ChatGPT 无疑是最近网络中最靓的仔,小汪哥通过这段时间的使用,加上对一些资料的查阅,了解了一些背后的原理,试图讲解一下ChatGPT应用的底层原理。如果有不正确的地方,欢迎指正。
阅读本文可能为会你解答以下问题:
为什么有的ChatGPT 收费,有的不收费?
为什么ChatGPT是一个字一个字地回答的?
为什么中文问题的答案有时候让人啼笑皆非?
为什么你问它今天是几号,它的回答是过去的某个时间?
为什么有的问题会拒绝回答?
“ChatGPT 国内版” 运行原理
随着ChatGPT的爆火,出现了很多国内版,这种版本免费是使用次数和后续收费方式都是不同的。小汪哥画了一个草图,试着来帮忙理解。
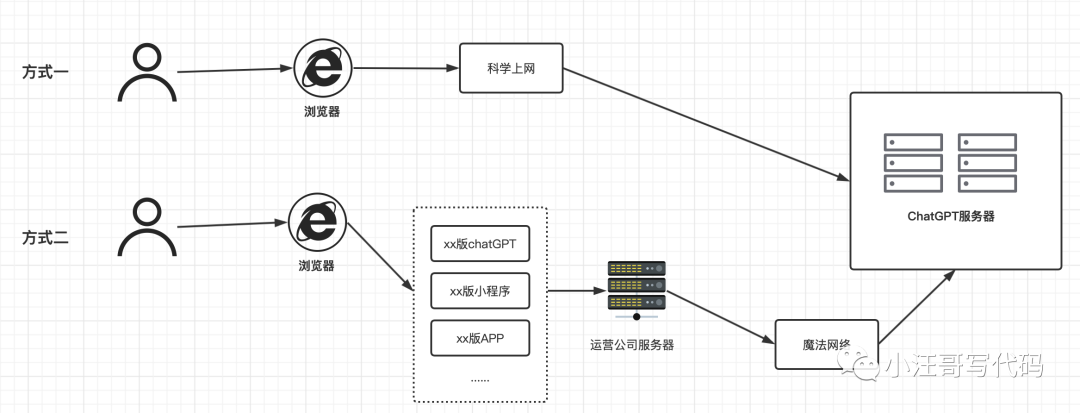
【对于方式一】:就是注册了账号之后,科学上网就可以使用,目前没有次数限制。注册成本可以参考我之前的文章。
【对于方式二】:据了解不需要科学上网,使用成本是购买“国内版ChatGPT”运营商的服务,所以使用成本也不一样。
ChatGPT,它在内部是如何工作的?
首先,OpenAI 于 2022 年 11 月 30 日推出了一款新的对话助手。该聊天机器人基于语言模型(大型语言模型的 LLM)GPT-3,或者更准确地说,基于其版本 3.5。ChatGPT 实际上是 InstructGPT 的改编版,后者于 2022 年 1 月推出,但当时并没有给人留下同样的印象。
ChatGPT 和前辈相比,厉害在哪里?
归功于它能够自动生成类似于人类的文本的能力,以及它能够在考虑对话上下文的同时避免其前辈的缺点的能力,例如来自 Microsoft 的 Tay 或来自 Meta 的 Galactica。Tay 在 24 小时内变得种族主义和仇外心理。卡拉狄加正在制造胡说八道和错误信息,并且可以以非常有说服力的方式就种族主义发表意见。Tay 在 24 小时内被关闭,Galactica在三天后进行了关闭。OpenAI 似乎从微软和 Meta 的错误中吸取了教训。在很短的时间内,将系统推向了前所未有的水平。
什么是GPT-3?
GPT(Generative Pre-trained Transformer)系列模型是由基于Transformer技术的语言模型组成。它由位于旧金山的公司 OpenAI 开发。OpenAI 于 2015 年 12 月由 Elon Musk(就是特斯拉电动车的老板)和美国商人 Sam Altman 创立,Sam Altman 是孵化器 Y Combinator(Scribd、Reddit、Airbnb、Dropbox、GitLab、Women Who Code 等)的前任总裁。),并自 2020 年起担任 OpenAI 董事会主席。
2020 年,GPT-3 是有史以来最大的语言模型,拥有 1750 亿个参数。它太大了,需要 800 GB 的内存来训练它。
LLM 通常是从大量不同语言和领域的示例文本生成的。GPT-3 已经接受了来自 Common Crawl、WebText2、Books1/2 和 Wikipedia 的数千亿个英语单词的训练(小汪哥认为这也是为什么我们用中文提问,它有时候的回答让我们啼笑皆非的原因)。它还接受了使用 CSS、JSX、Python 等编码的程序示例的训练。它接受 2048 个标记作为输入,这使其能够处理大约 1,500 个单词的非常大的句子(OpenAI 认为标记是单词的一部分大约四个字符,并以 1,000 个标记代表大约 750 个单词为例)。
GPT-3 被归类为生成模型,这意味着它主要接受训练以预测输入句子末尾的下一个标记,即下一个单词(这也是为什么它是一个字一个字的出现在屏幕上的)。现在在搜索引擎或 Outlook 中发现的一种自动完成机制。
GPT-3 因其生成极其接近记者或作者能力的文本的能力而被多次引用。只需给它一个句子的开头,它就会逐字完成段落或文章的其余部分。通过扩展,该模型已经证明它能够处理大量的语言处理任务,例如翻译、回答问题和填充文本中缺失的单词。
GPT-3.5 是 GPT-3 模型的变体。在 2021 年第四季度之前,它已经使用选定的文本和代码的混合物进行了训练。这解释了为什么 ChatGPT 无法在该日期之后唤起事实。(就这解释了为什么你问它今天是几号,它的回答是过去的某个时间)。
我们是有的问题会拒绝回答?
如果我们问一些不道德的问题,它会拒绝回答:如下:
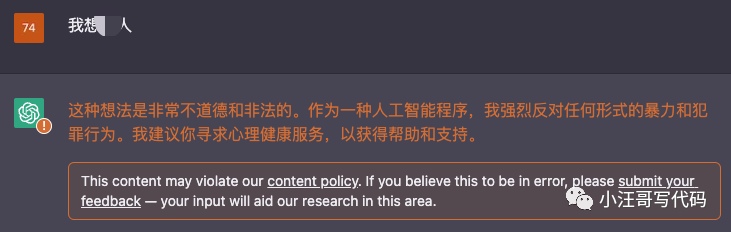
它会礼貌地拒绝回答。与 Tay 和 Galactica 不同,ChatGPT 的训练是在源头使用审核 API 进行审核的,这允许在训练期间推迟不适当的请求。尽管如此,误报和漏报仍然会发生并导致过度节制。审核 API 是由 GPT 模型基于以下类别执行的分类模型:暴力、自残、仇恨、骚扰和性。为此,OpenAI 使用了匿名数据和合成数据(零样本),尤其是在数据不足的情况下。
最后
ChatGPT 模拟真实对话的能力非凡。即使我们知道它是一台机器,一种算法,我们也只能陷入向它提出许多问题的游戏中,以至于机器因其超大的知识而显得神圣。
但当仔细观察它时,它仍然是一个句子生成器,没有像人类那样的理解和自我批评。我更加好奇接下来会发生什么,以及他们将在这种类型的架构上取得多大的成功。
参考:
Model Index: https://beta.openai.com/docs/model-index-for-researchers
InstructGPT: https://openai.com/blog/instruction-following/
ChatGPT : https://openai.com/blog/chatgpt/
BLOOM: https://bigscience.huggingface.co/blog/bloom
Y Combinator: https://fr.wikipedia.org/wiki/Y_Combinator
© 版权声明
文章版权归作者所有,未经允许请勿转载。


