学习ChatGPT,AI绘画引入人类反馈会怎样?
最近,深度生成模型在根据文本 prompt 生成高质量图像方面取得了显著成功,部分原因在于深度生成模型扩展到了大规模网络数据集(如 LAION)。但是,一些重大挑战依然存在,因而大规模文本到图像模型无法生成与文本 prompt 完全对齐的图像。举例而言,当前的文本到图像模型往往无法生成可靠的视觉文本,并在组合式图像生成方面存在困难。
回到语言建模领域,从人类反馈中学习已经成为一种用来「对齐模型行为与人类意图」的强大解决方案。这类方法通过人类对模型输出的反馈,首先学习一个旨在反映人类在任务中所关心内容的奖励函数,然后通过一种强化学习算法(如近端策略优化 PPO)使用学得的奖励函数来优化语言模型。这种带有人类反馈框架的强化学习(RLHF)已经成功地将大规模语言模型(例如 GPT-3)与复杂的人类质量评估结合起来。
近日,受 RLHF 在语言领域的成功,谷歌研究院和加州伯克利的研究者提出了使用人类反馈来对齐文本到图像模型的微调方法。

论文地址:https://arxiv.org/pdf/2302.12192v1.pdf
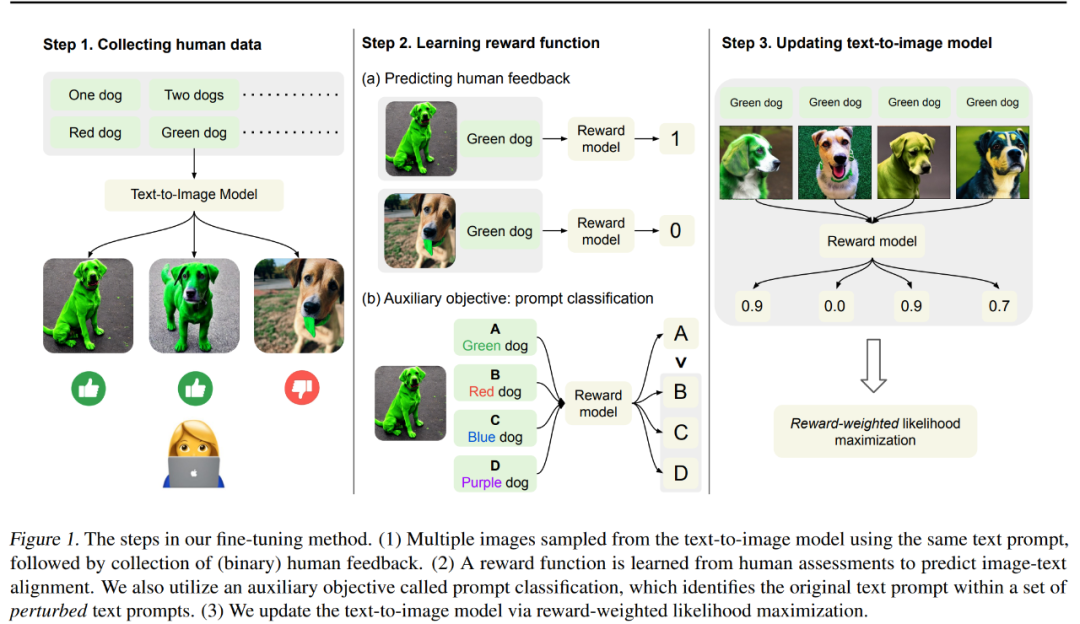
本文方法如下图 1 所示,主要分为 3 个步骤。
第一步:首先从「设计用来测试文本到图像模型输出对齐的」一组文本 prompt 中生成不同的图像。具体地,检查预训练模型更容易出错的 prompt—— 生成具有特定颜色、数量和背景的对象,然后收集用于评估模型输出的二元人类反馈。
第二步:使用了人工标记的数据集,训练一个奖励函数来预测给定图像和文本 prompt 的人类反馈。研究者提出了一项辅助任务,在一组扰动文本 prompt 中识别原始文本 prompt,以更有效地将人类反馈用于奖励学习。这一技术改进了奖励函数对未见过图像和文本 prompt 的泛化表现。
第三步:通过奖励加权似然最大化更新文本到图像模型,以更好地使它与人类反馈保持一致。与之前使用强化学习进行优化的工作不同,研究者使用半监督学习来更新模型,以测量模型输出质量即学得的奖励函数。
研究者使用带有人类反馈的 27000 个图像 – 文本对来微调 Stable Diffusion 模型,结果显示微调后的模型在生成具有特定颜色、数量和背景的对象方面实现显著提升。图像 – 文本对齐方面实现了高达 47% 的改进,但图像保真度略有下降。
此外,组合式生成结果也得到了改进,即在给定未见过颜色、数量和背景 prompt 组合时可以更好地生成未见过的对象。他们还观察到,学得的奖励函数比测试文本 prompt 上的 CLIP 分数更符合人类对对齐的评估。
不过,论文一作 Kimin Lee 也表示,本文的结果并没有解决现有文本到图像模型中所有的失效模型,仍存在诸多挑战。他们希望这项工作能够突出从人类反馈中学习在对齐文生图模型中的应用潜力。

方法介绍
为了将生成图像与文本 prompt 对齐,该研究对预训练模型进行了一系列微调,过程如上图 1 所示。首先从一组文本 prompt 中生成相应的图像,这一过程旨在测试文生图模型的各种性能;然后是人类评分员对这些生成的图像提供二进制反馈;接下来,该研究训练了一个奖励模型来预测以文本 prompt 和图像作为输入的人类反馈;最后,该研究使用奖励加权对数似然对文生图模型进行微调,以改善文本 – 图像对齐。
人类数据收集
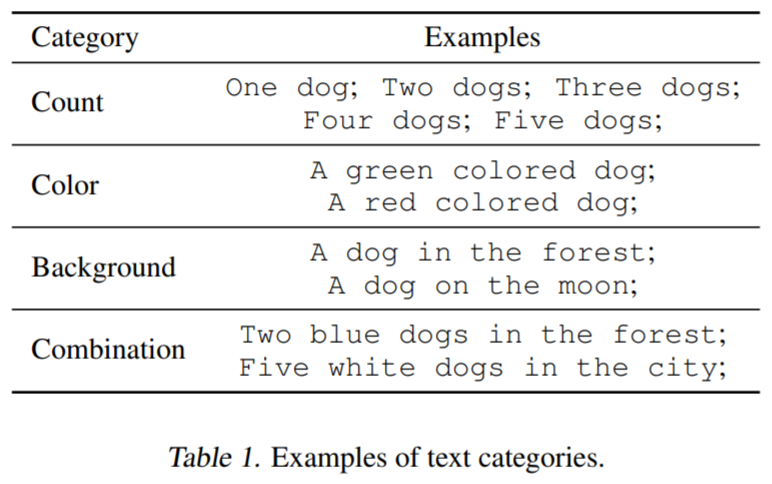
为了测试文生图模型的功能,该研究考虑了三类文本 prompt:指定数量(specified count)、颜色、背景。对于每个类别,该研究对每个描述该物体的单词或短语两两进行组合来生成 prompt,例如将绿色(颜色)与一只狗(数量)组合。此外,该研究还考虑了三个类别的组合(例如,在一个城市中两只染着绿颜色的狗)。下表 1 更好的阐述了数据集分类。每一个 prompt 会被用来生成 60 张图像,模型主要为 Stable Diffusion v1.5 。
人类反馈
接下来对生成的图像进行人类反馈。由同一个 prompt 生成的 3 张图像会被呈递给打标签人员,并要求他们评估生成的每幅图像是否与 prompt 保持一致,评价标准为 good 或 bad。由于这项任务比较简单,用二元反馈就可以了。
奖励学习
为了更好的评价图像 – 文本对齐,该研究使用奖励函数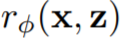 来衡量,该函数可以将图像 x 的 CLIP 嵌入和文本 prompt z 映射到标量值。之后其被用来预测人类反馈 k_y ∈ {0, 1} (1 = good, 0 = bad) 。
来衡量,该函数可以将图像 x 的 CLIP 嵌入和文本 prompt z 映射到标量值。之后其被用来预测人类反馈 k_y ∈ {0, 1} (1 = good, 0 = bad) 。
从形式上来讲,就是给定人类反馈数据集 D^human = {(x, z, y)},奖励函数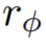 通过最小化均方误差 (MSE) 来训练:
通过最小化均方误差 (MSE) 来训练:

此前,已经有研究表明数据增强方法可以显着提高数据效率和模型学习性能,为了有效地利用反馈数据集,该研究设计了一个简单的数据增强方案和奖励学习的辅助损失(auxiliary loss)。该研究在辅助任务中使用增强 prompt,即对原始 prompt 进行分类奖励学习。Prompt 分类器使用奖励函数,如下所示:
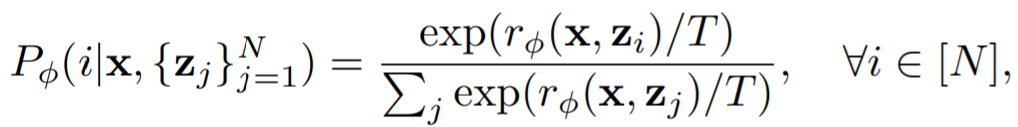
辅助损失为:
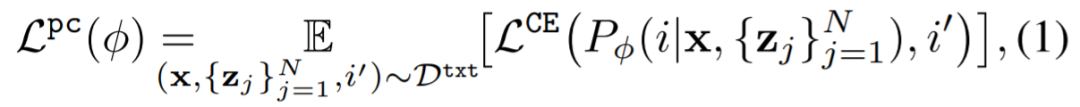
最后是更新文生图模型。由于模型生成的数据集多样性是有限的,可能导致过拟合。为了缓解这一点,该研究还最小化了预训练损失,如下所示:
实验结果
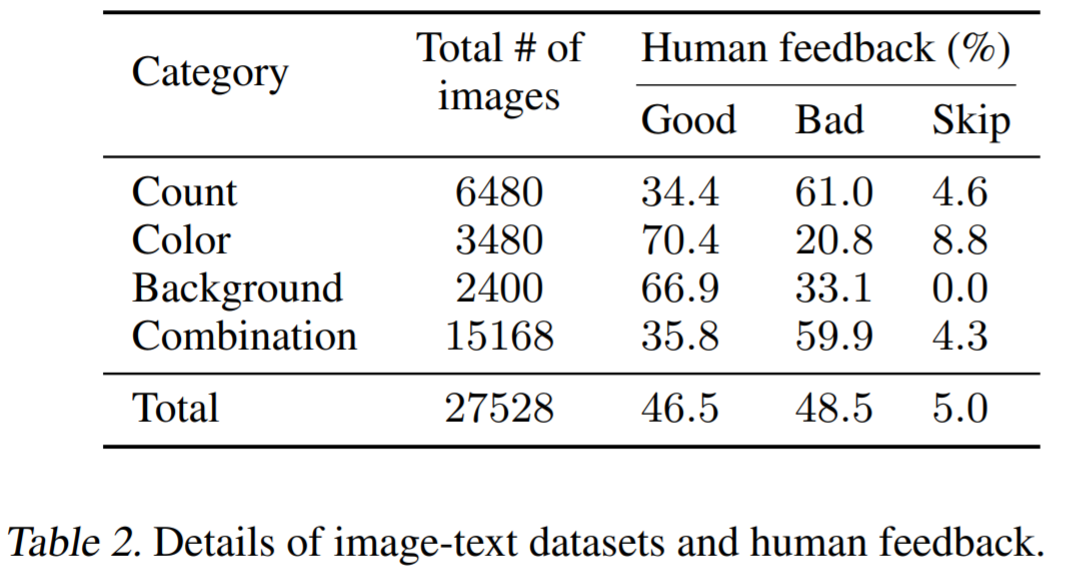
实验部分旨在测试人类反馈参与模型微调的有效性。实验用到的模型为 Stable Diffusion v1.5 ;数据集信息如表 1(参见上文)和表 2 所示,表 2 显示了由多个人类标签者提供的反馈分布。
人类对文本 – 图像对齐的评分(评估指标为颜色、物体数量)。如图 4 所示,本文方法显著提高了图像 – 文本对齐,具体来说,模型生成的图像中有 50% 的样本获得至少三分之二的赞成票(投票数量为 7 票或更多赞成票),然而,微调会稍微降低图像保真度(15% 比 10%)。
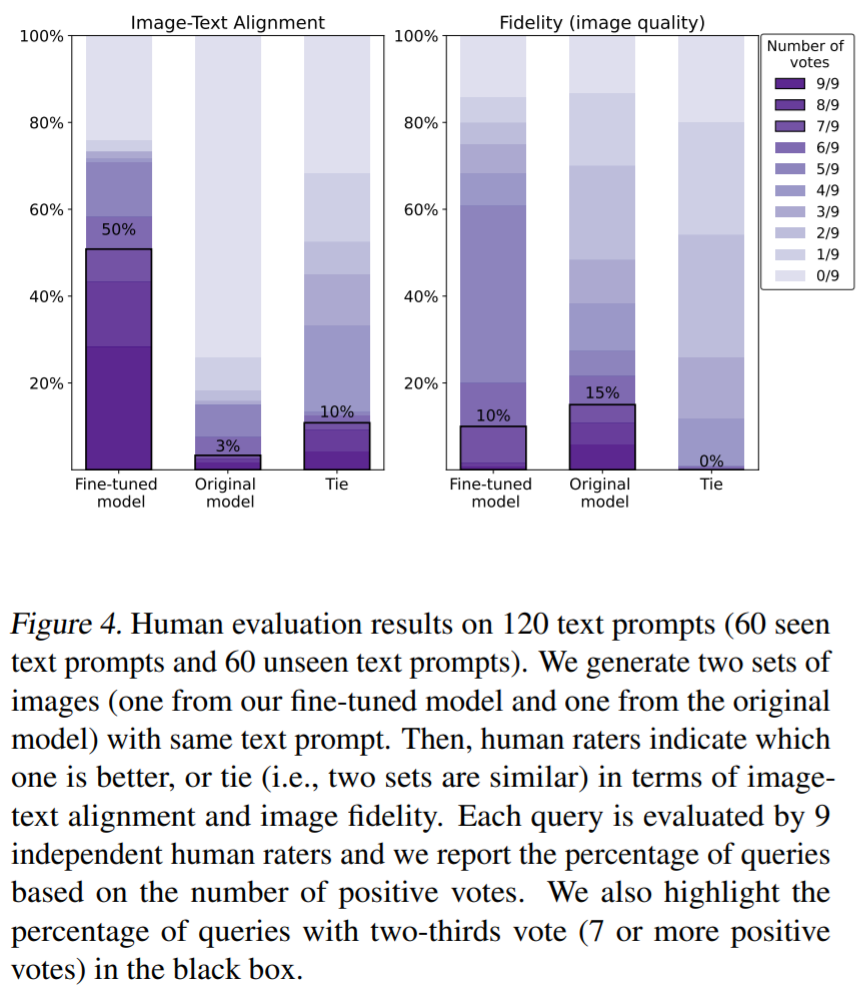
图 2 显示了来自原始模型和本文经过微调的对应模型的图像示例。可以看到原始模型生成了缺少细节(例如,颜色、背景或计数)的图像(图 2 (a)),本文模型生成的图像符合 prompt 指定的颜色、计数和背景。值得注意的是,本文模型还能生成没有见过的文本 prompt 图像,并且质量非常高(图 2 (b))。

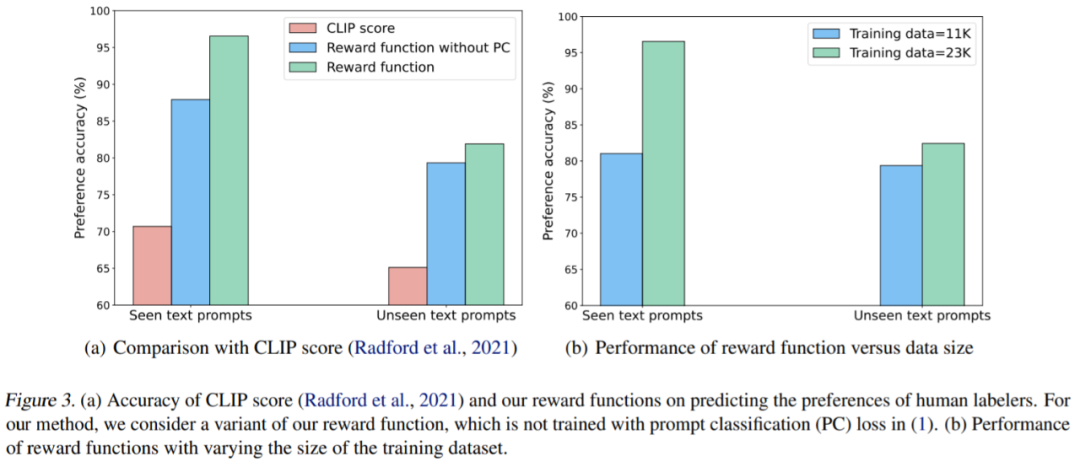
奖励学习的结果。图 3 (a) 为模型在见过的文本 prompt 和未见文本 prompt 中的评分。有奖励(绿色)比 CLIP 分数(红色)更符合典型的人类意图。
© 版权声明
文章版权归作者所有,未经允许请勿转载。