
译者 | 李睿
审校 | 孙淑娟
随着机器学习成为人们每天都在使用的很多应用程序的一部分,人们越来越关注如何识别和解决机器学习模型的安全和隐私方面的威胁。
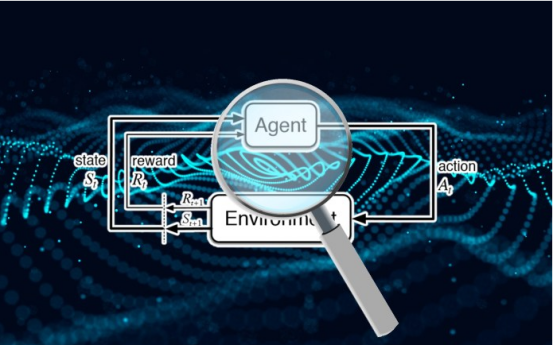
然而,不同机器学习范式面临的安全威胁各不相同,机器学习安全的某些领域仍未得到充分研究。尤其是强化学习算法的安全性近年来并未受到太多关注。
加拿大的麦吉尔大学、机器学习实验室(MILA)和滑铁卢大学的研究人员开展了一项新研究,主要侧重于深度强化学习算法的隐私威胁。研究人员提出了一个框架,用于测试强化学习模型对成员推理攻击的脆弱性。
研究结果表明,攻击者可以对深度强化学习(RL)系统进行有效攻击,并可能获得用于训练模型的敏感信息。他们的研究成果意义重大,因为强化学习技术目前正在进入工业和消费者应用领域。
成员推理攻击
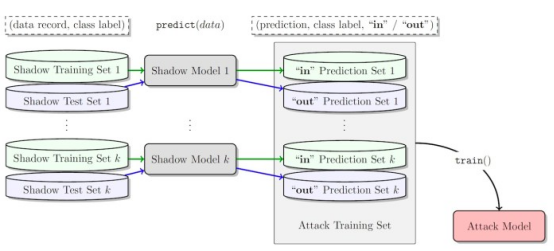
成员推理攻击可以观察目标机器学习模型的行为,并预测用于训练它的示例。
每个机器学习模型都在一组示例上进行训练。在某些情况下,训练示例包括敏感信息,例如健康或财务数据或其他个人身份信息。
成员推理攻击是一系列试图强制机器学习模型泄露其训练集数据的技术。虽然对抗性示例(针对机器学习的更广为人知的攻击类型)专注于改变机器学习模型的行为,并被视为安全威胁,但成员推理攻击侧重于从模型中提取信息,并且更多的是隐私威胁。
成员推理攻击已经在有监督的机器学习算法中进行了深入研究,其中模型是在标记示例上进行训练的。
与监督学习不同的是,深度强化学习系统不使用标记示例。强化学习(RL)代理从它与环境的交互中获得奖励或惩罚。它通过这些互动和强化信号逐渐学习和发展自己的行为。
该论文的作者在书面评论说,“强化学习中的奖励不一定代表标签;因此,它们不能充当其他学习范式中成员推理攻击设计中经常使用的预测标签。”
研究人员在他们的论文中写道,“目前还没有关于直接用于训练深度强化学习代理的数据的潜在成员泄漏的研究。”
而缺乏这种研究的部分原因是强化学习在现实世界中的应用有限。
研究论文的作者说,“尽管深度强化学习领域取得了重大进展,例如Alpha Go、Alpha Fold和GT Sophy,但深度强化学习模型仍未在工业规模上得到广泛采用。另一方面,数据隐私是一个应用非常广泛的研究领域,深度强化学习模型在实际工业应用中的缺乏极大地延迟了这一基础和重要研究领域的研究,导致对强化学习系统的攻击的研究不足。”
随着在现实世界场景中工业规模应用强化学习算法的需求不断增长,从对抗性和算法的角度对解决强化学习算法隐私方面的框架的关注和严格要求变得越来越明显和相关。
深度强化学习中成员推断的挑战
研究论文的作者说,“我们在开发第一代保护隐私的深度强化学习算法方面所做出的努力,使我们意识到从隐私的角度来看,传统机器学习算法和强化学习算法之间存在根本的结构差异。”
研究人员发现,更关键的是,考虑到潜在的隐私后果,深度强化学习与其他学习范式之间的根本差异在为实际应用部署深度强化学习模型方面提出了严峻挑战。
他们说,“基于这一认识,对我们来说最大的问题是:深度强化学习算法对隐私攻击(如成员推断攻击)的脆弱性有多大?现有的成员推理攻击攻击模型是专门为其他学习范式设计的,因此深度强化学习算法对这类攻击的脆弱程度在很大程度上是未知的。鉴于在世界范围内部署对隐私的严重影响,这种对未知事物的好奇心以及提高研究和工业界意识的必要性是这项研究的主要动机。”
在训练过程中,强化学习模型经历了多个阶段,每个阶段都由动作和状态的轨迹或序列组成。因此,一个成功的用于强化学习的成员推理攻击算法必须学习用于训练模型的数据点和轨迹。一方面,这使得针对强化学习系统设计成员推理算法变得更加困难;而另一方面,也使得难以评估强化学习模型对此类攻击的鲁棒性。
作者说,“与其他类型的机器学习相比,在强化学习中成员推理攻击(MIA)很困难,因为在训练过程中使用的数据点具有顺序和时间相关的性质。训练和预测数据点之间的多对多关系从根本上不同于其他学习范式。”
强化学习和其他机器学习范式之间的根本区别,使得在设计和评估用于深度强化学习的成员推理攻击时以新的方式思考至关重要。
设计针对强化学习系统的成员推理攻击
在他们的研究中,研究人员专注于非策略强化学习算法,其中数据收集和模型训练过程是分开的。强化学习使用“重放缓冲区”来解相关输入轨迹,并使强化学习代理可以从同一组数据中探索许多不同的轨迹。
非策略强化学习对于许多实际应用程序尤其重要,在这些应用程序中,训练数据预先存在并提供给正在训练强化学习模型的机器学习团队。非策略强化学习对于创建成员推理攻击模型也至关重要。
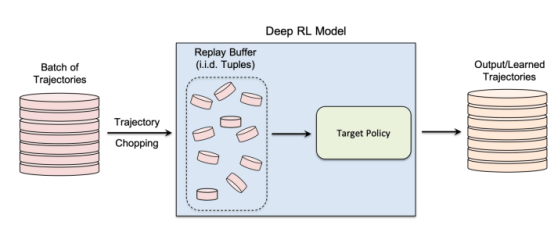
非策略强化学习使用“重放缓冲区”在模型训练期间重用先前收集的数据
作者说,“探索和开发阶段在真正的非策略强化学习模型中是分离的。因此,目标策略不会影响训练轨迹。这种设置特别适合在黑盒环境中设计成员推理攻击框架时,因为攻击者既不知道目标模型的内部结构,也不知道用于收集训练轨迹的探索策略。”
在黑盒成员推理攻击中,攻击者只能观察训练好的强化学习模型的行为。在这种特殊情况下,攻击者假设目标模型已经从一组私有数据生成的轨迹上进行了训练,这就是非策略强化学习的工作原理。
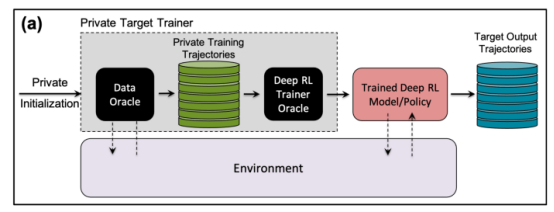
在研究中,研究人员选择了“批量约束深度Q学习”(BCQ),这是一种先进的非策略强化学习算法,在控制任务中表现出卓越的性能。然而他们表示,他们的成员推理攻击技术可以扩展到其他非策略强化学习模型。
攻击者进行成员推理攻击的一种方法是开发“影子模型”。这是一个分类器机器学习模型,它已经在来自与目标模型的训练数据和其他地方的相同分布的数据混合上进行了训练。在训练之后,影子模型可以区分属于目标机器学习模型训练集的数据点和模型以前未见过的新数据。由于目标模型训练的顺序性,为强化学习代理创建影子模型很棘手。研究人员通过几个步骤实现了这一点。
首先,他们为强化学习模型训练器提供一组新的非私有数据轨迹,并观察目标模型生成的轨迹。然后,攻击训练器使用训练和输出轨迹来训练机器学习分类器,以检测在目标强化学习模型训练中使用的输入轨迹。最后,为分类器提供了新的轨迹,将其分类为训练成员或新的数据示例。
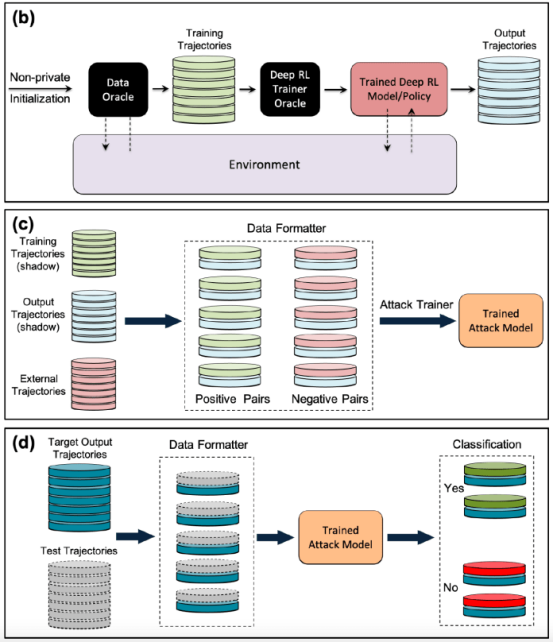
针对强化学习模型训练成员推理攻击的影子模型
针对强化学习系统测试成员推理攻击
研究人员以不同的模式测试了他们的成员推理攻击,其中包括不同的轨迹长度、单轨迹与多轨迹,以及相关轨迹与去相关轨迹。
研究人员在他们的论文中指出:“研究结果表明,我们提出的攻击框架在推断强化学习模型训练数据点方面非常有效……获得的结果表明,采用深度强化学习时存在很高的隐私风险。”
他们的研究结果表明,具有多条轨迹的攻击比单一轨迹的攻击更有效,并且随着轨迹变长并相互关联,攻击的准确性也会提高。
作者说,“自然设置当然是个体模型,攻击者有兴趣在用于训练目标强化学习策略的训练集中识别特定个体的存在(在强化学习中设置整个轨迹)。然而,成员推理攻击(MIA)在集体模式下的更好表现表明,除了由训练策略的特征捕获的时间相关性之外,攻击者还可以利用目标策略的训练轨迹之间的互相关性。”
研究人员表示,这也意味着攻击者需要更复杂的学习架构和更复杂的超参数调整,以利用训练轨迹之间的互相关和轨迹内的时间相关性。
研究人员说,“了解这些不同的攻击模式,可以让我们更深入地了解对数据安全和隐私的影响,因为它可以让我们更好地了解可能发生攻击的不同角度以及对隐私泄露的影响程度。”
现实世界中针对强化学习系统的成员推理攻击
研究人员测试了他们对基于Open AIGym和MuJoCo物理引擎的三项任务训练的强化学习模型的攻击。
研究人员说,“我们目前的实验涵盖了三个高维运动任务,Hopper、Half-Cheetah和Ant,这些任务都属于机器人模拟任务,主要推动将实验扩展到现实世界的机器人学习任务。”
该论文的研究人员表示,另一个应用成员推断攻击的令人兴奋的方向是对话系统,例如亚马逊Alexa、苹果Siri和谷歌助理。在这些应用程序中,数据点由聊天机器人和最终用户之间的完整交互轨迹呈现。在这一设置中,聊天机器人是经过训练的强化学习策略,用户与机器人的交互形成输入轨迹。
作者说,“在这种情况下,集体模式就是自然环境。换句话说,当且仅当攻击者正确推断出代表训练集中用户的一批轨迹时,攻击者才能推断出用户在训练集中的存在。”
该团队正在探索此类攻击可能影响强化学习系统的其他实际应用程序。他们可能还会研究这些攻击如何应用于其他环境中的强化学习。
作者说,“这一研究领域的一个有趣扩展是在白盒环境中针对深度强化学习模型研究成员推理攻击,其中目标策略的内部结构也为攻击者所知。”
研究人员希望他们的研究能够阐明现实世界中强化学习应用程序的安全和隐私问题,并提高机器学习社区的意识,以便在该领域开展更多研究。
原文标题:Reinforcement learning models are prone to membership inference attacks,作者:Ben Dickson
© 版权声明
文章版权归作者所有,未经允许请勿转载。


