
如何在卷积神经网络上运行 BERT?
你可以直接用 SparK —— 字节跳动技术团队提出的稀疏层次化掩码建模 (Designing BERT for Convolutional Networks: Sparse and Hierarchical Masked Modeling),近期已被人工智能顶会收录为 Spotlight 焦点论文:

论文链接:
https://arxiv.org/pdf/2301.03580
开源代码:
https://github.com/keyu-tian/SparK
这也是 BERT 在卷积神经网络 (CNN) 上的首次成功。先来感受一下 SparK 在预训练中的表现吧。
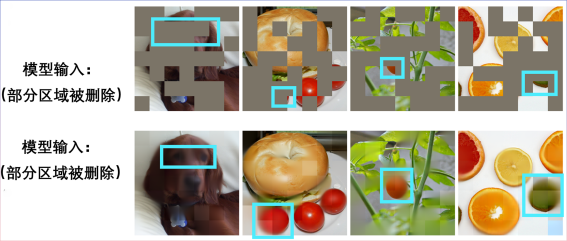
输入一张残缺不全的图片:

还原出一只小狗:

另一张残缺图片:

原来是贝果三明治:

其他场景也可实现图片复原:

BERT 和 Transformer 的天作之合
“任何伟大的行动和思想,都有一个微不足道的开始。”
在 BERT 预训练算法的背后,是简洁而深刻的设计。 BERT 使用“完形填空”:将一句话中的若干词语进行随机删除,并让模型学会恢复。
BERT 非常依赖于 NLP 领域的核心模型 —— Transformer。
Transformer 由于生来就适合处理可变长度的序列数据(例如一个英文句子),所以能轻松应付 BERT 完形填空的“随机删除”。
视觉领域的 CNN 也想享受 BERT:两个挑战何在?
回顾计算机视觉发展史,卷积神经网络模型凝练了平移等变性、多尺度结构等等众多经典模型精华,可谓CV 界的中流砥柱。但与 Transformer 大相径庭的是,CNN 天生无法适应经过完形填空“挖空”的、充满“随机孔洞”的数据,因此乍一看无法享受到 BERT 预训练的红利。

上图 a. 展示的是 MAE (Masked Autoencoders are Scalable Visual Learners) 这项工作,由于使用的是 Transformer 模型而非 CNN 模型,其可以灵活应对经过带有空洞的输入,乃与 BERT “天作之合”。
而右图 b. 则展示了一种粗暴融合 BERT 和 CNN 模型的方式——即把全部空洞区域“涂黑”,并将这张“黑马赛克”图输入到 CNN 中,结果可想而知,会带来严重的像素强度分布偏移问题,并导致很差的性能 (后文有验证)。这就是阻碍 BERT 在 CNN 上成功应用的挑战一。
此外,作者团队还指出,源自 NLP 领域的 BERT 算法,天然不具备“多尺度”的特点,而多尺度的金字塔结构在计算机视觉的悠久历史中可谓“金标准”。单尺度的 BERT,和天然多尺度的 CNN 之间的冲突,则是挑战二。
解决方案 SparK:稀疏且层次化的掩码建模

作者团队提出了 SparK (Sparse and hierarchical masKed modeling) 来解决前文两个挑战。
其一,受三维点云数据处理的启发,作者团队提出将经过掩码操作 (挖空操作) 后的零碎图片视为稀疏点云,并使用子流形稀疏卷积 (Submanifold Sparse Convolution) 来进行编码。这就让卷积网络能够自如处理随机删除后的图像。
其二,受 UNet 优雅设计的启发,作者团队自然地设计了一种带有横向连接的编码器-解码器模型,让多尺度特征在模型的多层次之间流动,让 BERT 彻底拥抱计算机视觉的多尺度黄金标准。
至此,一种为卷积网络 (CNN) 量身定制的稀疏的、多尺度的掩码建模算法 SparK 诞生了。
SparK 是通用的:其可被直接运用在任何卷积网络上,而无需对它们的结构进行任何修改,或引入任何额外的组件——不论是我们耳熟能详的经典 ResNet,还是近期的先进模型 ConvNeXt,均可直接从 SparK 中受益。
从 ResNet 到 ConvNeXt:三大视觉任务性能提升
作者团队选择了具代表性的两个卷积模型家族 ResNet 和 ConvNeXt,并在图像分类,目标检测、实例分割任务上进行了性能测试。
在经典 ResNet-50 模型上,SparK 作为唯一的生成式预训练,达到了 State-of-the-art 水准:

在 ConvNeXt 模型上,SparK 依旧领先。在预训练前,ConvNeXt 与 Swin-Transformer 平分秋色;而经预训练后,ConvNeXt 在三个任务上均压倒性超过了 Swin-Transformer:

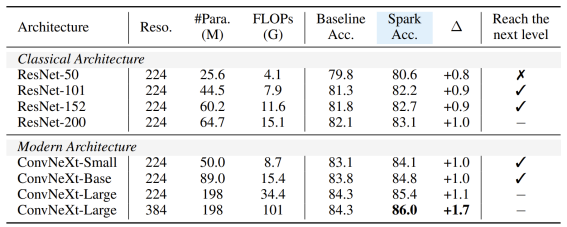
当从小到大,在完整的模型家族上验证 SparK,便可观察到:
无论模型的大与小、新与旧,均可从 SparK 中受益,且随着模型尺寸/训练开销的增长,涨幅甚至更高,体现出 SparK 算法的扩放 (scaling) 能力:
最后,作者团队还设计了一个验证性的消融实验,从中可见稀疏掩码和层次化结构第3行和第4行) 均是非常关键的设计,一旦缺失就会造成严重的性能衰退:

© 版权声明
文章版权归作者所有,未经允许请勿转载。


