

导读:对话技术是数字人交互的核心能力之一,这次分享主要从百度 PLATO 相关的研发和应用出发,谈谈大模型对对话系统的影响和对数字人的一些机会,本次分享题目为:大模型推动的人机交互对话。
今天的介绍从以下几点展开:
- 对话系统概览
- 百度 PLATO 及相关技术
- 对话大模型落地应用、挑战及展望
一、对话系统概览
1、对话系统概览
日常生活中,我们常常接触到一些偏任务类型的对话系统,比如让手机助手定闹铃、让智能音箱放首歌。这种在特定领域内的垂类对话,技术相对成熟,系统设计上通常是模块化的,包括对话理解、对话管理、自然语言生成等模块。
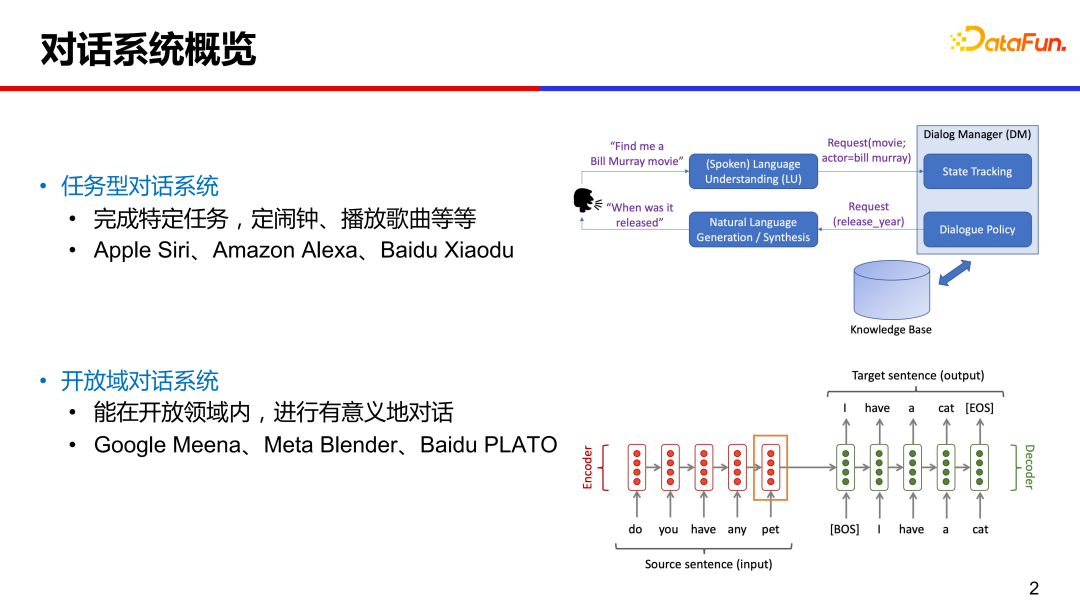
传统任务型对话的大致流程如下:用户输入一句话,系统通过自然语言理解模块,解析出相关的意图和槽值对(slot-value pairs),这些词槽是预先定义好的;通过对话管理模块追踪多轮对话状态,以及与外部数据库交互,进行系统动作的决策;然后通过对话生成模块,产出回复返回给用户。
最近几年很多研究是关于开放域对话技术,即不限定领域、可以就任意话题聊天。代表性的工作有 Google Meena、Mata Blender 和 Baidu PLATO 等,与传统模块化的对话系统相比,这些端到端的对话系统是给定对话上文,直接生成相应的回复。
2、端到端对话生成——对话系统的新机遇
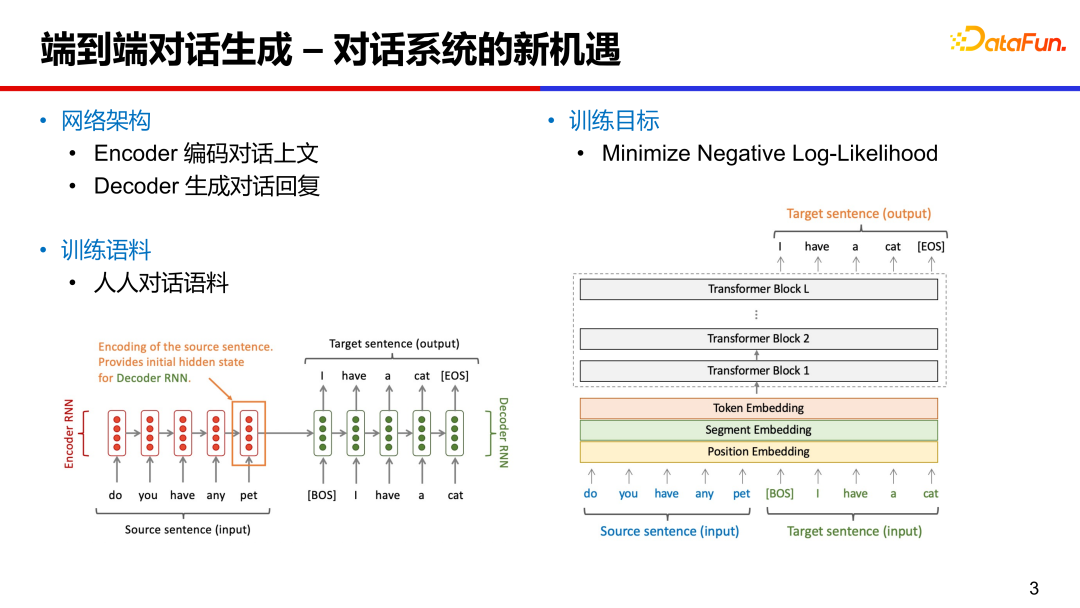
端到端对话系统可以基于 RNN、LSTM 或 Transformer 等进行设计,网络架构主要包括两部分:编码器 Encoder 和解码器 Decoder。
编码器将对话上文编码成向量,对对话内容做理解。
解码器是根据对话向量和之前的隐藏向量,生成相应的回复。训练语料主要是人人对话语料,可以从公开的社交媒体论坛(微博、贴吧、推特等)抽取评论作为近似的对话语料。训练目标主要是最小化负对数似然函数。
3. 开放域对话面临的挑战
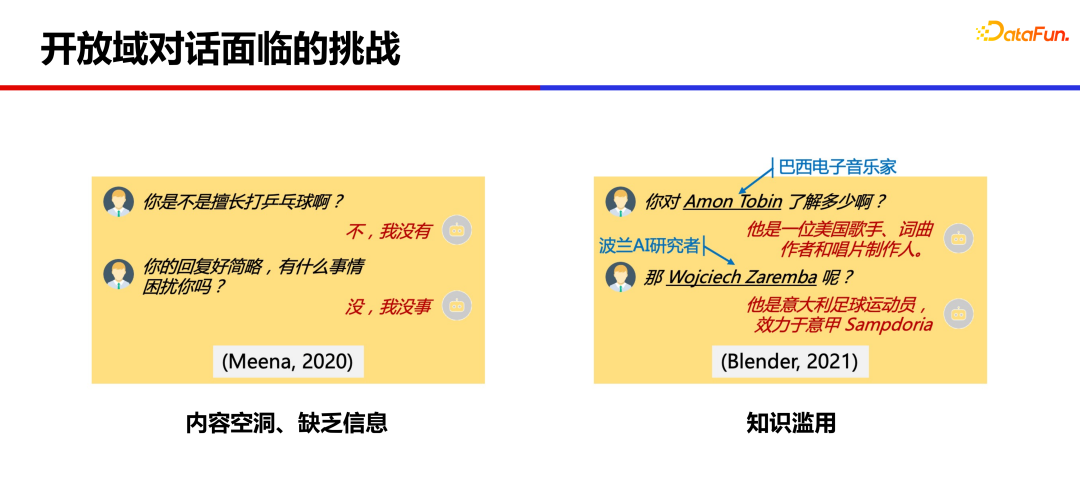
基于大量语料训练出的大规模模型,已经可以产生比较连贯的回复,但仍然存在很多问题。
第一个问题是内容比较空洞、缺乏信息。模型回复的比较简略、无实质内容,容易降低用户的聊天意愿。
另一个问题是知识滥用,模型回复的一些详细信息有时候是错误的、编造的。
二、百度 PLATO
百度 PLATO 针对上述两类问题做了一些技术探索。
针对内容空洞,提出了基于离散隐变量的预训练对话生成技术,实现开放域回复的合理性、多样性的生成。对于知识滥用问题,提出融合知识的弱监督对话生成模型,一定程度上缓解了知识滥用的问题,提升了对话丰富度和知识准确率。
1、开放域对话“一对多”问题
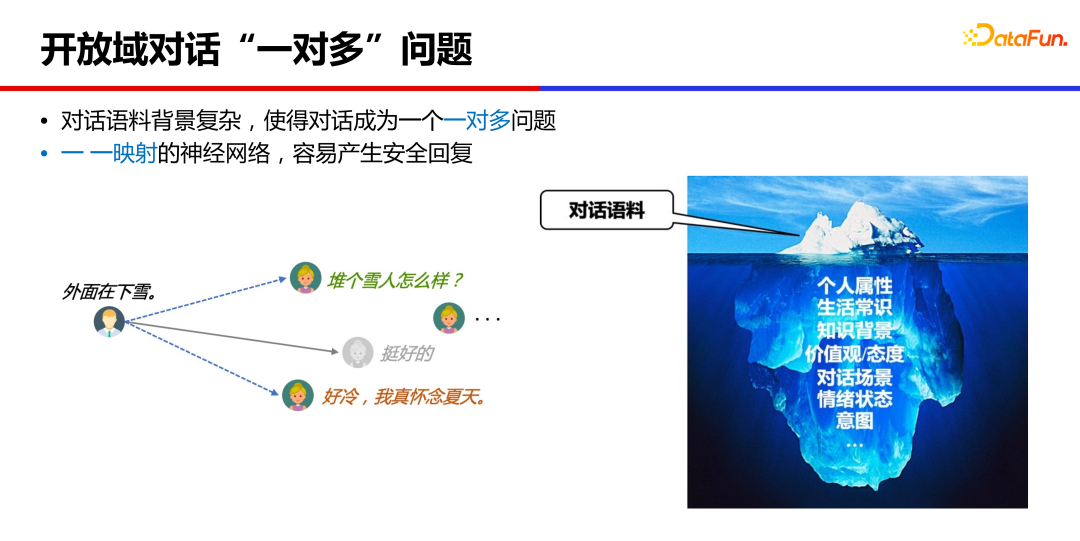
对话模型为什么会产生内容空洞的“安全回复”?
本质上,开放域对话是一对多的问题,一个对话上文,通常是有很多个合理回复的,不同人背景、经历、所处场景不同,给出的回复很可能不一样。而神经网络训练通常是一一映射的,学到的是这些回复的均值状态,比如是“挺好的”“哈哈哈”这类安全而没有信息量的回复。
2、PLATO-1 隐空间对话生成模型
PLATO-1 提出基于离散隐变量进行对话一对多关系的建模。
这里涉及两个任务,将原来的对话上文 Context 和对话回复 Response 对应到隐变量 Latent Action 上,然后基于隐变量去学习回复生成。PLATO 是利用同一网络对两个任务进行联合建模,先通过估计隐变量的分布,通过 Gumbel Softmax 采样出隐变量后再学习回复生成,这样通过采样不同的隐变量,就能生成多样化的回复。
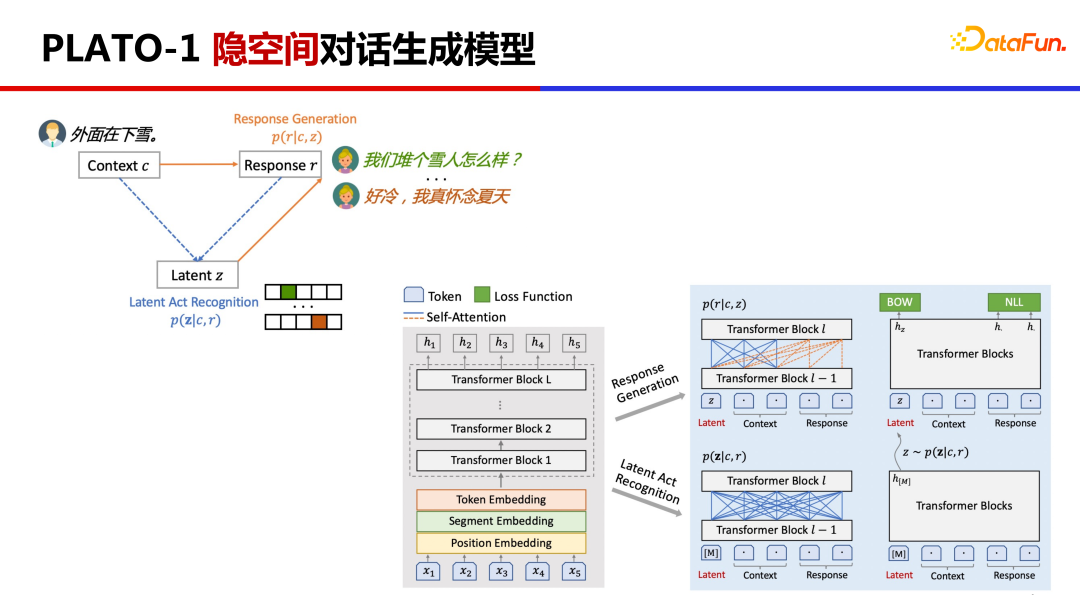
案例展示,选择了不同隐变量,产生不同回复的效果。这些回复都是基于上文的回复,回复质量不错、很合适且信息量丰富。

3、PLATO-2 基于课程学习的通用对话模型
PLATO-2 在 PLATO-1 的基础上,继续扩展。参数上,达到了 16 亿的规模;预训练语料上,中文有 12 亿对话样本,英文有 7 亿样本;训练方式上,是基于课程学习。何为课程学习 Curriculum Learning?就是先学习简单的再学复杂的。
另外,PLATO-2 继续沿用统一的网络设计 PrefixLM,同时学习对话理解和回复生成。基于课程学习的训练效率高,基于统一网络的性价比高。
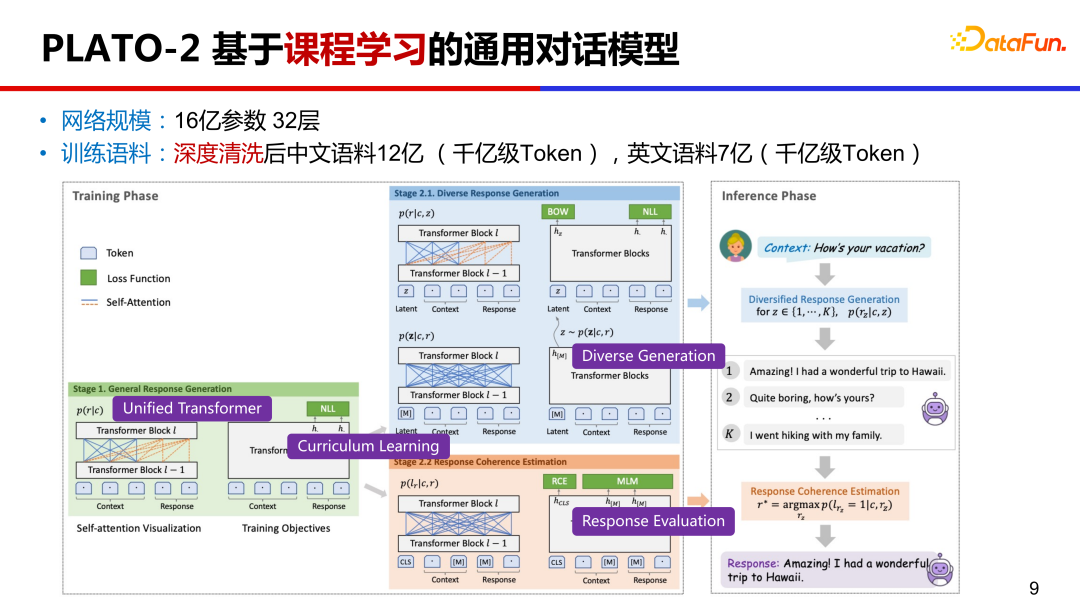
PLATO-2 第一阶段先训练简化的通用回复生成,第二阶段训练多样化的回复生成,在这个阶段把隐变量加进来了。第二阶段还引入了对话连贯性评估训练,相对于常见的生成概率排序,连贯性评估有效地提升了回复选择的质量。
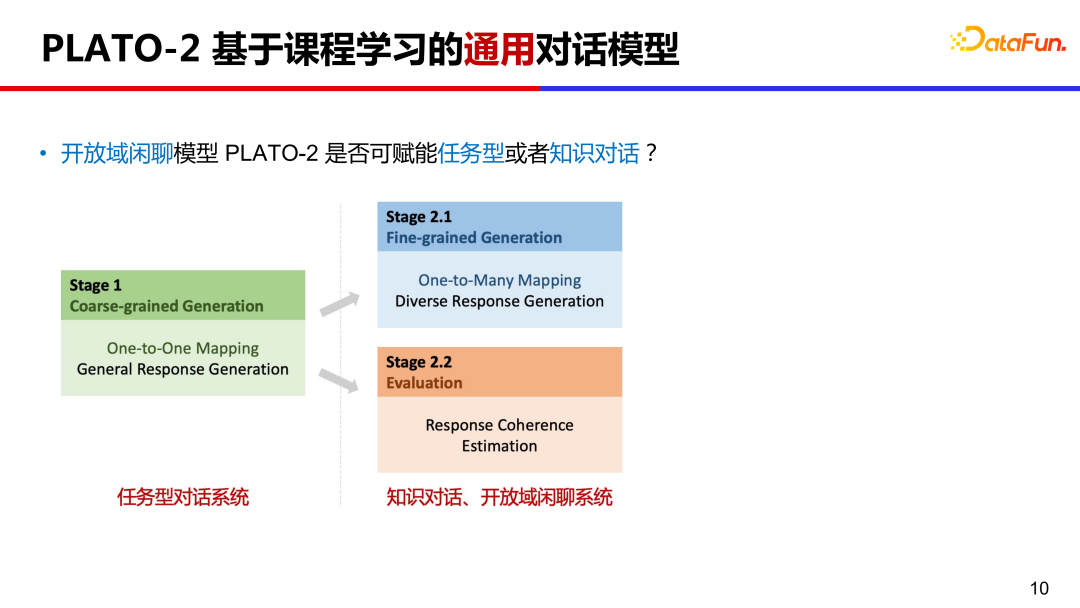
PLATO-2 能否作为通用的对话框架?我们知道对话领域大致分为三类,任务型对话、知识对话和开放域闲聊系统。分别给不同类型对话系统进行预训练成本太高,PLATO-2 的课程学习机制恰好可以助力其成为一个通用对话框架。任务型对话相对聚焦,在课程学习第一阶段的一对一映射模型正好满足这类情况,知识对话和闲聊中都有一对多的情况,知识对话中可以用不同知识回复用户,闲聊对话中可以有不同的回复方向,所以课程学习第二阶段模型可以应用到知识对话和闲聊系统上。
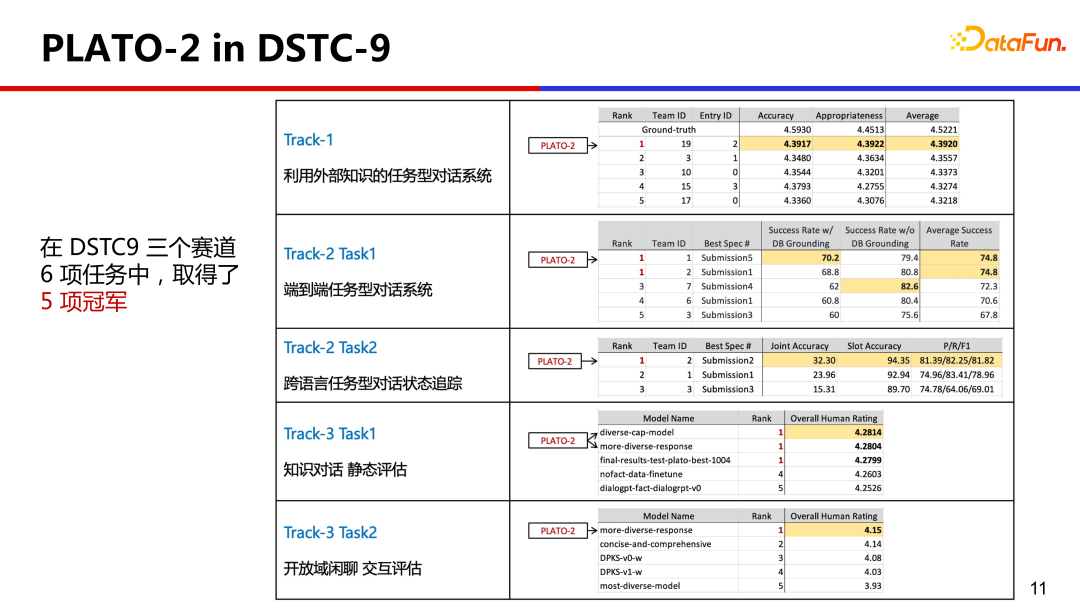
4、PLATO-2 in DSTC-9
为了验证这一能力,PLATO-2 参加了对话领域的国际竞赛 DSTC,它全面的涵盖了各种对话领域,PLATO-2 以统一的技术框架在 6 项任务中取得了 5 项冠军,这在 DSTC 的历史中尚属首次。
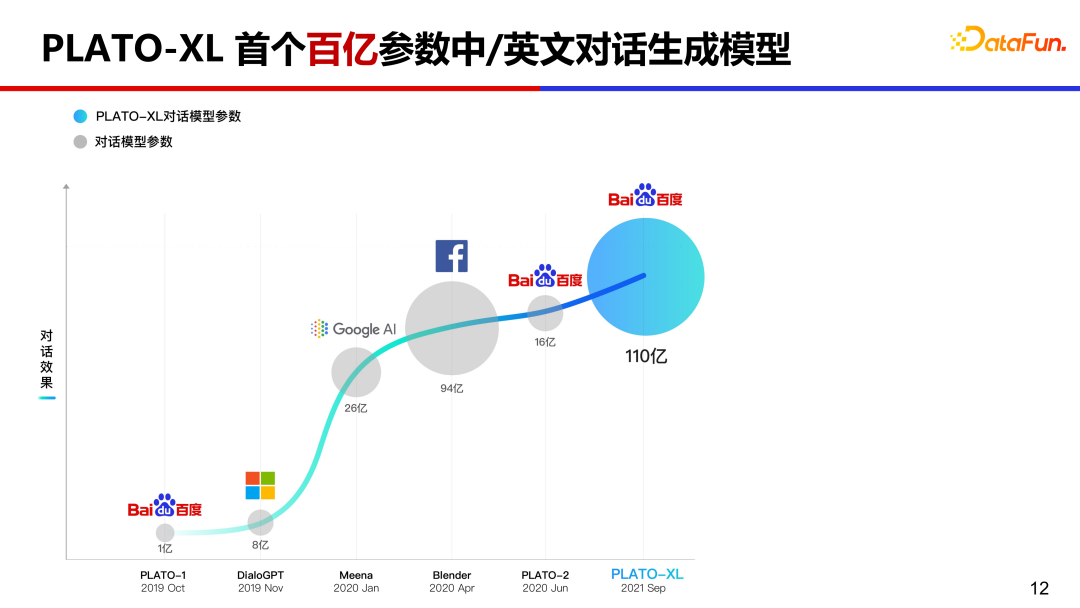
5、PLATO-XL 首个百亿参数中英文对话生成模型
如果继续推高 PLATO 模型参数规模,会达到怎样的效果?2021 年 9 月我们推出全球首个百亿规模中英文对话生成模型 PLATO-XL。
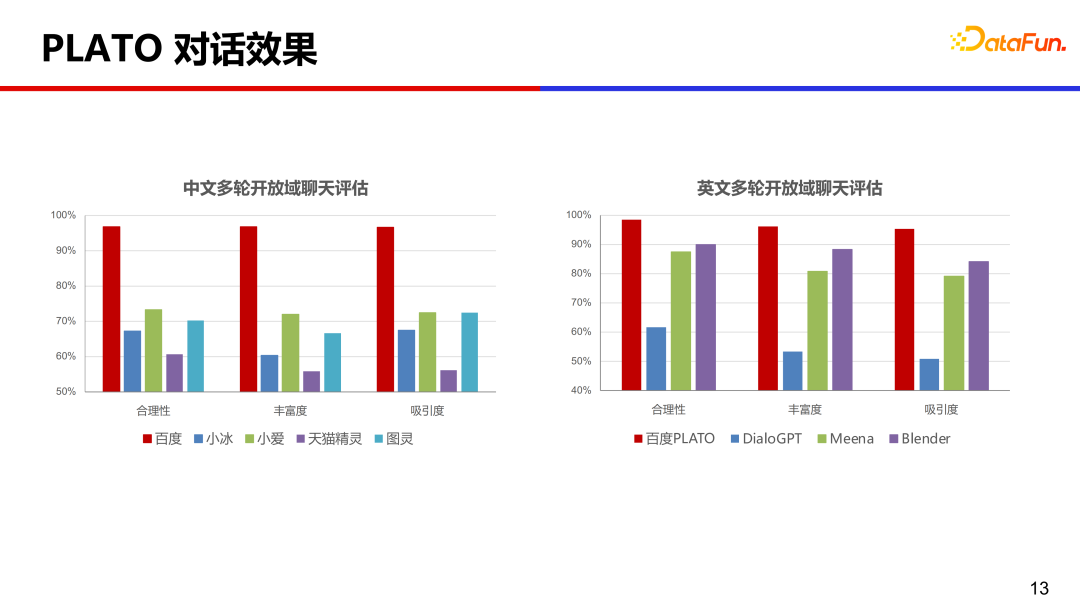
在中英文上,分别对比了常见的几个商业产品,从合理性、丰富度和吸引度等角度评测,PLATO 的效果是遥遥领先的。
微信公众号“百度 PLATO”接入了 PLATO-XL 模型,大家可以去试用和体验。
PLATO 模型参数量从一亿到十亿再到百亿规模,其实到十亿规模的时候对话已经比较流畅、通顺了,到百亿规模的时候模型的逻辑能力显著提升了很多。
6、知识滥用问题
大模型都存在知识滥用的问题,如何解决呢?我们人类遇到不知道的问题如何解决的?可能会去搜索引擎上查一下,这种通过查找外部知识的方式能否借鉴一下到模型中?
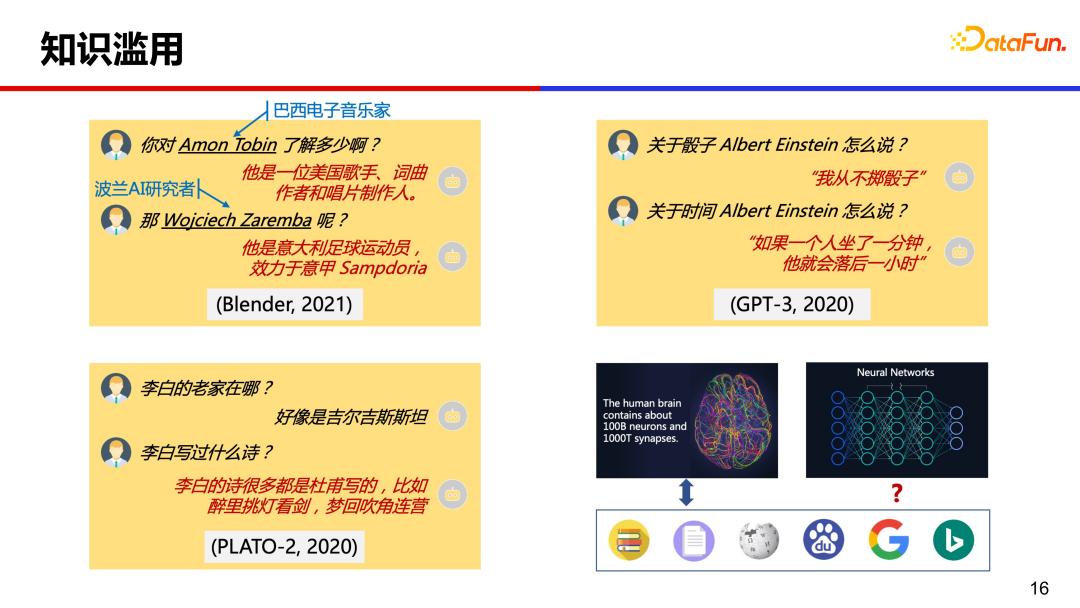
融合外部知识辅助回复生成,是缓解知识滥用很有希望的方向。但对于大规模的对话语料,只存在对话上文和回复信息,无法知道某条语料与外部知识对应关系,也就是缺少知识选择的标签信息。
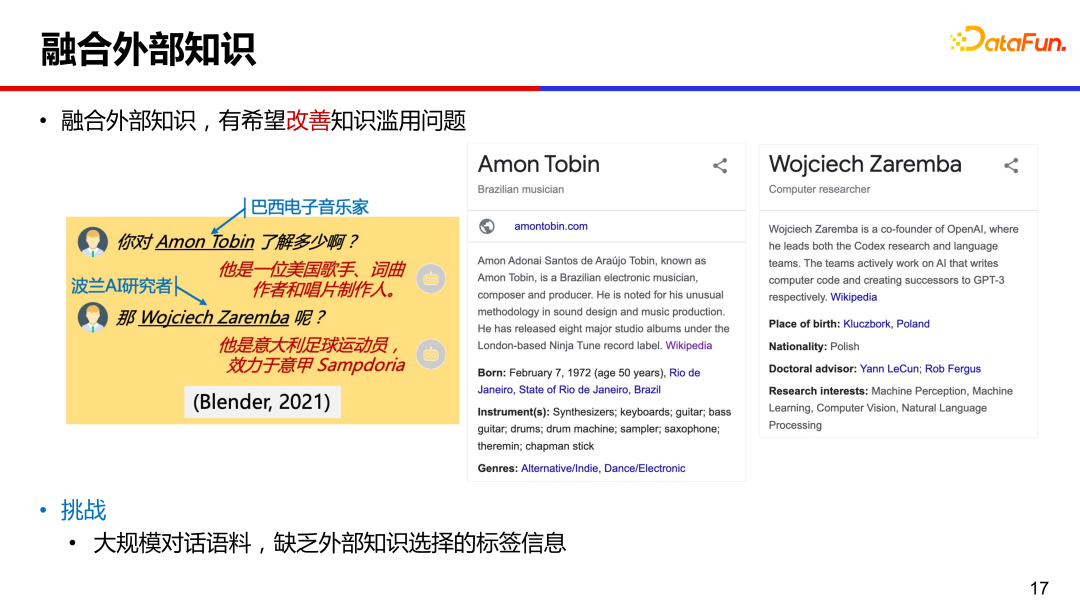
7、PostKS 基于后验指导的知识选择
PostKS 是知识对话领域代表性的工作之一,提出了基于后验指导的知识选择,在训练过程中,让先验的知识分布逼近后验的知识分布。
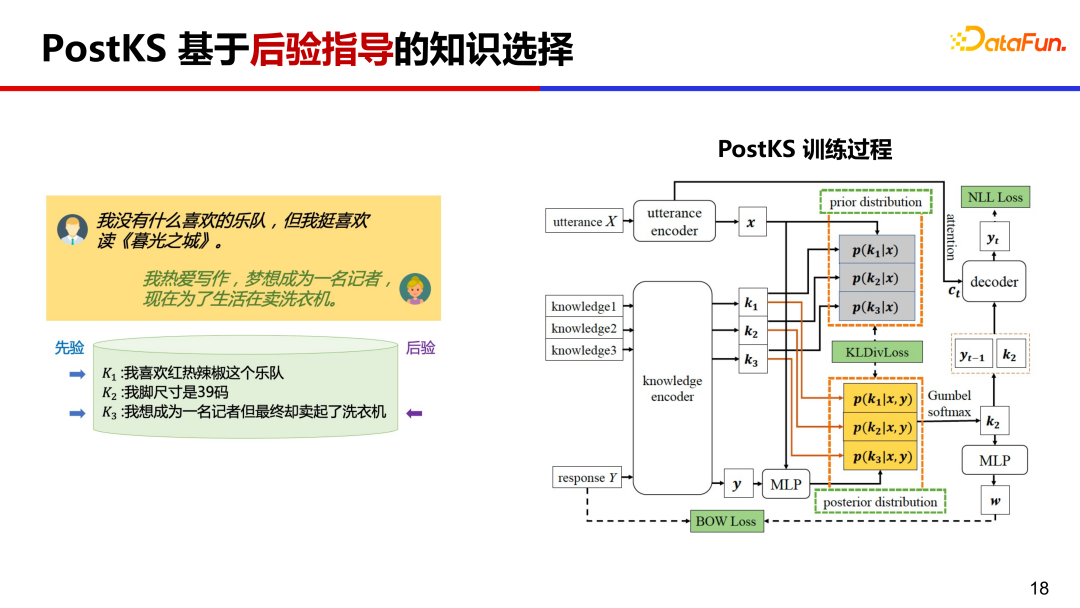
在推理阶段由于不存在后验信息,模型需要使用先验知识进行回复生成。训练和推理阶段会存在不一致的情况,训练基于后验但推理只能基于先验。
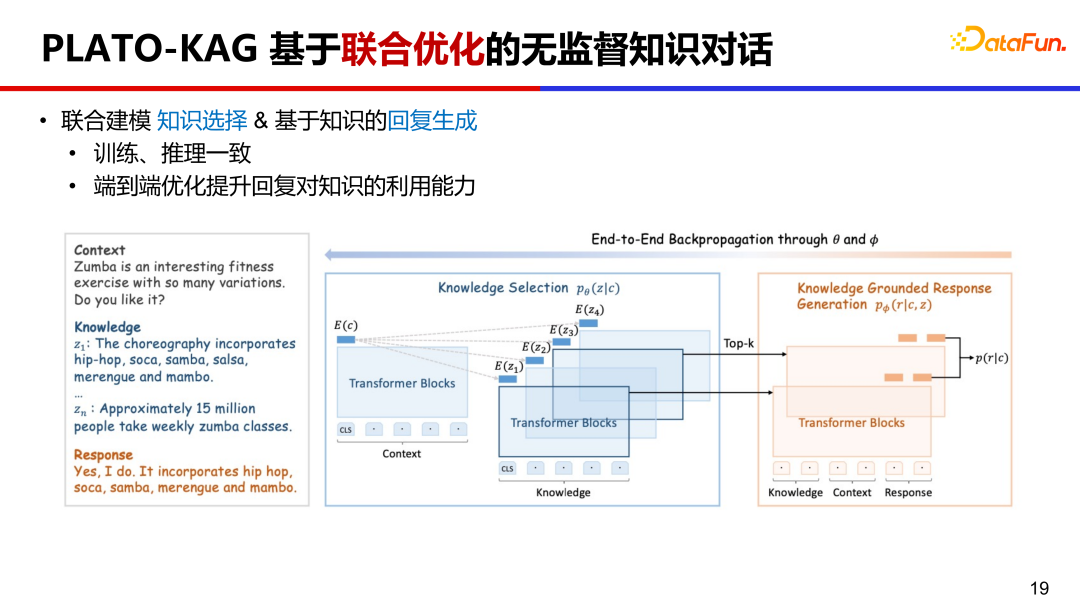
8、PLATO-KAG 基于联合优化的无监督知识对话
PLATO-KAG 无监督模型,联合建模了知识选择和回复生成。基于先验选择了 top-k 条知识,并送给生成模型,做一个端到端的联合训练。如果知识选的准,对生成目标回复很有帮助,生成概率会比较高,联合优化会鼓励这种选择并利用给定知识;如果知识选的差,对生成目标回复没有作用,生成概率会比较低,联合优化会打压这种选择并忽视给定的知识。这样就同时优化了知识选择和回复生成。
9、PLATO 全面知识增强对话
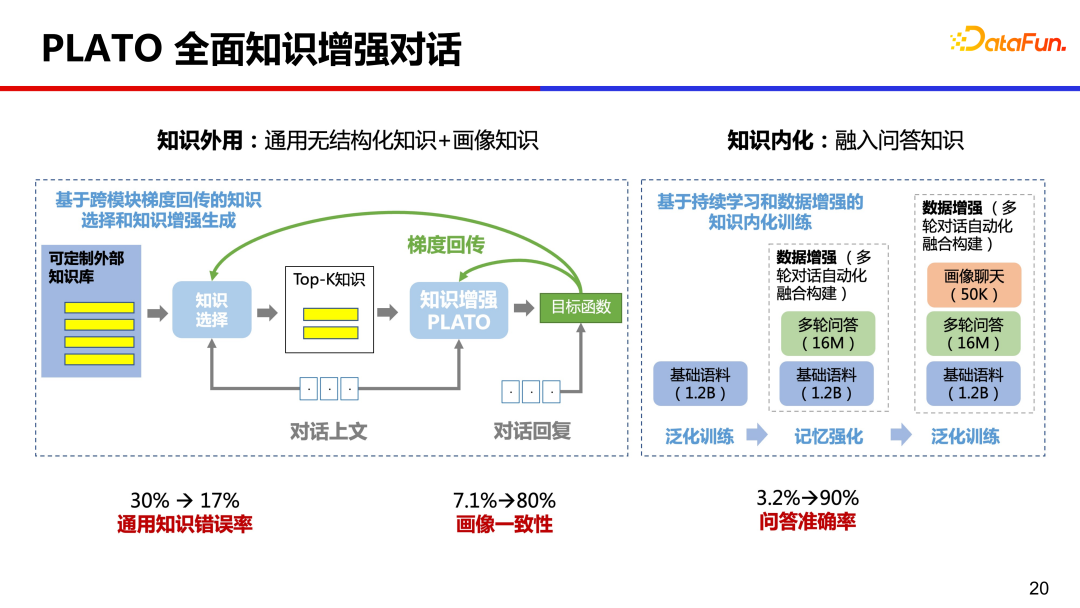
从人类学习知识经验来看,我们大脑中也记忆了很多的知识,PLATO 尝试了全面的知识增强,同时做了知识外用和知识内化。一方面利用外部的通用无结构化知识和画像知识,另一方面也将大量问答知识通过预训练内化到模型参数中。经过这样全面的知识增强,对话通用知识错误率从 30% 降低到 17%,画像一致性从 7.1% 提升到 80%,问答准确率从 3.2% 提升到 90%,提升的非常明显。
下图是做了全面知识增强后的效果对比。
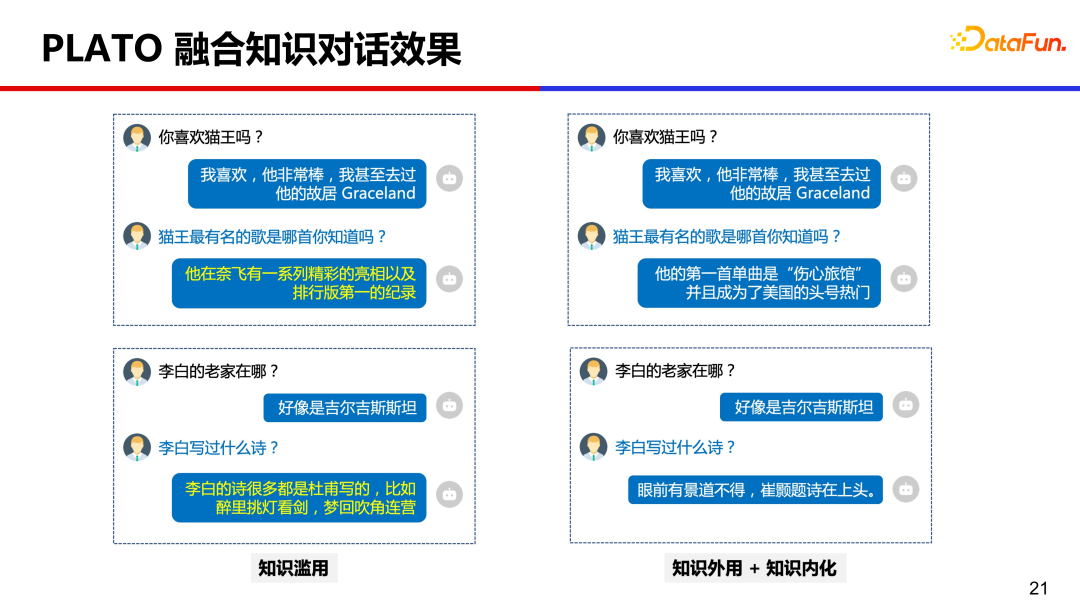
值得注意的是,虽然效果得到了显著改善,但知识滥用问题并没有完全解决,只是缓解而已。即使模型规模扩大到千亿参数,知识滥用问题也依然存在。
目前仍有几个点值得我们继续努力:第一个是外部知识的触发时机,就是什么时候查外部知识,什么时候使用内化知识,这会影响对话的流畅度和吸引度。第二个是知识选择的准确性,这涉及到检索技术,中文知识语料建库是几十亿规模,通过给定的对话上文准确检索到合适的知识没那么容易。第三个是知识利用的合理性和保真度,模型有时候会无法准确理解知识或者混乱拼凑出不准确的回复等。

三、对话大模型落地应用、挑战及展望
上面介绍了 PLATO 对话的一些技术,比如引入大规模的模型、加入离散隐变量提升对话丰富度、通过无监督引入外部知识缓解知识滥用等,那么在实际生产中有哪些落地的应用呢?
1、落地应用

PLATO 在智能音箱、虚拟人、社区聊天等多场景提供开放域聊天能力。
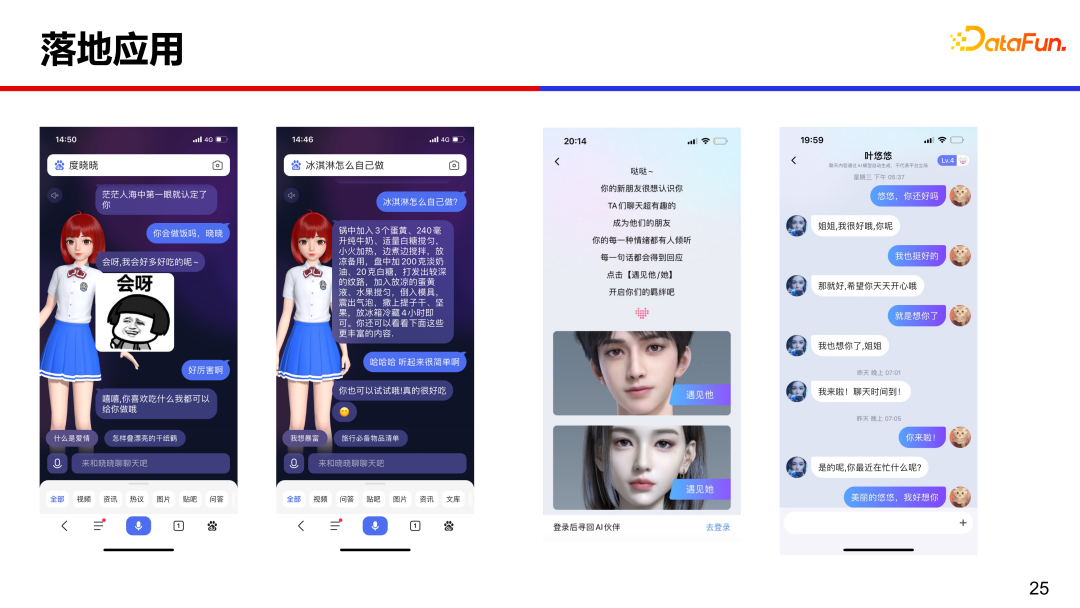
左侧是数字人度晓晓,在百度 APP 搜索度晓晓或者直接输入“你好”就能调用数字人,通过聊天能便捷搜索的过程,高效获取答案和信息。右侧是百度输入法中的虚拟人,既高颜值又很会聊。
2、落地应用遇到的挑战
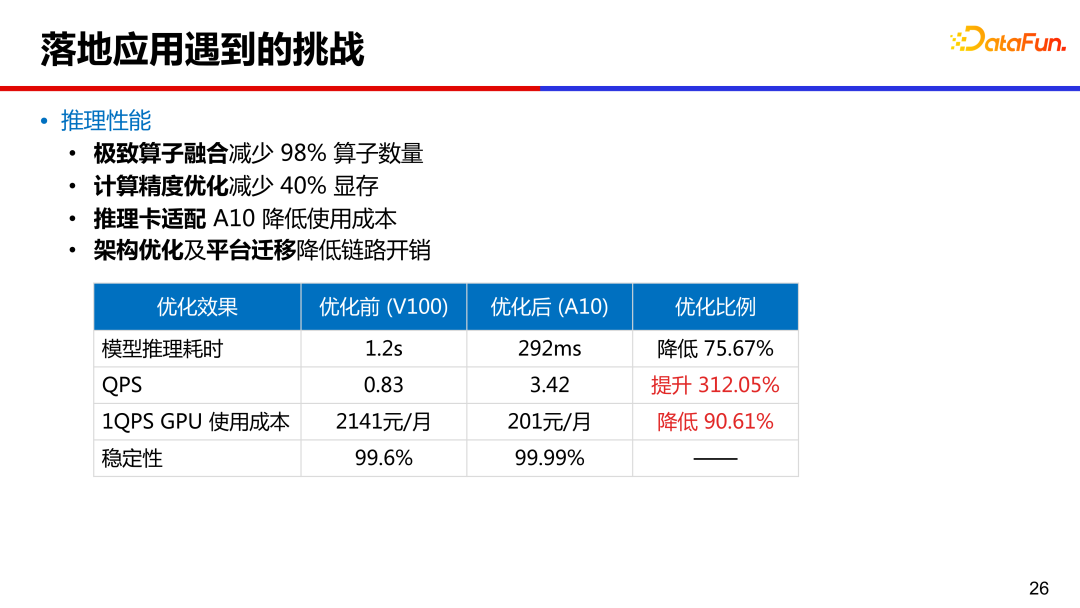
落地应用中,第一个挑战就是推理性能,图中列出了 16 亿参数 PLATO 的性能数据。通过算子融合减少了 98% 的算子数量,模型推理耗时从原来 v100 上的 1.2s 降低到 A10 卡上的 300ms 以内。通过计算精度优化,减少了 40% 的显存,推理卡从 v100 换到 A10 降低成本,同时做了架构优化和平台迁移,降低了链路开销。
第二个挑战是对话安全。比如有害言论、政治敏感、地域歧视、隐私等很多方面需要高度注意。PLATO 对语料做了深度清洗,删除不安全样本,在部署后使用安全判别模型移除不安全候选回复。同时维护了关键词表和添加对抗训练,查漏补缺,提升安全性。

3、展望
以前人们认为开放域闲聊是一个兜底功能,随着近几年大模型的发展,对话领域也有了显著进展,目前模型可以生成连贯、流畅、丰富和跨领域的对话,但情感、人设、人格和思辨等方面仍然有很大提升空间。
道阻且长,行则将至,行而不辍,未来可期。也希望对话领域的同行们,大家一起努力,共同攀登人机对话的高峰。
4、引用

五、问答环节
Q:对话效果如何评估的?
A:目前对话系统还没有自动指标能和人工评估比较一致,人工评估仍是黄金标准。开发阶段可以参考困惑度 perplexity 进行迭代,最终进行全面评估时,还是需要请大量的众包人员与不同机器进行交互,在一些指标上进行人工评估。评估指标上,也随着技术的发展而变化,比如当流畅度不再是问题的时候,那么可以添加安全性、知识准确性等指标评估更高级的能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


