
狂飙一个虚拟人,AI作画+表情迁移+唇形合成
哈喽,大家好。
ChatGPT 爆火之后,最近大家又开始关注AI作画了,AI作画的出现比ChatGPT早,只不过没有形成全行业性的关注。
AI作画 现在用的比较多的是扩散模型,二次元作画网站Novel AI的模型泄漏,被爆出用的就是Stable Diffusion(稳定扩散模型)
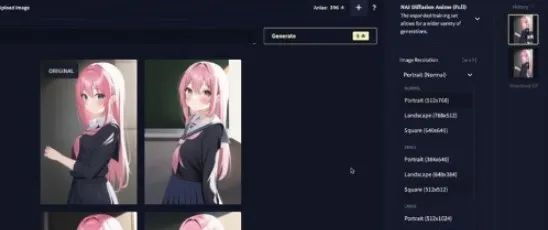
今天,教大家在本地搭建一个web版AI作画工具,可以生成自己的二次元图片,然后用 FOM 模型进行表情迁移,让人脸动起来,在用wav2lip让嘴唇随着声音动起来。
权重文件和测试数据已经打包好了,评论区获取。
首先,下载stable-diffusion-webui源码
https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
提示一下,安装步骤没必要按照官方的,官方的方式太死板了,反而制造更多麻烦。
安装 pytorch

选择对应 cuda 版本和 pytorch 版本安装即可。
安装stable-diffusion-webui依赖包
cd stable-diffusion-webui
pip install -e requirements.txt
安装结束后,执行python launch.py命令,运行后,发现还要安装一些包,如:
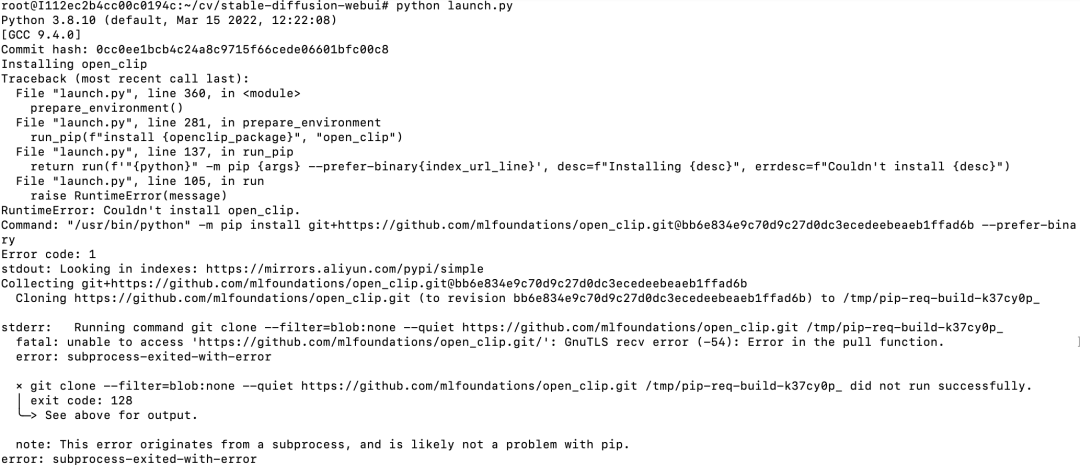
发现Installing open clip一行,说明还需要安装open clip,这个是从github下载源码安装,但github经常访问不了,所以这里经常以失败告终。
不过,观察上面的信息,可以找他安装命令
"/ur/bin/python" -m pip install git+https://github.com/mlfoundations/open_clip.git@bb6e834e9c70d9c27d0dc3ecedeebeaeblffad6b --prefer-bina
ry
我们可以将github.com改为国内的镜像,手动安装这个包
python -m pip install git+https://kgithub.com/mlfoundations/open_clip.gitebb6e834e9c70d9c27de
dc3ecedeebeaeb1ffad6b
--prefer-binarv
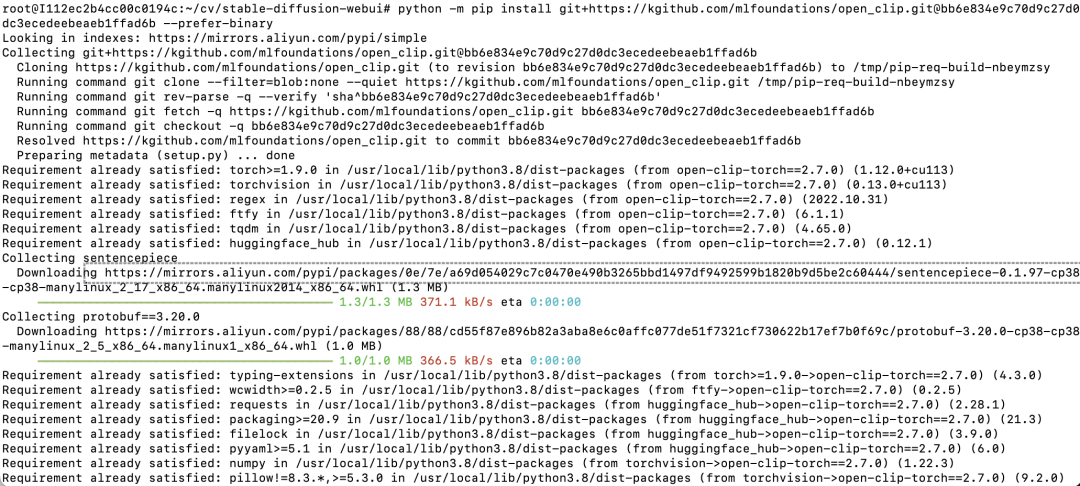
把github.com改为kgithub.com,可以看到安装速度很快。
重复执行python launch.py命令,用同样的方式把依赖包都安装上即可。
最后,看到如下输出,说明stable-diffusion-webui成功启动了
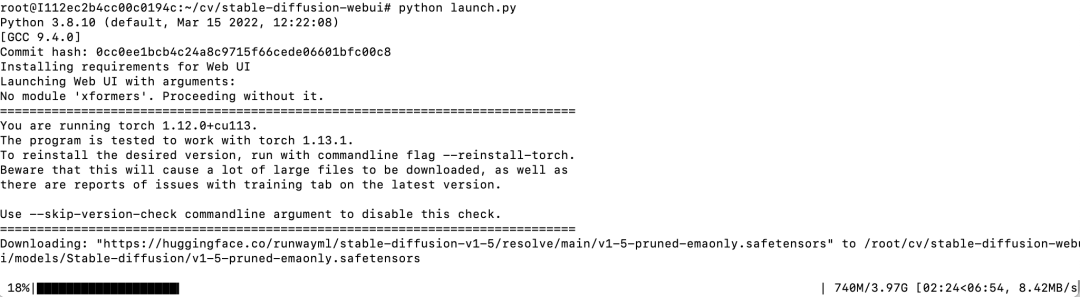
可以看到,这里自动下载的stable diffusion模型是v1-5-pruned-emaonly。
我提供了novel ai模型,效果更好,大家可以下载。覆盖models下Stable-diffusion目录即可。
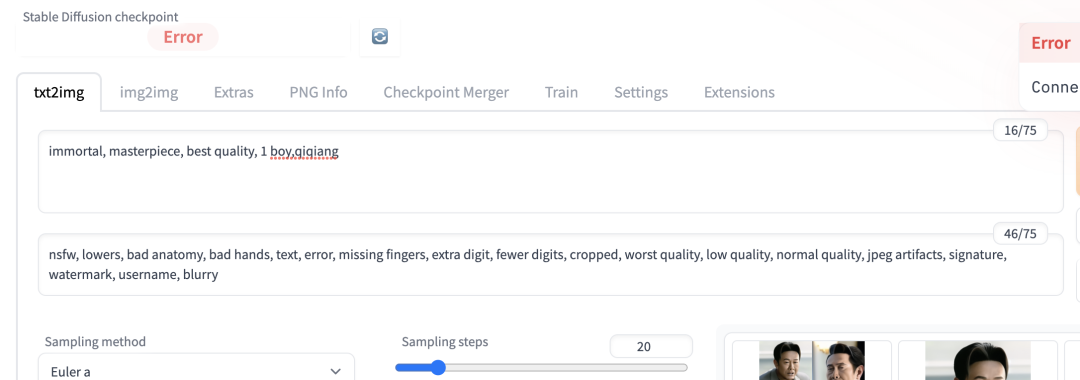
打开webui,填入正面tag和反面tag就可以自动生成图片了。
分享一个地址 https://docs.qq.com/doc/DWHl3am5Zb05QbGVs
这里有大量tag可以直接使用

也可以训练embedding生成特定人物或风格的图片,比如:我训练两个一个高启强的embedding,生成的图片如下:

接下来,我们就驱动图片动起来。
我是基于Paddle实现的,首先安装Paddlehub
pip install --upgrade paddlehub
FOM 模型进行表情迁移
import paddlehub as hub
FOM_Module = hub.Module(name="first_order_motion")
FOM_Module.generate(
source_image="input_data/qiqiang2.png", # 输入图像
driving_video="input_data/ting.mp4", # 输入驱动视频
ratio=0.4,
image_size=256,
output_dir='./output/', # 输出文件夹
filename='qisheng_out2.mp4', # 输出文件名
use_gpu=True)
Wav2lip嘴唇动起来
W2F_Module = hub.Module(name="wav2lip")
W2F_Module.wav2lip_transfer(
face='output/qisheng_out2.mp4',
audio='wavs/ting.wav',
output_dir='./transfer_result/',
use_gpu=True)
本文转载自微信公众号「 渡码」,可以通过以下二维码关注。转载本文请联系 渡码公众号。

© 版权声明
文章版权归作者所有,未经允许请勿转载。


