中山大学人机物智能融合实验室(HCP)在 AIGC 及多模态大模型方面成果丰硕,在近期的 AAAI 2023、CVPR 2023 先后入选了十余篇,位列全球研究机构的第一梯队。
其中一个工作实现了用因果模型来显著提升多模态大模型在调优中的可控及泛化性——《Masked Images Are Counterfactual Samples for Robust Fine-tuning》。

链接:https://arxiv.org/abs/2303.03052
使用预训练的大规模模型在下游任务上进行微调是当前流行的深度学习范式。尤其是近期预训练语言大模型 ChatGPT 的出色表现,使得这套技术范式得到了广泛的认可。经过海量数据的预训练,这些预训练大模型能够适应现实环境中多变的数据分布,因而在通用场景中表现出较强的鲁棒性。
然而,当用下游场景数据对预训练大模型进行微调以适应特定应用任务时,绝大多数情况下这些数据具有单一性。以这些数据对预训练大模型进行微调训练,往往会降低模型鲁棒性,使基于预训练大模型的应用变得困难。特别是在视觉模型方面,由于图像的多样性远远超过语言,下游微调训练导致视觉相关的预训练大模型鲁棒性下降的问题尤其突出。
之前的研究方法通常通过模型集成等方式在模型参数层面隐式地保持微调后预训练模型的鲁棒性。但是,这些工作并没有分析微调导致模型分布外性能下降的本质原因,也没有明确解决上述大模型微调后鲁棒性下降的问题。
该工作以跨模态大模型为基础,从因果关系的角度分析了预训练大模型鲁棒性损失的本质原因,并据此提出了一种能够显著提升模型鲁棒性的微调训练方法。该方法使得模型在适应下游任务的同时,仍能保持较强的鲁棒性,更好地满足实际应用需求。
以 OpenAI 在 2021 年发布的跨模态预训练大模型 CLIP(Contrastive Language–Image Pre-training)为例:CLIP 是一种基于对比的图片 – 文本联合学习的跨模态预训练大模型,是 Stable Diffusion 等生成式模型的基础。该模型通过包含约 4 亿个图像 – 文本对的海量多源数据进行训练,在一定程度上学习到了一些对于分布变化鲁棒的因果关系。
然而,当用特征单一的下游数据对 CLIP 进行微调时,容易破坏模型学习到的这些因果知识,因为训练图像的非语义表征和语义表征是高度纠缠的。例如,将 CLIP 模型迁移应用到 “农场” 这一下游场景时,许多训练图像中的 “奶牛” 都在草地上。此时,微调训练可能使模型学习到依赖草地这一非 “奶牛” 的语义表征来预测图像的语义。然而,这种相关性并不一定是真实的,例如 “奶牛” 也可能出现在公路上。因此,模型在进行微调训练后,其鲁棒性会降低,应用时的输出结果可能变得极不稳定,缺乏可控性。
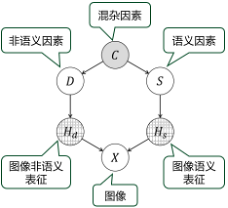
基于团队多年的大模型搭建和训练经验,该工作从因果关系的角度重新审视了预训练模型微调导致鲁棒性下降的问题。基于因果建模与分析,该工作提出了一种基于图像掩码构造反事实样本,并通过掩码图像学习提高模型鲁棒性的微调训练方法。
具体而言,为了打破下游训练图像中的假性相关,该工作提出了一种基于类激活图(CAM)的方法掩盖并替换图像特定区域的内容,用以操纵图像的非语义表征或语义表征,产生反事实样本。微调模型可以通过蒸馏的方式学习模仿预训练模型对这些反事实样本的表征,从而更好地解耦语义因素与非语义因素的影响,提高对下游领域中分布偏移的适应能力。
实验表明,该方法能够显著提高预训练模型在下游任务中的性能,同时在提升鲁棒性方面相较于现有大模型微调训练方法有显著优势。
该工作的重要意义是在一定程度上打开了预训练大模型从深度学习范式中继承的 “黑盒子”,是解决大模型的 “可解释性” 和 “可控性” 问题的重要探索,让我们离切实可享受的由预训练大模型带领的生产力提升越来越近。
中山大学 HCP 团队自 Transformer 机制问世起,从事大模型技术范式研究多年,致力于提升大模型的训练效率和引入因果模型来解决大模型的 “可控性” 问题。团队多年来自主研究开发了多个视觉、语言、语音和跨模态的预训练大模型,与华为诺亚方舟实验室联合开发的 “悟空” 跨模态大模型 (链接:https://arxiv.org/abs/2202.06767) 即是其中的典型案例。
团队简介
中山大学人机物智能融合实验室 (HCP Lab) 在多模态认知计算、机器人与嵌入式系统、元宇宙与数字人、可控内容生成等领域开展体系化研究,并深入应用场景打造产品原型,输出大量原创技术及孵化创业团队。实验室由 IAPR Fellow 林倞教授于 2010 年创办,获得中国图像图形学会科技一等奖、吴文俊自然科学奖、省级自然科学一等奖等荣誉;培养了梁小丹、王可泽等国家级青年人才。
© 版权声明
文章版权归作者所有,未经允许请勿转载。