
一行代码,炼丹2倍速!PyTorch 2.0惊喜问世,LeCun激情转发
12月2日,PyTorch 2.0正式发布!
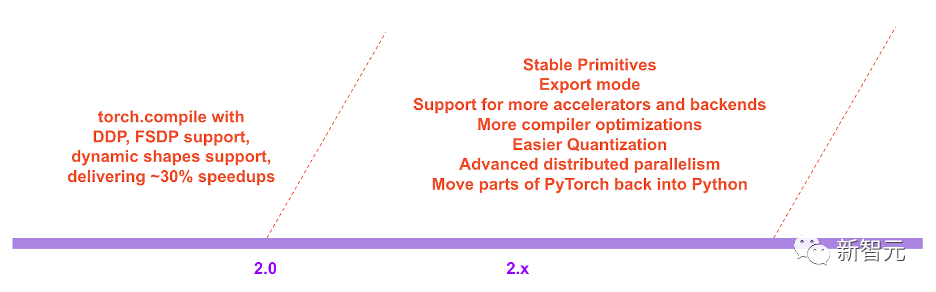
这次的更新不仅将PyTorch的性能推到了新的高度,同时也加入了对动态形状和分布式的支持。
此外,2.0系列还会将PyTorch的部分代码从C++移回Python。

目前,PyTorch 2.0还处在测试阶段,预计第一个稳定版本会在2023年3月初面世。

PyTorch 2.x:更快、更Python!
在过去的几年里,PyTorch从1.0到最近的1.13进行了创新和迭代,并转移到新成立的PyTorch基金会,成为Linux基金会的一部分。
当前版本的PyTorch所面临的挑战是,eager-mode难以跟上不断增长的GPU带宽和更疯狂的模型架构。
而PyTorch 2.0的诞生,将从根本上改变和提升了PyTorch在编译器级别下的运行方式。
众所周知,PyTorch中的(Py)来自于数据科学中广泛使用的开源Python编程语言。
然而,PyTorch的代码却并没有完全采用Python,而是把一部分交给了C++。
不过,在今后的2.x系列中,PyTorch项目团队计划将与torch.nn有关的代码移回到Python中。
除此之外,由于PyTorch 2.0是一个完全附加的(和可选的)功能,因此2.0是100%向后兼容的。
也就是说,代码库是一样的,API也是一样的,编写模型的方式也是一样的。
更多的技术支持
- TorchDynamo
使用Python框架评估钩子安全地捕获PyTorch程序,这是团队5年来在graph capture方面研发的一项重大创新。
- AOTAutograd
重载了PyTorch的autograd引擎,作为一个追踪的autodiff,用于生成超前的反向追踪。
- PrimTorch
将约2000多个PyTorch运算符归纳为约250个原始运算符的封闭集,开发人员可以针对这些运算符构建一个完整的PyTorch后端。大大降低了编写PyTorch功能或后端的障碍。
- TorchInductor
一个深度学习编译器,可以为多个加速器和后端生成快速代码。对于英伟达的GPU,它使用OpenAI Triton作为关键构建模块。
值得注意的是,TorchDynamo、AOTAutograd、PrimTorch和TorchInductor都是用Python编写的,并支持动态形状。
更快的训练速度
通过引入新的编译模式「torch.compile」,PyTorch 2.0用一行代码,就可以加速模型的训练。
这里不用任何技巧,只需运行torch.compile()即可,仅此而已:
opt_module = torch.compile(module)
为了验证这些技术,团队精心打造了测试基准,包括图像分类、物体检测、图像生成等任务,以及各种NLP任务,如语言建模、问答、序列分类、推荐系统和强化学习。其中,这些基准可以分为三类:
- 来自HuggingFace Transformers的46个模型
- 来自TIMM的61个模型:Ross Wightman收集的最先进的PyTorch图像模型
- 来自TorchBench的56个模型:github的一组流行代码库
测试结果表明,在这163个跨越视觉、NLP和其他领域的开源模型上,训练速度得到了38%-76%的提高。
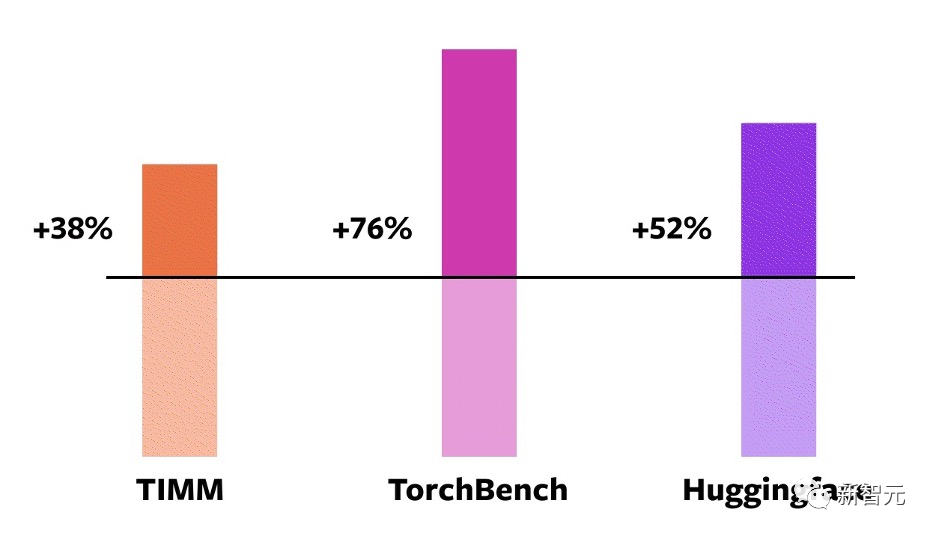
在NVIDIA A100 GPU上的对比
此外,团队还在一些流行的开源PyTorch模型上进行了基准测试,并获得了从30%到2倍的大幅加速。
开发者Sylvain Gugger表示:「只需添加一行代码,PyTorch 2.0就能在训练Transformers模型时实现1.5倍到2.0倍的速度提升。这是自混合精度训练问世以来最令人兴奋的事情!」
技术概述
PyTorch的编译器可以分解成三个部分:
- 图的获取
- 图的降低
- 图的编译
其中,在构建PyTorch编译器时,图的获取是更难的挑战。
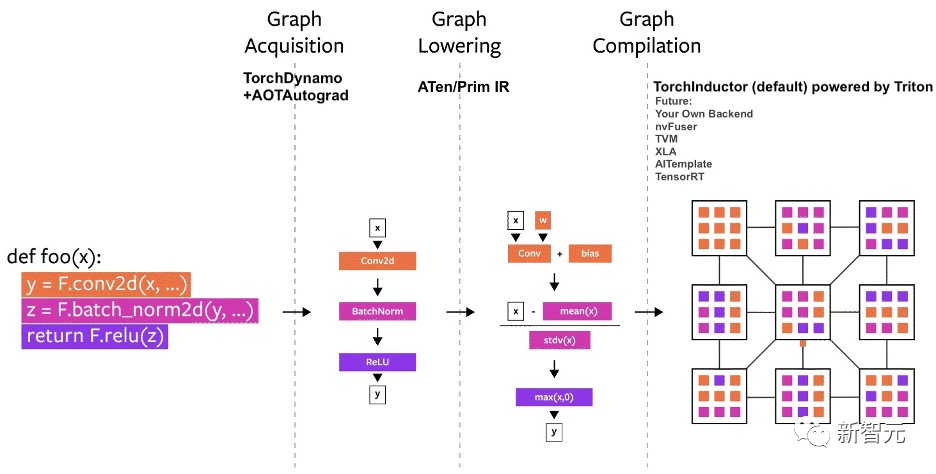
TorchDynamo
今年年初,团队便开始了TorchDynamo的工作,这种方法使用了PEP-0523中引入的CPython功能,称为框架评估API。
为此,团队采取了一种数据驱动的方法来验证TorchDynamo在graph capture上的有效性——通过使用7000多个用PyTorch编写的Github项目,来作为验证集。
结果显示,TorchDynamo在99%的时间里都能正确、安全地进行graph capture,而且开销可以忽略不计。
TorchInductor
对于PyTorch 2.0的新编译器后端,团队从用户如何编写高性能的自定义内核中得到了灵感:越来越多地使用Triton语言。
TorchInductor使用Pythonic定义的逐个循环级别的IR来自动将PyTorch模型映射到GPU上生成的Triton代码和CPU上的C++/OpenMP。
TorchInductor的核心循环级IR只包含大约50个运算符,而且它是用Python实现的,这使得它很容易得到扩展。
AOTAutograd
想要加速训练,就不仅需要捕获用户级代码,而且还要捕获反向传播。
AOTAutograd可以利用PyTorch的torch_dispatch扩展机制来追踪Autograd引擎,「提前」捕获反向传播,进而能够使用TorchInductor来加速前向和后向通道。
PrimTorch
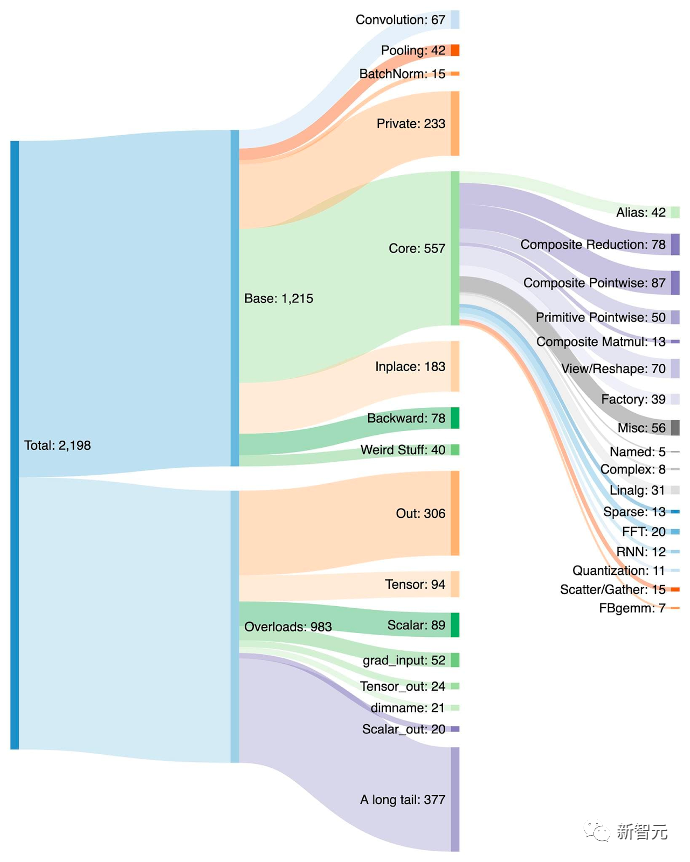
PyTorch有1200多个运算符,如果考虑到每个运算符的各种重载,则有2000多个。因此,编写后端或跨领域的功能成为一项耗费精力的工作。
在PrimTorch项目中,团队定义了两个更小更稳定的运算符集:
- Prim ops有大约~250个运算符,适合于编译器。由于足够低级,因此只需将它们融合在一起以获得良好的性能。
- ATen ops有大约~750个典型的运算符,适合于按原样输出。这些适合于已经在ATen级别上集成的后端,或者没有编译的后端,从而恢复像Prim ops这样的低级别运算符集的性能。
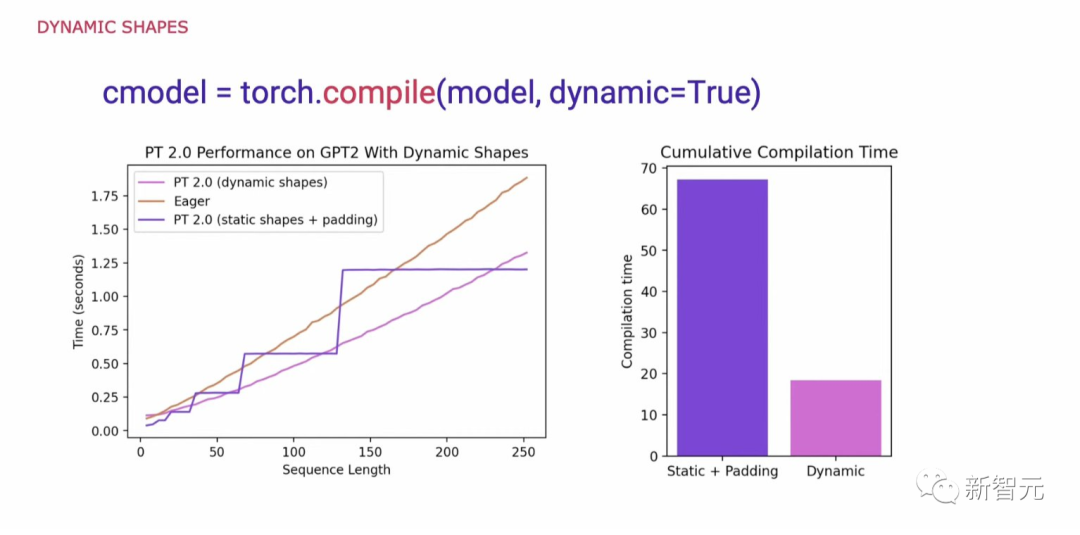
动态形状
在研究支持PyTorch代码通用性的必要条件时,一个关键要求是支持动态形状,并允许模型接受不同大小的张量,而不会在每次形状变化时引起重新编译。
在不支持动态形状的情况下,一个常见的解决方法是将其填充到最接近的2次方。然而,正如我们从下面的图表中所看到的,它产生了大量的性能开销,同时也带来了明显更长的编译时间。
现在,有了对动态形状的支持,PyTorch 2.0也就获得了比Eager高出了最多40%的性能。
最后,在PyTorch 2.x的路线图中,团队希望在性能和可扩展性方面进一步推动编译模式的发展。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


