
推理速度比Stable Diffusion快2倍;视觉Transformer统一图像文本
论文 1:One Model to Edit Them All: Free-Form Text-Driven Image Manipulation with Semantic Modulations
- 作者:Yiming Zhu 、 Hongyu Liu 等
- 论文地址:https://arxiv.org/pdf/2210.07883.pdf
摘要:本文首先利用已有的编码器将需要编辑的图像转换到 StyleGAN 的 W^+ 语义空间中的潜在编码 w,再通过提出的语义调制模块对该隐编码进行自适应的调制。该语义调制模块包括语义对齐和语义注入模块,首先通过注意力机制对齐文本编码和 GAN 的隐编码之间的语义,再将文本信息注入到对齐后的隐编码中,从而保证该隐编码拥有文本信息从而达到利用文本编辑图像能力。
不同于经典的 StyleCLIP 模型,我们的模型无需对每个文本单独训练一个模型,一个模型就可以响应多个文本从而对图像做有效的编辑,所以我们的模型成为 FFCLIP-Free Form Text-Driven Image Manipulation。同时我们的模型在经典的教堂,人脸以及汽车数据集上都取得了非常不错的效果。
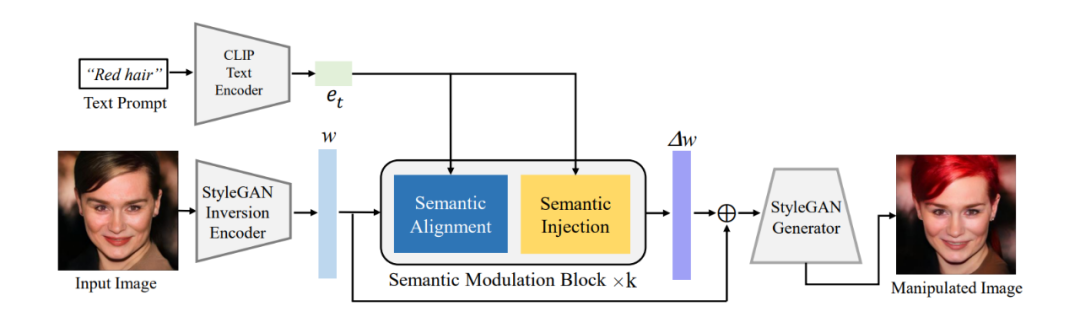
图 1:整体框架图
推荐:文本图片编辑新范式,单个模型实现多文本引导图像编辑。
论文 2:Printed Organic Photovoltaic Modules on Transferable Ultra-thin Substrates as Additive Power Sources
- 作者:Mayuran Saravanapavanantham、Jeremiah Mwaura 等
- 论文地址:https://onlinelibrary.wiley.com/doi/10.1002/smtd.202200940
摘要:麻省理工学院的研究人员已经开发出一种可扩展的制造技术,可以生产超薄、轻质的太阳能电池,这种电池可以铺设在任何表面上。
MIT 的研究人员制造出了比人类头发还薄的太阳能电池板,该电池板每公斤提供的能量是目前玻璃和硅基太阳能电池板的 18 倍。这些太阳能电池板的重量只有传统光电电池的百分之一。
这种超薄太阳能板也可以安装到船帆、无人机机翼和帐篷上。它们在偏远地区和救灾行动中尤其有用。

推荐:MIT 造出薄如纸的太阳能电池板。
论文 3:A Survey of Deep Learning for Mathematical Reasoning
- 作者:Pan Lu、 Liang Qiu 等
- 论文地址:https://arxiv.org/pdf/2212.10535.pdf
摘要:在近期发布的一篇报告中,来自 UCLA 等机构的研究者系统回顾了深度学习在数学推理方面的进展。
具体而言,本文讨论了各种任务和数据集(第 2 节),并研究了神经网络(第 3 节)和预训练语言模型(第 4 节)在数学领域的进展。此外还探讨了大型语言模型的上下文学习在数学推理中的快速发展(第 5 节)。文章进一步分析了现有的基准,发现对多模态和低资源环境的关注较少(第 6.1 节)。基于循证的研究表明,目前的计算能力表征是不充分的,深度学习方法在数学推理方面也是不一致的(第 6.2 节)。随后,作者建议在概括性和鲁棒性、可信推理、从反馈中学习和多模态数学推理方面改进目前的工作(第 7 节)。
推荐:深度学习如何慢慢推开数学推理的门。
论文 4:Muse: Text-To-Image Generation via Masked Generative Transformers
- 作者:Huiwen Chang 、 Han Zhang 等
- 论文地址:https://arxiv.org/pdf/2301.00704v1.pdf
摘要:该研究提出了一种使用掩码图像建模方法进行文本到图像合成的新模型,其中的图像解码器架构以来自预训练和 frozen T5-XXL 大型语言模型 (LLM) 编码器的嵌入为条件。
与建立在级联像素空间(pixel-space)扩散模型上的 Imagen (Saharia et al., 2022) 或 Dall-E2 (Ramesh et al., 2022) 相比,Muse 由于使用了离散 token,效率显著提升。与 SOTA 自回归模型 Parti (Yu et al., 2022) 相比,Muse 因使用并行解码而效率更高。
基于在 TPU-v4 上的实验结果,研究者估计 Muse 在推理速度上比 Imagen-3B 或 Parti-3B 模型快 10 倍以上,比 Stable Diffusion v1.4 (Rombach et al., 2022) 快 2 倍。研究者认为:Muse 比 Stable Diffusion 推理速度更快是因为 Stable Diffusion v1.4 中使用了扩散模型,在推理时明显需要更多次迭代。
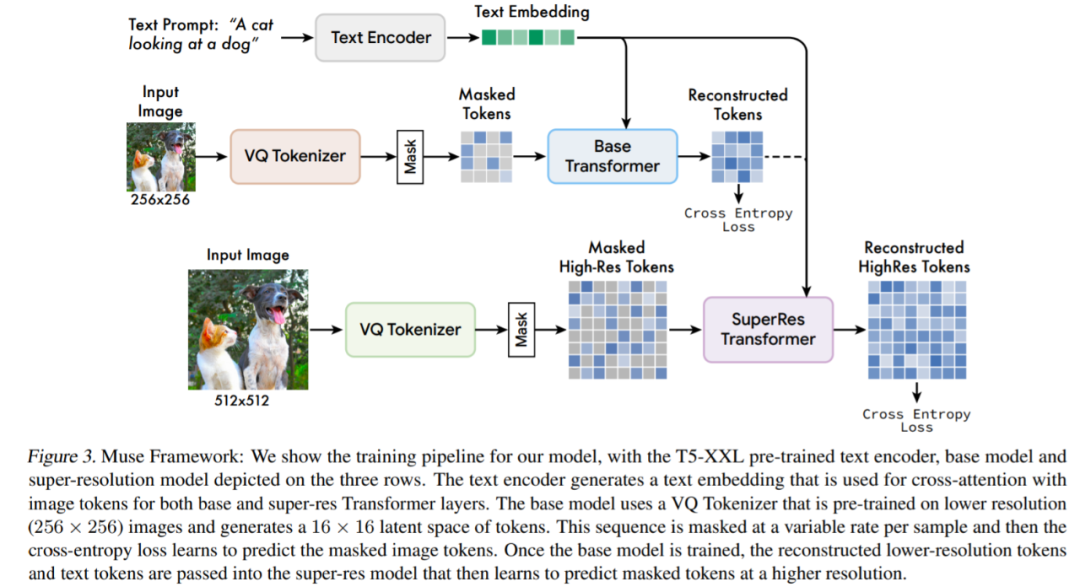
模型体系架构概述。
推荐:推理速度比 Stable Diffusion 快 2 倍,生成、修复图像谷歌一个模型搞定。
论文 5:Positive-Incentive Noise
- 作者:李学龙
- 论文地址:https://ieeexplore.ieee.org/document/10003114
摘要:在各式各样的科学研究的方方面面中,噪声大量存在,如仪器精度不足导致的仪器误差、人为操作中的失误导致的偏差、极端环境等外界干扰导致的信息失真等。研究者普遍认为噪声通常会对执行的任务产生不良影响,这已成为一个约定俗成的假设。因此,围绕着 “降噪” 这一核心任务产生了大量的研究工作。然而,西北工业大学李学龙教授团队在执行信号探测和处理任务时通过实验观察验证,对这一假设产生了质疑:科学研究中的噪声真的总是有害的吗?
恰如图 1 所示,在一个图像智能分类系统中,对图像加入适量的噪声后再训练,识别准确率反而上升了。这给我们带来一点启发:图像中加入一些噪声,而不是去除,再执行图像分类任务,可能效果会更好。只要噪声对目标的影响远小于噪声对背景的影响,产生 “伤敌(背景噪声)一千,自(目标信号)损八百” 的效果就有意义,因为任务追求的是高信噪比。从本质上来说,面对传统分类问题,在特征后随机加上适度的噪声,相当于升高了特征维度,某种意义上说,类似是给特征增加了一个核函数,实际上完成了一种低维空间到高维空间的映射,使数据更可分,从而提高了分类效果。
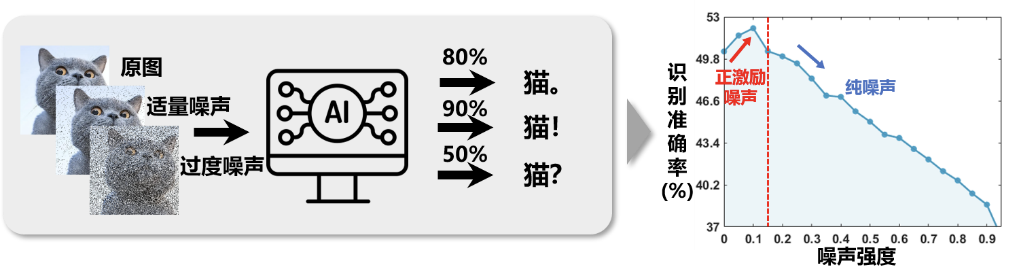
图 1 图像识别准确率随图像噪声强度的增大而 “反直觉” 地呈现出 “先增后减” 的关系。
推荐:西工大李学龙教授提出基于任务熵的数学分析框架。
论文 6:ABPN: Adaptive Blend Pyramid Network for Real-Time Local Retouching of Ultra High-Resolution Photo
- 作者:Biwen Lei 、 Xiefan Guo 等
- 论文地址:https://openaccess.thecvf.com/content/CVPR2022/papers/Lei_ABPN_Adaptive_Blend_Pyramid_Network_for_Real-Time_Local_Retouching_of_CVPR_2022_paper.pdf
摘要:来自达摩院的研究者以实现专业级的智能美肤为出发点,研发了一套高清图像的超精细局部修图算法 ABPN,在超清图像中的美肤与服饰去皱任务中都实现了很好的效果与应用。
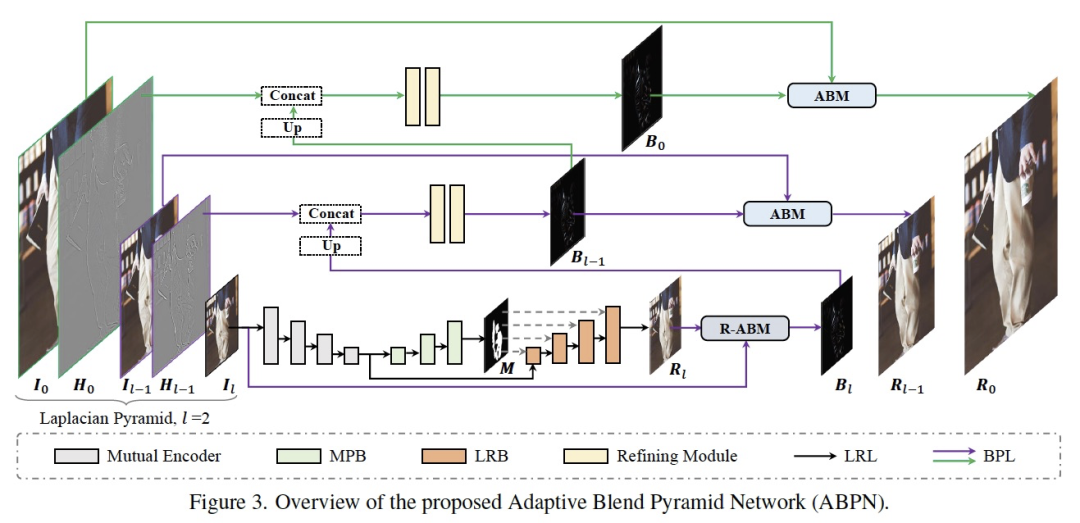
如上图所示,网络结构主要由两个部分组成:上下文感知的局部修饰层(LRL)和自适应混合金字塔层(BPL)。其中 LRL 的目的是对降采样后的低分辨率图像进行局部修饰,生成低分辨率的修饰结果图,充分考虑全局的上下文信息以及局部的纹理信息。进一步,BPL 用于将 LRL 中生成的低分辨率结果逐步向上拓展到高分辨率结果。其中,我们设计了一个自适应混合模块(ABM)及其逆向模块(R-ABM),利用中间混合图层 Bi,可实现原图与结果图之间的自适应转换以及向上拓展,展现了强大的可拓展性和细节保真能力。我们在脸部修饰及服饰修饰两个数据集中进行了大量实验,结果表明我们的方法在效果和效率上都大幅度地领先了现有方法。值得一提的是,我们的模型在单卡 P100 上实现了 4K 超高分辨率图像的实时推理。
推荐:一键抹去瑕疵、褶皱。
论文 7:Image-and-Language Understanding from Pixels Only
- 作者:Michael Tschannen、Basil Mustafa 等
- 论文地址:https://arxiv.org/pdf/2212.08045.pdf
摘要:开发一个可以处理任何模态或模态组合的单一端到端模型,将是多模态学习的重要一步。本文中,来自谷歌研究院(谷歌大脑团队)、苏黎世的研究者将主要关注图像和文本。
本文将对使用纯基于像素的模型进行文本和图像的多模态学习进行探索。该模型是一个单独的视觉 Transformer,它处理视觉输入或文本,或两者一起,所有都呈现为 RGB 图像。所有模态都使用相同的模型参数,包括低级特征处理;也就是说,不存在特定于模态的初始卷积、tokenization 算法或输入嵌入表。该模型仅用一个任务训练:对比学习,正如 CLIP 和 ALIGN 所推广的那样。因此模型被称作 CLIP-Pixels Only(CLIPPO)。
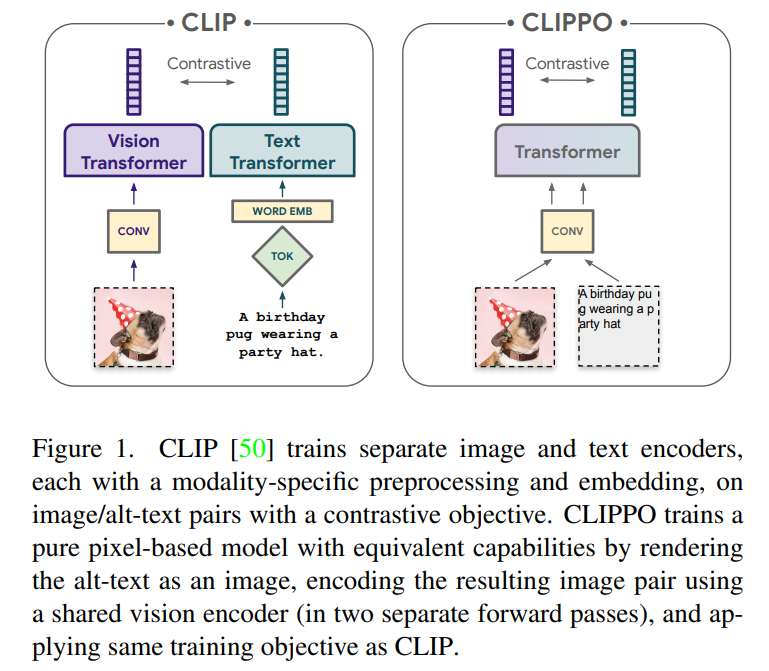
推荐:参数减半、与 CLIP 一样好,视觉 Transformer 从像素入手实现图像文本统一。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各 10 篇精选,并提供音频形式的论文摘要简介,详情如下:
10 NLP Papers音频:00:0020:02
本周 10 篇 NLP 精选论文是:
1. Rethinking with Retrieval: Faithful Large Language Model Inference. (from Hongming Zhang, Dan Roth)
2. Understanding Political Polarisation using Language Models: A dataset and method. (from Bhiksha Raj)
3. Towards Table-to-Text Generation with Pretrained Language Model: A Table Structure Understanding and Text Deliberating Approach. (from Hui Xiong)
4. Examining Political Rhetoric with Epistemic Stance Detection. (from Brendan O’Connor)
5. Towards Knowledge-Intensive Text-to-SQL Semantic Parsing with Formulaic Knowledge. (from Min-Yen Kan)
6. Leveraging World Knowledge in Implicit Hate Speech Detection. (from Jessica Lin)
7. Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers. (from Furu Wei)
8. EZInterviewer: To Improve Job Interview Performance with Mock Interview Generator. (from Tao Zhang)
9. Memory Augmented Lookup Dictionary based Language Modeling for Automatic Speech Recognition. (from Yuxuan Wang)
10. Parameter-Efficient Fine-Tuning Design Spaces. (from Diyi Yang)
10 CV Papers音频:00:0021:06
本周 10 篇 CV 精选论文是:
1. CA$^2$T-Net: Category-Agnostic 3D Articulation Transfer from Single Image. (from Jitendra Malik)
2. Mapping smallholder cashew plantations to inform sustainable tree crop expansion in Benin. (from Vipin Kumar)
3. Scale-MAE: A Scale-Aware Masked Autoencoder for Multiscale Geospatial Representation Learning. (from Trevor Darrell)
4. STEPs: Self-Supervised Key Step Extraction from Unlabeled Procedural Videos. (from Rama Chellappa)
5. Muse: Text-To-Image Generation via Masked Generative Transformers. (from Ming-Hsuan Yang, Kevin Murphy, William T. Freeman)
6. Understanding Imbalanced Semantic Segmentation Through Neural Collapse. (from Xiangyu Zhang, Jiaya Jia)
7. Cross Modal Transformer via Coordinates Encoding for 3D Object Dectection. (from Xiangyu Zhang)
8. Learning Road Scene-level Representations via Semantic Region Prediction. (from Alan Yuille)
9. Learning by Sorting: Self-supervised Learning with Group Ordering Constraints. (from Bernt Schiele)
10. AttEntropy: Segmenting Unknown Objects in Complex Scenes using the Spatial Attention Entropy of Semantic Segmentation Transformers. (from Pascal Fua)
10 ML Papers音频:00:0023:15
本周 10 篇 ML 精选论文是:
1. Self-organization Preserved Graph Structure Learning with Principle of Relevant Information. (from Philip S. Yu)
2. Modified Query Expansion Through Generative Adversarial Networks for Information Extraction in E-Commerce. (from Altan Cakir)
3. Disentangled Explanations of Neural Network Predictions by Finding Relevant Subspaces. (from Klaus-Robert Müller)
4. L-HYDRA: Multi-Head Physics-Informed Neural Networks. (from George Em Karniadakis)
5. On Transforming Reinforcement Learning by Transformer: The Development Trajectory. (from Dacheng Tao)
6. Boosting Neural Networks to Decompile Optimized Binaries. (from Kai Chen)
7. NeuroExplainer: Fine-Grained Attention Decoding to Uncover Cortical Development Patterns of Preterm Infants. (from Dinggang Shen)
8. A Theory of Human-Like Few-Shot Learning. (from Ming Li)
9. Temporal Difference Learning with Compressed Updates: Error-Feedback meets Reinforcement Learning. (from George J. Pappas)
10. Estimating Latent Population Flows from Aggregated Data via Inversing Multi-Marginal Optimal Transport. (from Hongyuan Zha)
© 版权声明
文章版权归作者所有,未经允许请勿转载。


