
LLaMA模型惨遭泄漏,Meta版ChatGPT被迫「开源」!GitHub斩获8k星,评测大量出炉
ChatGPT角逐之战愈演愈烈。
前几周,Meta发布了自家的大型语言模型LLaMA,参数量从70亿到650亿不等。
论文中,仅用1/10参数的LLaMA(130亿)在大多数基准测试下超越了GPT-3。
对于650亿参数的LLaMA,则与DeepMind的Chinchilla(700亿参数)和谷歌的PaLM(5400亿参数)旗鼓相当。
虽然Meta声称LLaMA是开源的,但还需要研究人员申请并进行审核。
然而万万没想到的是,刚发布没几天,LLaMA的模型文件就提前泄露了。
那么,问题来了,这究竟是故意的还是不小心的
LLaMA惨遭「开源」?
近日,国外论坛4chan上泄露了LLaMA的成品库。

上周四,用户llamanon在4chan的技术板上发帖,通过种子文件(torrent)发布7B和65B的LLaMA模型。

这个种子链接目前被合并到了LLaMA的GitHub页面。
他还向项目提交了第二个拉请求,该请求提供了一个种子链接,链接到模型的另一组权重。
目前该项目在GitHub已收获8k星。
然而,泄密者最大的错误之一就是在泄密的模型中包含了他们的唯一标识符代码。
这个代码是专门用来追踪泄密者的,使用户llamanon的个人信息处于危险之中。
正所谓,LLaMA开源的不太体面,网友帮它体面了。
此外,4chan上的用户还为那些希望在自己的工作站上部署该模型的人创建了一个方便的资源。
并提供了一个分布教程的指南,说明如何获得模型,并将修改后的权重添加到其中,以便进行更有效的推理。
更重要的是,这个资源甚至提供了一种将LLaMA集成到 在线写作平台KoboldAI的方法。

对于这件事究竟是Meta有意为之,还是无意泄漏。网友们纷纷发表了自己的看法。
一位网友分析地头头是道,「也许这是Meta故意泄露的,以对抗 OpenAI。」
一些客户认为这是一个更好的模型,它恰好击中了他们以每年25万美元的价格出售访问权的商业计划的核心。访问他们的服务一个月可以购买一台能够运行这种泄露模型的机器。Meta削弱了一个潜在的新贵竞争对手,以保持当前的大型科技卡特尔稳定。也许这有点阴谋论,但我们生活在大科技和大阴谋的时代。
周一,Meta称,尽管LLaMA已经泄露给未经授权的用户,仍将继续向认可的研究人员发布其人工智能工具。
有网友直接称,自己下载了70亿参数的LLaMA,尽管不知道如何运行,万一以后用上就能拿来了。
LLaMA的泄露和开源是一个大事件:
Stable Diffusion开源了。8个月后,我们现在就可以读懂别人的思想,解码他们看到的一切。
随着LLMs的开放,我们将得到一些真正的疯狂的东西。

模型初步评测
LLaMA发布不久后,网友发现这个最小参数的模型也需要近30GB的GPU才能运行。
然而,通过比特和字节库进行浮点优化,他们能够让模型在单个NVIDIA RTX 3060上运行。
此外,GitHub 上的一名研究人员甚至能够在Ryzen 7900X CPU上运行LLM的7B 版本,每秒能推断出几个单词。
那么LLaMA模型究竟怎样?国外小哥便对它进行了评测。

LLaMA在很多测试中表现出色。
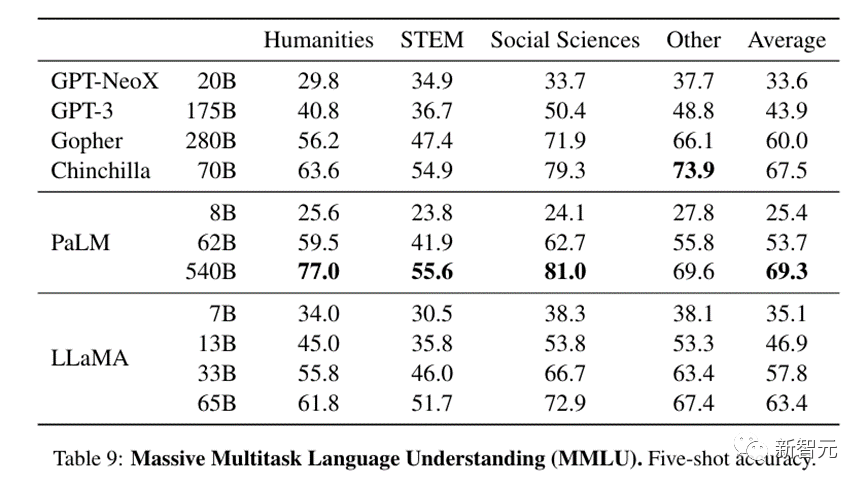
在大规模多任务语言理解方面,即使相对较小的13B模型也与GPT-3水平相当,而GPT-3的规模是其13倍。
33B版本远远优于GPT-3, 65B则可与现有最强大的LLM模型–谷歌的540B参数的PaLM竞争。
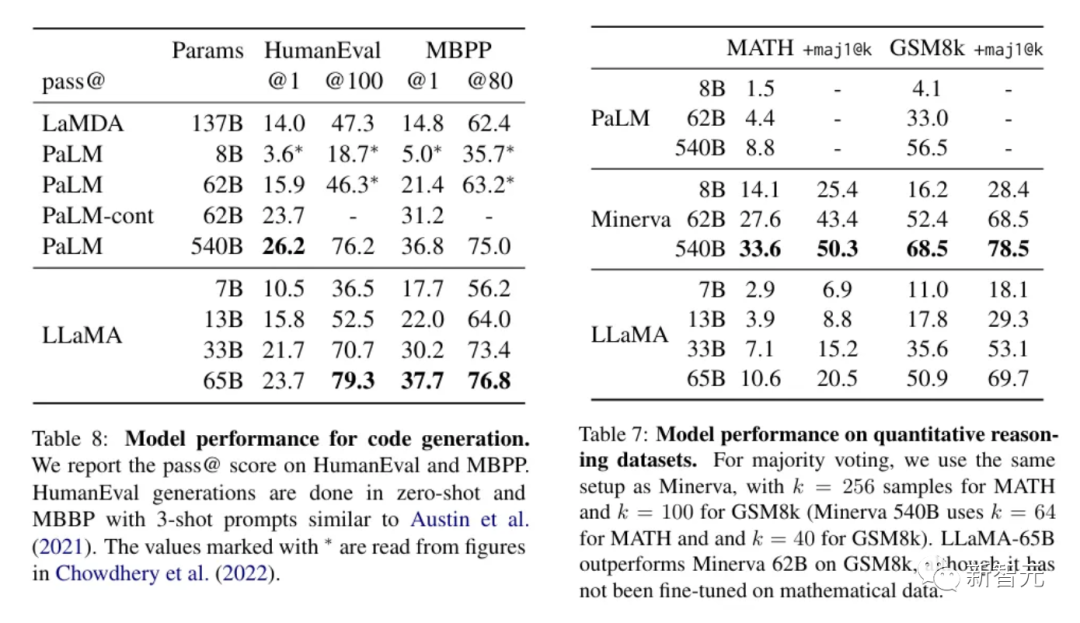
对于需要应用逻辑或计算进行处理的文本方面,LLaMA表现优秀,在定量推理方面可与PaLM相较,甚至比后者的代码生成能力更好。
鉴于这些结果,LLaMA似乎是目前最先进的模型之一,而且,它足够小,不需要多少资源就能运行。这使得LLaMA对于人们来说充满诱惑,想让人和它玩玩,见识一下它的本领。
解释笑话
PaLM原始论文中展示了一个非常酷的用例:给定一个笑话,让模型解释它为什么好笑。这个任务需要把尝试和逻辑结合起来,PaLM之前的所有模型都无法做到这一点。
将其中一些笑话交给LLaMA和ChatGPT来解释,有些笑话语言模型能get到,比如Schimidhuber冗长无聊的发言。

但总体上LLaMA和ChatGPT都没什么幽默感。
不过两者应对听不懂的笑话的策略不同,ChatGPT会产生「一堵文本墙」,希望其中至少有一些语句是正确答案,这种行为就像是不知道答案的学生,希望老师能从他们的一通乱说里找出答案。
零样本归类
这是一种很实用的功能,使得人们可以用LLM代替评分员来生成训练集,然后在这些训练集上训练较小的可服务的模型。
一个更有挑战性的任务是点击广告分类,由于连人类都不能就什么是点击广告达成一致,在提示中会向模型提供一些例子,所以事实上这是一个少样本而非零样本归类。下面是LLaMA的提示。
测试中只有LLaMA-33B会设法遵循所要求格式给出答案,而且其预测是合理的,ChatGPT表现次之,能给出比较合理的答案,但时常不按规定的格式回答,较小的7B、13B模型则不太适合完成这项任务。

代码生成
虽然法LLM在人文方面表现出色,但不擅长STEM科目,那么LLaMA在这方面的表现如何呢?
在提示中,给出搜索表的形式和希望达到的目的,要求模型给提供SQL查询语句。
ChatGPT在这项任务中表现更好一点,但语言模型给出的结果总体都不太靠谱。

在与ChatGPT对比进行的各项测试中,LLaMA并没有如想象中一样大获全胜。当然如果其间差距只是由RLHF(带有人类反馈的强化学习)造成的,那小型模型的未来可能会更光明。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


