
这家公司做出了或许能引爆第四次工业革命的产品,但他们却百思不得其解:为啥自家的产品能这么火?
就,真的不是凡尔赛。
最近,MIT Technology Review采访了ChatGPT的几位开发者,让我们近距离地了解了这个大爆的AI产品背后的故事。
火成这样,没有丝毫防备
当OpenAI在202211月下旬悄无声息地推出ChatGPT时,这家初创公司并没有报多大的期望。
OpenAI的员工也没想过,自家模型即将走上的,是一条属于顶流的爆红之路。
ChatGPT仿佛在一夜间大红大紫,还引发了关于大语言模型的一场全球淘金热,而OpenAI还没有丝毫准备,只能匆忙地赶上自己顶流模型的脚步,试图抓住商机。
在OpenAI从事政策工作的Sandhini Agarwal说,在OpenAI内部,ChatGPT一直被视为「研究预览」——它是一个两年前技术的更完善的版本,更重要的是,公司试图通过公众的反馈,来消除模型的一些缺陷。
谁能想到,这样一个「预览」产品,阴差阳错出道后就爆红了呢。
对此,OpenAI的科学家很懵逼,对于外界的鲜花和掌声,他们也很清醒。
「我们不想把它夸大为一个巨大的基础性进步,」参与研发ChatGPT的OpenAI科学家Liam Fedus说。

ChatGPT团队成员当中,有5位被评为2023年度 AI 2000 全球人工智能学者
为此,MIT Technology Review的记者Will Douglas Heaven采访了OpenAI的联合创始人John Schulman、开发者Agarwal和Fedus、对齐团队的负责人Jan Leike。
ChatGPT为什么这么火,我们自己都不明白
创始人John Schulman表示,ChatGPT发布后几天,他时不时就会刷推特。有那么一段疯狂的时期,推特信息流中全是ChatGPT的截图。
他想到了这是一个对用户很直观的产品,也想到它会有一些粉丝,但没想到它会变得这么主流。
Jan Leike表示,一切都太突然了,所有人都很惊讶,努力地跟上ChatGPT爆火的节奏。他很好奇,到底是什么在推动它的人气飙升,难道有什么幕后推手?毕竟,OpenAI自己都搞不清为什么ChatGPT能这么火。

Liam Fedus解释了他们如此惊讶的原因,因为ChatGPT并不是第一个通用的聊天机器人,此前就已经有很多人尝试过了,所以Liam Fedus觉得他们的机会并不大。不过,私人测试版也给了他信心——或许,这款A是用户们真心会喜欢的东西。
Sandhini Agarwal总结道,对所有人来说,ChatGPT一炮而红都是个惊喜。此前,大家在这些模型上做了太多的工作了,以至于都忘记了对于公司外部的普罗大众来说,它是这么惊人。
的确,ChatGPT内的大部分技术并不新鲜。它是GPT-3.5的一个微调版本,而在ChatGPT几个月前,OpenAI就发布了GPT-3.5。而GPT-3.5本身就是GPT-3的更新版本,GPT-3出现于2020年。
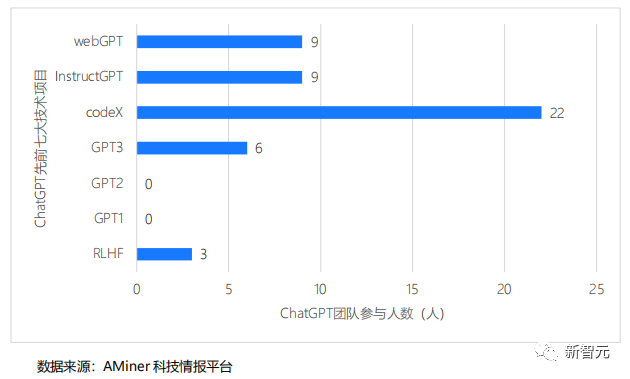
ChatGPT团队参与此前七大技术研发人数
在网站上,OpenAI以应用编程接口或API的形式提供了这些模型,其他开发者可以很轻易地将模型插入自己的代码中。
在2022年1月,OpenAI还发布了GPT-3.5的前一个微调版本InstructGPT。只不过,这些技术没有向公众推介罢了。
微调过程
根据Liam Fedus的介绍,ChatGPT模型是由与InstructGPT相同的语言模型微调而来的,使用的微调方法类似。研究人员增加了一些对话数据,并对训练过程进行了一些调整。所以他们不想把它夸大为一个巨大的基础性进步。
事实证明,对ChatGPT起了大作用的,是对话数据。
根据标准基准的评估,实际上两个模型之间的原始技术能力并没有很大差别,ChatGPT最大的不同是,更容易获得和使用。
Jan Leike解释说,在某种意义上,可以把ChatGPT理解为OpenAI已有一段时间的AI系统的一个版本。ChatGPT的能力并没有更强。在ChatGPT问世之前,同样的基本模型已经在API上使用了将近一年时间。
而研究者们的改进可以概括为,在某种意义上,让它更符合人类想用它做什么。它会在对话中和用户交谈,是一个聊天界面,很容易访问。它更容易推断出意图,而用户可以通过来回试探,来达到自己想要的目的。
秘诀就是,人类反馈强化学习(RLHF)技术,这和InstructGPT的训练方式很像——教会它人类用户实际喜欢的样子。
Jan Leike介绍说,他们让一大群人阅读了ChatGPT的提示和回应,然后对回应进行二选一的选择,看看大家认为哪个回应更好。然后,所有这些数据都被合并到一次训练中。
它的大部分内容与他们在InstructGPT上所做的是一样的。比如你希望它有帮助的,希望它是真实的,希望它不会恶毒。
另外还有一些细节,比如如果用户的询问不清楚,它应该问后续的问题去细化。它还应该澄清,自己是一个人工智能系统,不应该承担它没有的身份,不应该声称拥有它不具备的能力。当用户要求它做它不该做的任务时,它必须明确拒绝。
也就是有一个清单,列出了人类评分员必须对模型进行排名的各种标准,比如真实性。但他们也会偏爱某些做法,比如AI不要假装自己是人。
准备发布
总的来说,ChatGPT用的都是OpenAI已经使用过的技术,所以团队在准备向公众发布这个模型时,没有做任何特别的事情。在他们看来,为以前的模型设定的标准已经足够了,GPT-3.5已经足够安全。
而在ChatGPT对人类偏好的训练中,它自学了拒绝行为,拒绝了很多请求。
OpenAI为ChatGPT组建了一些 「唱红脸的」人:公司里的每个人都坐下来,试图打破这个模型。也有外部团体做同样的事情。值得信赖的早期用户也会提供反馈。
Sandhini Agarwal介绍道,他们确实发现了它会产生某些不需要的输出,但这些都是GPT-3.5也产生的东西。因此,只看风险的话,作为一个「研究预览」,ChatGPT已经够好了。
John Schulman也表示,不可能等到一个系统100%完美了,才去发布它。几个月来,他们对早期版本进行了beta测试,beta测试人员对ChatGPT的印象很好。
OpenAI最担心的,其实是事实性的问题,因为ChatGPT太喜欢捏造东西了。但是这些问题在InstructGPT和其他大型语言模型中都存在,所以在研究者们看来,只要ChatGPT在事实性和其他安全问题上比那些模型更好,就已经足够了。
而根据有限的评估,在发布之前,可以确认ChatGPT比其他模型更真实,更安全,因此,OpenAI决定继续发布。
发布后的反馈
ChatGPT发布后,OpenAI一直在观察用户是如何使用它的。
一个大型语言模型被放在数以千万计的用户手中,这种事还是史上第一次。
用户们也玩疯了,想测试ChatGPT的极限在哪里,bug在哪里。
ChaatGPT的走红,也让许多问题涌现出来,比如偏见问题,比如通过prompt诱导的问题。
Jan Leike表示,某些在推特上疯传的东西,其实OpenAI已经有人悄悄出手了。
比如越狱问题,绝对是他们需要解决的。用户就是喜欢尝试通过一些弯弯绕绕让模型说不好的话,这在OpenAI的意料之内,也是一条必经之路。
当发现越狱时,OpenAI会把这些情况添加到训练和测试数据中,所有数据都会被纳入未来的模型。
Jan Leike表示,每当有一个更好的模型,他们都会想把它拿出来测试。
他们非常乐观地认为,一些有针对性的对抗性训练,可以使越狱的情况得到很大的改善。虽然目前还不清楚这些问题是否会完全消失,但他们认为,自己可以使很多越狱行为变得困难。
当一个系统「正式出道」时,很难预见到所有实际会发生的事情。
因此,他们只能把重点放在监测人们使用该系统的目的上,看看会发生什么,然后对此作出反应。

如今,微软已经推出了必应Chat,很多人认为它是OpenAI官方未宣布的GPT-4的一个版本。
在这个前提下,Sandhini Agarwal表示,现在他们面临的,肯定比六个月前高得多,但仍然低于一年后的水平。
这些模型是在什么背景下被使用的,有极其重要的意义。
对于谷歌和微软这样的大公司,即使有一件事不符合事实,也会成为巨大的问题,因为他们本身就是搜索引擎。
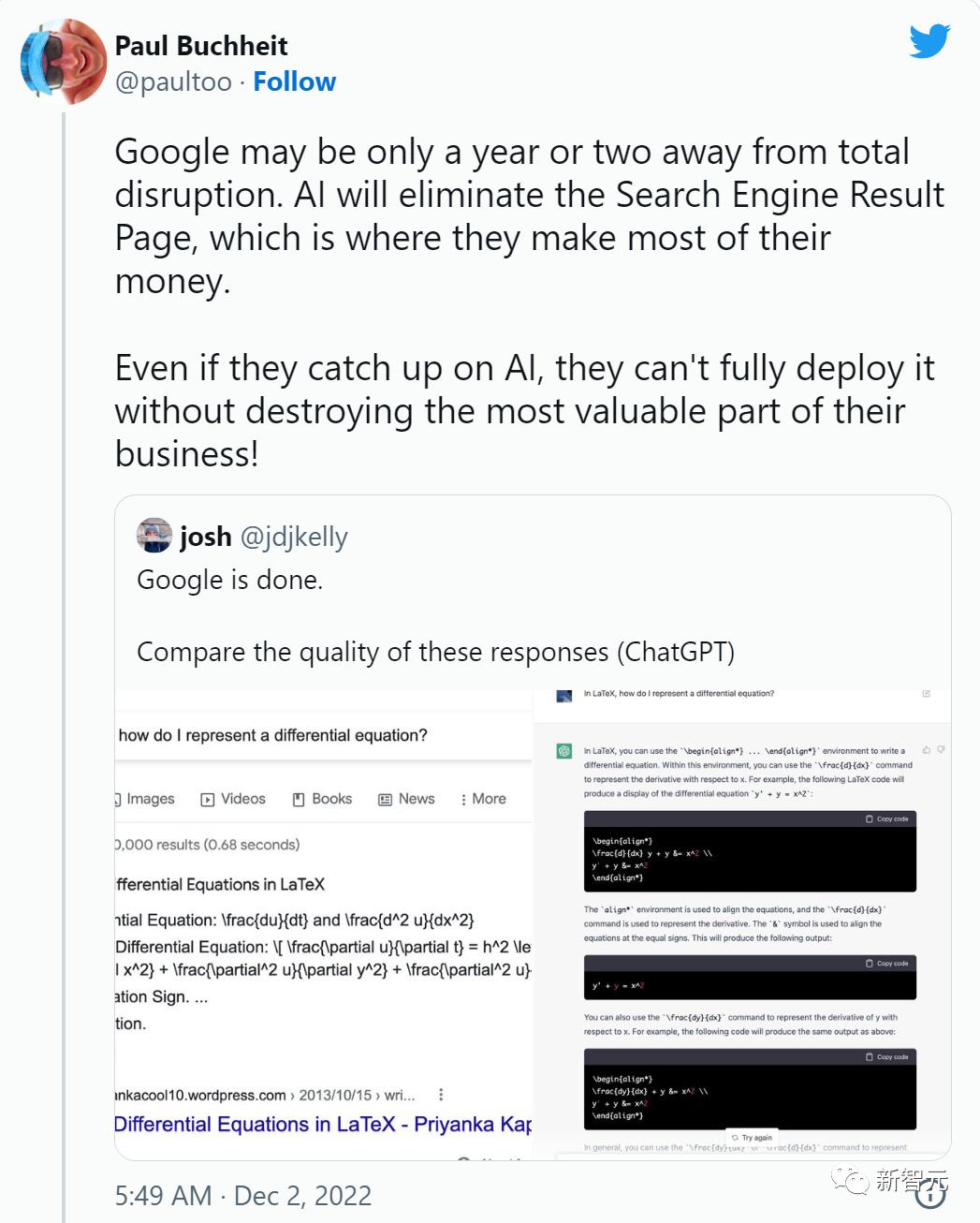
谷歌的第23位员工、创建了Gmail的Paul Buchheit,对谷歌持悲观态度
作为搜索引擎的大语言模型,和一个只为了好玩的聊天机器人是完全不同的。OpenAI的研究者们也在努力弄清楚,如何在不同用途之间游走,创造出真正对用户有用的东西。
John Schulman承认,OpenAI低估了人们对于ChatGPT政治问题的关心程度。为此,在收集训练数据时,他们希望做出一些更好的决定,来减少这方面的问题。
Jan Leike表示,从自己的角度来看,ChatGPT经常出现失败。有太多问题需要解决了,但OpenAI并没有解决。这一点,他坦诚地承认。
尽管语言模型已经存在了一段时间,但仍然处于早期。
接下来,OpenAI需要做的事情,就更多了。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


