
打架识别,基于循环神经网络RNN的视频分类任务
哈喽,大家好。
今天给大家分享AI项目——打架识别。

使用的技术跟我们上次分享的摔倒识别不同,摔倒识别使用的是基于骨骼点的时空卷积神经网络,适用于人体骨骼行为,而这次分享的打架识别使用的是循环神经网络RNN,可以实现更通用的视频分类任务。
当然也可以用Vision Transformer,文中也有介绍。
代码已经打包好了,获取方式见评论区。
1. 整体思路
视频其实就是某种行为的连续序列,因此要使用序列模型处理,循环神经网络RNN就是序列模型。
RNN最初应用在自然语言处理中,如:根据输入词,判断下一次词的概率
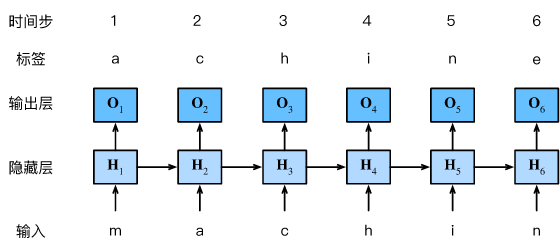
模型为了读懂每个词代表的含义,模型会把每个词用n维向量表示,这个过程 其实就是word embedding。
按照这个思路,一段视频其实就是一句话,视频里每张画面就是一个词,同样地,我们也可以用卷机神经网络将每张图映射成n维向量。
所以,我们就可以训练一个RNN模型,将表示视频的n维向量送入RNN模型,让他输出视频类别的概率。
现在比较流行的RNN模型有LSTM、GRU,本文使用的是GRU。
2. 数据集
打架的开源数据集有很多,如:fight-detection-surv-dataset、A-Dataset-for-Automatic-Violence-Detection-in-Videos和UBI_FIGHTS等等。
我使用的是fight-detection-surv-dataset数据集,包括 150 个打架视频和 150 个正常视频。
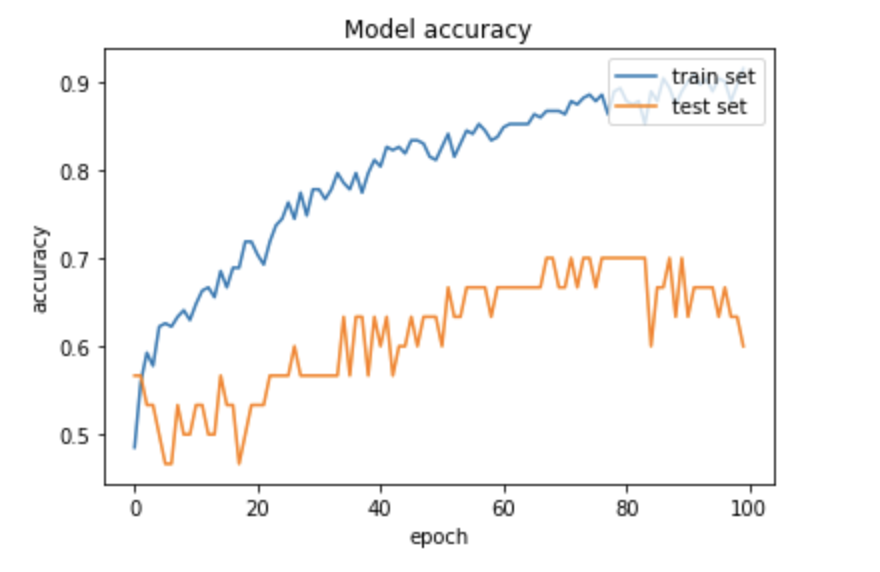
数据集很小,训练的时候很容易过拟合,精度只有 70%。但思路和代码都是可以复用的。
大家做的时候可以换成大的数据集,比如:ucf数据,包含很多动作视频

ucf50数据集
我用这个数据集训练过 GRU 和 Transformer模型,效果还可以。
3. 提取视频特征
接下来,我们要做的就是提取视频特征,将视频中每张画面映射成n维向量。
使用InceptionResNetV2网络,输入一张图片,输出的是 1536 维向量。
def video_feat_extractor():
inception_resnetv2 = InceptionResNetV2(
include_top=False,
weights='imagenet',
pooling='avg',
input_shape=(IMAGE_SIZE, IMAGE_SIZE, 3))
inputs = tf.keras.Input(shape=(IMAGE_SIZE, IMAGE_SIZE, 3))
inputs_preprocessed = preprocess_input(inputs)
outputs = inception_resnetv2(inputs_preprocessed)
return tf.keras.Model(inputs, outputs, name='video_feat_extractor')
这样,词向量就已经有了。然后再抽取每个视频的前20帧,组成一个句子。
MAX_FRAMES = 20
video_feat_extractor_model = video_feat_extractor()
# 取前MAX_FRAMES帧
frames = frames[:MAX_FRAMES]
# 计算视频特征
video_feat = video_feat_extractor_model(frames)
dataset_feats.append(video_feat)
dataset_feats是20 * 1536的向量。
这样,我们就将一个视频用向量形式表示出来了。
4. 循环神经网络
GRU是LSTM的一个变种
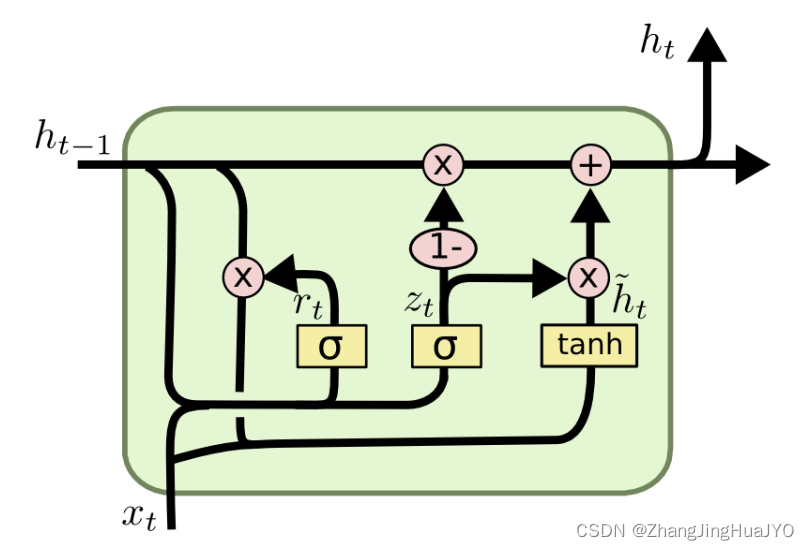
模型搭建也比较简单。
model = keras.Sequential([
layers.InputLayer(input_shape=(MAX_FRAMES, FRAME_FEAT_LEN)),
layers.GRU(4, return_sequences=False),
layers.Dropout(0.1),
layers.Dense(class_num, activatinotallow='softmax')
])
GRU超参数 4 代表 4 个 unit,即:模型输出向量长度是 4,大家如果做其他分类任务,可以尝试调整该值。

编译模型
model.compile(optimizer=optimizers.Adam(0.0001),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
这是个多分类任务,因此损失函数使用sparse_categorical_crossentropy。
接着就可以训练模型了,模型在训练集和测试集精度如下:
5. vision transformer
同样的,我们也可以用流行的Transformer来训练视频分类模型
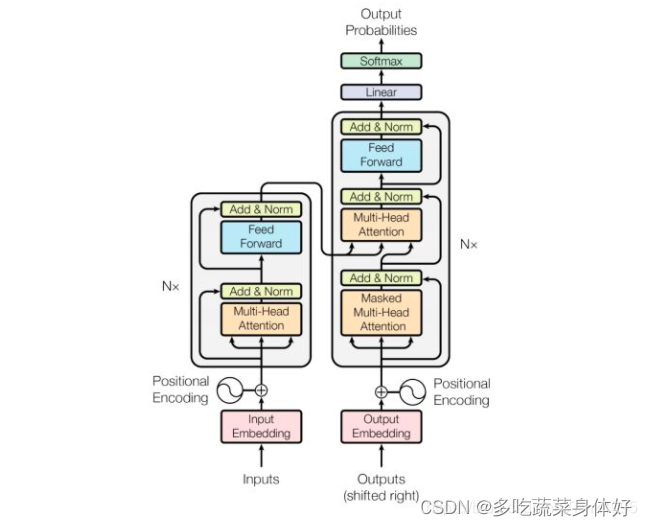
对于视频分类任务,不需要Decoder网络,用多头自注意力模型搭建一个 Encoder网络即可。
关于vision transformer后续有机会的话我会专门分享一个项目,这次代码以GRU为主。

© 版权声明
文章版权归作者所有,未经允许请勿转载。


