
由于可以做一些没训练过的事情,大型语言模型似乎具有某种魔力,也因此成为了媒体和研究员炒作和关注的焦点。
当扩展大型语言模型时,偶尔会出现一些较小模型没有的新能力,这种类似于「创造力」的属性被称作「突现」能力,代表我们向通用人工智能迈进了一大步。
如今,来自谷歌、斯坦福、Deepmind和北卡罗来纳大学的研究人员,正在探索大型语言模型中的「突现」能力。

解码器提示的 DALL-E
神奇的「突现」能力
自然语言处理(NLP)已经被基于大量文本数据训练的语言模型彻底改变。扩大语言模型的规模通常会提高一系列下游NLP任务的性能和样本效率。
在许多情况下,我们可以通过推断较小模型的性能趋势预测大型语言模型的性能。例如,规模对语言模型困惑的影响已被验证跨越超过七个数量级。
然而,某些其他任务的性能却并没有以可预测的方式提高。
例如,GPT-3的论文表明,语言模型执行多位数加法的能力对于从100M到13B参数的模型具有平坦的缩放曲线,近似随机,但会在一个节点造成性能的飞升。
鉴于语言模型在NLP研究中的应用越来越多,因此更好地理解这些可能意外出现的能力非常重要。
在近期发表在机器学习研究(TMLR)上的论文「大型语言模型的突现能力」中,研究人员展示了数十个扩展语言模型所产生的「突现」能力的例子。
这种「突现」能力的存在提出了一个问题,即额外的缩放是否能进一步扩大语言模型的能力范围。
某些提示和微调方法只会在更大的模型中产生改进
「突现」提示任务
首先,我们讨论在提示任务中可能出现的「突现」能力。
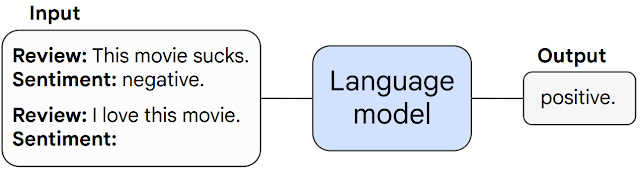
在此类任务中,预先训练的语言模型会被提示执行下一个单词预测的任务,并通过完成响应来执行任务。
如果没有任何进一步的微调,语言模型通常可以执行训练期间没有看到的任务。
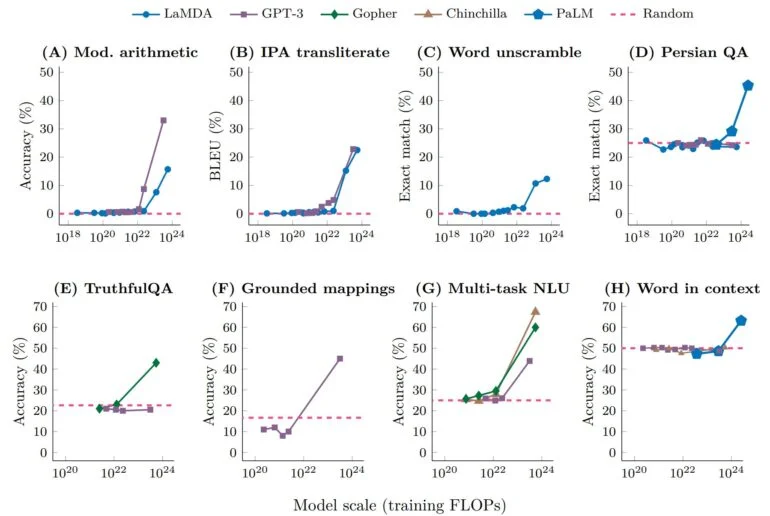
当任务在特定规模阈值下不可预测地从随机性能飙升至高于随机性能时,我们将其称为「突现」任务。
下面我们展示了三个具有「突现」表现的提示任务示例:多步算术、参加大学水平的考试和识别单词的预期含义。
在每种情况下,语言模型的表现都很差,对模型大小的依赖性很小,直到达到某个阈值——它们的性能骤升。
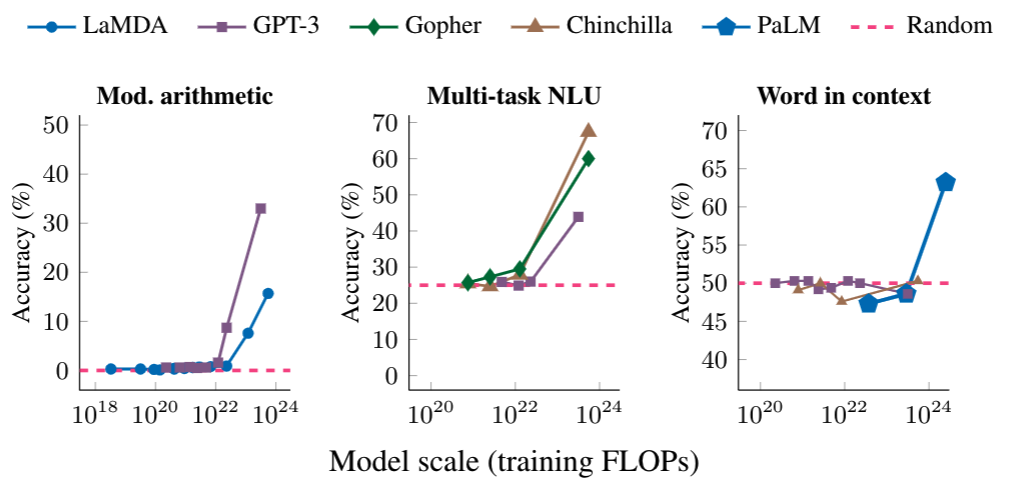
对于足够规模的模型,这些任务的性能只会变得非随机——例如,算术和多任务NLU任务的训练每秒浮点运算次数(FLOP)超过10的22次方,上下文任务中单词的训练FLOP超过10的24次方。
「突现」提示策略
第二类「突现」能力包括增强语言模型能力的提示策略。
提示策略是用于提示的广泛范式,可应用于一系列不同的任务。当它们对小型模型失败并且只能由足够大的模型使用时,它们被认为是可「突现」的。
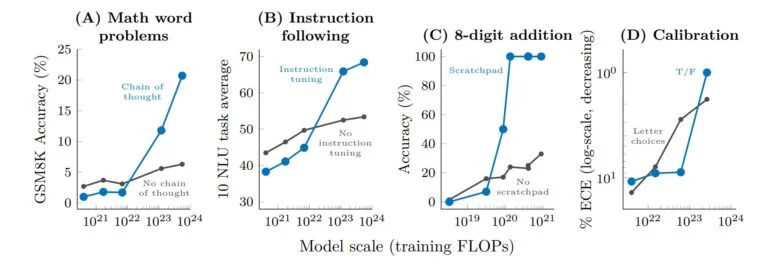
思维链提示是「突现」提示策略的一个典型示例,提示模型在给出最终答案之前生成一系列中间步骤。
思维链提示使语言模型能够执行需要复杂推理的任务,例如多步数学单词问题。
值得一提的是,模型无需经过明确培训即可获得思维链推理的能力,下图则显示了一个思维链提示的示例。

思维链提示的实证结果如下所示。
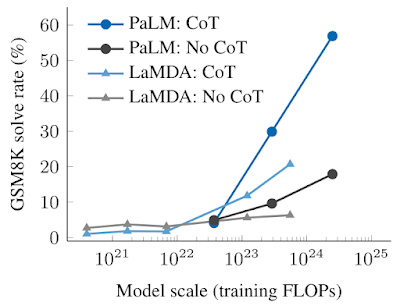
对于较小的模型,应用思维链提示并不会优于标准提示,例如当应用于GSM8K时,这是一个具有挑战性的数学文字问题基准。
然而对于大型模型,思维链提示在GSM8K上达到了57%的解决率,在我们的测试中性能显著提升。
研究「突现」能力的意义
那么研究「突现」能力,又究竟有什么意义呢?
识别大型语言模型中的「突现」能力,是理解此类现象及其对未来模型能力的潜在影响的第一步。
例如,由于「突现」小样本提示能力和策略没有在预训练中明确编码,研究人员可能不知道当前语言模型的小样本提示能力的全部范围。
此外,进一步扩展是否会潜在地赋予更大的模型「突现」能力,这个问题同样十分重要。
- 为什么会出现「突现」能力?
- 当某些能力出现时,语言模型的新现实世界应用会被解锁吗?
- 由于计算资源昂贵,能否在不增加扩展性的情况下通过其他方法解锁突现」能力(例如更好的模型架构或训练技术)?
研究人员表示,这些问题尚且不得而知。
不过随着NLP领域的不断发展,分析和理解语言模型的行为,包括由缩放产生的「突现」能力,是十分重要的。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


