
被GPT带飞的In-Context Learning发展现状如何?这篇综述梳理明白了
随着语言模型和语料库规模的逐渐扩大,大型语言模型(LLM)展现出更多的潜力。近来一些研究表明,LLM 可以使用 in-context learning(ICL)执行一系列复杂任务,例如解决数学推理问题。
来自北京大学、上海 AI Lab 和加州大学圣巴巴拉分校的十位研究者近期发布了一篇关于 in-context learning 的综述论文,详细梳理了 ICL 研究的当前进展。

论文地址:https://arxiv.org/pdf/2301.00234v1.pdf
in-context learning 的核心思路是类比学习,下图描述了语言模型如何使用 ICL 进行决策。
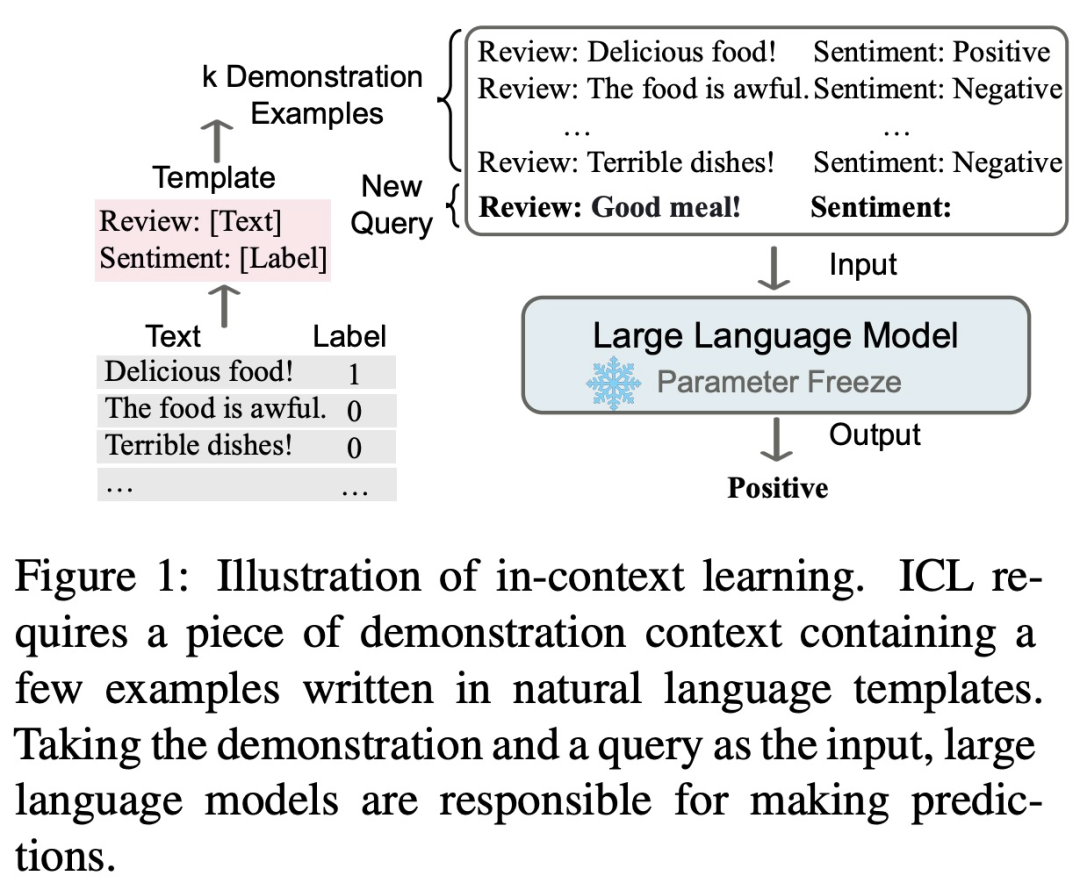
首先,ICL 需要一些样例来形成演示语境,这些样例通常用自然语言模板编写。然后,ICL 将查询问题和演示语境相联系,形成 prompt,并且将其输入语言模型进行预测。与监督学习需要使用反向梯度更新模型参数的训练阶段不同,ICL 不需要参数更新即可使预训练语言模型直接执行预测任务,并且模型有望学习演示样例中隐藏的模式,并据此做出正确的预测。
作为一种新的范式,ICL 有很多吸引人的优势。首先,演示样例用自然语言格式编写,这为与大语言模型关联提供了一个可解释的接口。通过改变演示样例和模板(Liu et al., 2022; Lu et al., 2022; Wu et al., 2022; Wei et al., 2022c),这种范式使将人类知识纳入语言模型变得更加容易。第二,in-context learning 类似于人类通过类比学习的决策过程。第三,与监督式训练相比,ICL 是一个无需训练的学习框架。这不仅可以大大降低模型适应新任务的计算成本,而且还可以使语言模型即服务(LMaaS,Sun et al., 2022)成为可能,并轻松应用于大规模的现实任务。
尽管 ICL 有着大好的前景,但仍存在许多值得探究的问题,包括它的性能。例如原始的 GPT-3 模型就具备一定的 ICL 能力,但一些研究发现,通过预训练期间的适应,这种能力还可以获得显著的提升。此外,ICL 的性能对特定的设置很敏锐,包括 prompt 模板、语境样例的选择和样例顺序等。此外,ICL 的工作机制虽然看似合理,但仍不够清晰明了,能够初步解释其工作机制的研究也不多。
本篇综述论文总结道,ICL 的强大性能依赖于两个阶段:
- 培养大型语言模型 ICL 能力的训练阶段;
- 大型语言模型根据特定任务演示进行预测的推理阶段。
在训练阶段,语言模型直接按照语言建模目标进行训练,例如从左到右的生成。尽管这些模型并没有专门针对 in-context learning 进行优化,但 ICL 的能力依旧令人惊喜。现有的 ICL 研究基本以训练良好的语言模型为主干。
在推理阶段,由于输入和输出的 label 都是用可解释的自然语言模板表征的,因此 ICL 性能可以从多个角度得到优化。该综述论文进行了详细的描述和比较,并选择合适的例子进行演示,针对不同的任务设计具体的评分方法。
这篇综述论文的大致内容和结构如下图所示,包括:ICL 的正式定义 (§3)、warmup 方法 (§4)、prompt 设计策略 (§5) 和评分函数 (§6)。
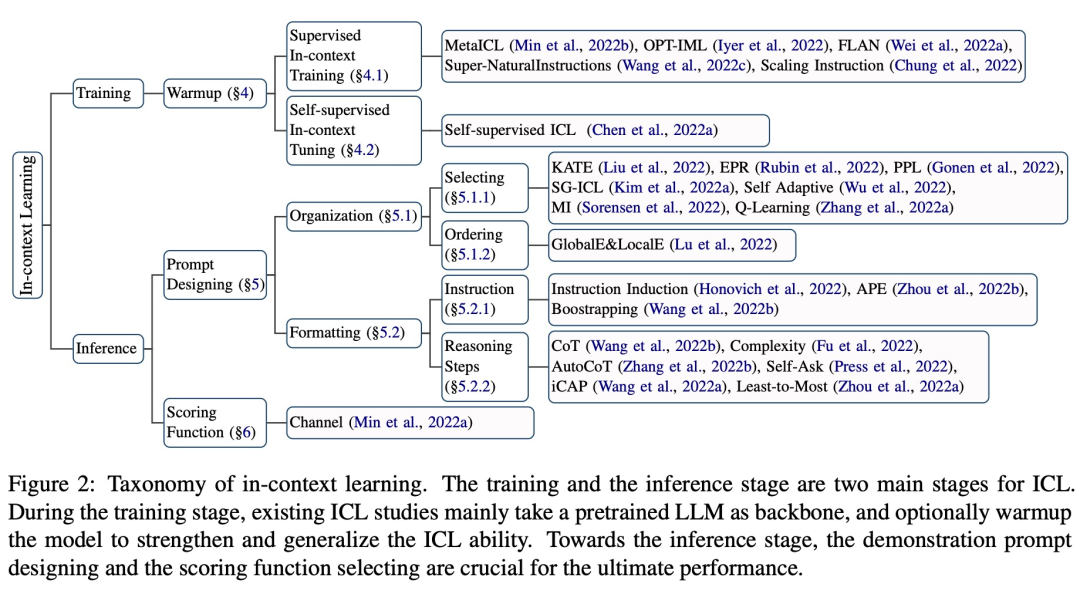
此外,§7 深入阐述了当前为揭开 ICL 背后工作原理所做的探索。§8 进一步为 ICL 提供了有用的评估与资源,§9 介绍了能显示出 ICL 有效性的潜在应用场景。最后,§10 总结了 ICL 领域存在的挑战和潜在的方向,为该领域的进一步发展提供参考。
感兴趣的读者可以阅读论文原文,了解更多研究细节。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


