
多模态研究的一个重要目标就是提高机器对于图像和文本的理解能力。特别是针对如何在两种模型之间实现有意义的交流,研究者们付出了巨大努力。举例来说,图像描述(image captioning)生成应当能将图像的语义内容转换输出为可被人们理解的连贯文本。相反,文本 – 图像生成模型也可利用文本描述的语义来创建逼真的图像。
这就会带来一些同语义相关的有趣问题:对于给定的图像,哪种文本描述最准确地描述了图像?同样地,对于给定的文本,最有意义的图像实现方式又是哪种?针对第一个问题,一些研究宣称最佳的图像描述应该是既自然且还能还原视觉内容的信息。而对于第二个问题,有意义的图像应该是高质量的、多样性的且忠于文本内容的。
不论怎样,在人类交流的推动下,包含文本 – 图像生成模型及图像 – 文本生成模型的交互任务可以帮助我们选择最准确的图像文本对。
如图 1 所示,在第一个任务中,图像 – 文本模型是信息发送者,文本 – 图像模型是信息接收者。发送者的目标是使用自然语言将图像的内容传达给接收者,以便其理解该语言并重建真实的视觉表征。一旦接收者可以高保真地重建原始图像信息,则表明信息已传递成功。研究者认为这样生成的文本描述即为最优的,通过其产生的图像也最近似于原始图像。

这一规律受到人们使用语言进行交流的启发。试想如下情形:在一个紧急呼救的场景中,警察通过电话获知车祸的情况和受伤人员的状况。这本质上涉及现场目击者的图像描述过程。警方需要根据语言描述在脑海中重建环境场景,以组织恰当的救援行动。显然,最好的文本描述应该是该场景重建的最佳指南。
第二个任务涉及文本重建:文本 – 图像模型成为信息发送者,图像 – 文本模型则成为信息接收者。一旦两个模型就文本层面上信息内容达成一致,那么用于传达信息的图像媒介即为重现源文本的最优图像。
本文中,来自慕尼黑大学、西门子公司等机构的研究者提出的方法,同智能体间通信紧密相关。语言是智能体之间交换信息的主要方法。可我们如何确定第一个智能体与第二个智能体对什么是猫或什么是狗这样的问题有相同的理解呢?

论文地址:https://arxiv.org/pdf/2212.12249.pdf
本文所想要探求的想法是让第一个智能体分析图像并生成描述该图像的文本,而后第二个智能体获取该文本并据此来模拟图像。其中,后一个过程可以被认为是一个具象化体现的过程。该研究认为,如果第二个智能体模拟的图像与第一个智能体接收到的输入图像相似(见图 1),则通信成功。
在实验中,该研究使用现成的模型,特别是近期开发的大规模预训练模型。例如,Flamingo 和 BLIP 是图像描述模型,可以基于图像自动生成文本描述。同样地,基于图像 – 文本对所训练的图像生成模型可以理解文本的深层语义并合成高质量的图像,例如 DALL-E 模型和潜在扩散模型 (SD) 即为这种模型。
此外,该研究还利用 CLIP 模型来比较图像或文本。CLIP 是一种视觉语言模型,可将图像和文本对应起来表现在共享的嵌入空间(embedding space)中。该研究使用手动创建的图像文本数据集,例如 COCO 和 NoCaps 来评估生成的文本的质量。图像和文本生成模型具有允许从分布中采样的随机分量,因而可以从一系列候选的文本和图像中选择最佳的。不同的采样方法,包括核采样,均可以被用于图像描述模型,而本文采用核采样作为基础模型,以此来显示本文所使用方法的优越性。
方法概览
本文框架由三个预训练的 SOTA 神经网络组成。第一,图像 – 文本生成模型;第二,文本 – 图像生成模型;第三,由图像编码器和文本编码器组成的多模态表示模型,它可以将图像或文本分别映射到其语义嵌入中。
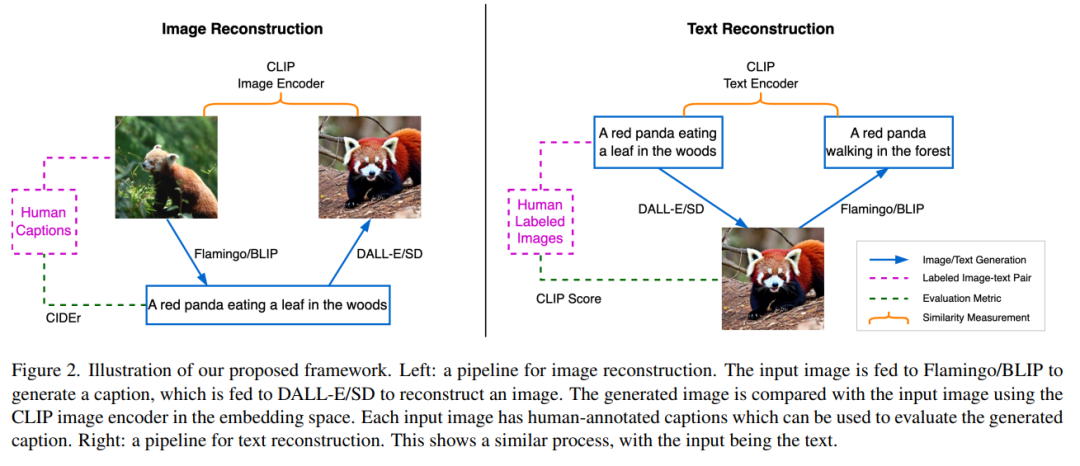
通过文本描述的图像重建
如图 2 左半部分所示,图像重建任务是使用语言作为指令重建源图像,此过程的效果实现将促使描述源场景的最佳文本生成。首先,源图像 x 被输送到 BLIP 模型以生成多个候选文本 y_k。例如,一只小熊猫在树林中吃树叶。生成的文本候选集合用 C 表示,然后文本 y_k 被发送到 SD 模型以生成图像 x’_k。这里 x’_k 是指基于小熊猫生成的图像。随后,使用 CLIP 图像编码器从源图像和生成的图像中提取语义特征: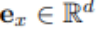 和
和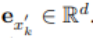 。
。
然后计算这两个嵌入向量之间的余弦相似度,目的是找到候选的文本描述 y_s, 即
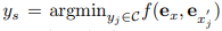
其中 s 为最接近源图像的图像索引。
该研究使用 CIDEr(图像描述度量指标)并参照人类注解来评估最佳文本。由于对生成的文本质量感兴趣,该研究将 BLIP 模型设定为输出长度大致相同的文本。这样就能保证进行相对公平的比较,因为文字的长度与可传递图像中信息量的多少呈正相关。在这项工作中,所有模型都会被冻结,不会进行任何微调。
通过图像实现文本重建
图 2 中右侧部分显示了与上一节描述过程的相反过程。BLIP 模型需要在 SD 的引导下猜测源文本,SD 可以访问文本但只能以图像的格式呈现其内容。该过程始于使用 SD 为文本 y 生成候选图像 x_k ,生成的候选图像集用 K 来表示。使用 SD 生成图像会涉及随机采样过程,其中每一次生成过程都可能会以在巨大的像素空间中得到不同的有效图像样本为终点。这种采样多样性会提供一个候选池来为筛选出最佳图像。随后,BLIP 模型为每个采样图像 x_k 生成一个文本描述 y’_k。这里 y’_k 指的是初始文本一只小熊猫在森林里爬行。然后该研究使用 CLIP 文本编码器提取源文本和生成文本的特征,分别用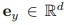 和
和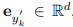 表示。此任务的目的是寻找匹配文本 y 语义的最佳候选图像 x_s。为此,该研究需要比较生成文本和输入文本之间的距离,然后选择出配对文本距离最小的图像,即
表示。此任务的目的是寻找匹配文本 y 语义的最佳候选图像 x_s。为此,该研究需要比较生成文本和输入文本之间的距离,然后选择出配对文本距离最小的图像,即
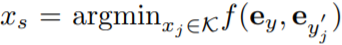
该研究认为图像 x_s 可以最好地描绘出文本描述 y,因为它可以以最小的信息损失将内容传递给接收者。此外,该研究将与文本 y 相对应的图像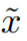 视为 y 的参考表示(reference presentation),并将最佳图像量化为它与参考图像的接近程度。
视为 y 的参考表示(reference presentation),并将最佳图像量化为它与参考图像的接近程度。
实验结果
图 3 中的左侧图表显示了两个数据集上图像重建质量和描述文本质量之间的相关性。对于每个给定图像,重建图像质量(在 x 轴中显示)越好,文本描述质量(在 y 轴中显示的)也越好。
图 3 的右侧图表揭示了恢复的文本质量和生成的图像质量之间的关系:对于每个给定的文本,重建的文本描述(显示在 x 轴上)越好,图像质量(显示在 y 轴上)就越好。
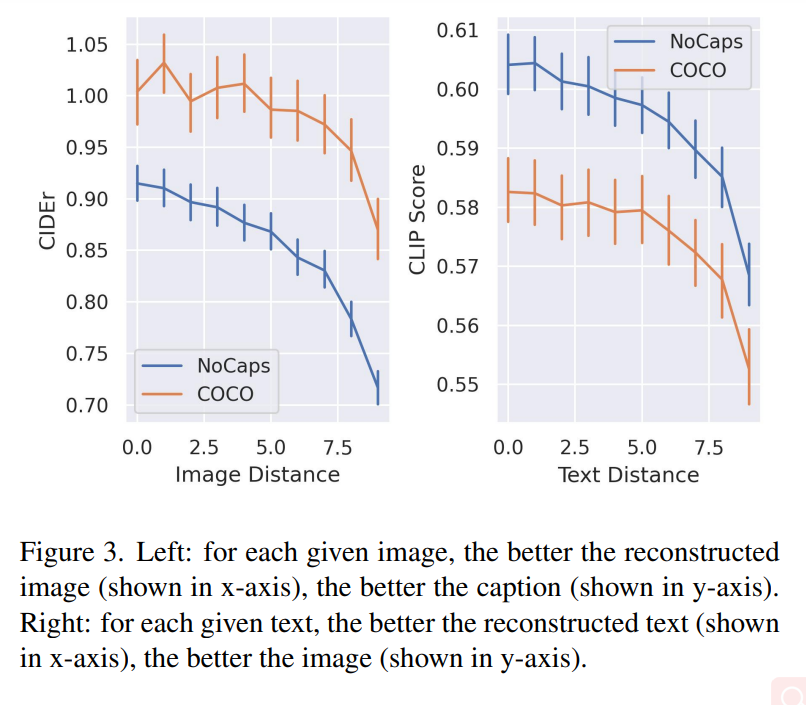
图 4(a)和(b)显示了图像重建质量和基于源图像的平均文本质量之间的关系。图 4(c)和(d)显示了文本距离(text distance)与重建图像质量之间的相关性。
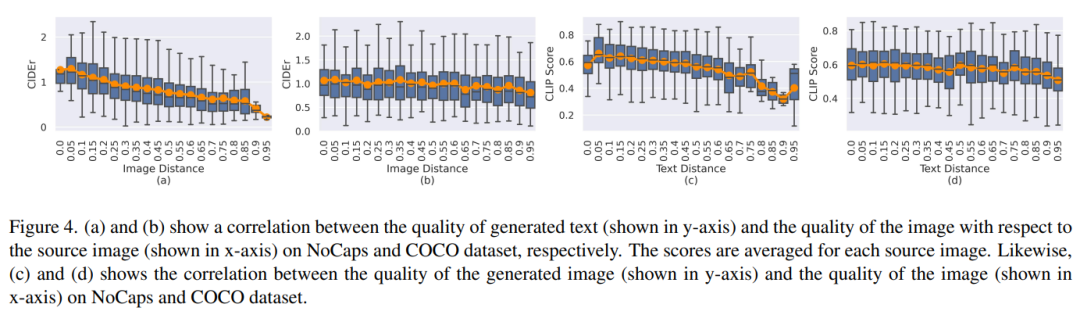
表 1 显示出该研究的采样方法在每个度量标准下都优于核采样,模型的相对增益可以高达 7.7%。
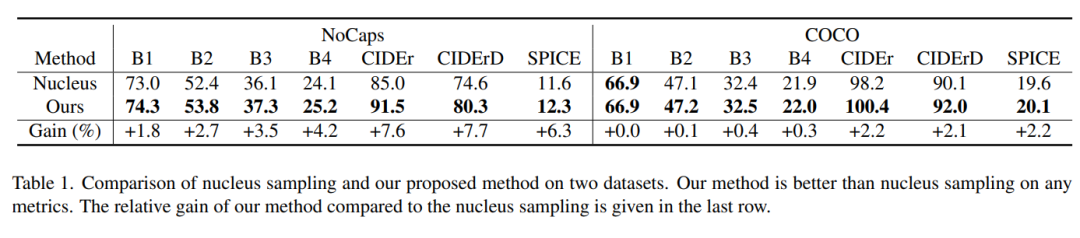
图 5 显示了两个重建任务的定性示例。

© 版权声明
文章版权归作者所有,未经允许请勿转载。


