然而,传统的人工监管方式存在如下问题:
- 人工监管无法实时记录出入车辆的综合信息,并将信息格式化输出,例如车牌、出入状态、车辆颜色、车辆类别等;
- 人工监管无法实时抓拍车辆图片,作为备份存储,更加客观地呈现车辆外观;
- 人工监管可能存在由于门卫疲劳导致疏漏或者记录错误;
- 人工监管无法24小时全天监控车辆,不方便门卫进行其他工作。
传统的人工监管方式弊端日益突出,需要采用新方式对车辆进行监管。智慧家庭运营中心自研场景化AI智能分析能力,建设面向社区和乡村的“车辆车牌多能力摄像头”。主要针对社区门口和道路场景,对经过的车辆进行结构化信息提取,并将车辆图片抓拍上报给平台,提示工作人员做出相应处理回应。实现“预防为主、防微杜渐、全程监管、社会共治”的创新性监管模式。
Part 01、 车辆车牌检测
目标检测是比图像分类更进一步的AI技术,目标检测除了需要识别分类图片中的目标类别,还需要将目标用边界框标出。于是目标检测任务流程可以分为两个类别,包括One-stage和Two-stage方法。最初的目标检测任务都是Two-stage算法,该算法主要分为两个步骤,包括检测框的确定和目标分类。首先通过特定的网络结构生成目标的检测框,确定目标边界,然后对边界框中的内容进行图像分类,确定其属于何种类别。Two-stage算法中最著名的算法是Faster R-CNN,它的检测精度高,然而算法运行速度慢,不适用于摄像头端侧处理。相比之下,One-stage算法直接通过网络同时确定目标的边界框和类别。其中,YOLO系列是应用最广泛也是端侧最成熟的One-stage目标检测算法,经过5个版本的迭代,YOLOv5同时保证了运行速度和算法精度,于是在端侧我们使用YOLOv5作为车辆车牌检测算法,图1(a)是YOLOv5主要算法框架[1]。为了进一步提高检测速度,我们使用模型剪枝和量化方法轻量化算法框架。图1(b)是道路场景检测示意图。
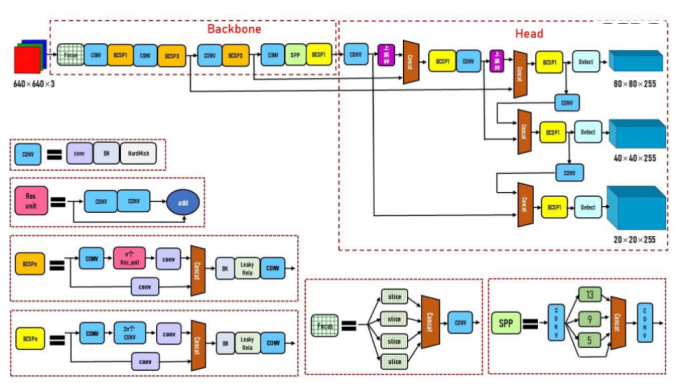
图1(a) YOLOv5主要算法框架

图1(b) 道路场景检测示意图
Part 02、 车牌字符识别
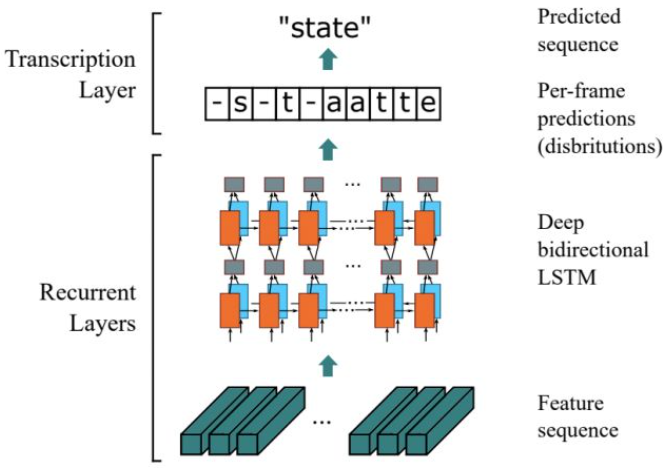
在车牌字符识别步骤中使用了文字识别技术。我们基于车牌检测的结果,识别车牌区域上的文字内容。在文字识别算法中,通常使用基于CTC的字符识别算法,其中典型的算法模型是CRNN[2],图2是CRNN算法结构图,CRNN网络主要分为CNN和RNN网络。首先使用CNN网络如VGG、ResNet、MobileNet等主干网络提取文字区域的深度特征,然后使用双向LSTM结构处理深度特征获得输入图片的上下文信息的序列特征,最终将序列特征输入到CTC损失函数,解码序列结果。
在实际应用中,由于摄像头抓拍角度问题,车牌图片往往存在一定的形变,不规则的文本不利于识别。为了提高该场景下的识别精度,我们在车牌检测之后,文本识别之前加入文本矫正模块,将不规则文本矫正为规则文本。利用空间变换网络STN[3],通过空间变换矫正不规则的文字图片,使其成为水平方向的规整图片,再将其送入到CRNN算法获得车牌字符识别的结果。
(a)

(b)
图2 CRNN算法结构以及矫正网络结构
Part 03、 车辆属性识别
车辆属性主要包括车辆类型和颜色信息。在实际的抓拍过程中,抓拍到的往往是车辆局部信息,如图3所示,视角的局限性和环境的影响,会降低车辆属性识别的准确率。为了尽量多且连续地抓拍车辆的综合信息,我们采用3D卷积分类,提取整个时间序列上的车辆信息,对于某段时间在不同视角的车辆进行属性识别。

图3 抓拍的单帧图片视角局限
二维卷积是对单帧图片进行卷积操作,二维卷积的输入是H*W的二维矩阵。而三维卷积[4]是对多帧图片进行卷积操作,三维卷积的输入是H*W*C的三维矩阵,相比之下多了深度C。三维卷积在图片的三个方向分别滑动,每个位置都会通过卷积运算输出一个数值。相比于二维卷积,三维卷积可以将时序上的多帧图片同时卷积,获得图片的时序特征。图4是三维卷积分析车辆属性示意图。
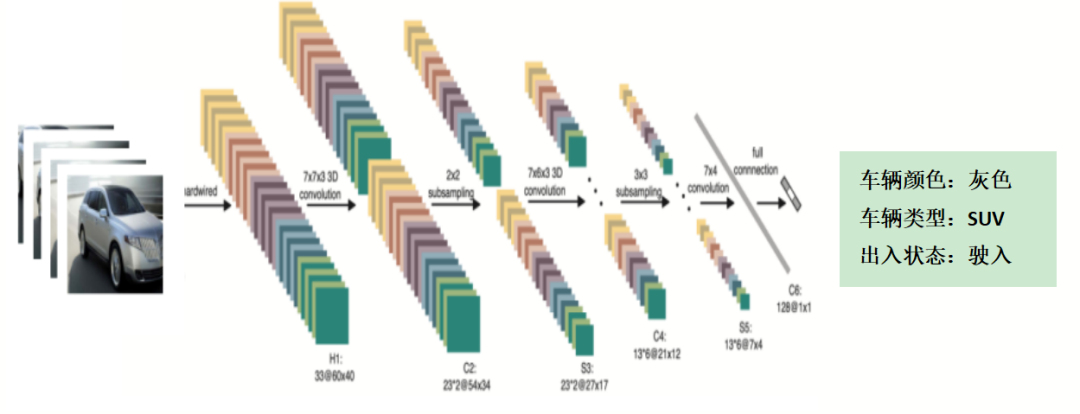
图4 采用3D卷积获得车辆属性识别结果
Part 04、 结束语
智慧家庭运营中心的“车辆车牌多能力摄像头”利用CV技术解决出入口传统车辆监控方式存在的诸多问题,围绕社区、乡村车辆的监管需求,实现“预防为主、防微杜渐、全程监管、社会共治”的创新监管模式。
目前已经落地甘肃31个小区,并以此为锚点,拓展场景化业务,助力安防业务升级转型,落实智能防疫和数字乡村建设。
参考文献
[1] https://zhuanlan.zhihu.com/p/172121380
[2] Baoguang Shi, Xiang Bai, and Cong Yao. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. In TPAMI, volume 39, pages 2298–2304.
[3] Max Jaderberg, Karen Simonyan, Andrew Zisserman, et al. Spatial transformer networks. In NIPS, pages 2017–2025.
[4] Ji S, Xu W, Yang M, et al. 3D convolutional neural networks for human action recognition[J]. IEEE transactions on pattern analysis and machine intelligence, 2013, 35(1): 221-231.
© 版权声明
文章版权归作者所有,未经允许请勿转载。