三维重建是计算机视觉(CV)和计算机图形学(CG)的热点主题之一,它通过 CV 技术处理相机等传感器拍摄的真实物体和场景的二维图像,得到它们的三维模型。随着相关技术的不断成熟,三维重建越来越广泛地应用于智能家居、AR 旅游、自动驾驶与高精度地图、机器人、城市规划、文物重建、电影娱乐等多个不同领域。
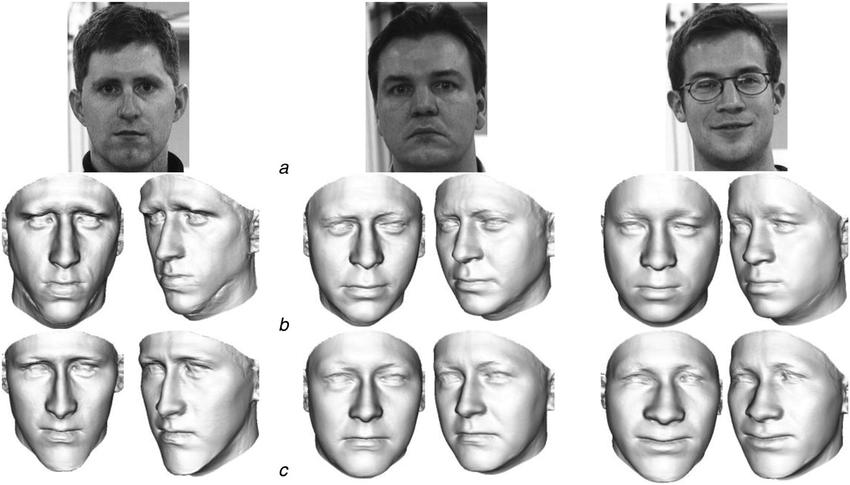
典型的基于二维图像的三维人脸重建。图源:10.1049/iet-cvi.2013.0220
传统三维重建大致可以分为光测度和几何方法,前者分析像素点的亮度变化,后者依靠视差完成重建。近年来又开始采用机器学习尤其是深度学习技术,在特征检测、深度估计等方面取得很好的效果。虽然当前一些方法利用空间几何模型与纹理贴图,在场景的外观还原度上与真实世界看起来几近相同。
但应看到,这些方法仍存在一些局限,仅能还原场景外观特征,无法实现场景内光照、反射率和粗糙度等更深层次属性的数字化,对这些深层信息的查询和编辑更无从谈起了。这也导致无法将它们转化为渲染引擎可用的 PBR 渲染资产,也就不能生成真实感十足的渲染效果。如何解决这些问题呢?逆渲染技术逐渐进入了人们的视野。
逆渲染任务最早是由老一辈计算机科学家 Barrow 和 Tenenbaum 于 1978 年提出,在三维重建的基础上,进一步恢复光照、反射率、粗糙度和金属度等场景内在属性,实现更具真实感的渲染。不过从图像中分解这些属性极其不稳定,不同的属性配置往往导致相似的外观。随着可微分渲染和隐式神经表示的进展,一些方法在具有显式或隐式先验的以物体为中心的小场景中取得了较好效果。
然而大规模室内场景的逆渲染一直没能很好地解决,不仅难以在真实场景下恢复物理合理的材质,场景内多视角一致性也很难保证。在国内有这样一家深耕自主研发核心算法,专注三维重建领域大规模行业应用的技术公司 —— 如视(Realsee),针对大规模室内场景的逆渲染这一难啃的课题,开创性地提出了高效的多视角逆渲染框架。论文已被 CVPR 2023 会议接收。

- 项目地址:http://yodlee.top/TexIR/
- 论文地址:https://arxiv.org/pdf/2211.10206.pdf
具体来讲,如视新方法可以基于精准的空间数据,反向推测获取诸如光照、反射率、粗糙度等场景内在属性,在三维重建的基础上恢复出贴近真实场景的光照和材质表现,在重建效果、成本效率、应用范围等维度实现全面提升。
本文将对如视大规模室内场景的多视角逆渲染技术进行详细的解读,并深入剖析其优势所在。
面向大规模室内场景
如视全新逆渲染技术做到「准、细、快」
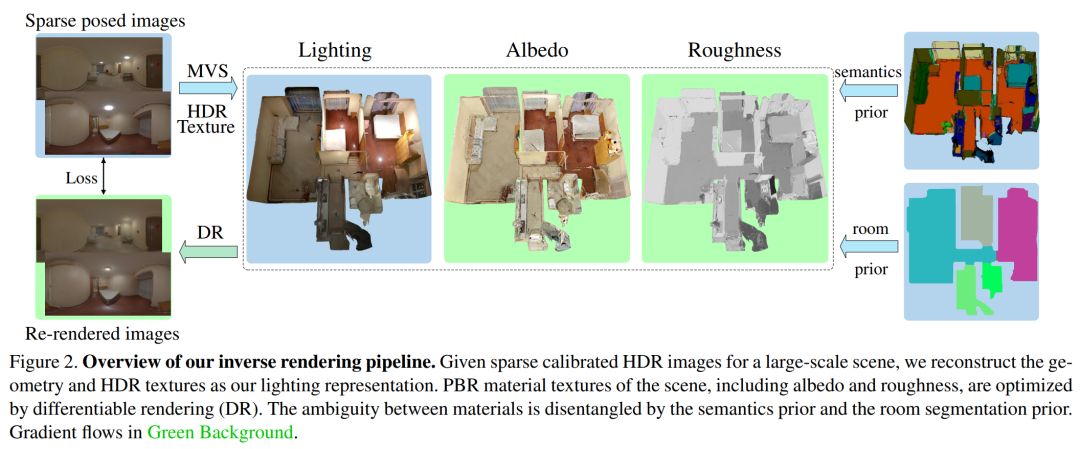
下图 2 为如视全新逆渲染方法的整体流程。给定一组经过校准的大规模室内场景的 HDR 图像,该方法旨在准确地恢复全局一致的光照和 SVBRDFs(双向反射率分布函数),从而方便地集成到图像 pipeline 和下游应用中。
为了实现这些目标,如视首先提出一种被称为 TBL(Texture-based Lighting)的紧凑光照表示,它由 3D 网格和 HDR 纹理组成,高效建模了整个室内大场景任意位置内包含直接和无限次弹射间接光照的全局光照。基于 TBL,如视又进一步提出了具有预计算辐照度的混合光照表示,大幅提升了效率并减轻了材质优化中的渲染噪声。最后如视引入了一种基于分割的三阶段式材质优化策略,很好地处理了复杂大规模室内场景中材质物理上的模糊性。
基于纹理的光照(TBL)
在表示大规模室内场景的光照上,TBL 的优势分别表现在神经表示的紧凑性、IBL 全局光照以及参量光的可解释性和空间一致性。TBL 是对整个场景的全局表示,定义了所有表面点的射出辐照度。而一个表面点的射出辐照度通常等于 HDR 纹理的值,即输入的 HDR 图像中相应像素观察到的 HDR 辐照度。
如视使用自研的高质量三维重建技术来重建整个大场景的网格模型。最终基于输入的 HDR 图像来重建 HDR 纹理,并通过 HDR 纹理从任意位置任意方向查询全局光照。下图 3(左)展示了 TBL 的可视化。

混合光照表示
在实践中,直接利用 TBL 优化材质存在弊端,蒙特卡洛高采样数会导致很高的计算和内存成本。由于大多数噪声存在于漫反射分量,如视对漫反射分量表面点的辐照度进行预计算。因此可以高效地查询辐照度,取代了成本高昂的在线计算,如图 3(右)所示。基于 TBL 的渲染方程由公式 (1) 重新写为公式 (2)。
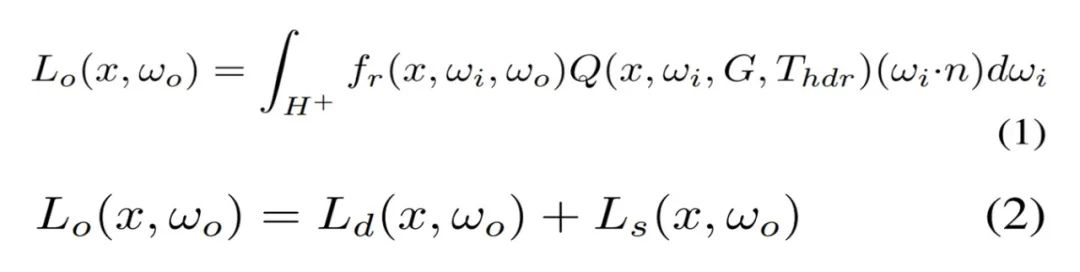
如视提出了两种表示来建模预计算辐照度。一种是神经辐照度场(NIrF),它是一个浅层多层感知器(MLP),以表面点作为输入并输出辐照度 p。另一种是辐照度纹理(IrT),它类似于计算机图形学中常用的光照贴图。
可以看到,这种混合光照表示包含了用于漫反射分量的预计算辐照度和用于镜面反射分量的源 TBL,大大降低了渲染噪声,实现了材质的高效优化。公式 (2) 中的漫反射分量被建模为公式 (3) 所示。
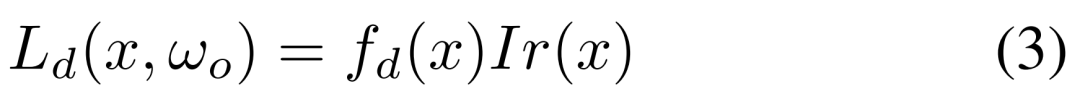
基于分割的三阶段式材质估计
对于神经材质而言,很难用极其复杂的材质对大规模场景进行建模,并且不适配传统的图形引擎。如视选择直接优化几何的显式材质纹理,使用了以 SV 反照率和 SV 粗糙度作为参数的简化版 Disney BRDF 模型。不过由于观察的稀疏性,直接优化显式材质纹理导致不一致和未收敛的粗糙度。
对此,如视利用语义和房间分割先验来解决这一问题,其中语义图像通过基于学习的模型预测,房间分割通过占用网格计算。在实现过程中,如视采取三阶段式策略。
第一阶段基于 Lambertian 假设来优化稀疏反照率,而不像以物体为中心的小场景那样将反照率初始化为常数。虽然可以通过公式 (3) 直接计算漫反射反照率,但在高光区域会使得反照过亮,导致下一阶段的粗糙度过高。因此,如视使用语义平滑约束在相同的语义分割上激发类似的反照率,如下公式 (4) 所示。稀疏的反照率通过公式 (5) 来优化。
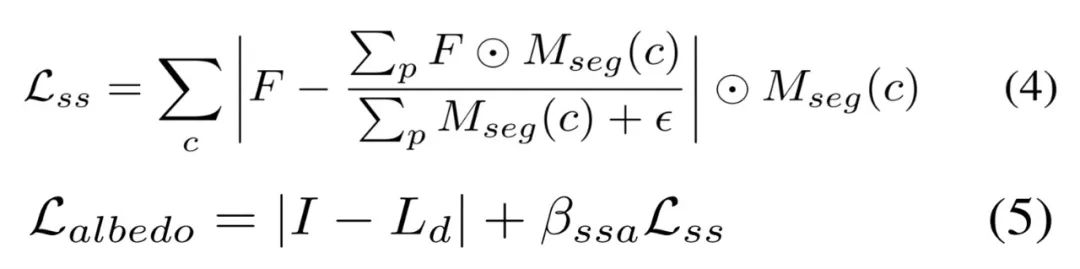
第二阶段基于虚拟高光(VHL)的采样和基于语义的传播。在多视图图像中,只能观察到稀疏的镜面反射线索会导致全局不一致的粗糙度,大规模场景尤甚。不过通过语义分割先验,高光区域的合理粗糙度可以传播到具有相同语义的区域。
如视首先基于粗糙度为 0.01 的输入姿态来渲染图像以找到每个语义类的 VHL 区域,然后根据冻结的稀疏反照率和光照来优化这些 VHL 的粗糙度。合理的粗糙度可以通过公式 (6) 传播到相同的语义分割中,并且该粗糙度可以通过公式 (7) 进行优化。
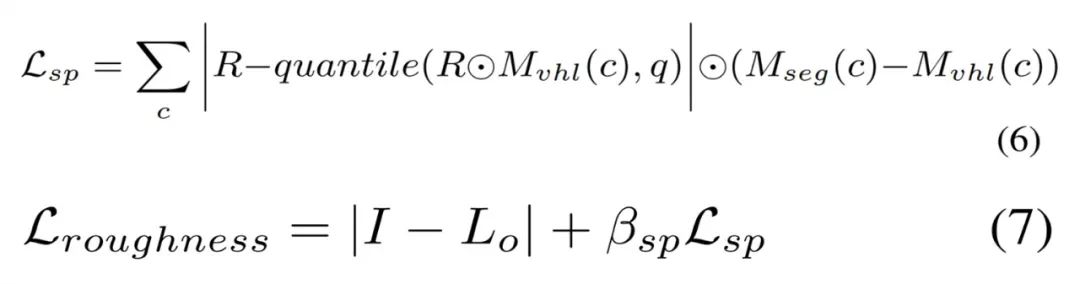
第三阶段基于分割的微调。如视基于语义分割和房间分割先验来微调所有的材质纹理。具体地,如视使用了与公式 (4) 类似的平滑约束以及用于粗糙度的房间平滑约束,使不同房间的粗糙度变得更柔和、平滑。房间平滑约束由公式 (8) 定义,同时不对反照率使用任何平滑约束,总损失被定义公式 (9) 所示。
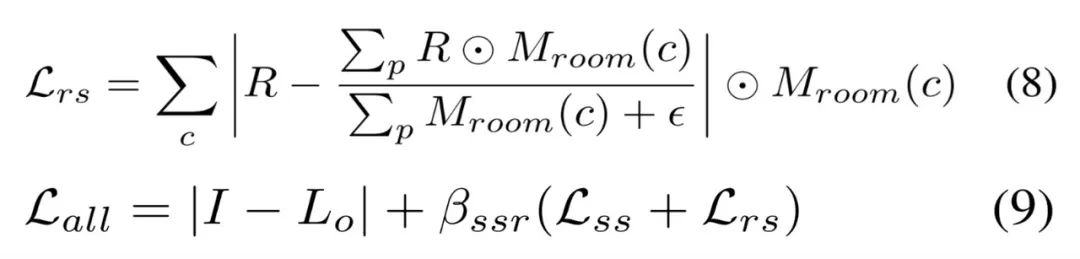
实验设置和效果比较
关于数据集,如视使用了两个数据集:合成数据集和真实数据集。对于前者,如视使用路径追踪器创建一个具有不同材质和光源的合成场景,渲染了 24 个用于优化的视图和 14 个新视图,为每个视图渲染 Ground Truth 材质图像。对于后者,由于 Scannet、Matterport3D 和 Replica 等常用大规模场景的真实数据集缺乏 full-HDR 图像,如视收集了 10 个 full-HDR 真实数据集,并通过合并 7 个包围式曝光捕获 10 到 20 个 full-HDR 全景图像。
关于基线方法。对于从大规模场景的多视图图像中恢复 SVBRDFs,目前逆渲染方法有基于单张图像学习的 SOTA 方法 PhyIR、以多视图物体为中心的 SOTA 神经渲染方法 InvRender、NVDIFFREC 和 NeILF。关于评估指标,如视使用 PSNR、SSIM 和 MSE 来评估材质预测和重渲染图像以进行定量比较,并使用 MAE 和 SSIM 来评估由不同光照表示渲染的重打光图像。
首先来看合成数据集上的评估,如下表 1 和图 4 所示,如视方法在粗糙度估计方面显著优于 SOTA 方法,并且该粗糙度可以产生物理合理的镜面反射率。此外相较于原来的隐式表示,具有如视混合光照表示的 NeILF 减少了材质与光照之间的模糊性。
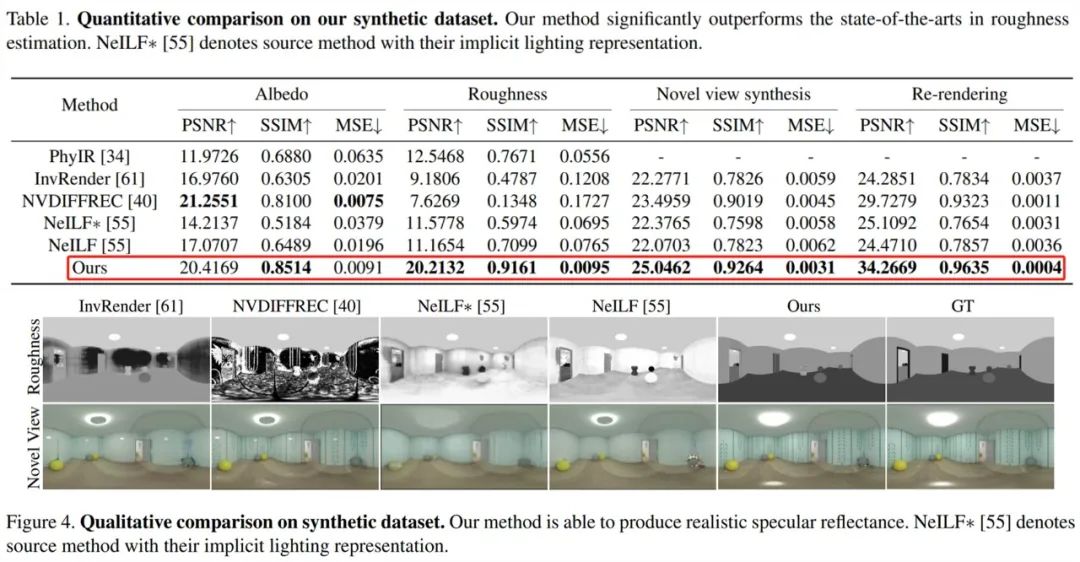
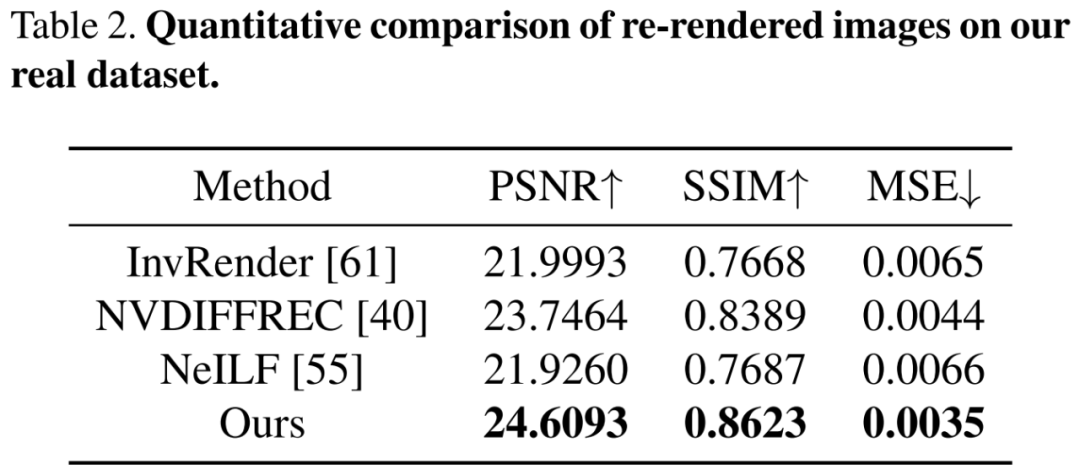
接着在包含复杂材质和光照的挑战性真实数据集上进行评估,下表 2 的定量比较结果显示出如视方法优于以往方法。尽管这些方法具有近似的重渲染误差,但仅有如视方法解耦了全局一致和物理合理的材质。
下图 5 和图 6 分别展示了 3D 视图和 2D 图像视图的定性比较。PhyIR 由于域间隙大导致泛化性能差,无法实现全局一致性预测。InvRender、NVDIFFREC 和 NeILF 产生了带有伪影的模糊预测,难以解耦正确的材质。NVDIFFREC 虽能实现与如视方法类似的性能,但无法解耦反照率与粗糙度之间的模糊性,比如镜面反射分量中的高光被错误地恢复为漫反射反照率。

消融实验
为了展示其光照表示和材质优化策略的有效性,如视针对 TBL、混合光照表示、第一阶段的反照率初始化、第二阶段用于粗糙度估计的 VHL 采样和语义传播、第三阶段基于分割的微调进行了消融实验。
首先将 TBL 与以往方法中广泛使用的 SH 光照和 SG 光照方法进行了比较,结果如下图 7 所示,如视 TBL 在低频和高频特征方面都表现出了高保真度。

其次验证混合光照表示的有效性,将混合光照表示与原始 TBL 进行比较,结果如下图 8 所示。如果没有混合光照表示,反照率会导致噪声并且收敛变慢。预计算辐照度的引入可以使用高分辨率输入来恢复精细的材质,并大大加速优化过程。同时与 NIrF 相比,IrT 产生了更精细和无伪影的反照率。

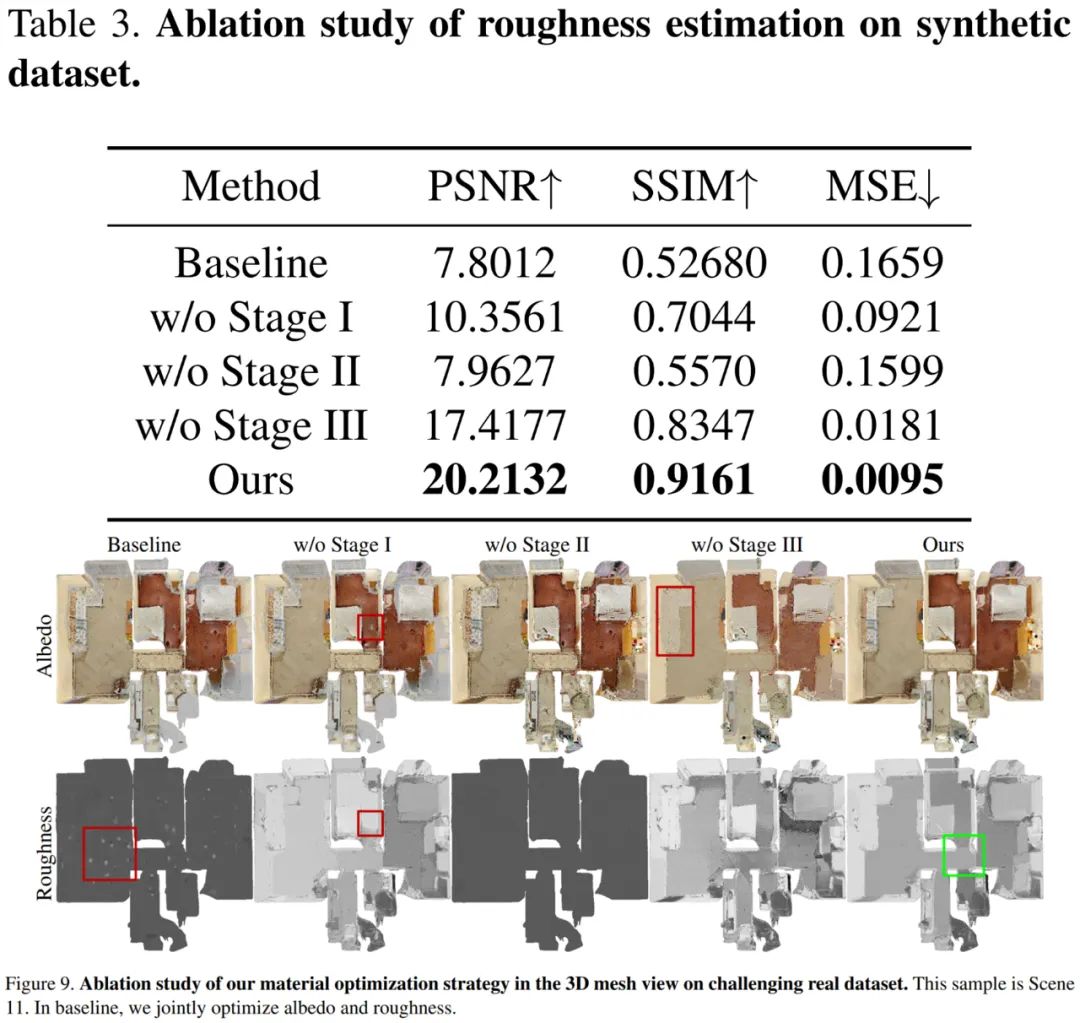
最后对三阶段式策略的有效性进行了验证,结果如下表 3 和图 9 所示。基线粗糙度未能收敛且仅高光区域得到更新。第一阶段如果没有反照率初始化,则高光区域反照过亮并导致不正确的粗糙度。第二阶段基于 VHL 的采样和基于语义的传播,对于恢复未观察到镜面反射高光区域的合理粗糙度至关重要。第三阶段基于分割的微调产生了精细的反照率,使得最终的粗糙度更平滑,并阻止了不同材质之间粗糙度的错误传播。
如视全新逆渲染技术,强在哪里?
其实,如视在其 CVPR 2022 论文《PhyIR: Physics-based Inverse Rendering for Panoramic Indoor Images》中通过提出神经网络训练方法,在单张图像的逆渲染任务上取得了 SOTA 结果。现在全新逆渲染框架不仅做到了多视角、整屋全空间全场景,而且解决了以往逆渲染方法的多个关键缺陷。
首先以往基于合成数据训练的方法在真实场景中表现不佳。如视全新深度逆渲染框架首次引入了「层级式场景先验」,通过多阶段的材质优化并结合全球最大三维空间数据库如视数字空间中的居住空间数据,对空间内的光照、反射率和粗糙度等物理属性实现了分层级的精准预测。
预测结果最终输出为物理合理、全局一致的多类型材质贴图,将如视设备真实拍摄的室内场景数据无缝转化为数字化渲染资产,适配 Unity、Blender 等目前所有主流渲染引擎,由此实现场景资产自动生成和基于物理的 MR 应用,如材质编辑、新视图合成、重打光、虚拟物体插入等。这种通用性很强的数字资产有利于支持后续更多不同的应用和产品。

材质编辑

重打光
其次以往基于优化的可微渲染方法计算成本极高,效率极低。近年来,为了更好地解决逆渲染问题,同时减少对训练数据的依赖,可微渲染方法被提出,即通过「微分求导」方式使正向渲染可微分,进而将梯度反向传播至渲染参数,最终优化得到基于物理的待求解参数。这类方法包括球谐(spherical-harmonic, SH)光照 [1] 和三维球形高斯(Volumetric Spherical Gaussian, VSG)光照。
但是大规模室内场景存在遮挡、阴影等大量复杂的光学效应,在可微渲染中建模全局光照会带来高昂的计算成本。如视本次提出的 TBL 在高效准确地表示室内场景全局光照的同时,只需要大约 20MB 内存,而基于密集网格的 VSG 光照 [2] 大约需要 1GB 内存,基于稀疏网格的 SH 光照方法 Plenoxels [3] 大约需要 750MB 内存,数据内存容量实现了数十倍缩减。
不仅如此,如视新方法可以在 30 分钟内完成整个室内场景的逆渲染,而传统方法 [4] 可能需要 12 个小时左右,整整提升了 24 倍。计算速度的大幅提升意味着成本的降低,性价比优势更加显著,从而离大规模实际应用更近了一步。
最后以往的类 NeRF 神经逆渲染方法(如 PS-NeRF [5]、 NeRFactor [6] 等)主要面向以物体为中心的小规模场景,建模大规模室内场景似乎无能为力。基于如视精准数字空间模型以及高效准确的混合光照表示,全新逆渲染框架通过引入语义分割和房间分割先验解决了这一问题。
对于此次的全新深度逆渲染框架,如视首席科学家潘慈辉表示,「真正意义上实现了对真实世界更深层的数字化,解决了以往逆渲染方法难以在真实场景下恢复物理合理的材质和光照以及多视角一致性的问题,为三维重建和 MR 的落地应用带来了更大想象空间。」
把握逆渲染技术优势
在数字空间中创新 VR + 产业融合
一直以来,如视在三维重建领域拥有很多技术积累,投入大量精力打磨并致力于相关算法的落地。同时对前沿技术的研发支持力度很大,非常看重行业上领先技术的攻克。这些成为包括此次全新逆渲染技术在内如视三维实景模型重建和 MR 研究获得国际学术界认可的重要基础,并帮助如视算法能力在理论研究、技术应用等层面步入国际领先水平。
这些算法及技术优势将实现对真实世界的更深层数字化,并借此进一步加速实现数字空间的建设。目前,如视数字空间通过自研的采集设备,在不同国家、不同应用场景中的累计采集量已经超过 2700 万套、覆盖面积达到 22.74 亿平方米。如视数字空间又将助力其 VR + 产业融合发展方向,为商业零售、工业设施、文博会展、公共事务、家居家装、房产交易等行业带来数字化应用升级的全新发展机遇,如 VR 看房、VR 博物馆等。

如视打造的AI营销助手
对于 VR + 产业融合,如视的最大优势在于不断良性进化的数字化重建算法和海量真实数据的积累,使其同时拥有了较高的技术壁垒和较大的数据壁垒。这些算法和数据在某种程度上还能相互循环起来,不断地扩大优势。同时数据和算法的壁垒使如视更加容易地切入各个行业的痛点问题,带来一些技术解决方案,创新行业发展新模式。
逆渲染技术成果连续两年入选 CVPR,主要脱胎于如视想要在 MR 方向上有所作为并在产业上实现一些落地。未来,如视希望打通实景 VR 与纯虚拟仿真之间的 Gap,真正做到虚实融合,并构建更多行业应用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。