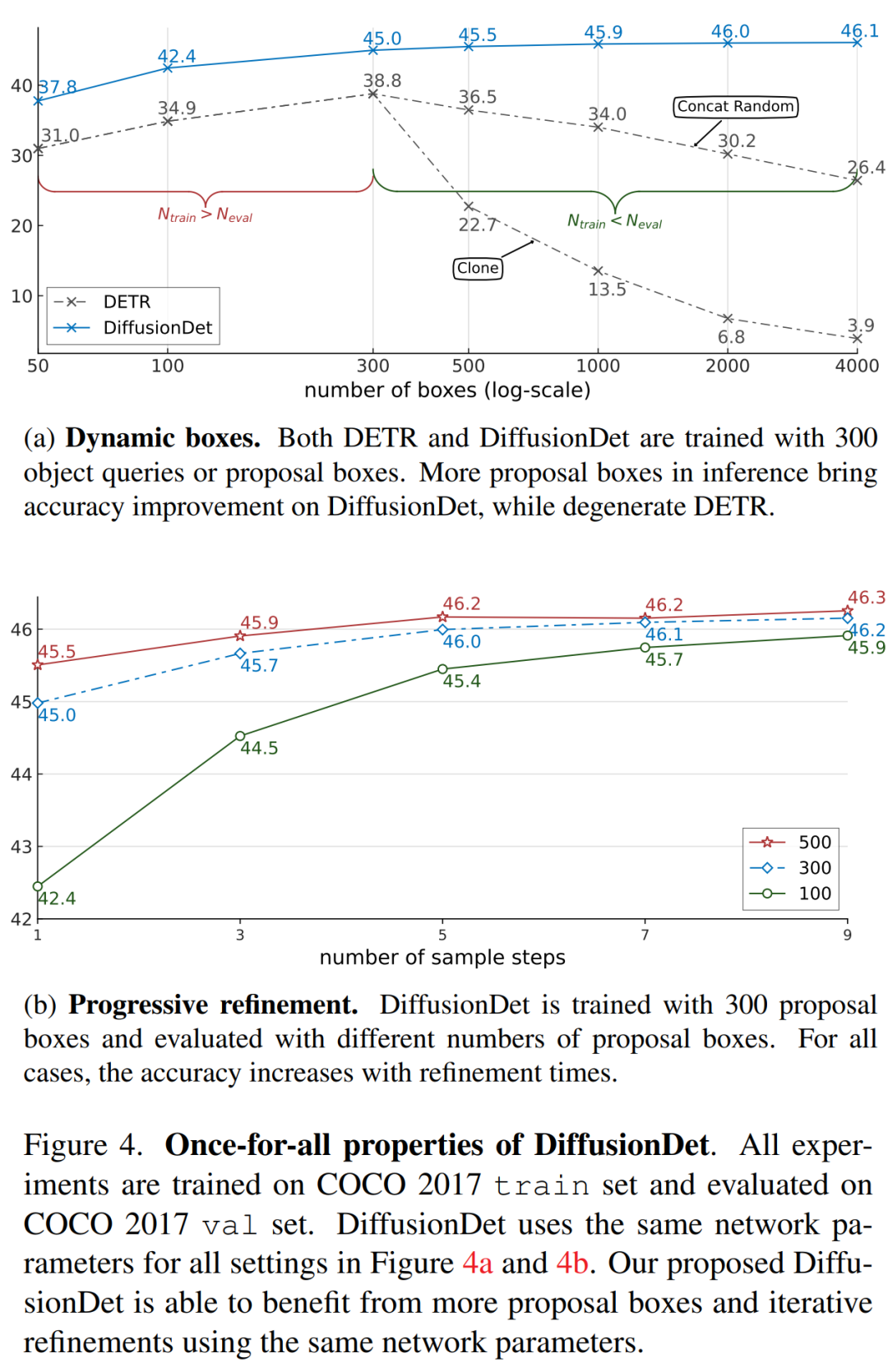
DiffusionDet 的主要特性在于对所有推理实例进行一次训练。一旦模型经过训练,它就可以用于更改推理中框的数量和样本步骤数,如下图 4 所示。DiffusionDet 可以通过使用更多框或 / 和更多细化步骤来实现更高的准确度,但代价是延迟率更高。因此,研究者将单个 DiffusionDet 部署到多个场景中,并在不重新训练网络的情况下获得所需的速度 – 准确率权衡。
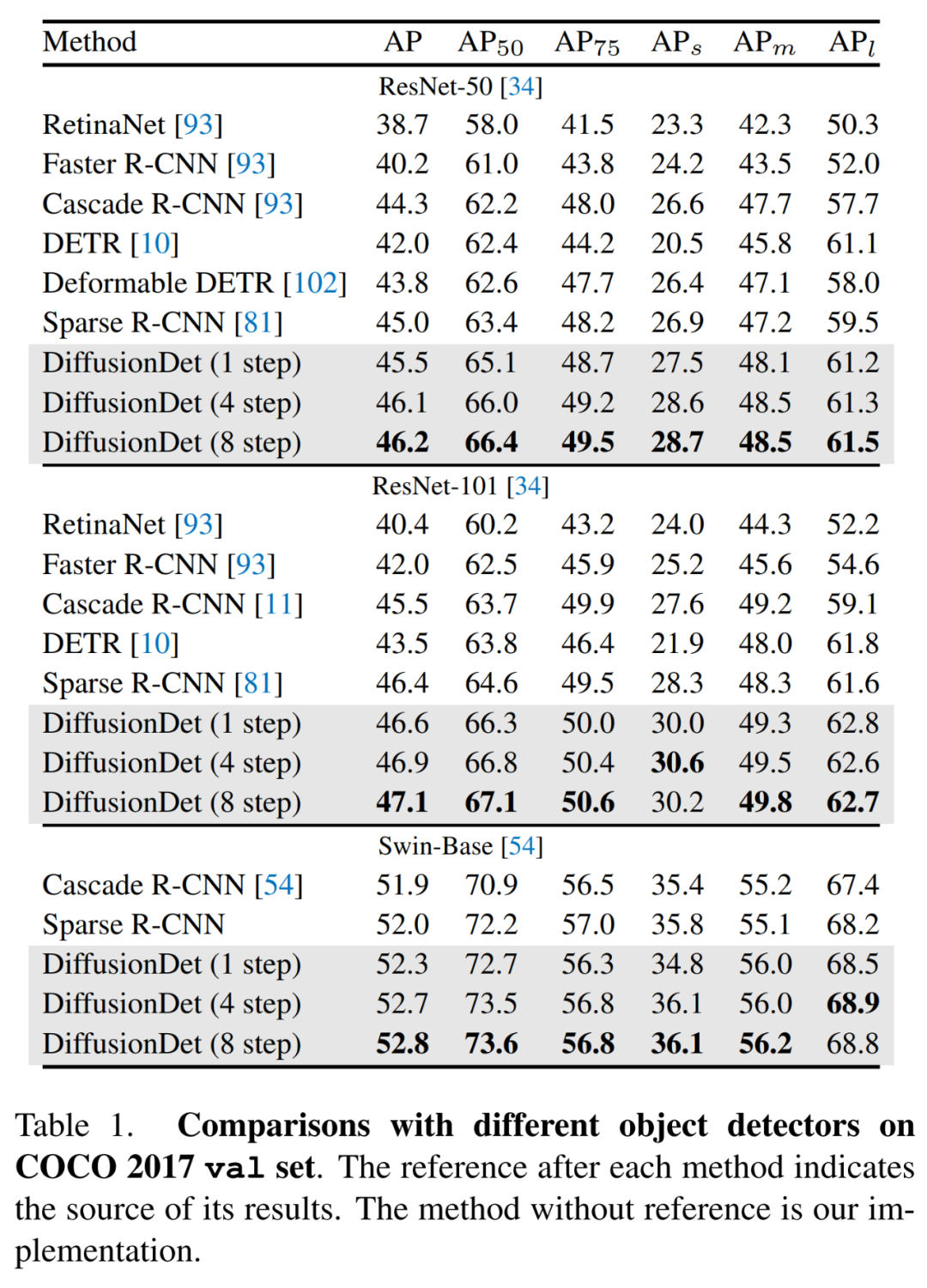
研究者将 DiffusionDet 与以往在 MS-COCO 和 LVIS 数据集上的检测器进行了比较,具体如下表 1 所示。他们首先将 DiffusionDet 的目标检测性能与以往在 MS-COCO 上的检测器进行了比较。结果显示,没有细化步骤的 DiffusionDet 使用 ResNet-50 主干网络实现了 45.5 AP,以较大的优势超越了以往成熟的方法,如 Faster R-CNN、RetinaNet、DETR 和 Sparse R-CNN。并且当主干网络的尺寸扩大时,DiffusionDet 显示出稳定的提升。
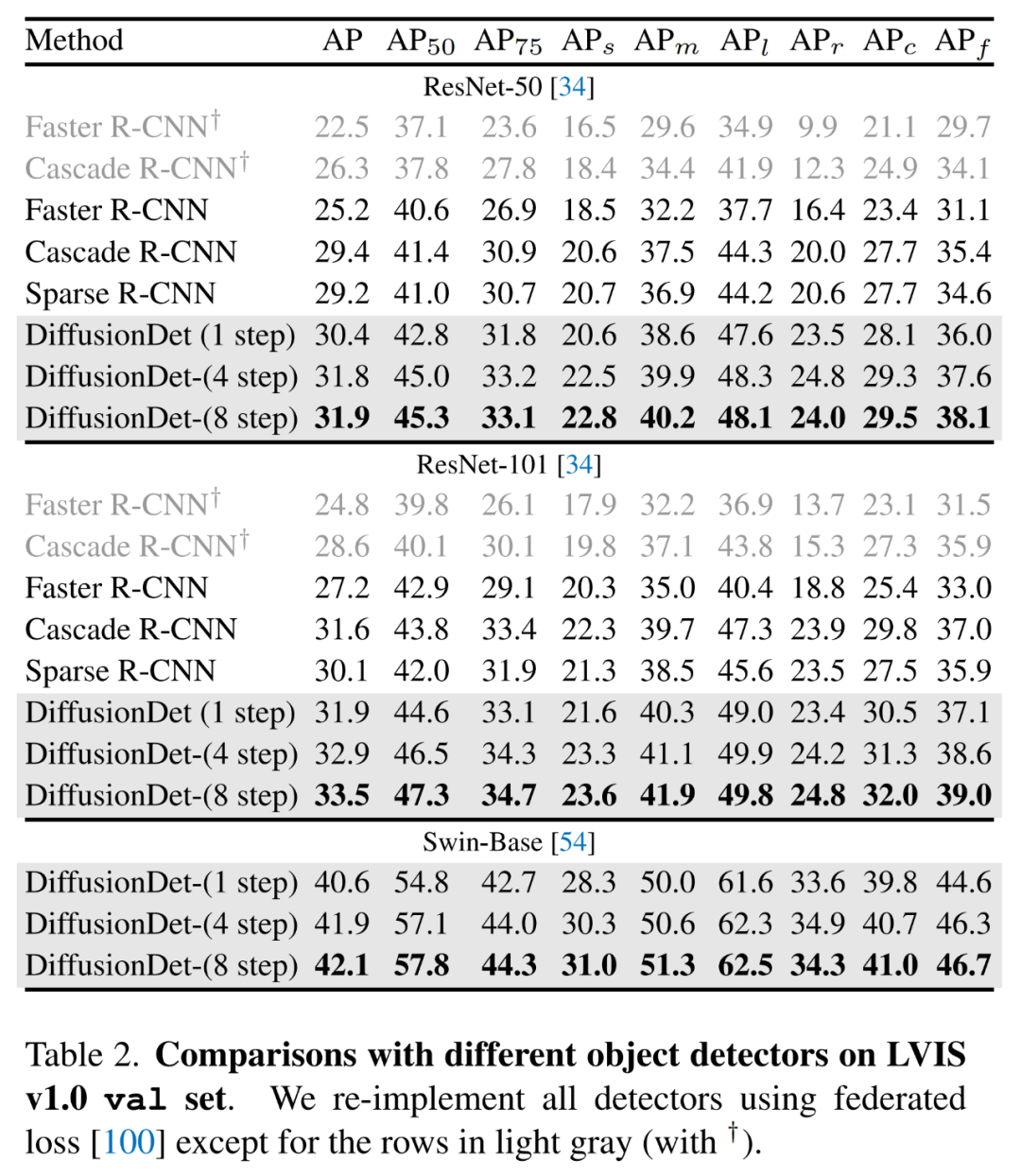
下表 2 中展示了在更具挑战性的 LVIS 数据集上的结果,可以看到,DiffusionDet 使用更多的细化步骤可以获得显著的增益。
更多实验细节请参阅原论文。
© 版权声明
文章版权归作者所有,未经允许请勿转载。