
谷歌砸了4亿刀的Anthrophic:AI模型训练计算量5年增加1000倍!
自从发现缩放定律以来,人们认为人工智能的发展会像坐火箭一样迅速。
2019年的时候,多模态、逻辑推理、学习速度、跨任务转移学习和长期记忆还是会有减缓或停止人工智能进展的 「墙」。在此后的几年里,多模态和逻辑推理的「墙」都已经倒下了。
鉴于此,大多数人已经越来越相信,人工智能的快速进展将继续下去,而不是停滞不前或趋于平稳。
现在,人工智能系统在大量任务上的表现已经接近人类水平,而且训练这些系统的成本远远低于哈勃太空望远镜、大型强子对撞机这类「大科学」项目,所以说,AI未来的发展潜力巨大。
不过随之发展所带来的的安全隐患问题也越来越凸显。
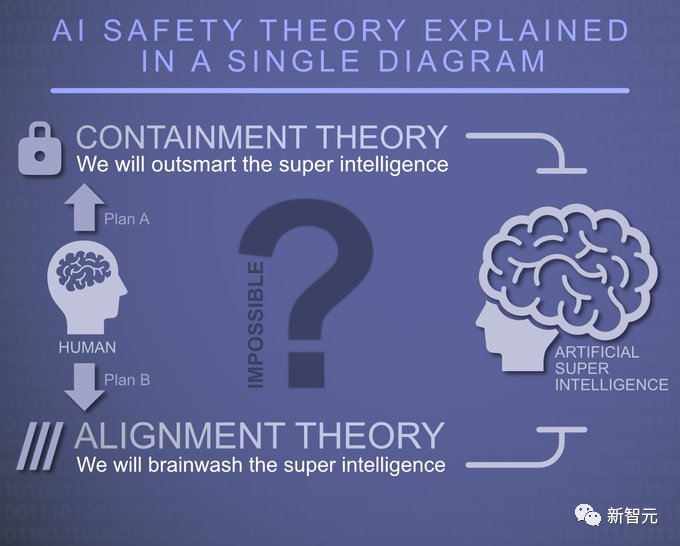
对于人工智能的安全问题,Anthropic分析了三种可能性:

乐观情况下,先进的人工智能因安全故障而产生灾难性风险的可能性非常小。已经开发的安全技术,如从人类反馈中强化学习(RLHF)和宪法人工智能(CAI),已经基本上足以应对风险。
主要风险是故意滥用,以及由广泛的自动化和国际权力动态的转变等导致的潜在危害,这将需要人工智能实验室和第三方,如学术界和民间社会机构,进行大量的研究,来帮助政策制定者驾驭高级人工智能带来的一些潜在的结构性风险。
不好也不坏的情况下,灾难性的风险是先进的人工智能发展的一个可能甚至是合理的结果,我们需要大量的科学和工程努力来避免这些风险,例如通过Anthropic所提供的「组合拳」,我们就能规避风险。
Anthropic目前的安全研究
Anthropic目前正在各种不同的方向上工作,主要分为三个领域:AI在写作、图像处理或生成、游戏等方面的能力;开发新的算法来训练人工智能系统的对齐能力;评估和理解人工智能系统是否真的对齐、效果如何,以及其应用能力。
Anthropic开展了以下这些项目,来研究如何训练安全的人工智能。
机制可解释性
机制可解释性,即试图将神经网络逆向工程变成人类可以理解的算法,类似于人们对一个未知的、有可能不安全的计算机程序进行逆向工程。
Anthropic希望它可以使我们能够做一些类似于「代码审查」的事情,可以对模型进行审查、确定不安全的方面来提供强有力的安全保证。
这是一个非常困难的问题,但也不像看上去那样不可能。
一方面,语言模型是大型的、复杂的计算机程序( 「叠加」的现象会使事情变得更难)。另一方面,有迹象表明,这种方法比人们最初想象得更容易解决。而Anthropic已经成功地将这种方法扩展到小型语言模型,甚至发现了一种似乎可以驱动语境学习的机制,而且对于负责记忆的机制也更为了解。
Antropic的可解释性研究想要填补其他种类的排列组合科学所留下的空白。例如,他们认为可解释性研究可以产生的最有价值的东西之一,是识别一个模型是否是欺骗性对齐的能力。
在许多方面,技术一致性问题与检测人工智能模型的不良行为的问题密不可分。
如果在新情况下,也能稳健地检测出不良行为(例如通过 “阅读模型的思想”),那么我们就能够找到更好的方法来训练模型,不去表现出这些故障模式。
Anthropic相信,通过更好地了解神经网络和学习的详细工作原理,可以开发出更广泛的工具来追求安全。
可扩展的监督
将语言模型转化为统一的人工智能系统,需要大量的高质量反馈来引导它们的行为。主要是人类可能无法提供必要的准确反馈,来充分训练模型在广泛的环境中去避免有害的行为。
可能是人类会被人工智能系统愚弄,无法提供反映他们实际需求的反馈(例如,不小心为误导性建议提供了积极的反馈)。而且人类在规模上做不到这点,这就是可扩展的监督问题,也是训练安全、一致的人工智能系统的核心问题。
因此,Anthropic认为提供必要的监督的唯一方法,是让人工智能系统部分地监督自己或协助人类监督自己。以某种方式,将少量高质量的人类监督,放大为大量高质量的人工智能监督。
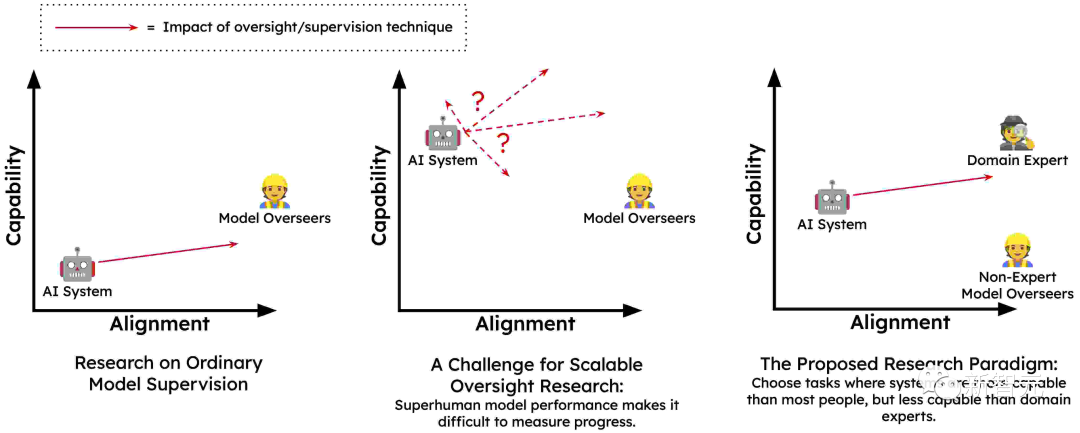
这个想法已经通过RLHF和宪法人工智能等技术显示出了希望,语言模型已经在预训练中学习了很多关于人类价值观的知识,可以期待更大的模型对人类价值观有更准确的认识。
可扩展监督的另一个关键特征,特别是像CAI这样的技术,是允许自动进行红队(又称对抗性训练)。也就是说,他们可以自动向人工智能系统生成有潜在问题的输入,看看它们如何反应,然后自动训练它们以更诚实和无害的方式行事。
除了CAI,还有人类辅助监督、AI-AI辩论、多Agent RL的红队,以及创建模型生成的评估等多种可扩展的监督方法。通过这些方法,模型可以更好地理解人类的价值观,行为也会更符合人类价值观。以此,Anthropic可以训练出更强大的安全系统。
学习过程,而不是实现结果
学习一项新任务的一种方式是通过试错。如果知道所期望的最终结果是什么,就可以不断尝试新的策略,直到成功。Anthropic把这称为「以结果为导向的学习」。
在这个过程中,智能体的策略完全由期望的结果决定,将趋向于选择一些低成本的策略,让它实现这一目标。
更好的学习方式通常是让专家指导你,去了解他们获得成功的过程。在练习回合中,你的成功可能并不重要,重要的是,你可以专注于改进你的方法。
随着你的进步,你可能会与你的教练协商,去寻求新的策略,看看它是否对你更有效。这叫做「过程导向的学习」。在以过程为导向的学习中,最终的结果不是目的,掌握过程才是关键。
至少在概念层面上,许多对高级人工智能系统安全性的担忧,都可以通过以过程为导向的方式训练这些系统来解决。
人类专家将继续理解人工智能系统所遵循的各个步骤,而为了使这些过程得到鼓励,它们必须向人类说明理由。
人工智能系统不会因为以不可捉摸或有害的方式获得成功而得到奖励,因为它们将只能根据其过程的有效性和可理解性获得奖励。
这样它们就不会因为追求有问题的子目标(如资源获取或欺骗)而得到奖励,因为人类或其智能体会在训练过程中为它的获取过程提供负面反馈。
Anthropic认为以「过程为导向的学习」可能是训练安全和透明系统的最有希望的途径,也是最简单的方法。
了解泛化
机制性的可解释性工作对神经网络所进行的计算进行了反向工程。Anthropic还试图对大型语言模型(LLM)的训练程序有一个更详细的了解。
LLMs已经展示了各种令人惊讶的新行为,从惊人的创造力到自我保护到欺骗。所有这些行为都来自于训练数据,但过程很复杂:
模型首先在大量的原始文本上进行「预训练」,从中学习广泛的表征,模拟不同智能体的能力。然后,它们以各种方式进行微调,其中一些可能会产生令人惊讶的后果。
由于微调阶段过度参数化,学习到的模型在很大程度上取决于预训练的隐性偏见,而这种隐性偏见来自于在世界大部分知识的预训练中建立的复杂的表征网络。
当一个模型的行为令人担忧时,例如当它扮演一个具有欺骗性的人工智能时,它是否只是对近乎相同的训练序列进行无害的「反刍」?还是说这种行为(甚至是会导致这种行为的信念和价值观)已经成为模型对人工智能助手概念的一个组成部分,以至于他们在不同的环境下都会应用这种概念?
Anthropic正在研究一种技术,尝试将模型的输出追溯回训练数据,以此来找出可以帮助理解这种行为的重要线索。
危险故障模式的测试
一个关键的问题是,先进的人工智能可能会发展出有害的突发行为,例如欺骗或战略规划能力,而这些行为在较小和能力较弱的系统中是不存在的。
在这种问题成为直接威胁之前,Anthropic认为能够预测它的方法就是建立环境。所以,他们故意将这些属性训练到小规模的模型中。因为这些模型的能力还不足以构成危险,这样就可以隔离和研究它们。
Anthropic对人工智能系统在「情境意识」下的行为特别感兴趣——例如,当它们意识到自己是一个在训练环境中与人类交谈的人工智能时,这会如何影响它们在训练期间的行为?人工智能系统是否会变得具有欺骗性,或者发展出令人惊讶的不理想的目标?
在理想的情况下,他们想要建立详细的量化模型,说明这些倾向是如何随规模变化的,这样就能提前预测到突然出现的危险故障模式。
同时,Anthropic也关注与研究本身相关的风险:
如果研究是在较小的模型上进行,不可能有严重的风险;如果在能力更强的大型模型上进行,就会有明显的风险。因此,Anthropic不打算在能够造成严重伤害的模型上进行这种研究。
社会影响和评估
Anthropic研究的一个关键支柱,是通过建立工具、测量,批判性地评估和理解人工智能系统的能力、限制和潜在的社会影响其潜在的社会影响。
例如,Anthropic已经发表了分析大型语言模型可预测性的研究,他们研究了这些模型的高级可预测性和不可预测性,并分析这种属性会如何导致有害行为。
在这项工作中,他们研究了红队语言模型的方法,通过探测模型在不同模型规模下的输出来发现并减少危害。最近,他们又发现目前的语言模型可以遵循指令,减少偏见和成见。
Anthropic非常关注人工智能系统的快速应用将如何在短期、中期和长期内影响社会。
通过对人工智能今天的影响进行严格的研究,他们旨在为政策制定者和研究人员提供他们需要的论据和工具,来帮助减轻潜在的重大社会危机,确保人工智能的好处可以惠及人们。
结语
人工智能会在未来十年内,对世界产生前所未有的影响。计算能力的指数级增长和人工智能能力的可预测改进表明,未来的技术要比如今的先进得多。
然而,如何确保这些强大的系统与人类价值观紧密结合,我们对此还没有一个扎实的理解,因此也无法保证将灾难性故障的风险降到最小。所以,我们要时时刻刻为不太乐观的情况做好准备。
通过多个角度的经验研究,Anthropic所提供的安全工作「组合拳」,似乎可以帮助我们解决人工智能的安全问题。
Anthropic提出的这些安全建议告诉我们:
「要提高我们对人工智能系统如何学习和推广到现实世界的理解,开发可扩展的人工智能系统监督和审查技术,创建透明和可解释的人工智能系统,培训人工智能系统遵循安全流程而不是追求结果,分析人工智能的潜在危险故障模式以及如何预防它们, 评估人工智能的社会影响,以指导政策和研究等等。」
对于人工智能的完美防御之法,我们还处于摸索阶段,不过Anthropic很好地为大家指明了前路。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


