面对越来越深的深度学习模型和海量的视频大数据,人工智能算法对计算资源的依赖越来越高。为了有效提升深度模型的性能和效率,通过探索模型的可蒸馏性和可稀疏性,本文提出了一种基于 “教导主任 – 教师 – 学生” 模式的统一的模型压缩技术。
该成果由人民中科和中科院自动化所联合研究团队合作完成,相关论文发表在人工智能顶级国际期刊 IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) 上。该成果是首次将 “教导主任” 角色引入模型蒸馏技术,对深度模型的蒸馏与裁剪进行了统一。

论文地址:https://ieeexplore.ieee.org/abstract/document/9804342
目前该项成果已经应用于人民中科自主研发的跨模态智能搜索引擎 “白泽”。“白泽” 打破图文音视等不同模态间信息表达的隔阂,将文字、图片、语音和视频等不同模态信息映射到一个统一特征表示空间,以视频为核心,学习多个模态间统一的距离度量,跨越文字、语音、视频等多模态内容的语义鸿沟,实现大一统的搜索能力。
然而面对海量的互联网数据尤其是视频大数据,跨模态的深度模型对计算资源的消耗逐渐提升。基于该项研究成果,“白泽”能够在保证算法性能的情况下,将模型大小进行大规模压缩,从而实现高通量低功耗的跨模态智能理解和搜索能力。根据初步的实际应用情况来看,该项技术能够将大模型的参数规模压缩平均四倍以上。一方面能够极大降低模型对 GPU 服务器等高性能计算资源的消耗,另一方面能够将无法在边缘端部署的大模型经过蒸馏压缩后实现边缘端的低功耗部署。
模型压缩的联合学习框架
深度算法模型的压缩和加速可通过蒸馏学习或结构化稀疏裁剪实现,但这两个领域均存在一些局限性。对于蒸馏学习方法,旨在训练一个轻量化模型(即学生网络)来模拟复杂庞大的模型(即教师网络)。在教师网络的指导下,学生网络可以获得比单独训练的更优性能。
然而,蒸馏学习算法仅仅专注于提升学生网络的性能,往往忽略了网络结构的重要性。学生网络的结构一般是预定义好的,并且在训练过程中是固定的。
对于结构化稀疏裁剪或滤波器裁剪,这些方法旨在将一个冗余繁杂的网络裁剪成一个稀疏紧致的网络。然而,模型裁剪仅仅用于获得一个紧致的结构。目前已有方法都没有充分利用原始复杂模型所包含的“知识”。近期研究为了平衡模型性能和大小,将蒸馏学习和结构化稀疏裁剪进行结合。但是这些方法仅限于简单的损失函数的结合。
为了深入分析以上问题,该研究首先对模型进行基于压缩感知训练,通过分析模型性能和结构发现,对于深度算法模型,存在两个重要属性:可蒸馏性(distillability)和可稀疏性(sparsability)。
具体而言,可蒸馏性指的是能够从教师网络中蒸馏出有效知识的密度。它可以通过学生网络在教师网络指导下所获得的性能收益来衡量。例如,拥有更高可蒸馏性的学生网络可以获得更高性能。可蒸馏性也可以在网络层级别上被定量分析。
如图 1-(a)所示,柱形图表示蒸馏学习损失梯度和真值分类损失梯度之间的余弦相似度(Cosine Similarity)。更大的余弦相似度说明当前蒸馏的知识对于模型性能更有帮助。这样,余弦相似度也可以成为可蒸馏性的一种度量。由图 1-(a)可得,可蒸馏性随着模型层数变深逐渐增大。这也解释了为什么常规使用蒸馏学习的监督均施加在模型最后几层中。并且,在不同的训练轮次,学生模型也有不同的可蒸馏性,因为随着训练时间变化余弦相似度也在改变。因此,在训练过程中对不同层进行可蒸馏性的动态分析十分必要。
另一方面,可稀疏性指的是模型在有限精度损失下能够获得的裁剪率(或称压缩率)。更高的可稀疏性对应更高裁剪率的潜力。如图 1-(b)所示,网络的不同层或模块展现了不同的可稀疏性。类似于可蒸馏性,可稀疏性也可以在网络层级别和时间维度进行分析。然而,目前没有方法去探索和分析可蒸馏性和可稀疏性。现有方法常常使用一种固定的训练机制,这样很难达到一个最优结果。
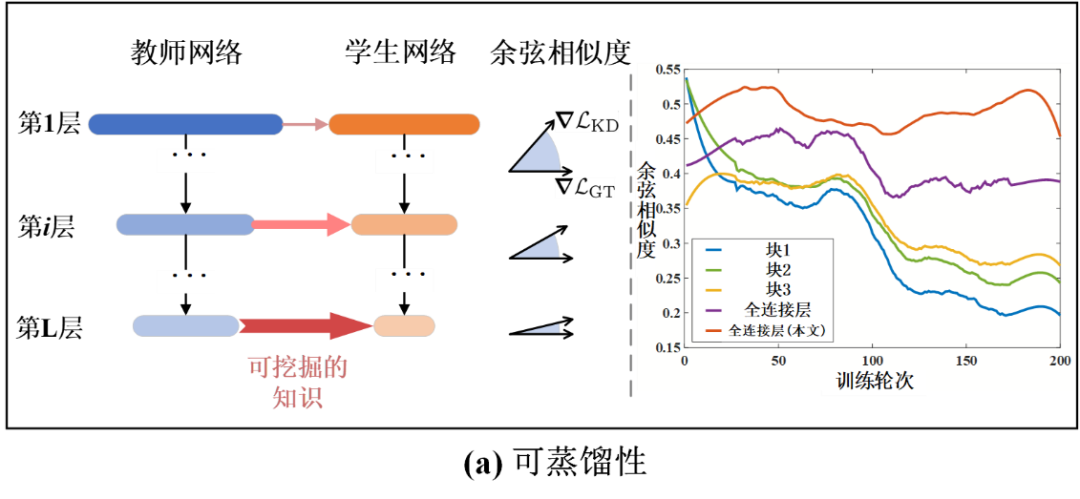
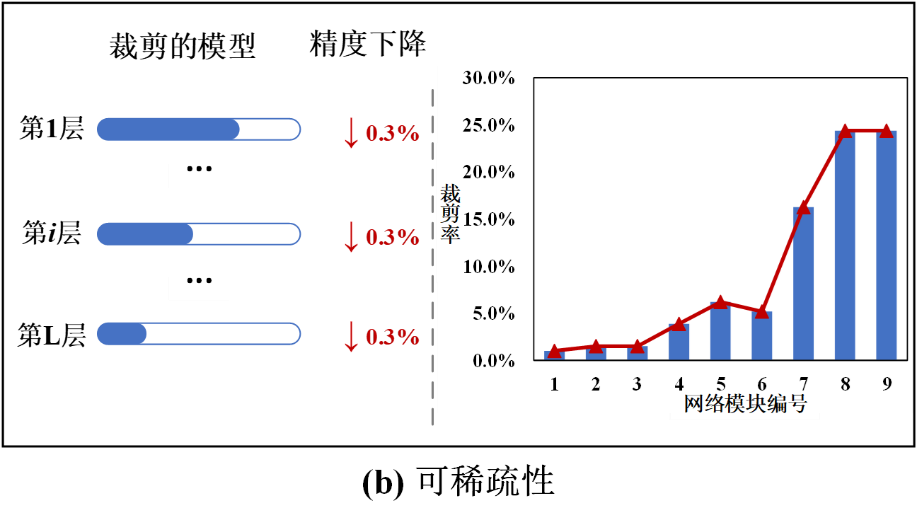
图 1 深度神经网络的可蒸馏性和可稀疏性示意图
为了解决以上问题,该研究分析了模型压缩的训练过程,从而获得有关可蒸馏性和可稀疏性的相关发现。受这些发现启发,该研究提出了一种基于动态可蒸馏性与可稀疏性联合学习的模型压缩方法。它能动态结合蒸馏学习和结构化稀疏裁剪,通过学习可蒸馏性和可稀疏性,自适应地调节联合训练机制。
与常规的 “教师 – 学生(Teacher-Student)” 框架不同,本文提出的方法能够被描述成 “在学校学习(Learning-in-School)” 框架,因为它包含三大模块:教师网络,学生网络和教导主任网络。
具体而言,与之前相同,教师网络教导学生网络。而教导主任网络负责控制学生网络学习的强度以及学习的方式。通过获取当前教师网络和学生网络的状态,教导主任网络可以评估当前学生网络的可蒸馏性和可稀疏性,然后动态地平衡和控制蒸馏学习监督和结构化稀疏裁剪监督的强度。
为了优化本文方法,该研究还提出一种基于交替方向乘子法的蒸馏学习 & 裁剪的联合优化算法,来更新学生网络。为了优化和更新教导主任网络,本文提出一种基于元学习的教导主任优化算法。借助动态调节监督信号,反过来可蒸馏性也能被影响。如图 1-(a)所示,本文方法证明能够延缓可蒸馏性的下降趋势,并且通过合理利用蒸馏的知识,提升了整体的可蒸馏性。
本文方法的整体算法框架和流程图如下图所示。该框架包含三大模块,教师网络,学生网络和教导主任网络。其中,初始的待压缩裁剪的复杂冗余网络被看作教师网络,而在后面的训练过程中,逐渐被稀疏的原始网络被看作是学生网络。教导主任网络是一个元网络,它输入教师网络和学生网络的信息来衡量当前可蒸馏性和可稀疏性,从而控制蒸馏学习和稀疏的监督强度。
这样,在每一时刻,学生网络都能被动态地蒸馏知识指导和被稀疏。例如,当学生网络有更高的可蒸馏性,则教导主任会让更强的蒸馏监督信号指导学生网络(见图 2 中粉色箭头信号);与此相反,当学生网络有更高的可稀疏性,教导主任会让更强的稀疏监督信号施加于学生网络中(见图 2 中橙色箭头信号)。
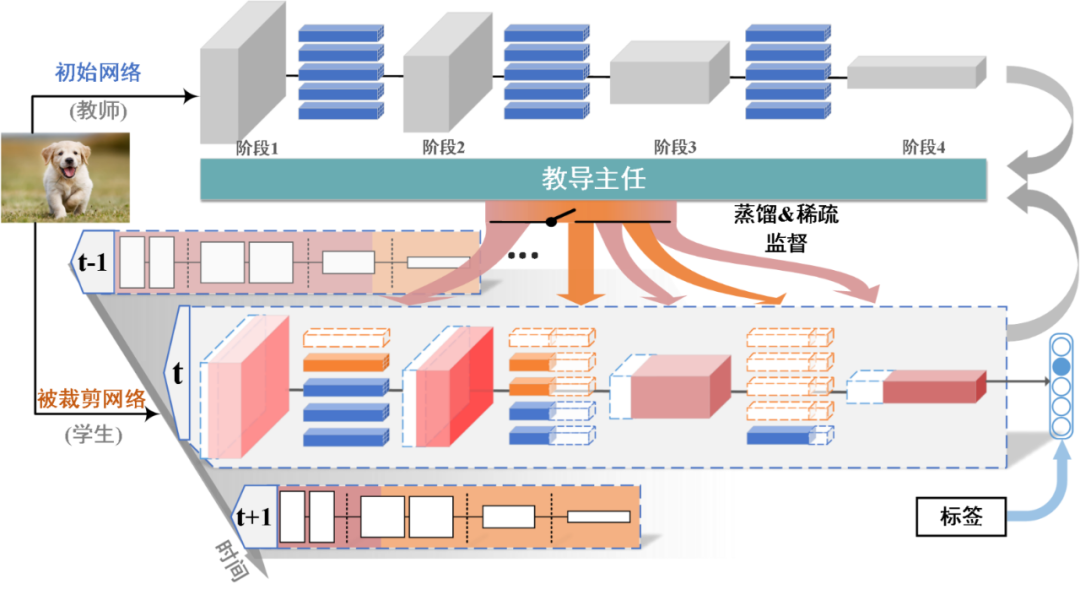
图 2 基于可蒸馏性与可稀疏性联合学习的模型压缩算法示意图
实验结果
实验将本文提出的方法与 24 种主流模型压缩方法(包括稀疏裁剪方法和蒸馏学习方法)在小规模数据集 CIFAR 和大规模数据集 ImageNet 上进行比较。实验结果如下图所示,结果证明本文所提方法的优越性。
表 1 在 CIFAR10 上的模型裁剪结果性能对比:
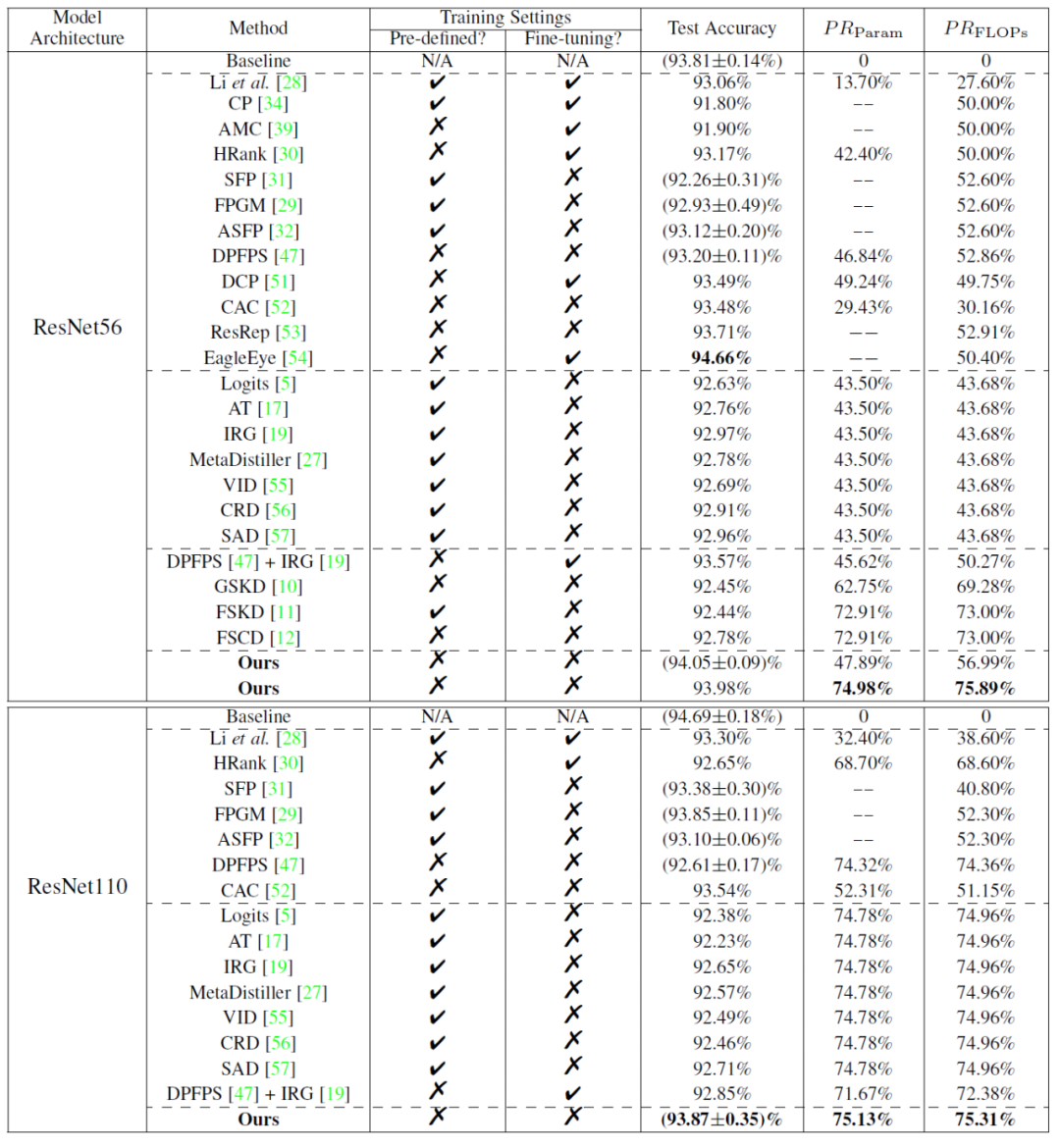
表 2 在 ImageNet 上的模型裁剪结果性能对比:
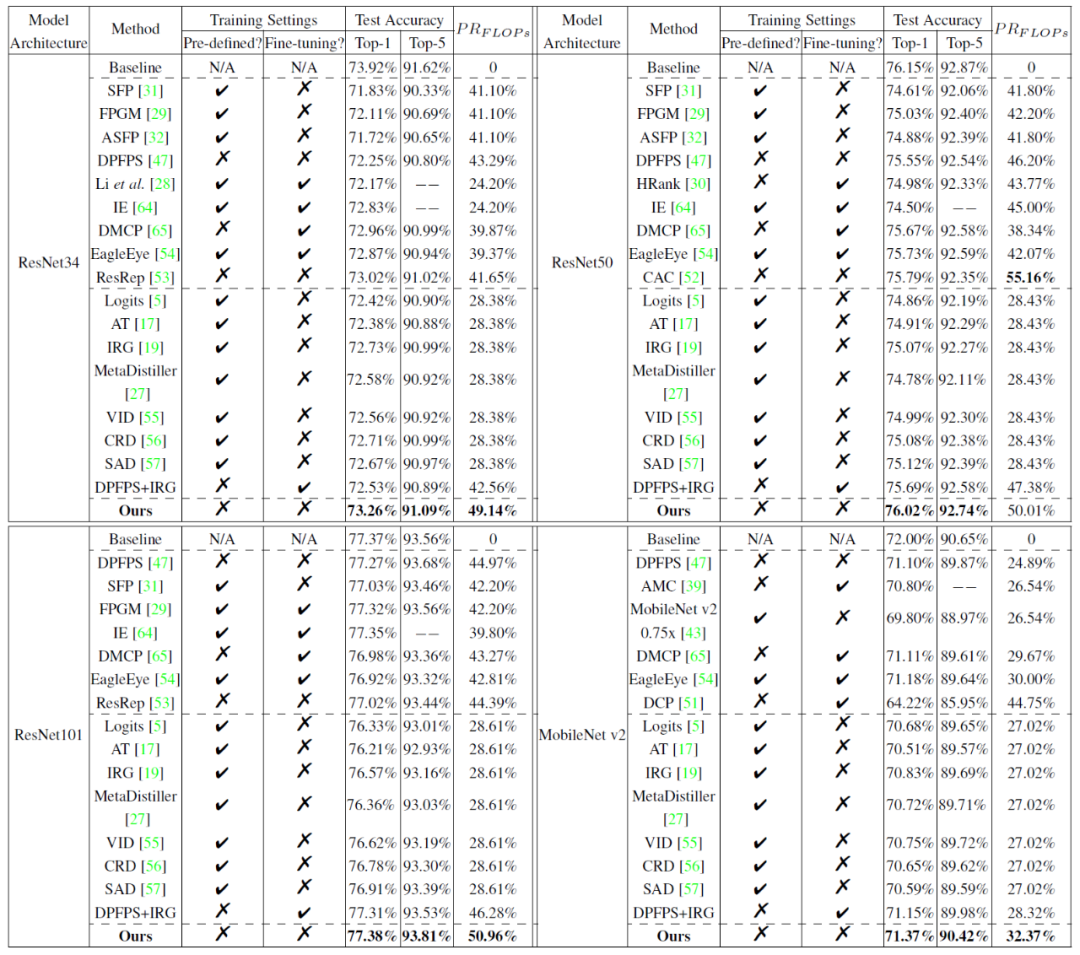
更多研究细节,可参考原论文。
© 版权声明
文章版权归作者所有,未经允许请勿转载。