
2022 年即将步入尾声。在这一年里,机器学习领域涌现出了大量有价值的论文,对机器学习社区产生了深远的影响。
今日,ML & NLP 研究者、Meta AI 技术产品营销经理、DAIR.AI 创始人 Elvis S. 对 2022 年热度很高的 12 篇机器学习论文进行了汇总。帖子很火,还得到了图灵奖得主 Yann LeCun 的转推。
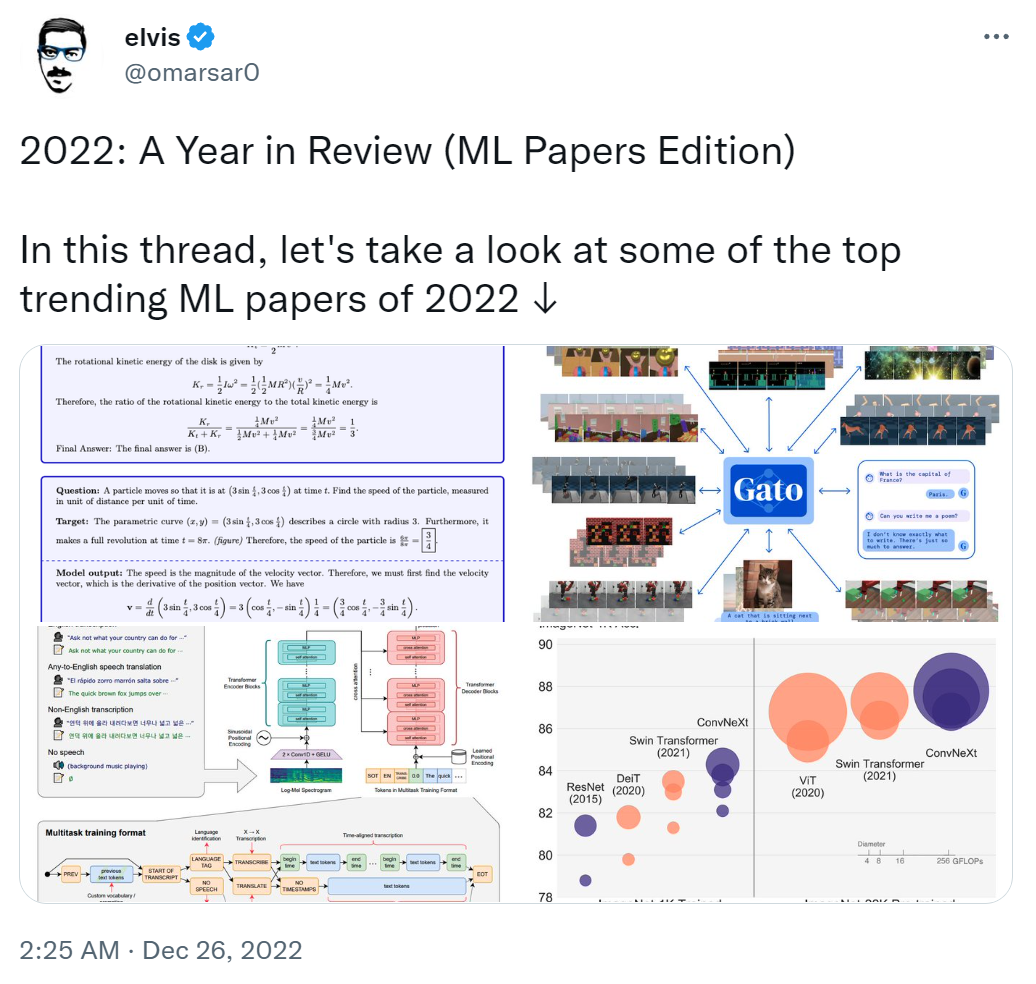
接下来,我们一一来看。
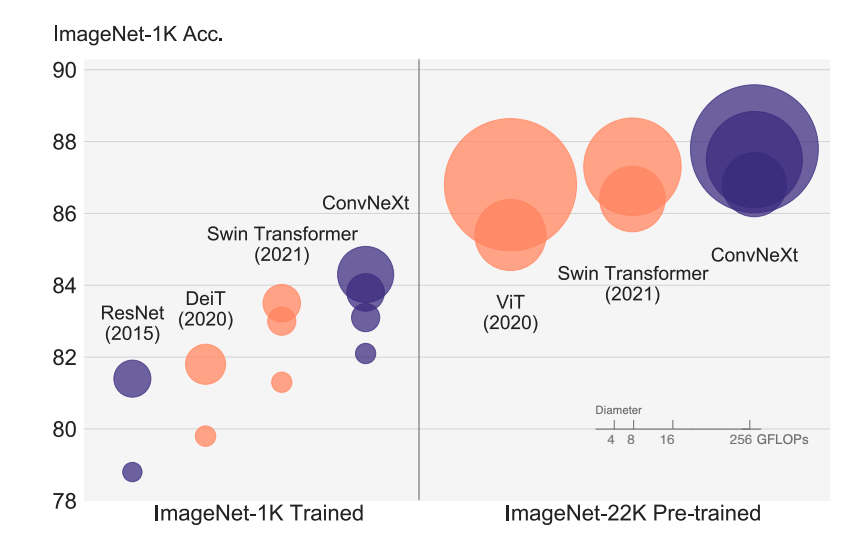
论文 1:A ConvNet for the 2020s
视觉识别的快速发展始于 ViT 的引入,其很快取代了传统 ConvNet,成为 SOTA 图像分类模型。ViT 模型在包括目标检测、语义分割等一系列计算机视觉任务中存在很多挑战。因此有研究者提出分层 Swin Transformer,重新引入 ConvNet 先验,使得 Transformer 作为通用视觉主干实际上可行,并在各种视觉任务上表现出卓越的性能。
然而,这种混合方法的有效性在很大程度上仍归功于 Transformer 的内在优势,而不是卷积固有的归纳偏置。本文中,FAIR 、UC 伯克利的研究者重新检查了设计空间并测试了纯 ConvNet 所能达到的极限。研究者逐渐将标准 ResNet「升级」为视觉 Transformer 的设计,并在此过程中发现了导致性能差异的几个关键组件。
论文地址:https://arxiv.org/abs/2201.03545v2
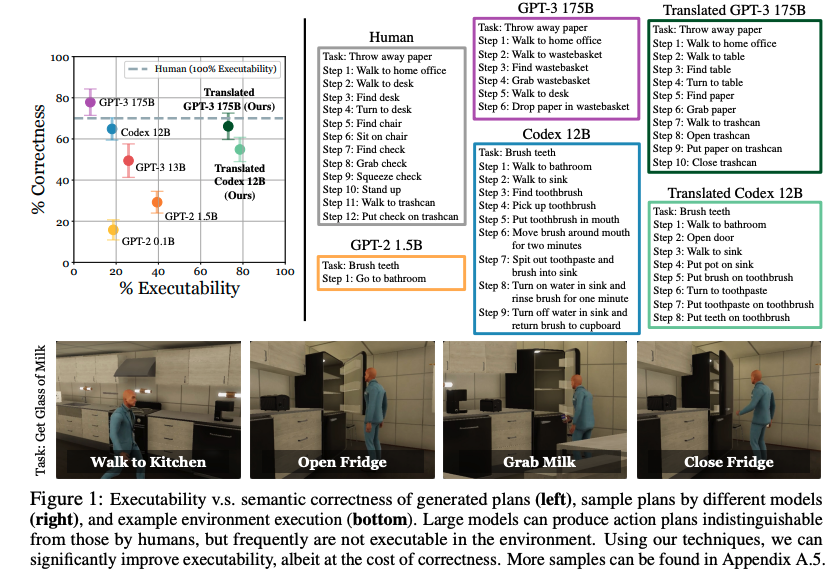
论文 2:Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents
通过大型语言模型(LLM)学习的世界知识能能用于交互式环境中的行动吗?本文中,UC 伯克利、CMU 和谷歌的研究者探究了将自然语言表达为一组选定可操作步骤的可能性。以往的工作侧重于从显式分布示例中学习如何行动,但他们惊讶地发现,如果预训练语言模型足够大并得到适当的提示,则可以有效地将高级任务分解为中级规划,无需进一步训练。但是,LLM 制定的规划往往无法精确地映射到可接受的行动。
研究者提出的步骤以现有演示为条件,并将规划在语义上转换为可接受的行动。在 VirtualHome 环境中的评估表明,他们提出的方法大大提高了 LLM 基线的可执行性。人工评估揭示了可执行性和正确性之间的权衡,但展现出了从语言模型中提取可操作知识的可能性迹象。
论文地址:https://arxiv.org/abs/2201.07207v2
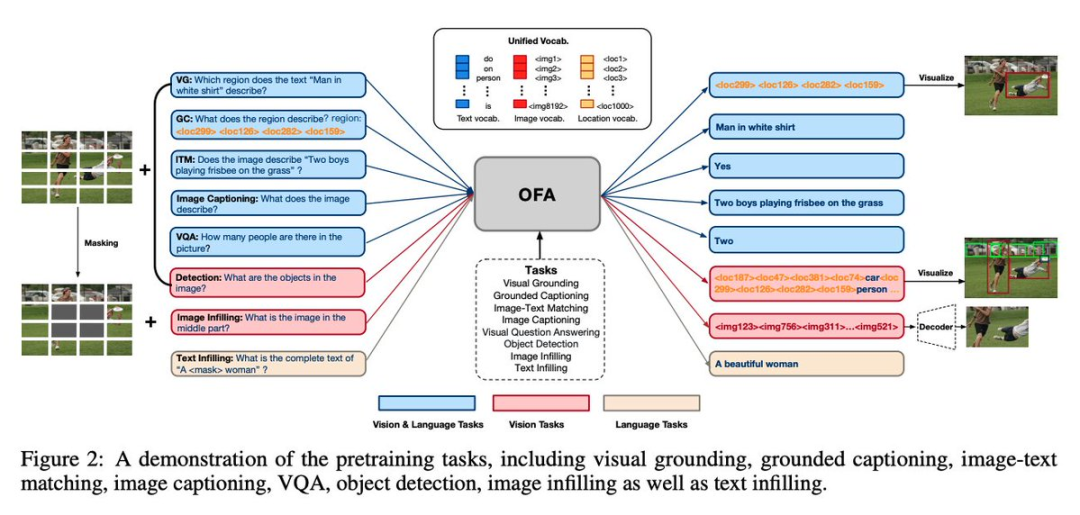
论文 3:OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
这是阿里达摩院推出的统一多模态多任务模型框架 OFA,总结了通用模型现阶段最好符合的三个特点,即模态无关、任务无关、任务多样性。该论文被 ICML 2022 接收。
在图文领域,OFA 将 visual grounding、VQA、image caption、image classification、text2image generation、language modeling 等经典任务通过统一的 seq2seq 框架进行表示,在任务间共享不同模态的输入输出,并且让 Finetune 和预训练保持一致,不新增额外的参数结构。
论文地址:https://arxiv.org/abs/2202.03052v2
论文 4:Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer
深度学习中的超参数(HP)调优是一个成本高昂的过程,对于具有数十亿参数的神经网络而言更是如此。本文中,微软和 OpenAI 的研究者表明,在最近发现的 Maximal Update Parametrization(muP)中,即使模型大小发生变化,很多最优 HP 仍保持稳定。
这促成了他们称为 muTransfer 的全新 HP 调优范式,即在 muP 中对目标模型进行参数化,在较小的模型上不直接进行 HP 调优,并将它们零样本迁移到全尺寸模型中,这也意味着根本不需要直接对后者模型进行调优。研究者在 Transformer 和 ResNet 上验证了 muTransfer。例如,通过从 40M 参数的模型进行迁移,性能优于已发布的 6.7B GPT-3 模型,调优成本仅为预训练总成本的 7%。
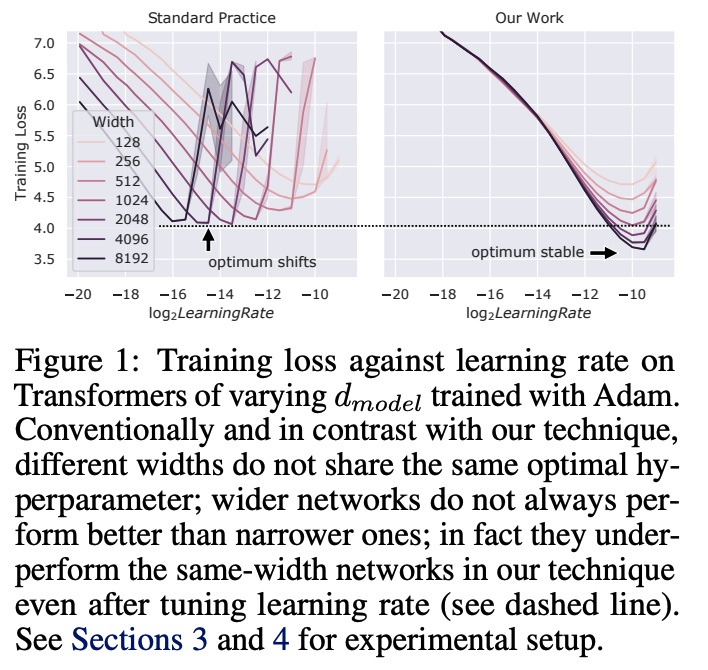
论文地址:https://arxiv.org/abs/2203.03466v2
论文 5:OPT: Open Pre-trained Transformer Language Models
大模型往往经过成千上万个计算日的训练,在零样本和少样本学习中展现出了非凡的能力。不过考虑到它们的计算成本,如果没有充足的资金,这些大模型很难复制。对于少数可以通过 API 获得的模型,无法访问它们完整的模型权重,也就难以展开研究。
本文中,Meta AI 的研究者提出了 Open Pre-trained Transformers(OPT),这是一套仅用于解码器的预训练 transformers 模型,参数从 125M 到 175B 不等。他们表明,OPT-175B 性能与 GPT-3 相当,但开发所需的碳足迹仅为后者的 1/7。
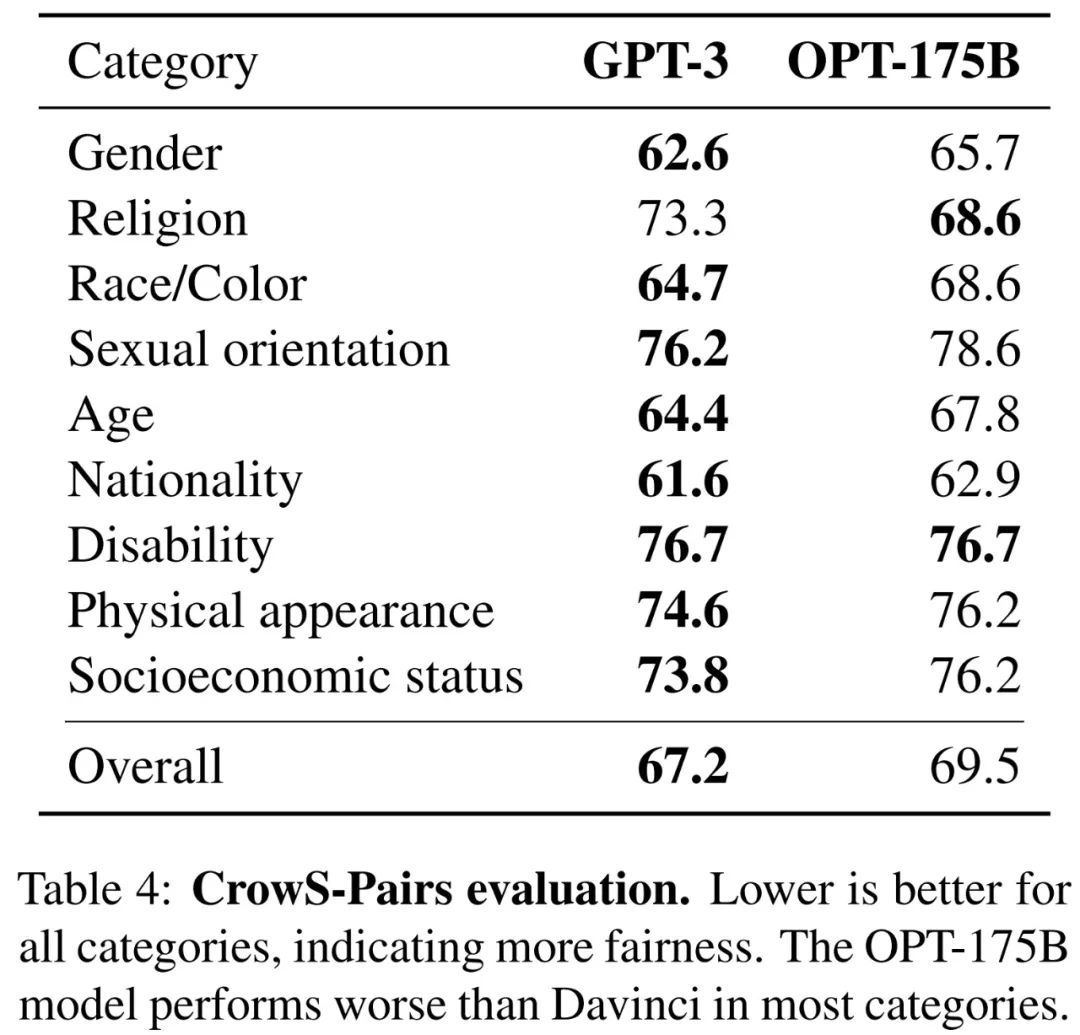
论文地址:https://arxiv.org/abs/2205.01068v4
论文 6:A Generalist Agent
受大规模语言建模的启发,Deepmind 构建了一个单一的「通才」智能体 Gato,它具有多模态、多任务、多具身(embodiment)特点。
Gato 可以玩雅达利游戏、给图片输出字幕、和别人聊天、用机械臂堆叠积木等等。此外,Gato 还能根据上下文决定是否输出文本、关节力矩、按钮按压或其他 token。
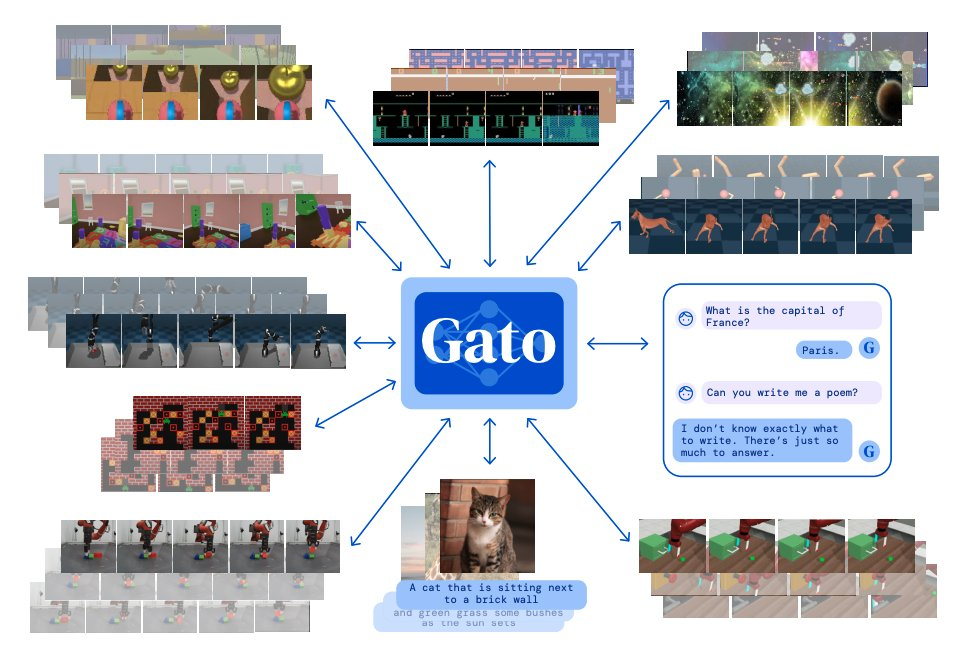
与大多数智能体玩游戏不同,Gato 使用相同的训练模型就能玩许多游戏,而不用为每个游戏单独训练。

论文地址:https://arxiv.org/abs/2205.06175v3
论文 7:Solving Quantitative Reasoning Problems with Language Models
来自谷歌的研究者提出了一种叫作 Minerva 的深度学习语言模型,可以通过逐步推理解决数学定量问题。其解决方案包括数值计算、符号操作,而不需要依赖计算器等外部工具。
此外,Minerva 还结合了多种技术,包括小样本提示、思维链、暂存器提示以及多数投票原则,从而在 STEM 推理任务上实现 SOTA 性能。
Minerva 建立在 PaLM(Pathways Language Model ) 的基础上,在 118GB 数据集上进一步训练完成,数据集来自 arXiv 上关于科技方面的论文以及包含使用 LaTeX、MathJax 或其他数学表达式的网页的数据进行进一步训练。
下图为 Minerva 解决问题示例展示:

论文地址:https://arxiv.org/abs/2206.14858
论文 8:No Language Left Behind: Scaling Human-Centered Machine Translation
来自 Meta AI 的研究者发布了翻译模型 NLLB(No Language Left behind ),直译为「一个语言都不能少」,其可以支持 200 + 语言之间的任意互译,除了中英法日等常用语种翻译外,NLLB 还能对包括卢干达语、乌尔都语等在内的许多小众语言进行翻译。
Meta 宣称,这是全球第一个以单一模型对应多数语言翻译的设计,他们希望借此能够帮助更多人在社群平台上进行跨语言互动,同时提高用户在未来元宇宙中的互动体验。
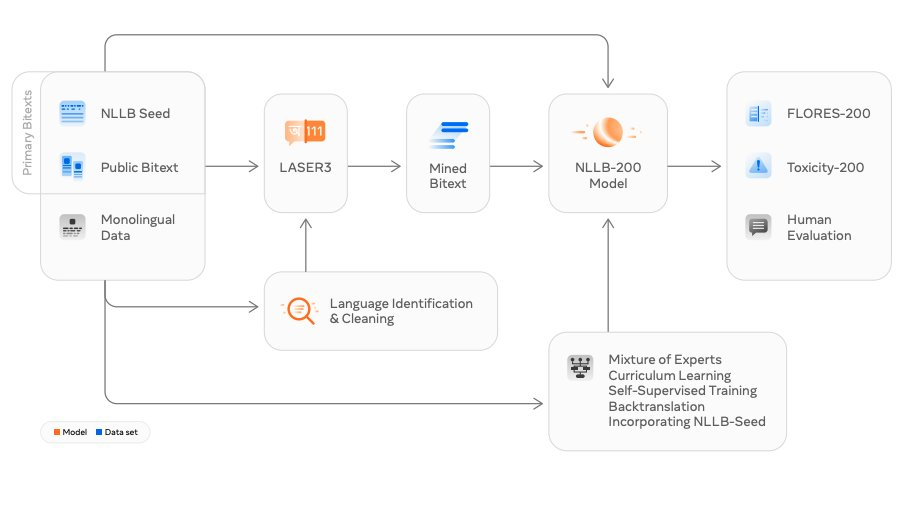
论文地址:https://arxiv.org/abs/2207.04672v3
论文 9:High-Resolution Image Synthesis with Latent Diffusion Models
最近一段时间 Stable Diffusion 火爆出圈,围绕这一技术展开的研究数不胜数。
该研究是来自慕尼黑大学和 Runway 的研究者基于其 CVPR 2022 的论文《High-Resolution Image Synthesis with Latent Diffusion Models》,并与 Eleuther AI、LAION 等团队合作完成。Stable Diffusion 可以在消费级 GPU 上 10 GB VRAM 下运行,并在几秒钟内生成 512×512 像素的图像,无需预处理和后处理。
时间仅过去四个月,该开源项目已收获 38K 星。
项目地址:https://github.com/CompVis/stable-diffusion
Stable Diffusion 生成图像示例展示:

论文 10:Robust Speech Recognition via Large-Scale Weak Supervision
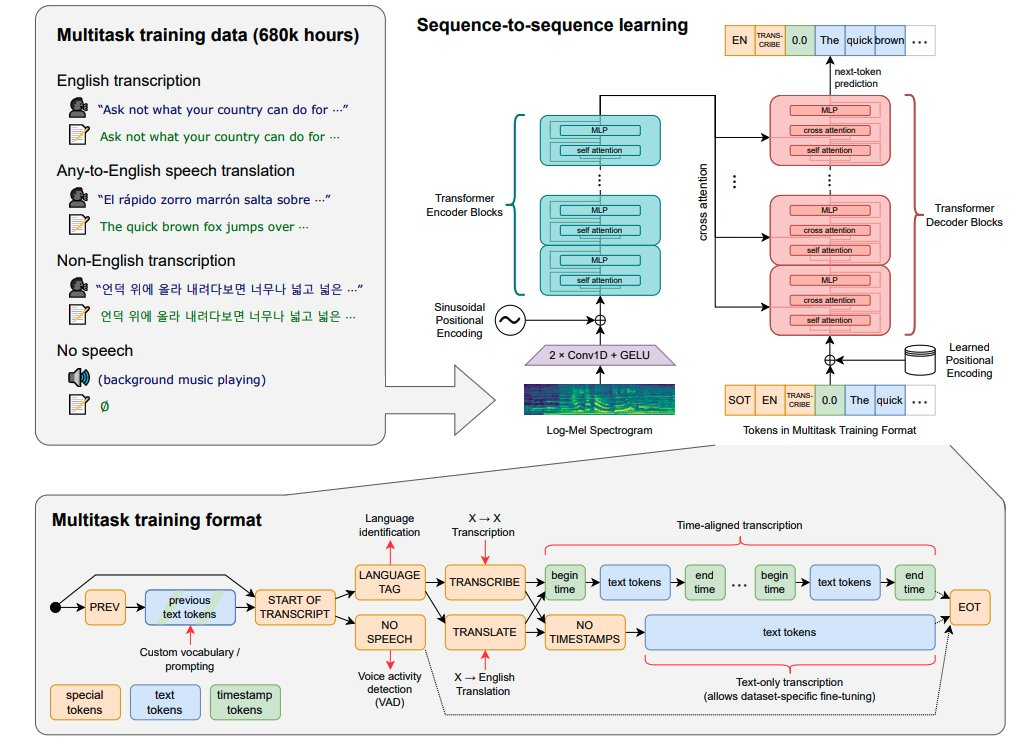
OpenAI 发布开源模型 Whisper,在英语语音识别方面接近人类水平,并具有较高的准确性。
Whisper 是一个自动语音识别(ASR,Automatic Speech Recognition)系统,OpenAI 通过从网络上收集了 68 万小时的 98 种语言和多任务监督数据对 Whisper 进行了训练。除了可以用于语音识别,Whisper 还能实现多种语言转录,以及将这些语言翻译成英语。
论文地址:https://arxiv.org/abs/2212.04356
论文 11:Make-A-Video: Text-to-Video Generation without Text-Video Data
来自 Meta AI 的研究者提出了一种最先进的文本到视频模型:Make-A-Video,可以将给定的文本提示生成视频。
Make-A-Video 有三个优点:(1)它加速了 T2V(Text-to-Video)模型的训练,不需要从头开始学习视觉和多模态表示,(2)它不需要配对的文本 – 视频数据,(3)生成的视频继承了当今图像生成模型的多项优点。
该技术旨在实现文本到视频生成,仅用几个单词或几行文本就能生成独一无二的视频。如下图为一只狗穿着超级英雄的衣服,披着红色的斗篷,在天空中飞翔:

论文地址:https://arxiv.org/abs/2209.14792
论文 12:Galactica: A Large Language Model for Science
近年来,随着各学科领域研究的进步,科学文献和数据呈爆炸式增长,使学术研究者从大量信息中发现有用的见解变得越来越困难。通常,人们借助搜索引擎来获取科学知识,但搜索引擎不能自主组织科学知识。
最近,Meta AI 的研究团队提出了一种新的大型语言模型 Galactica,可以存储、组合和推理科学知识。Galactica 可以自己总结归纳出一篇综述论文、生成词条的百科查询、对所提问题作出知识性的回答。
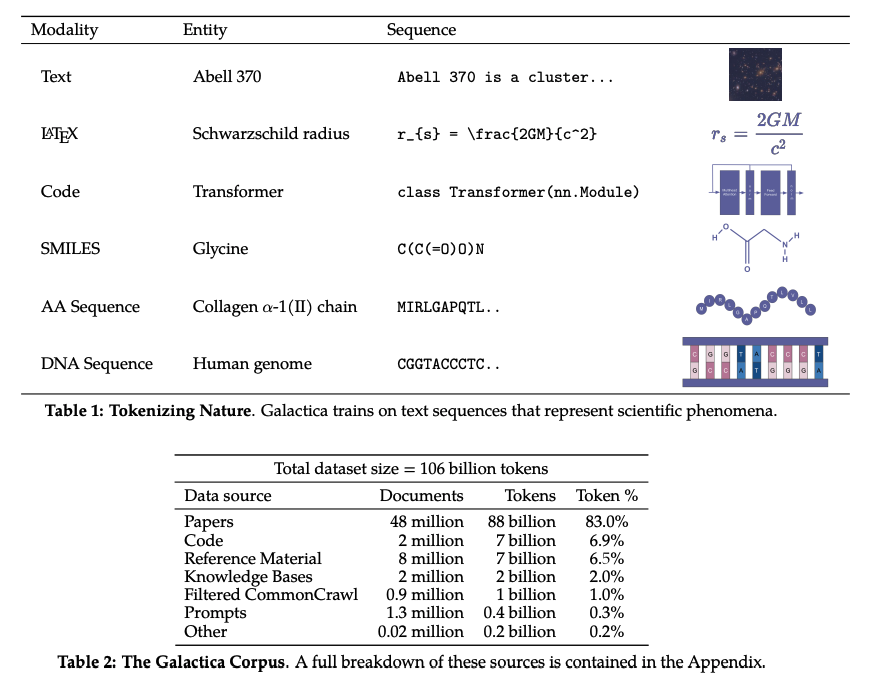
论文地址:https://arxiv.org/abs/2211.09085
© 版权声明
文章版权归作者所有,未经允许请勿转载。


