

一. 背景介绍
在字节跳动,基于深度学习的应用遍地开花,工程师关注模型效果的同时也需要关注线上服务一致性和性能,早期这通常需要算法专家和工程专家分工合作并紧密配合来完成,这种模式存在比较高的 diff 排查验证等成本。
随着 PyTorch/TensorFlow 框架的流行,深度学习模型训练和在线推理完成了统一,开发者仅需要关注具体算法逻辑,调用框架的 Python API 完成训练验证过程即可,之后模型可以很方便的序列化导出,并由统一的高性能 C++ 引擎完成推理工作。提升了开发者训练到部署的体验。
然而,完整的服务通常还存在大量的预处理/后处理等业务逻辑,这类逻辑通常是把各种输入经过加工处理转变为 Tensor,再输入到模型,之后模型的输出 Tensor 再加工成目标格式,一些典型的场景如下:
- Bert
- Resnet
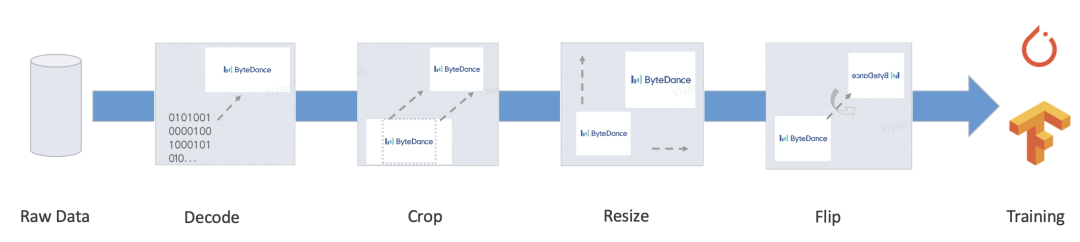
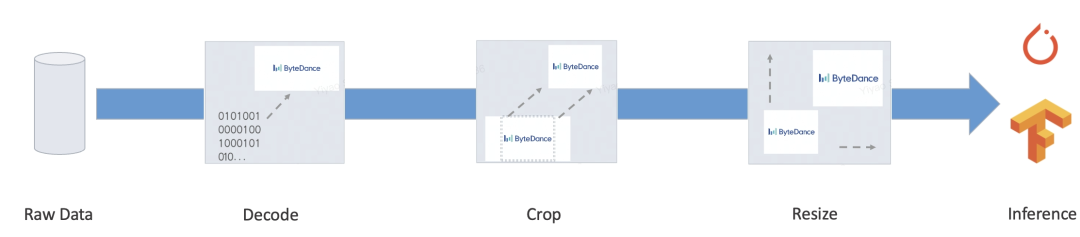
我们的目标就是为以上端到端的过程,提供自动化且统一的训练、推理方案,减轻人工开发推理过程、对齐 diff 等一系列问题,实现大规模的统一部署方案。
二. 核心问题
PyTorch/TensorFlow 等框架相对已经解决了模型的训练/推理统一的问题,因此模型计算本身不存在训推一体的问题了(算子性能优化不在本次讨论范围)。
核心要解决的问题就是:预处理和后处理需要提供高性能训推一体的方案。
对于此类逻辑,TensorFlow 2.x 提供了 tf.function(还不完善),PyTorch 提供了 TorchScript,其无一例外都是选择了原生 Python 语法子集。 但即使强大如此,仍然存在不可忽略的问题:
- 性能:此方案大多基于虚拟机实现,虚拟机方案灵活并且非常可控,但深度学习框架中的虚拟机大多通常性能不够优良。补充说明一下,框架早期都是为 Tensor 计算设计,数组计算每个算子成本很高,虚拟机的派发和调度成本可以忽略。但是,移植到程序语言编程层面开销难以忽略,代码写多了就会成为性能瓶颈。据测试,TorchScript 解释器性能只有 Python 的 1/5 左右,tf.function 性能更差一些。
- 功能不全:事实上应用到真实场景中,我们仍然可以找出很多 tf.function/TorchScript 不支持的重要功能,比如:自定义的资源不能打包,只能序列化内置类型;字符串只能做 bytes 处理,中文等 unicode 会造成 diff;容器必须同构,不支持自定义类型等等…
再者,还有很多非深度学习任务,比如在自然语言处理中仍然有很多非深度学习的应用或者子任务,如序列标注,语言模型解码,树模型的人工特征构造等任务,这些通常具有更灵活的特征范式,但同时都没有完整实现端到端的训推一体方案,仍然有大量的开发以及正确性校验工作。
为了解决上述问题,我们开发了一套基于编译的预处理方案:MATXScript!
三. MATXScript
在深度学习算法开发中,开发者通常使用 Python 进行快速迭代和实验,同时使用 C++ 开发高性能的线上服务,其中正确性校验和服务开发都会成为较重负担!
MatxScript(https://github.com/bytedance/matxscript) 是一个 Python 子语言的 AOT 编译器,可以自动化将 Python 翻译成 C++,并提供一键打包发布功能。使用 MATXScript 可以让开发者快速进行模型迭代的同时以较低成本完成高性能服务的部署。
核心架构如下:
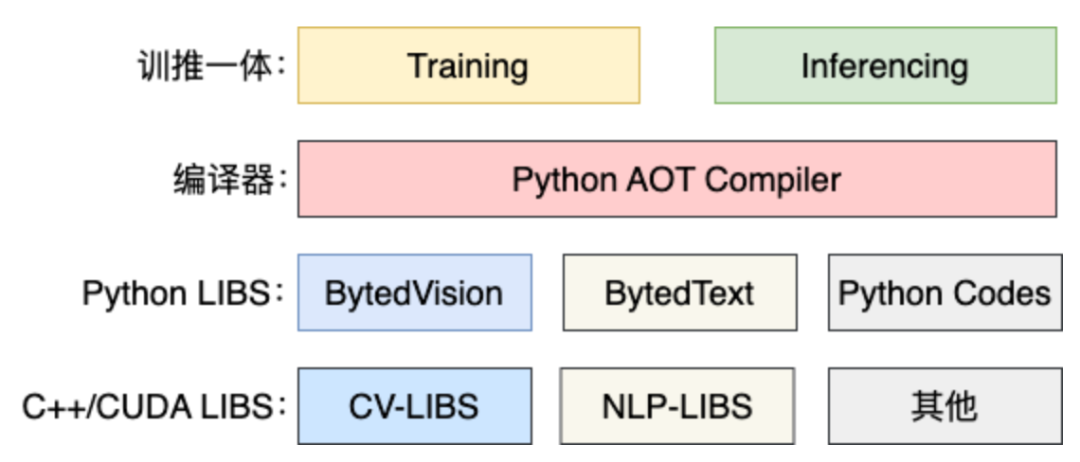
- 最底层是纯 C++/CUDA 的基础库,由高性能算子专家开发。
- 在基础库之上,准守约定封装出来 Python 的 库,可以用在 training 过程中。
- 需要 inferencing 时,利用 MATXScript 可以把 Python 代码,翻译成对等的 C++ 代码,编译成动态链接库,加上模型及其他依赖的资源,一起打包发布即可。
其中,编译器作用非常关键,其核心流程如下:
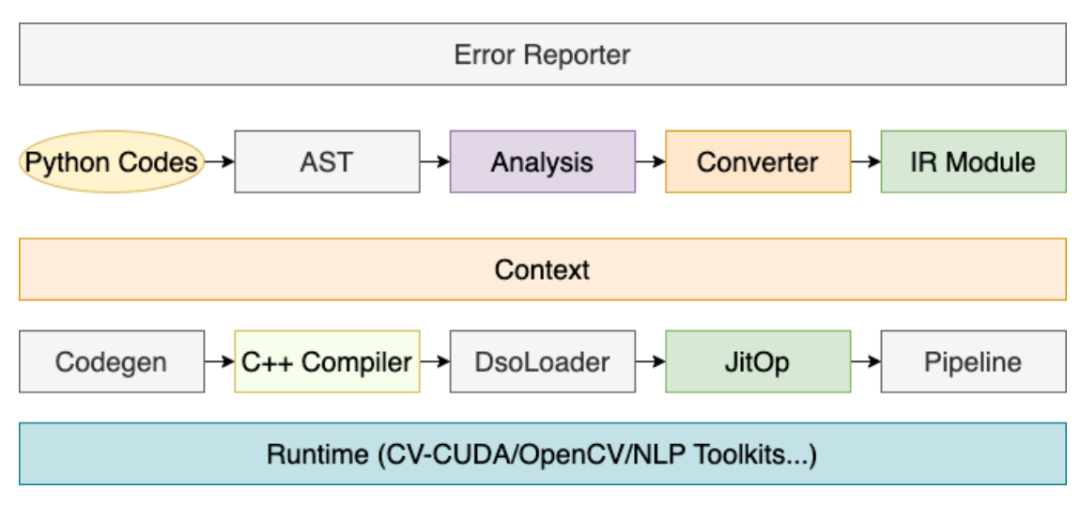
通过以上流程,用户所编写的预处理代码,可以被编译成 Pipeline 中的一个 JitOp,为了把前后处理和模型联动,我们还开发了 tracing 系统(接口设计上参考了 PyTorch),架构如下:
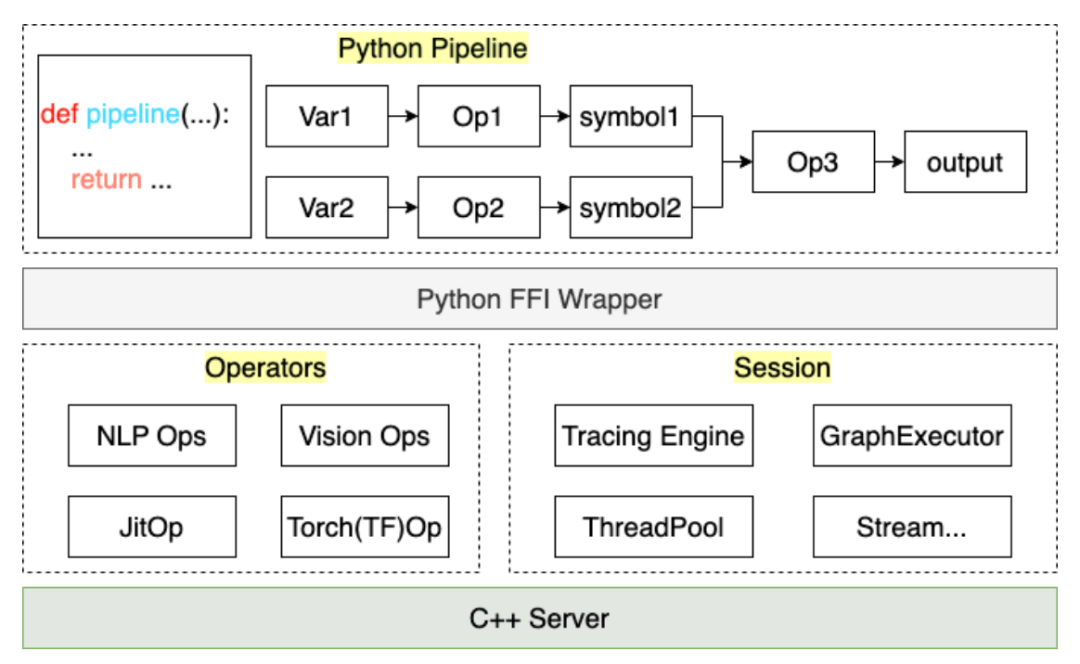
基于 MATXScript,我们可以训练和推理使用同一套代码,大大降低了模型部署的成本。同时,架构和算法得到了解耦,算法同学完全使用 Python 工作即可,架构同学专注于编译器开发及 Runtime 优化,在字节跳动,此方案得到了大规模部署验证!
四. 小试牛刀
此处以最简单的英文文本预处理为例,展示一下 MATXScript 如何使用。
目标:把一段英文文本转成 indexes
- 编写一个基本的查字典的逻辑
class Text2Ids:
def __init__(self) -> None:
self.table: Dict[str, int] = {
"hello": 0,
"world": 1,
"[UNK]": 2,
}
def lookup(self, word: str)
return self.table.get(word, 2)
def __call__ (self, words: List[str])
return [self.lookup(w) for w in words]
- 编写 Pipeline
import matx
class WorkFlow:
def __init__(self):
# 此处会进行代码编译,Python 代码自动编译封装为 Callable 对象
self.text2ids = matx.script(Text2Ids)()
def process(self, texts):
ids = self.text2ids(texts)
return ids
# test
handler = WorkFlow()
print(handler.process("hello world unknown"))
# output: [0, 1, 2]
- Trace 导出到 磁盘
# dump
mod = matx.trace(handler.process, "hello world")
print(mod.run({"texts": "hello world"}))
mod.save('./my_dir')
# load
mod = matx.load('./my_dir', -1)
print(mod.run({"texts": "hello world"}))
- C++ 加载
#include <string>
#include <vector>
#include <map>
#include <iostream>
#include <matxscript/pipeline/tx_session.h>
using namespace ::matxscript::runtime;
int main()
{
// test case
std::unordered_map<std::string, RTValue> feed_dict;
feed_dict.emplace("texts", Unicode(U"hello world"));
std::vector<std::pair<std::string, RTValue>> result;
const char* module_path = "./my_dir";
const char* module_name = "model.spec.json";
{
// -1 mean cpu
auto sess = TXSession::Load(module_path, module_name, -1);
auto result = sess->Run(feed_dict);
for (auto& r : result) {
std::cout << "key: " << r.first << ", value: " << r.second << std::endl;
}
}
return 0;
}
完整的代码见:https://github.com/bytedance/matxscript/tree/main/examples/text2ids
小结:以上是一个非常简单的纯 Python 实现的预处理逻辑,且能被一段通用的 C++ 代码加载运行,下面我们结合模型展示一个实际的多模态端到端案例!
五. 多模态案例
此处以图文多模态(Bert+Resnet)为例,模型使用 PyTorch 编写,展示训练和部署中实际的工作。
- 配置环境
a. 配置 gcc/cuda 等基础设施(通常是运维同学已经搞定)
b. 安装 MATXScript 及基于此开发的基础库(text、vision等) - 编写模型代码
a. 此处省略,大家可以参考论文或其他开源实现自行搞定 - 编写预处理代码
a. text
from typing import List, Dict, Tuple
import libcut
import matx
class Vocabulary:
...
def utf8_decoder(s: List[bytes]):
return [x.decode() for x in s]
class TextNDArrayBuilder:
...
class TextPipeline:
def __init__(self, mode: str = "eval"):
self.mode = mode
self.cut_engine = libcut.Cutter('/path/to/cut_models', ...)
self.vocab = matx.script(Vocabulary)('/path/to/vocab.txt')
self.decoder = matx.script(utf8_decoder)
self.input_builder = matx.script(TextNDArrayBuilder)(self.vocab)
def process(self, text: List[bytes]):
# List[bytes] 是对齐 C++ 的 vector<string>
text: List[str] = self.decoder(text)
words: List[List[str]] = self.cut_engine(text)
batch_ids: List[List[int]] = self.vocab(words)
input_ids, segment_ids, mask_ids = self.input_builder(batch_ids, 32)
if self.mode == "train":
return input_ids.torch(), segment_ids.torch(), mask_ids.torch()
return input_ids, segment_ids, mask_ids
b. vision
from typing import List, Dict, Tuple
import matx
from matx import vision
class VisionPipeline:
def __init__(self,
device_id: int = 0,
mode: str = "eval",
image_size: int = 224,):
self.is_training = mode == 'train'
self.mode = mode
...
def process(self, image,):
if self.is_training:
decode_nds = self.random_crop_decode(image)
flip_nds = self.random_flip(decode_nds)
resize_nds = self.resize(flip_nds)
transpose_nd = self.transpose_norm(resize_nds, vision.SYNC)
else:
decode_nds = self.decode(image)
resize_nds = self.resize(decode_nds)
crop_nds = self.center_crop(resize_nds)
transpose_nd = self.transpose_norm(crop_nds, vision.SYNC)
if self.mode == "trace":
return transpose_nd
return transpose_nd.torch()
- 接入 DataLoader
a. TextPipeline 可以当成一个正常的 Python Class 接入 Dataset 即可
b. VisionPipeline 涉及到 GPU 预处理,更适合按 batch 进行处理,需要自己单独构造一个 DataLoader(这里埋个点,之后会开源字节跳动内部基于多线程的 DataLoader) - 加上模型代码,开始训练吧
- 导出端到端的 Inference Model
class MultimodalEvalPipeline:
def __init__(self):
self.text_pipe = TextPipeline(mode="eval", ...)
self.vision_pipe = VisionPipeline(mode="eval", ...)
self.torch_model = torch.jit.load('/path/to/multimodal.jit', map_locatinotallow='cuda:0')
self.tx_model_op = matx.script(self.torch_model, device=0)
def eval(self, texts: List[bytes], images: List[bytes])
input_ids, segment_ids, mask_ids = self.text_pipe.process(texts)
images = self.vision_pipe.process(images)
scores = self.tx_model_op(input_ids, segment_ids, mask_ids, images)
return scores
# examples
example_batch_size = 8
text_examples = ['hello, world'.encode()] * example_batch_size
with open('/path/image.jpg', 'rb') as f:
image_example = f.read()
image_examples = [image_example] * example_batch_size
# pipeline instance
pipe = MultimodalEvalPipeline(...)
mod = matx.trace(pipe.eval, text_examples, image_examples)
# test
print(mod.run({"texts": text_examples, "images": image_examples}))
# save
mod.save('/path/to/my_multimodal')
小结:经过以上步骤,我们即可完成端到端的训练&发布工作,且整个过程是纯 Python 代码完成的,可以完全由算法同学自己控制。当然,如果模型计算本身还有性能问题,也是可以在背后通过自动改图优化工作完成。
注:完整代码示例见 https://github.com/bytedance/matxscript/tree/main/examples/e2e_multi_modal
六. 统一Server
在上个章节,我们得到了一个算法同学发布的模型包,本章节论述如果用统一的服务进行加载和运行。
完整的 Server 包括:IDL 协议、Batching 策略、进/线程调度和排布、模型推理…
这里,我们只讨论模型推理这块,其他的都是可以按约定开发即可。我们以一个 main 函数来示例模型加载和运行的过程:
#include <string>
#include <vector>
#include <map>
#include <iostream>
#include <matxscript/pipeline/tx_session.h>
using namespace ::matxscript::runtime;
int main()
{
// test case
std::unordered_map<std::string, RTValue> feed_dict;
feed_dict.emplace("texts", List({String("hello world")}));
feed_dict.emplace("images", List({String("......")}));
std::vector<std::pair<std::string, RTValue>> result;
const char* module_path = "/path/to/my_multimodal";
const char* module_name = "model.spec.json";
{
// cuda:0
auto sess = TXSession::Load(module_path, module_name, 0);
auto result = sess->Run(feed_dict);
for (auto& r : result) {
std::cout << "key: " << r.first << ", value: " << r.second << std::endl;
}
}
return 0;
}
以上代码就是最简单的一个 C++ 加载多模态模型的案例,对 Server 开发的同学来说,只需进行简单的抽象和约定,即可把上述代码改造成一个统一的 C++ 模型服务框架。
七. 更多信息
我们是字节跳动-AML-机器学习系统团队,致力于为公司提供统一的高性能训推一体化框架,同时也会通过火山引擎机器学习平台服务于合作企业,火山引擎机器学习平台预计 2023 年起提供 MATX 的相关支持,包括预置镜像环境、常用场景的公开样例、企业接入和使用过程中的技术保障等,可以达到训练和推理场景低成本加速和一体化的效果。欢迎在 https://www.volcengine.com/product/ml-platform 详细了解我们的产品。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


