
利用统计测试和机器学习分析和预测太阳能发电的性能测试和对比
本文将讨论通过使用假设测试、特征工程、时间序列建模方法等从数据集中获得有形价值的技术。我还将解决不同时间序列模型的数据泄漏和数据准备等问题,并且对常见的三种时间序列预测进行对比测试。
介绍
时间序列预测是一个经常被研究的话题,我们这里使用使用两个太阳能电站的数据,研究其规律进行建模。首先将它们归纳为两个问题来解决这些问题:
- 是否有可能识别出性能欠佳的太阳能组件?
- 是否可以预报两天的太阳能发电量?
在继续回答这些问题之前,让我们先了解太阳能发电厂是如何发电的。
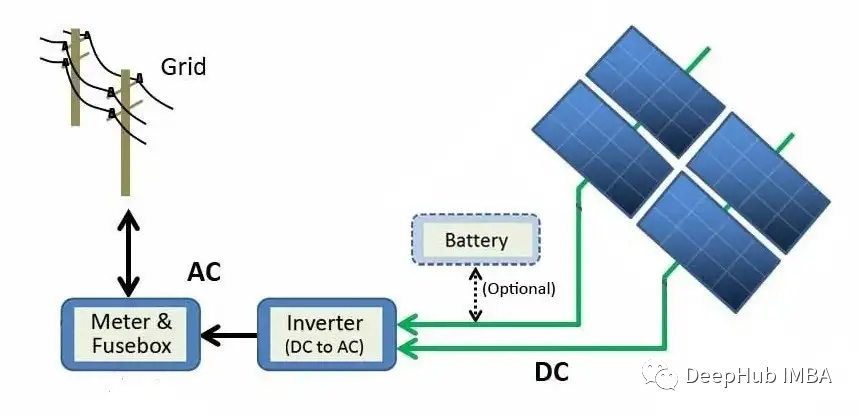
上图描述了从太阳能电池板模块到电网的发电过程。太阳能通过光电效应直接转化为电能。当硅(太阳能电池板中最常见的半导体材料)等材料暴露在光线下时,光子(电磁能量的亚原子粒子)被吸收并释放自由电子,从而产生直流电(DC)。使用逆变器,直流电被转换成交流电(AC)并发送到电网,在那里它可以被分配到家庭。
数据
原始数据由每个太阳能发电厂的两个逗号分隔值(CSV)文件组成。一份文件显示了发电过程,另一份文件显示了太阳能发电厂传感器记录的测量数据。每个太阳能发电厂的两个数据集都被整理成一个pandas的df。
太阳能发电厂1号(SP1)和太阳能发电厂2号(SP2)的数据每15分钟收集一次,从2020年5月15日到2020年6月18日。SP1和SP2数据集都包含相同的变量。
- Date Time -间隔15分钟
- Ambient temperature-模块周围空气的温度
- Module temperature-模块的温度
- Irradiation——模块上的辐射
- DC Power (kW) -直流
- AC Power (kW) -交流
- Daily Yield-每日发电量总和
- Total Yield-逆变器的累计产量
- Plant ID -太阳能电站的唯一标识
- Module ID -每个模块的唯一标识
天气传感器用于记录每个太阳能发电厂的环境温度、组件温度和辐射。
对于这个数据集直流功率将是因变量(目标变量)。我们目标是的试图找到性能不佳的太阳能模块。
两个独立的df用于分析和预测。唯一的区别是用于预测的数据被重新采样为每小时的间隔,而用于分析的数据帧包含15分钟的间隔。
首先我们删除Plant ID,因为它对试图回答上述问题没有任何价值。Module ID也从预测数据集中删除。表1和表2显示了数据示例。


在继续分析数据之前,我们对太阳能发电厂做了一些假设,包括:
- 数据采集仪器无故障
- 模块定期清洗(忽略维护的影响)
- 两个太阳能电站周围都没有遮挡问题
探索性数据分析(EDA)
对于数据科学的新手来说,EDA是通过绘图可视化和执行统计测试来理解数据的关键一步。我们首先通过绘制SP1和SP2的DC和AC,可以观察到每个太阳能发电厂的性能。
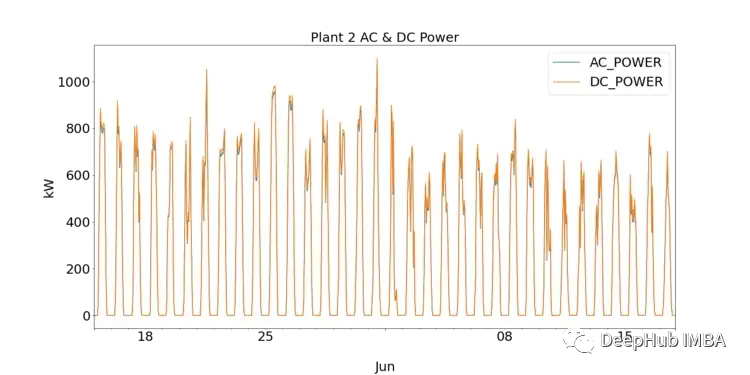
SP1显示的直流功率比sp2高一个数量级。假设SP1采集的数据是正确的,用于记录数据的仪器没有故障,这就说明SP1中逆变器需要进行更深入的研究
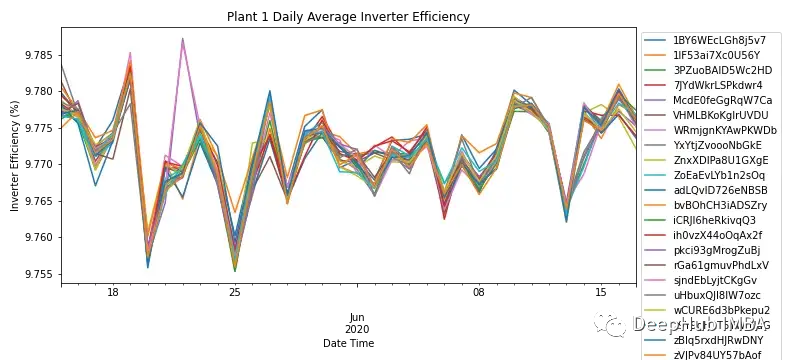
通过按每个模块的日频率聚合AC和DC功率,图3显示了SP1中所有模块的逆变器效率。根据领域内知识,太阳能逆变器的效率应该在93-96%之间。由于所有模块的效率范围为9.76% – 9.79%,这里可以说明需要调查逆变器的性能,以及是否需要更换。
由于SP1显示了逆变器的问题,因此仅在SP2上进行了进一步的分析。
尽管这一小段分析是我们花了更多的时间对逆变器进行研究,但它并没有回答确定太阳能模块性能的主要问题。
由于SP2的逆变器正常工作,可以通过深入挖掘数据,来识别和调查任何异常情况。
图4中显示了模块温度和环境温度之间的关系,并且有模块温度极高的情况。
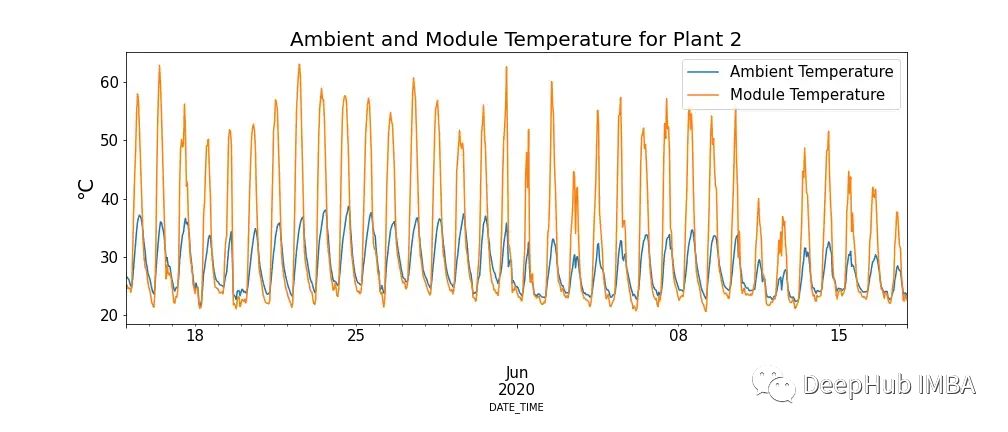
这看起来似乎违反我们的认知,但是可以看到高温对太阳能电池板的确有负面影响。当光子与太阳能电池内的电子接触时,它们会释放自由电子,但在更高的温度下,更多的电子已经处于激发态,这降低了电池板可以产生的电压,进而降低了效率。
考虑到这一现象,下面的图5显示了SP2的模块温度和直流功率(环境温度低于模块温度的数据点和模块运行数量较少的一天中的时间已经过过滤,以防止数据倾斜)。
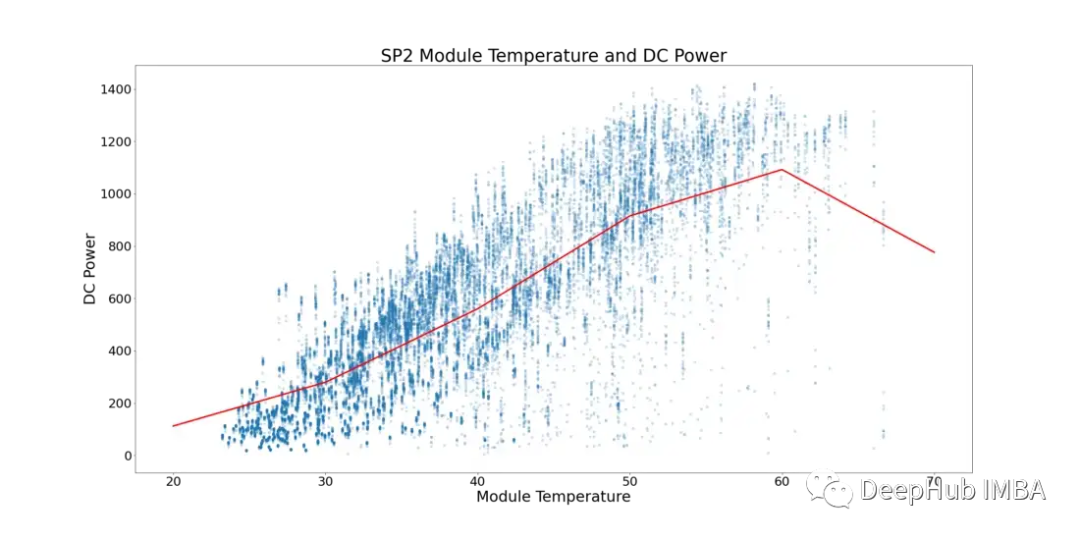
在图5中,红线表示平均温度。这里可以看到有一个明确的临界点和直流电源停滞的迹象。在~52°C开始平稳。为了找到性能次优的太阳能模块,所有显示模块温度超过52°C的行都被删除。
下面的图6显示了SP2中每个模块在一天中的直流功率。这样就基本符合了预期,午间发电量较大。但是还有个问题,在运行高峰时期,发电量较低。我们很难总结造成这种情况的原因,因为当天的天气条件可能很差,或者SP2可能需要进行日常的维护等等。
图6中也有低性能模块的迹象。它们可以被识别为图上偏离最近群集的模块(单个数据点)。

为了确定哪些模块表现不佳,我们可以进行统计测试,同时将每个模块的性能与其他模块进行比较,从而确定性能。
每隔15分钟,不同模块的直流电源在同一时间的分布是正态分布,通过假设检验可以确定哪些模块表现不佳。计数是指模块落在99.9%置信区间之外且p值< 0.001的次数。
图7按降序显示了每个模块在统计上显著低于同期其他模块的次数。

从图7中可以清楚地看出,模块’ Quc1TzYxW2pYoWX ‘是有问题的。这些信息可以提供给SP2的相关工作人员,调查原因。
建模
下面我们开始使用三种不同的时间序列算法:SARIMA、XGBoost和CNN-LSTM,进行建模并比较
对于所有三个模型,都使用预测下一个数据点进行预测。Walk-forward验证是一种用于时间序列建模的技术,因为随着时间的推移,预测会变得不那么准确,因此更实用的方法是在实际数据可用时,用实际数据重新训练模型。
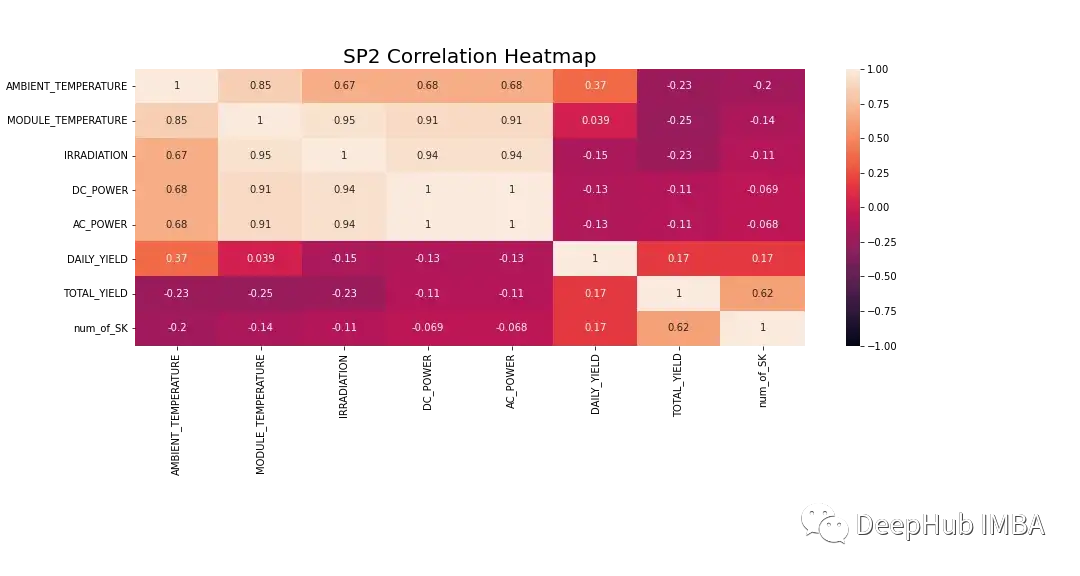
在建模之前需要更详细地研究数据。图8显示了SP2数据集中所有特征的相关热图。热图显示了因变量直流功率,与模块温度、辐照和环境温度的强相关性。这些特征可能在预测中发挥重要作用。
在下面的热图中,交流功率显示皮尔森相关系数为1。为了防止数据泄漏问题,我们将直流功率从数据中删除。
SARIMA
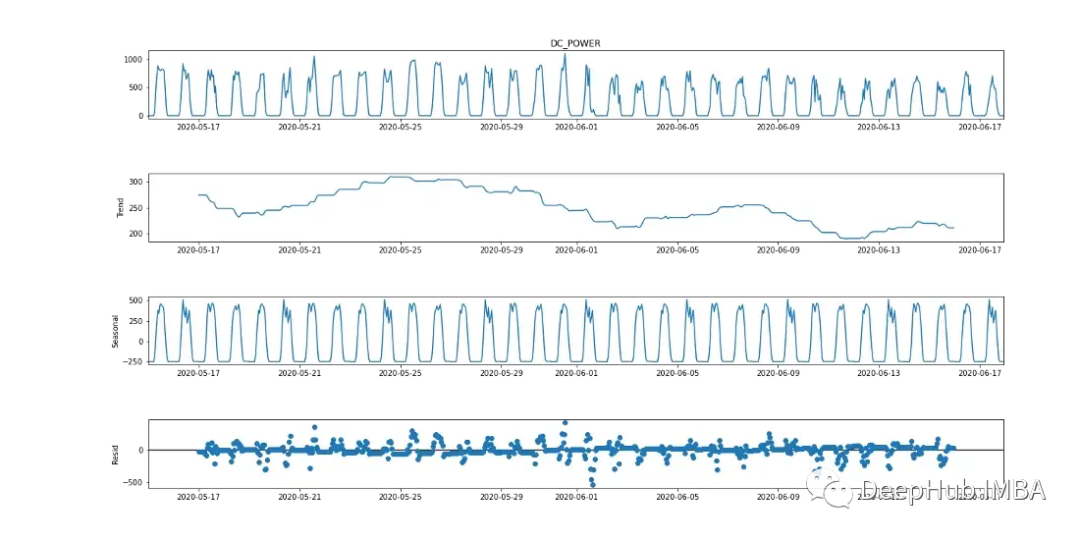
季节自回归综合移动平均(SARIMA)是一种单变量时间序列预测方法。由于目标变量显示出24小时循环周期的迹象,SARIMA是一个有效的建模选项,因为它考虑了季节影响。这可以从下面的季节分解图中观察到。
SARIMA算法要求数据是平稳的。有多种方法来检验数据是否平稳,例如统计检验(增强迪基-福勒检验),汇总统计(比较数据的不同部分的均值/方差)和可视化分析数据。在建模之前进行多次测试是很重要的。
增强迪基-富勒(ADF)检验是一种“单位根检验”,用于确定时间序列是否平稳。从根本上说,这是一个统计显著性检验,其中存在一个零假设和替代假设,并根据得出的p值得出结论。
零假设:时间序列数据是非平稳的。
替代假设:时间序列数据是平稳的。
在我们的例子中,如果p值≤0.05,我们可以拒绝原假设,并确认数据没有单位根。
from statsmodels.tsa.stattools import adfuller
result = adfuller(plant2_dcpower.values)
print('ADF Statistic: %f' % result[0])
print('p-value: %f' % result[1])
print('Critical Values:')
for key, value in result[4].items():
print('\t%s: %.3f' % (key, value))

从ADF检验来看,p值为0.000553,< 0.05。根据这一统计数据,可以认为该数据是稳定的。然而,查看图2(最上面的图),有明显的季节性迹象(对于被认为是平稳的时间序列数据,不应该有季节性和趋势的迹象),这说明数据是非平稳的。因此,运行多个测试非常重要。
为了用SARIMA对因变量建模,时间序列需要是平稳的。如图9(第一个和第三个图)所示,直流电有明显的季节性迹象。取第一个差值[t-(t-1)]去除季节性成分,如图10所示,因为它看起来类似于正态分布。数据现在是平稳的,适用于SARIMA算法。
SARIMA的超参数包括p(自回归阶数)、d(差阶数)、q(移动平均阶数)、p(季节自回归阶数)、d(季节差阶数)、q(季节移动平均阶数)、m(季节周期的时间步长)、trend(确定性趋势)。
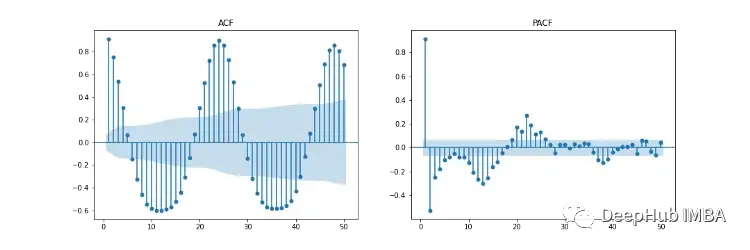
图11显示了自相关(ACF)、部分自相关(PACF)和季节性ACF/PACF图。ACF图显示了时间序列与其延迟版本之间的相关性。PACF显示了时间序列与其滞后版本之间的直接相关性。蓝色阴影区域表示置信区间。SACF和SPACF可以通过从原始数据中取季节差(m)来计算,在本例中为24,因为在ACF图中有一个明显的24小时的季节效应。
根据我们的直觉,超参数的起点可以从ACF和PACF图中推导出来。如ACF和PACF均呈逐渐下降的趋势,即自回归阶数(p)和移动平均阶数(q)均大于0。p和p可以通过分别观察PCF和SPCF图,并计算滞后值不显著之前具有统计学显著性的滞后数来确定。同样,q和q可以在ACF和SACF图中找到。
差阶(d)可以通过使数据平稳的差的数量来确定。季节差异阶数(D)是根据从时间序列中去除季节性成分所需的差异数来估计的。
这些超参数选择可以看这篇文章:https://arauto.readthedocs.io/en/latest/how_to_choose_terms.html
也可以采用网格搜索方法进行超参数优化,根据最小均方误差(MSE)选择最优超参数,包括p = 2, d = 0, q = 4, p = 2, d = 1, q = 6, m = 24, trend = ‘ n ‘(无趋势)。
from time import time
from sklearn.metrics import mean_squared_error
from statsmodels.tsa.statespace.sarimax import SARIMAX
configg = [(2, 1, 4), (2, 1, 6, 24), 'n']
def train_test_split(data, test_len=48):
"""
Split data into training and testing.
"""
train, test = data[:-test_len], data[-test_len:]
return train, test
def sarima_model(data, cfg, test_len, i):
"""
SARIMA model which outputs prediction and model.
"""
order, s_order, t = cfg[0], cfg[1], cfg[2]
model = SARIMAX(data, order=order, seasonal_order=s_order, trend=t,
enforce_stationarity=False, enfore_invertibility=False)
model_fit = model.fit(disp=False)
yhat = model_fit.predict(len(data))
if i + 1 == test_len:
return yhat, model_fit
else:
return yhat
def walk_forward_val(data, cfg):
"""
A walk forward validation technique used for time series data. Takes current value of x_test and predicts
value. x_test is then fed back into history for the next prediction.
"""
train, test = train_test_split(data)
pred = []
history = [i for i in train]
test_len = len(test)
for i in range(test_len):
if i + 1 == test_len:
yhat, s_model = sarima_model(history, cfg, test_len, i)
pred.append(yhat)
mse = mean_squared_error(test, pred)
return pred, mse, s_model
else:
yhat = sarima_model(history, cfg, test_len, i)
pred.append(yhat)
history.append(test[i])
pass
if __name__ == '__main__':
start_time = time()
sarima_pred_plant2, sarima_mse, s_model = walk_forward_val(plant2_dcpower, configg)
time_len = time() - start_time
print(f'SARIMA runtime: {round(time_len/60,2)} mins')
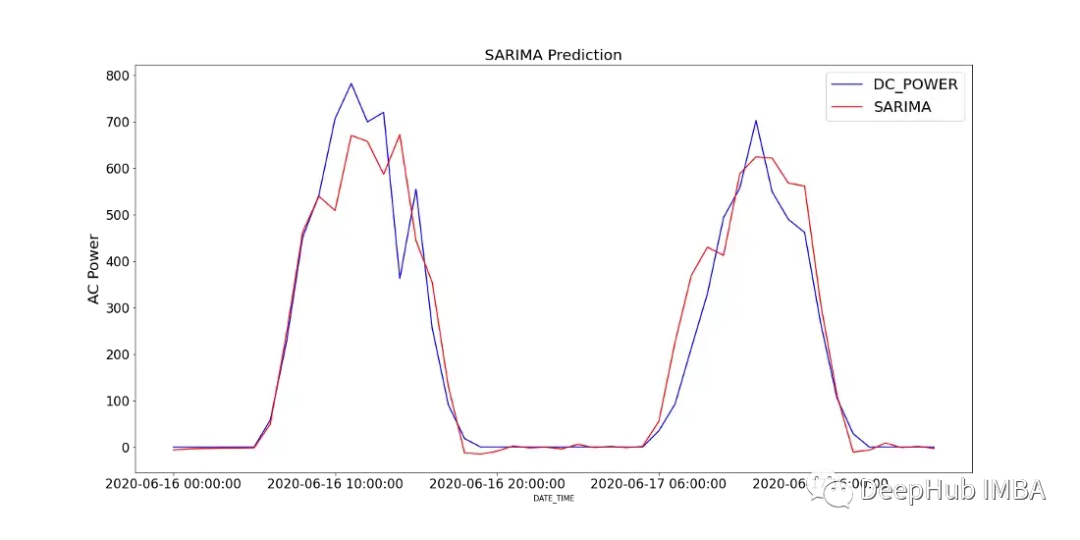
图12显示了SARIMA模型的预测值与SP2 2天内记录的直流功率的比较。
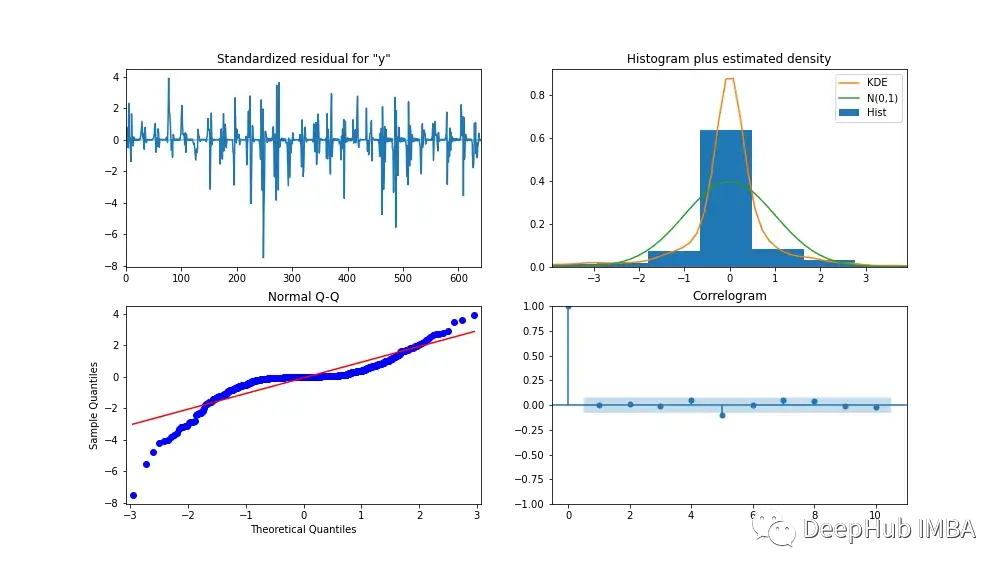
为了分析模型的性能,图13显示了模型诊断。相关图显示在第一个滞后后几乎没有相关性,下面的直方图显示在平均值为零附近的正态分布。由此我们可以说模型无法从数据中收集到进一步的信息。
XGBoost
XGBoost (eXtreme Gradient Boosting)是一种梯度增强决策树算法。它使用集成方法,其中添加新的决策树模型来修改现有的决策树分数。与SARIMA不同的是,XGBoost是一种多元机器学习算法,这意味着该模型可以采用多特征来提高模型性能。
我们采用特征工程提高模型精度。还创建了3个附加特性,其中包括AC和DC功率的滞后版本,分别为S1_AC_POWER和S1_DC_POWER,以及通过交流功率除以直流功率的总体效率EFF。并将AC_POWER和MODULE_TEMPERATURE从数据中删除。图14通过增益(使用一个特征的分割的平均增益)和权重(一个特征在树中出现的次数)显示了特征的重要性级别。

通过网格搜索确定建模使用的超参数,结果为:*learning rate = 0.01, number of estimators = 1200, subsample = 0.8, colsample by tree = 1, colsample by level = 1, min child weight = 20 and max depth = 10
我们使用MinMaxScaler将训练数据缩放到0到1之间(也可以试验其他缩放器,如log-transform和standard-scaler,这取决于数据的分布)。通过将所有自变量向后移动一段时间,将数据转换为监督学习数据集。
import numpy as np
import pandas as pd
import xgboost as xgb
from sklearn.preprocessing import MinMaxScaler
from time import time
def train_test_split(df, test_len=48):
"""
split data into training and testing.
"""
train, test = df[:-test_len], df[-test_len:]
return train, test
def data_to_supervised(df, shift_by=1, target_var='DC_POWER'):
"""
Convert data into a supervised learning problem.
"""
target = df[target_var][shift_by:].values
dep = df.drop(target_var, axis=1).shift(-shift_by).dropna().values
data = np.column_stack((dep, target))
return data
def xgb_forecast(train, x_test):
"""
XGBOOST model which outputs prediction and model.
"""
x_train, y_train = train[:,:-1], train[:,-1]
xgb_model = xgb.XGBRegressor(learning_rate=0.01, n_estimators=1500, subsample=0.8,
colsample_bytree=1, colsample_bylevel=1,
min_child_weight=20, max_depth=14, objective='reg:squarederror')
xgb_model.fit(x_train, y_train)
yhat = xgb_model.predict([x_test])
return yhat[0], xgb_model
def walk_forward_validation(df):
"""
A walk forward validation approach by scaling the data and changing into a supervised learning problem.
"""
preds = []
train, test = train_test_split(df)
scaler = MinMaxScaler(feature_range=(0,1))
train_scaled = scaler.fit_transform(train)
test_scaled = scaler.transform(test)
train_scaled_df = pd.DataFrame(train_scaled, columns = train.columns, index=train.index)
test_scaled_df = pd.DataFrame(test_scaled, columns = test.columns, index=test.index)
train_scaled_sup, test_scaled_sup = data_to_supervised(train_scaled_df), data_to_supervised(test_scaled_df)
history = np.array([x for x in train_scaled_sup])
for i in range(len(test_scaled_sup)):
test_x, test_y = test_scaled_sup[i][:-1], test_scaled_sup[i][-1]
yhat, xgb_model = xgb_forecast(history, test_x)
preds.append(yhat)
np.append(history,[test_scaled_sup[i]], axis=0)
pred_array = test_scaled_df.drop("DC_POWER", axis=1).to_numpy()
pred_num = np.array([pred])
pred_array = np.concatenate((pred_array, pred_num.T), axis=1)
result = scaler.inverse_transform(pred_array)
return result, test, xgb_model
if __name__ == '__main__':
start_time = time()
xgb_pred, actual, xgb_model = walk_forward_validation(dropped_df_cat)
time_len = time() - start_time
print(f'XGBOOST runtime: {round(time_len/60,2)} mins')
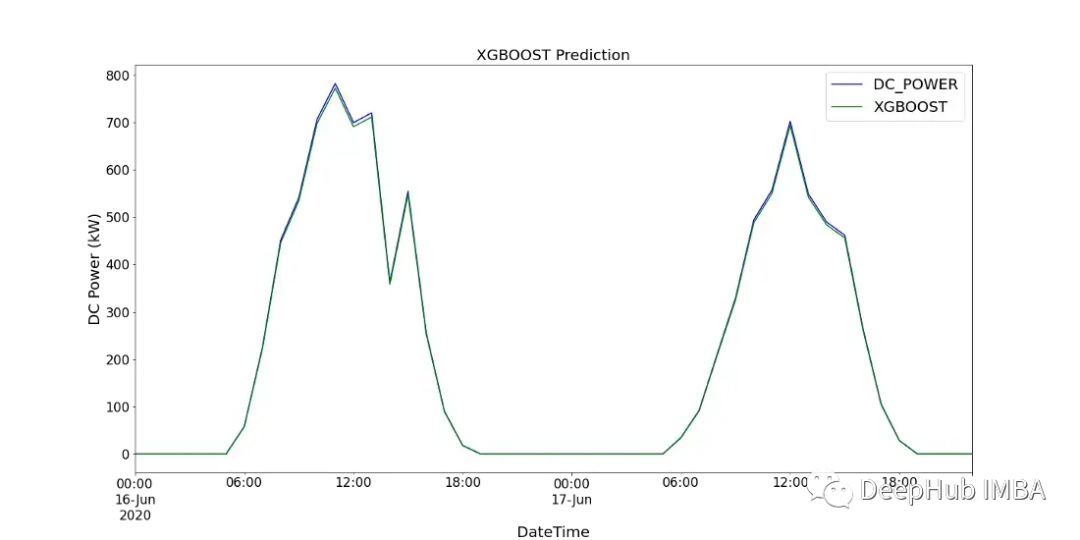
图15显示了XGBoost模型的预测值与SP2 2天内记录的直流功率的比较。
CNN-LSTM
CNN-LSTM (convolutional Neural Network Long – Short-Term Memory)是两种神经网络模型的混合模型。CNN是一种前馈神经网络,在图像处理和自然语言处理方面表现出了良好的性能。它还可以有效地应用于时间序列数据的预测。LSTM是一种序列到序列的神经网络模型,旨在解决长期存在的梯度爆炸/消失问题,使用内部存储系统,允许它在输入序列上积累状态。
在本例中,使用CNN-LSTM作为编码器-解码器体系结构。由于CNN不直接支持序列输入,所以我们通过1D CNN读取序列输入并自动学习重要特征。然后LSTM进行解码。与XGBoost模型类似,使用scikitlearn的MinMaxScaler使用相同的数据并进行缩放,但范围在-1到1之间。对于CNN-LSTM,需要将数据重新整理为所需的结构:[samples, subsequences, timesteps, features],以便可以将其作为输入传递给模型。
由于我们希望为每个子序列重用相同的CNN模型,因此使用timedidistributedwrapper对每个输入子序列应用一次整个模型。在下面的图16中可以看到最终模型中使用的不同层的模型摘要。
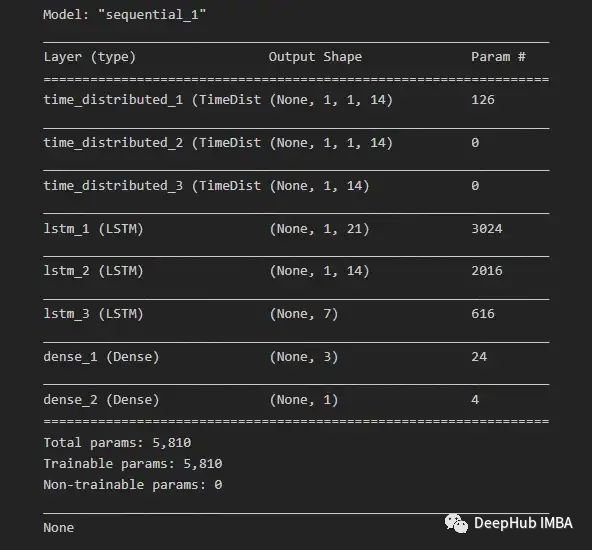
在将数据分解为训练数据和测试数据之后,将训练数据分解为训练数据和验证数据集。在所有训练数据(包括验证数据)的每次迭代之后,模型可以进一步使用这一点来评估模型的性能。
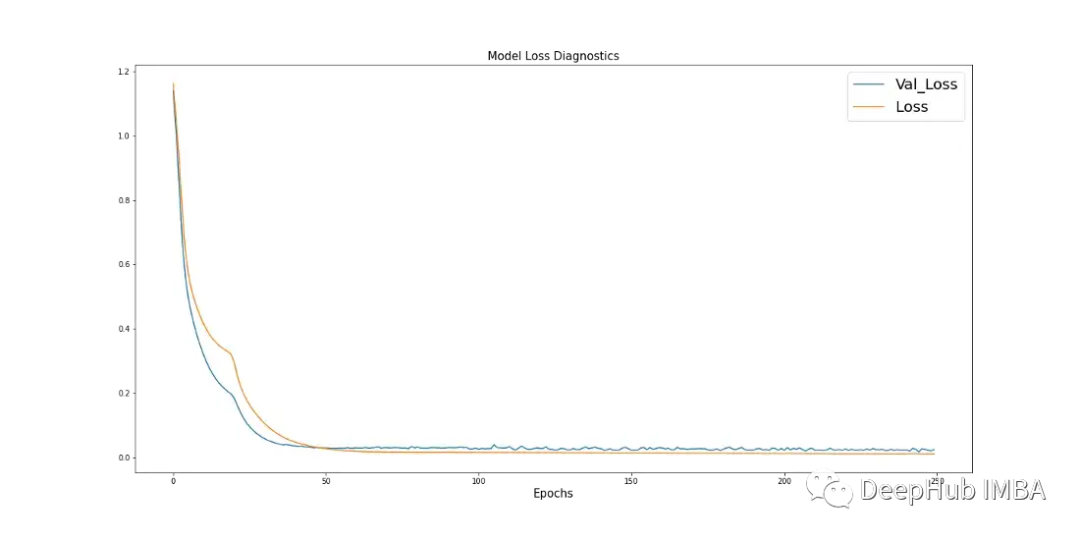
学习曲线是深度学习中使用的一个很好的诊断工具,它显示了模型在每个阶段之后的表现。下面的图17显示了模型如何从数据中学习,并显示了验证数据与训练数据的收敛。这是良好模特训练的标志。
import pandas as pd
import numpy as np
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import MinMaxScaler
import keras
from keras.models import Sequential
from keras.layers.convolutional import Conv1D, MaxPooling1D
from keras.layers import LSTM, TimeDistributed, RepeatVector, Dense, Flatten
from keras.optimizers import Adam
n_steps = 1
subseq = 1
def train_test_split(df, test_len=48):
"""
Split data in training and testing. Use 48 hours as testing.
"""
train, test = df[:-test_len], df[-test_len:]
return train, test
def split_data(sequences, n_steps):
"""
Preprocess data returning two arrays.
"""
x, y = [], []
for i in range(len(sequences)):
end_x = i + n_steps
if end_x > len(sequences):
break
x.append(sequences[i:end_x, :-1])
y.append(sequences[end_x-1, -1])
return np.array(x), np.array(y)
def CNN_LSTM(x, y, x_val, y_val):
"""
CNN-LSTM model.
"""
model = Sequential()
model.add(TimeDistributed(Conv1D(filters=14, kernel_size=1, activation="sigmoid",
input_shape=(None, x.shape[2], x.shape[3]))))
model.add(TimeDistributed(MaxPooling1D(pool_size=1)))
model.add(TimeDistributed(Flatten()))
model.add(LSTM(21, activation="tanh", return_sequences=True))
model.add(LSTM(14, activation="tanh", return_sequences=True))
model.add(LSTM(7, activation="tanh"))
model.add(Dense(3, activation="sigmoid"))
model.add(Dense(1))
model.compile(optimizer=Adam(learning_rate=0.001), loss="mse", metrics=['mse'])
history = model.fit(x, y, epochs=250, batch_size=36,
verbose=0, validation_data=(x_val, y_val))
return model, history
# split and resahpe data
train, test = train_test_split(dropped_df_cat)
train_x = train.drop(columns="DC_POWER", axis=1).to_numpy()
train_y = train["DC_POWER"].to_numpy().reshape(len(train), 1)
test_x = test.drop(columns="DC_POWER", axis=1).to_numpy()
test_y = test["DC_POWER"].to_numpy().reshape(len(test), 1)
#scale data
scaler_x = MinMaxScaler(feature_range=(-1,1))
scaler_y = MinMaxScaler(feature_range=(-1,1))
train_x = scaler_x.fit_transform(train_x)
train_y = scaler_y.fit_transform(train_y)
test_x = scaler_x.transform(test_x)
test_y = scaler_y.transform(test_y)
# shape data into CNN-LSTM format [samples, subsequences, timesteps, features] ORIGINAL
train_data_np = np.hstack((train_x, train_y))
x, y = split_data(train_data_np, n_steps)
x_subseq = x.reshape(x.shape[0], subseq, x.shape[1], x.shape[2])
# create validation set
x_val, y_val = x_subseq[-24:], y[-24:]
x_train, y_train = x_subseq[:-24], y[:-24]
n_features = x.shape[2]
actual = scaler_y.inverse_transform(test_y)
# run CNN-LSTM model
if __name__ == '__main__':
start_time = time()
model, history = CNN_LSTM(x_train, y_train, x_val, y_val)
prediction = []
for i in range(len(test_x)):
test_input = test_x[i].reshape(1, subseq, n_steps, n_features)
yhat = model.predict(test_input, verbose=0)
yhat_IT = scaler_y.inverse_transform(yhat)
prediction.append(yhat_IT[0][0])
time_len = time() - start_time
mse = mean_squared_error(actual.flatten(), prediction)
print(f'CNN-LSTM runtime: {round(time_len/60,2)} mins')
print(f"CNN-LSTM MSE: {round(mse,2)}")
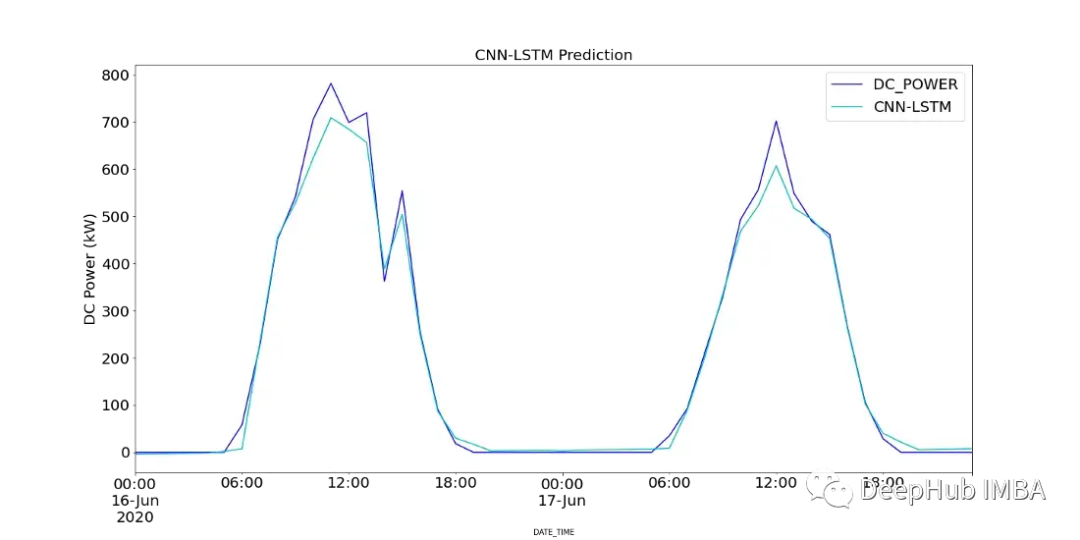
图18显示了CNN-LSTM模型的预测值与SP2 2天内记录的直流功率的对比。
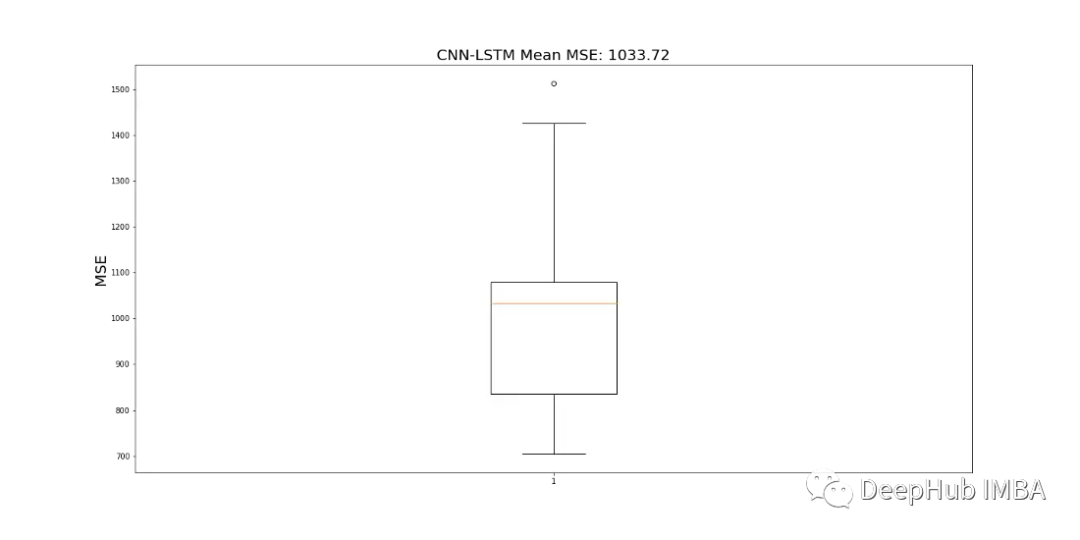
由于CNN-LSTM的随机性,该模型运行10次,并记录一个平均MSE值作为最终值,以判断模型的性能。图19显示了为所有模型运行记录的mse的范围。
结果对比
下表显示了每个模型的MSE (CNN-LSTM的平均MSE)和每个模型的运行时间(以分钟为单位)。
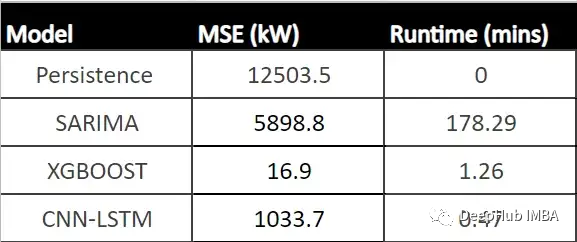
从表中可以看出,XGBoost的MSE最低、运行时第二快,并且与所有其他模型相比具有最佳性能。由于该模型显示了一个可以接受的每小时预测的运行时,它可以成为帮助运营经理决策过程的强大工具。
总结
在本文中我们分析了SP1和SP2,确定SP1性能较低。所以对SP2的进一步调查显示,并且查看了SP2中那些模块性能可能有问题,并使用假设检验来计算每个模块在统计上明显表现不佳的次数,’ Quc1TzYxW2pYoWX ‘模块显示了约850次低性能计数。
我们使用数据训练三个模型:SARIMA、XGBoost和CNN-LSTM。SARIMA表现最差,XGBOOST表现最好,MSE为16.9,运行时间为1.43 min。所以可以说XGBoost在表格数据中还是最优先得选择。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


