
本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
阿里达摩院,又搞事儿了。
这两天,它们发布了一个全新的语音识别模型:
Paraformer。
开发人员直言不讳:这是我们“杀手锏”级的作品。
——不仅识别准确率“屠榜”几大权威数据集,一路SOTA,推理效率上相比传统模型,也最高可提升10倍。
值得一提的是,Paraformer刚宣布就已经开源了。
语音输入法、智能客服、车载导航、会议纪要等场景,它都可以hold住。
怎么做到的?
Paraformer:从自回归到非自回归
我们知道语音一直是人机交互重要研究领域。
而当前语音识别基础框架已从最初复杂的混合语音识别系统,演变为高效便捷的端到端语音识别系统。
其中最具代表性的模型当属自回归端到端模型Transformer,它可以在识别过程中需逐个生成目标文字,实现了较高准确率。
不过Transformer计算并行度低,无法高效结合GPU进行推理。
针对该问题,学术界近年曾提出并行输出目标文字的非自回归模型。
然而这种模型也存在着建模难度和计算复杂度高,准确率有待提升的问题。
达摩院本次推出的Paraformer,首次在工业级应用层面解决了端到端识别效果与效率兼顾的难题。
它属于单轮非自回归模型。
对于这一类模型,现有工作往往聚焦于如何更加准确地预测目标文字个数,如较为典型的Mask CTC,采用CTC预测输出文字个数。
但考虑到现实应用中,语速、口音、静音以及噪声等因素的影响,如何准确的预测目标文字个数以及抽取目标文字对应的声学隐变量仍然是一个比较大的挑战。
另外一方面,通过对比自回归模型与单轮非自回归模型在工业大数据上的错误类型(如下图所示,AR与vanilla NAR),大家发现相比于自回归模型,非自回归模型在预测目标文字个数(插入错误+删除错误)方面差距较小,但是替换错误显著的增加。
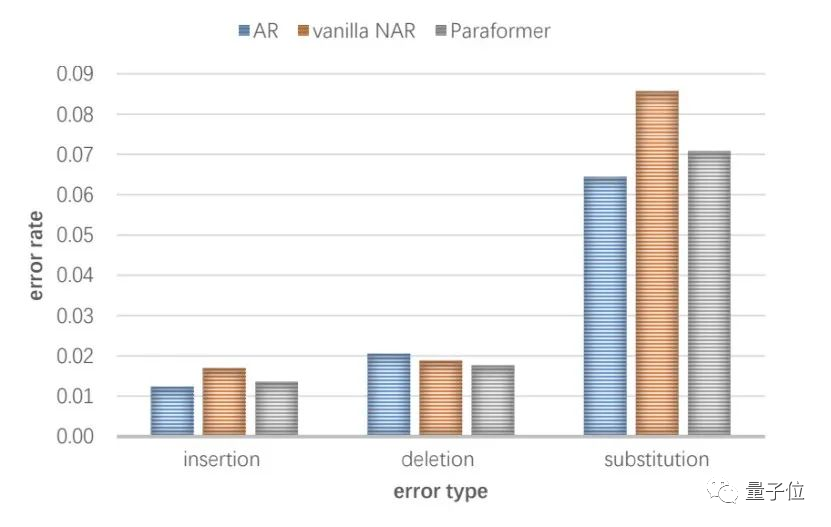
阿里达摩院认为这是由于单轮非自回归模型中条件独立假设导致的语义信息丢失。与此同时,目前非自回归模型主要停留在学术验证阶段,还没有工业大数据上的相关实验与结论。
Paraformer是如何做的呢?
针对第一个问题,阿里达摩院采用一个预测器(Predictor)来预测文字个数并通过Continuous integrate-and-fire (CIF)机制来抽取文字对应的声学隐变量。
针对第二个问题,受启发于机器翻译领域中的Glancing language model(GLM),他们设计了一个基于GLM的 Sampler模块来增强模型对上下文语义的建模。
除此之外,团队还设计了一种生成负样本策略来引入MWER区分性训练。
最终,Paraformer由Encoder、Predictor、Sampler、Decoder与Loss function五部分组成。
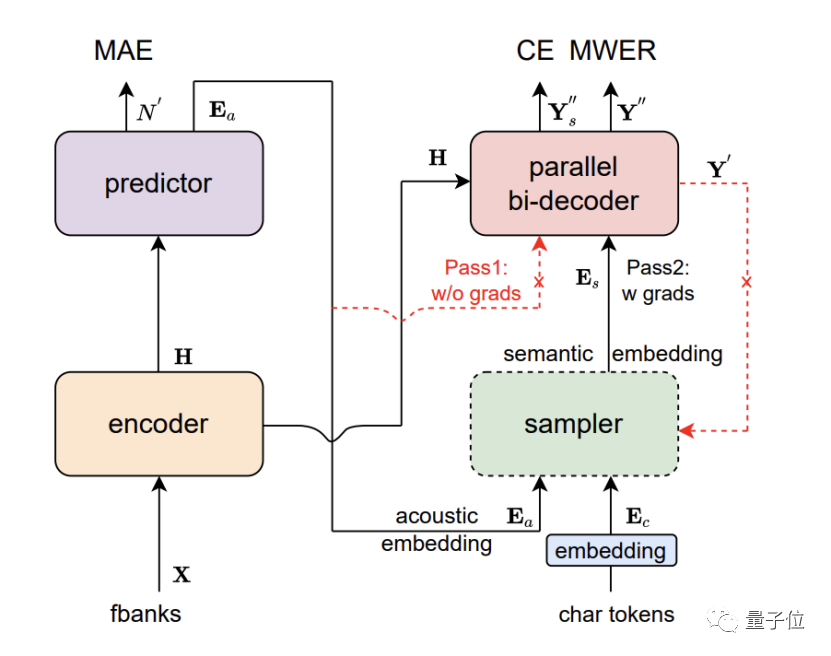
核心点主要包含以下几点:
- Predictor模块:基于CIF 的Predictor 预测语音中目标文字个数以及抽取目标文字对应的声学特征向量;
- Sampler:通过采样,将声学特征向量与目标文字向量变换成含有语义信息的特征向量,配合双向的Decoder来增强模型对于上下文的建模能力;
- 基于负样本采样的MWER训练准则。
效果SOTA,推理效率最高提10倍
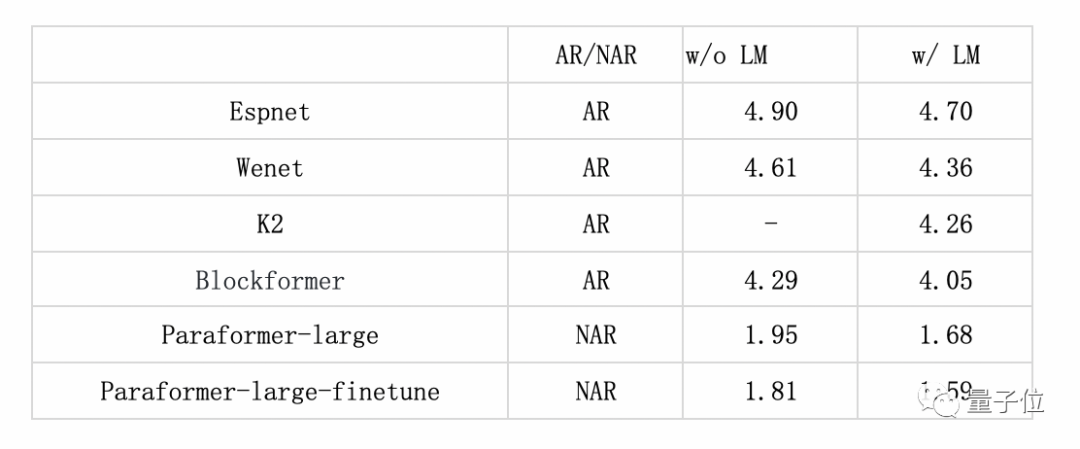
最终,在学术界常用的中文识别评测任务AISHELL-1、AISHELL-2及WenetSpeech等测试集上, Paraformer-large模型均获得了最优效果。
在AISHELL-1上,Paraformer在目前公开发表论文中,为性能(识别效果&计算复杂度)最优的非自回归模型,且Paraformer-large模型的识别准确率远远超于目前公开发表论文中的结果(dev/test:1.75/1.95)。
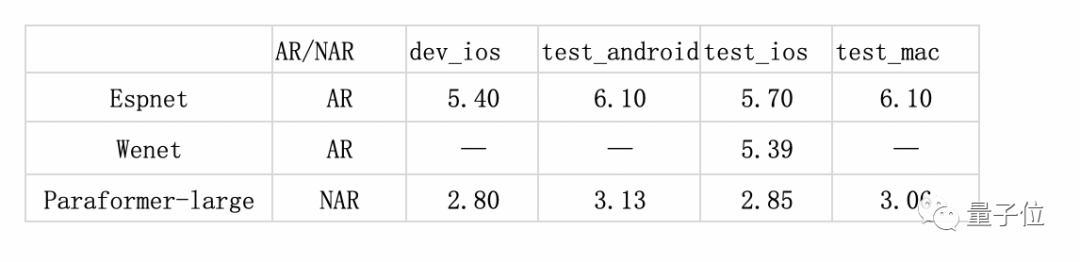
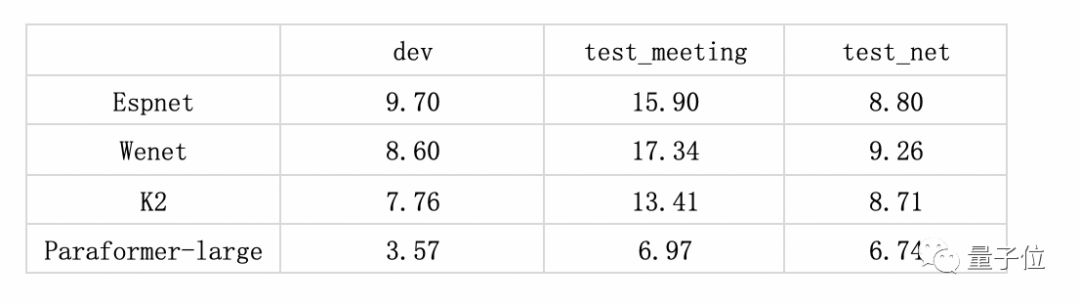
在专业的第三方全网公共云中文语音识别评测SpeechIO TIOBE白盒测试中,Paraformer-large识别准确率超过98%,是目前公开测评中准确率最高的中文语音识别模型。

配合GPU推理,不同版本的Paraformer可将推理效率提升5~10倍。
同时,Paraformer使用了6倍下采样的低帧率建模方案,可将计算量降低近6倍,支持大模型的高效推理。
体验地址:https://www.modelscope.cn/models/damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/summary
论文地址:https://arxiv.org/abs/2206.08317

© 版权声明
文章版权归作者所有,未经允许请勿转载。