TensorFlow应用技术拓展—图像分类
1.科研平台环境部署操作拓展
针对于机器学习中的模型训练,本人推荐大家多学习TensorFlow官方的课程或资源,比如中国大学MOOC上的两门课程《 TensorFlow 入门实操课程 》和《 TensorFlow 入门课程 – 部署篇 》。科研或者工作过程中涉及的模型分布式训练,可能一个资源平台往往会非常耗时,无法及时满足个人需求。在这里,我将就上一篇《初步了解TensorFlow框架学习》提到的九天毕昇平台的使用进行一个具体的拓展,来方便学生和用户来更快捷地进行模型训练。该平台可以进行数据管理,模型训练等任务,是一个方便快捷的科研任务实践平台。在模型训练中具体操作步骤为:
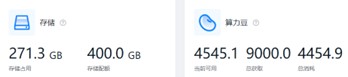
(1)注册并登录九天毕昇平台,由于后续训练任务需消耗算力豆,而新用户的算力豆数量有限,但可以通过分享好友等任务来完成算力豆的获取。同时针对大型模型训练任务,为获取更多的模型训练存储空间,可邮件方式联系该平台的工作人员进行了控制台的升级,从而达到了日后所需的训练存储要求。存储和算力豆详情如下图:
(2)进入数据管理界面部署科研项目模型使用的数据集,通过将科研任务所需的数据集进行打包上传,完成模型训练所需数据集在该平台上的部署。

(3)在模型训练窗口新增项目训练实例,选择之前导入的数据集和所需的CPU资源。创建后的实例即为科研所需要训练的单个模型文件。新增项目实例的详情如下图所示:

(4)运行新增的项目实例,即运行项目训练环境,运行成功后,则可以选择jupyter编辑器创建和编辑所需的代码文件。


(5)后续代码编写和模型训练即可使用jupyter编辑器进行操作即可。
2. 图像分类技术拓展
图像分类,顾名思义就是根据图像之间差异性来对不同图像进行类别判断。而针对图像之间地差异性去设计判别模型就是机器学习中需要去掌握的知识。图像分类的基本知识和操作过程可以参考中国大学MOOC上的《TensorFlow入门实操课程》,快速了解TensorFlow基础应用与设计思路。。https://www.icourse163.org/learn/youdao-1460578162?tid=1461280442#/learn/content?type=detail&id=1239107268&cid=1260057739
本章主要是想通过拓展图像分类技术来让接触该课程的用户更加深入地理解图像分类。
2.1 卷积操作有什么用?
说到对图像进行处理或者分类,必然绕不开一个操作,这个操作就是卷积。具体的卷积操作通过学习视频基本都能了解,但是更多的读者可能也只是停留在会如何进行卷积操作的程度上,而对于为什么去进行卷积,卷积操作有什么用这些仍然是一知半解。这里为大家进行一定拓展来帮助大家更好理解卷积。
基本的卷积过程下图所示,以图像为例,使用一个矩阵来表示图像,矩阵的每个元素即为图像中对应的像素值。卷积操作就是通过将卷积核逐乘对应的矩阵,从而得到这些小区域的特征值。而提取到的特征会因为卷积核的不同而有所差异,这也是后续会有人对图像不同通道进行卷积操作来获取图像不同通道的特征,来更好地进行后续分类任务。
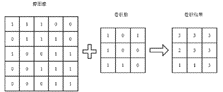
在日常地模型训练中,具体地卷积核并不需要进行人工设计,而是通过给定图像的真实标签,使用网络来自动训练出来的,但是这样的过程不利于人们去理解卷积核和卷积过程,或者说不直观。因此为了帮助大家更好理解卷积操作的意义,在这举一个卷积操作的例子。如下图矩阵所示,数值表示图形的像素,为了方便计算,在这里只取了0和1, 不难看出该矩阵图形的特点上面一半图形是明亮的,下面一半图形是黑的,因此该图像具有很清晰的一道分界线,即具有很明显的水平特征。

因此为了很好地提取上述矩阵的水平特征,设计的卷积核应该也要具有水平特征提取的属性。而采用垂直特征提取属性的卷积核相对而言在特征提取的明显程度上会略显不足。 如下所示,采用提取水平特征的卷积核进行卷积:
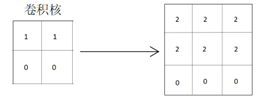
由得到的卷积结果矩阵可知,原始图形的水平特征被很好地提取出来,并且图形地分界线会更加明显,因为图形有颜色的部分像素值加深了,很好地提取并突出了图形的水平特征。当采用提取垂直特征的卷积核进行卷积时:

由得到的卷积结果矩阵可知,原始图形的水平特征也能被提取出来,但是会产生两条分界线,图形变化由特别明亮到明亮再到黑,反映到真实图形上的情况也就变成由明到暗再到黑的情况,与真实原始图形反应的水平特征有所差别。
由上述例子不难得知,卷积核的不同会影响最终提取的图形特征的优劣程度,同时不同图形所反应出来的特征也有所不同,如何根据图形特征属性的不同来设计出网络模型来更好地学习和设计出卷积核也尤为关键。在实际地图形分类项目中,就需要根据图像的差异来选择提取合适的特征,并且往往需要有所取舍的去考虑。
2.2 如何考虑卷积来更好的进行图像分类?
在上一节中通过卷积操作的作用可以知道,设计网络模型来更好地去学习出适配图像的卷积核尤为重要。但在实际应用中,都是通过给定图像类别的真实标签,将类别标签转成机器能够理解的向量数据,来自动学习训练。当然,也不是完全无法通过人工设置来改善的。虽然数据集的标签是固定好的,但是我们可以根据数据集的图片类型去选择不同的网络模型,针对不同的网络模型的优劣势去考虑往往会有不错的训练效果。
同时在提取图像特征时,也可以考虑使用多任务学习的方法,在已有的图像数据中,再次同样使用一次图像数据去提取一些额外的图像特征(例如图像的通道特征和空间特征等),然后对之前提取到的特征进行一个补充或者填充,来完善最终提取到的图像特征。当然,有时候这种操作会造成提取的特征冗余,取得的分类效果往往适得其反,因此需要根据实际训练的分类结果去酌情考量。
2.3 网络模型选择的一些建议
图像分类领域发展已经有很长一段时间了,从最初经典的AlexNet网络模型到近几年火热的ResNet网络模型等,图像分类技术已经发展地比较完善,对于一些常用的图像数据集的分类准确率已经趋于100%。目前该领域中,大多数人采用的网络模型都是选择最新的,并且在大多数图像分类任务中,使用最新的网络模型确实可以带来很明显的分类效果,由此很多人在这一领域中往往会忽略以前的网络模型,直接去学习最新的、流行的网络模型。
在这,本人还是建议各位读者能够对图形分类领域的一些经典的网络模型都需要去进行一个熟悉,因为技术的更新迭代是非常快的,即使现在最新的网络模型今后也可能会被淘汰,但是基本的网络模型运行的原理是大致相通的,通过掌握经典的网络模型,不仅可以掌握基本的原理,还可以明白不同网络模型之间的差异和针对不同任务处理时的优劣性。例如,当你的图像数据集比较小时,采用最新的网络模型训练起来可能会非常复杂耗时,但是提升的效果微乎其微,因此为了可以忽略不计的效果去牺牲自己的训练时间成本反而得不偿失。因此,对于图像分类网络模型的掌握需要做到知其然还能知其所以然,这样今后选择图像分类模型时真正能做到有的放矢。
作者介绍:
稀饭,51CTO社区编辑,曾任职某电商人工智能研发中心大数据技术部门,做推荐算法。目前从事自然语言处理方向研究,主要擅长领域有推荐算法、NLP、CV,使用代码语言有Java、Python、Scala。发表ICCC会议论文一篇。
© 版权声明
文章版权归作者所有,未经允许请勿转载。