IBM开发云原生AI超级计算机Vela 可灵活部署并训练数百亿参数模型
ChatGPT红遍网络,其背后的AI模型训练也广受关注。IBM研究部门日前宣布,其开发的云原生超级计算机Vela可以快速部署并用于训练基础AI模型。自2022年5月以来,该公司数十名研究人员一直在使用这款超级计算机训练具有数百亿参数的AI模型。
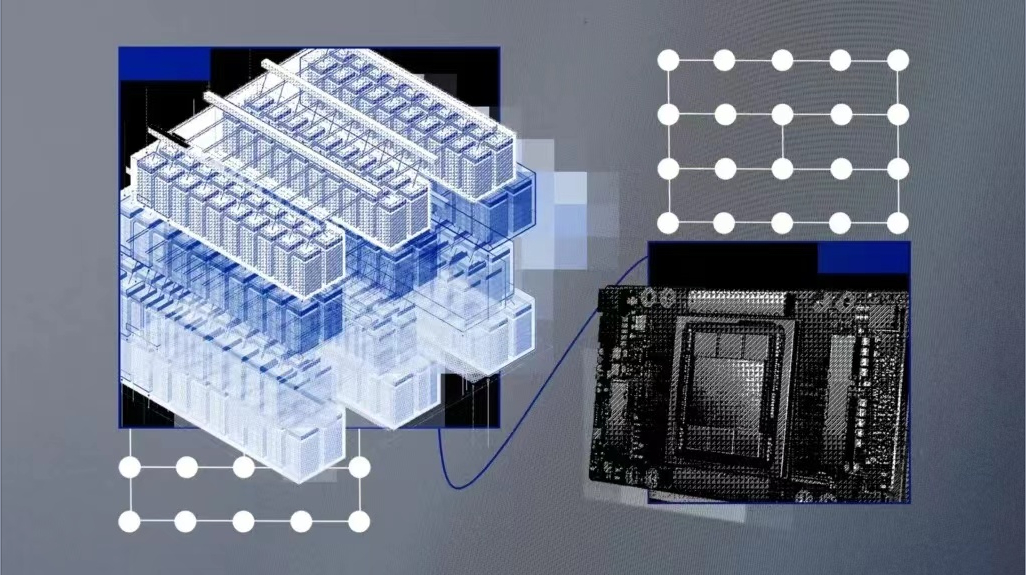
基础模型是基于大量未标记数据训练的AI模型,它们的通用性意味着只需微调就可以用于一系列不同的任务。它们的规模非常庞大,需要大量且成本高昂的计算能力。因此正如专家表示,计算能力将成为开发下一代大规模基础模型的最大瓶颈,训练它们需要花费大量算力和时间。
训练可以运行数百亿个或数千亿个参数的模型,需要采用高性能的计算硬件,包括网络、并行文件系统和裸机节点等。这些硬件很难部署,运行成本也很高。微软于2020年5月为OpenAI建造了AI超级计算机,并托管在Azure云平台中。但IBM表示,它们是由硬件驱动的,这增加了成本,并限制了灵活性。
云端AI超级计算机
因此,IBM创建了名为Vela的“专门专注于大规模AI”的系统。
Vela可以根据需要部署到IBM的任何一个云数据中心中,它本身就是一个“虚拟云”。与构建物理的超级计算机相比,虽然这种方法在计算能力方面有所下降,但创造了一个更灵活的解决方案。云计算解决方案通过API接口为工程师提供资源,更方便地访问广泛的IBM云生态系统以进行更深入的集成,并能够根据需要扩展性能。
IBM工程师解释说,Vela能够访问IBM云对象存储上的数据集,而不是构建自定义存储后端。以往这些基础设施必须单独构建到超级计算机中。
任何AI超级计算机的关键组成部分都是大量的GPU以及连接它们的节点。Vela其实是将每个节点配置为虚拟机(而不是裸机),这是最常见的方法,也被广泛认为是AI训练最理想的方法。
Vela是如何构建的?
云端虚拟计算机的弊病之一是性能不能保证。为了解决性能下降问题,并在虚拟机内部提供裸机性能,IBM工程师找到了一种释放全部节点性能(包括GPU、CPU、网络和存储),并将负载损耗降低到5%以下的方法。
这涉及到为虚拟化配置裸机主机,支持虚拟机扩展、大型页面和单根IO虚拟化,以及真实地表示虚拟机内的所有设备和连接;还包括网卡与CPU和GPU匹配,以及它们彼此之间如何桥接起来。完成这些工作后,他们发现虚拟机节点的性能“接近裸机”。
此外,他们还致力于设计具有大型GPU内存和大量本地存储的AI节点,用于缓存AI训练数据、模型和成品。在使用PyTorch的测试中,他们发现通过优化工作负载通信模式,与超级计算中使用的类似Infiniband的更快的网络相比,他们还能够弥补以太网网络相对较慢的瓶颈。
配置方面,每个Vela都采用了8个80GB A100 GPU、两个第二代Intel Xeon可扩展处理器、1.5TB内存和四个3.2TB NVMe硬盘驱动器,并能够以任何规模部署到IBM在全球的任何一个云数据中心。
IBM的工程师表示:“拥有合适的工具和基础设施是提高研发效率的关键因素。许多团队选择遵循为AI构建传统超级计算机的可靠路径……我们一直在研究一种更好的解决方案,以提供高性能计算和高端用户生产力的双重好处。”
© 版权声明
文章版权归作者所有,未经允许请勿转载。