
昨晚实在是有些热闹。
一边英伟达 GTC 正在进行中,一边谷歌正式开放了 Bard 的测试,这里微软必应也不甘寂寞。
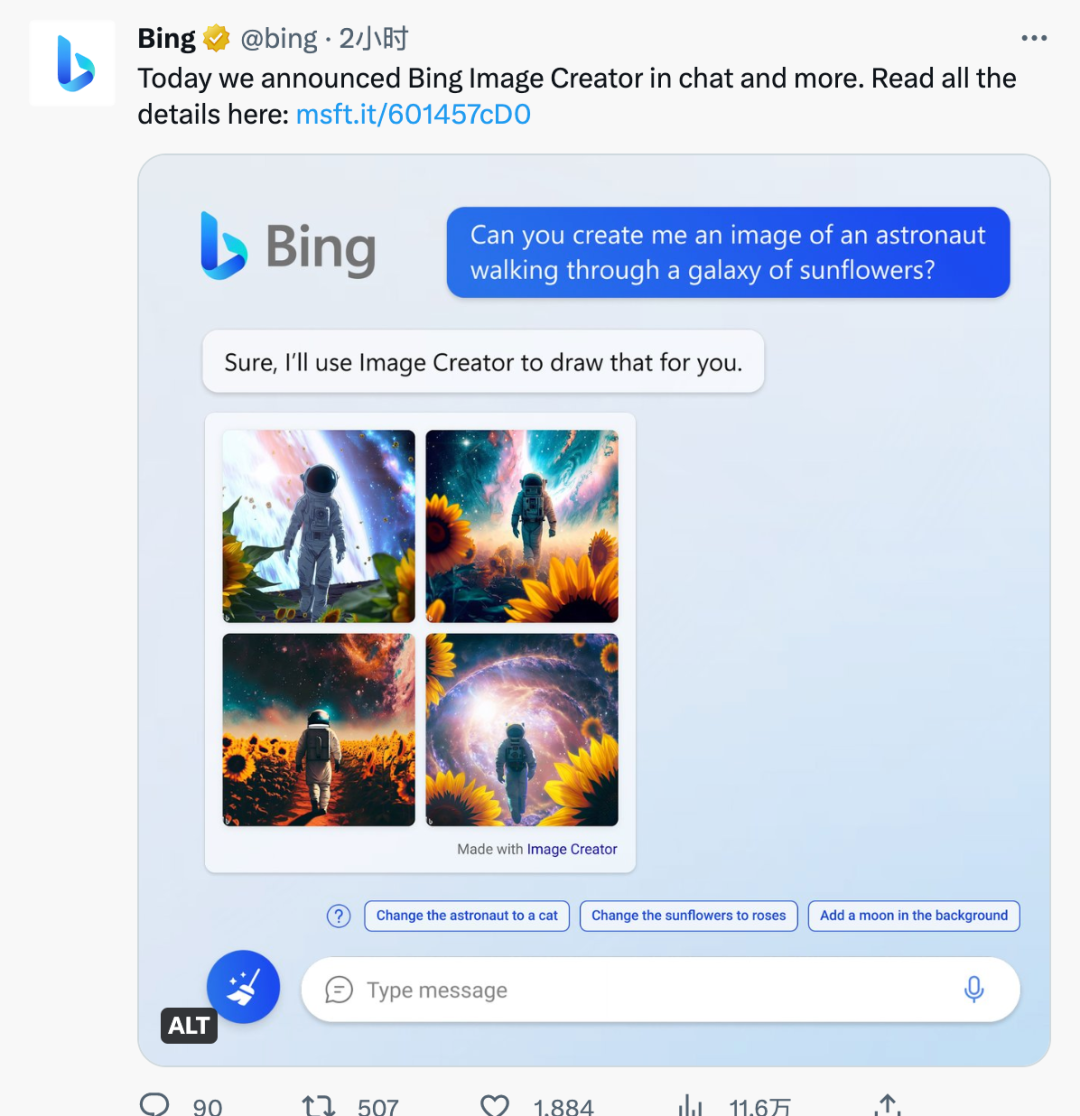
今日,微软正式宣布,必应搜索引擎接入了 OpenAI 的 DALL·E 模型,增加了 AI 生成图像的功能。
也就是说,在接入 ChatGPT 之后,必应再次强化,Bing Image Creator 能够让用户用 DALL·E 模型生成图像。
「对于拥有必应预览版权限的用户,Bing Image Creator 将完全集成到必应聊天体验中,首先在创意模式下推出。」微软消费者营销主管 Yusuf Mehdi 解释道。「通过输入图像描述,提供位置或活动等额外语境,选择艺术风格,Image Creator 将根据用户的想象生成图像。」
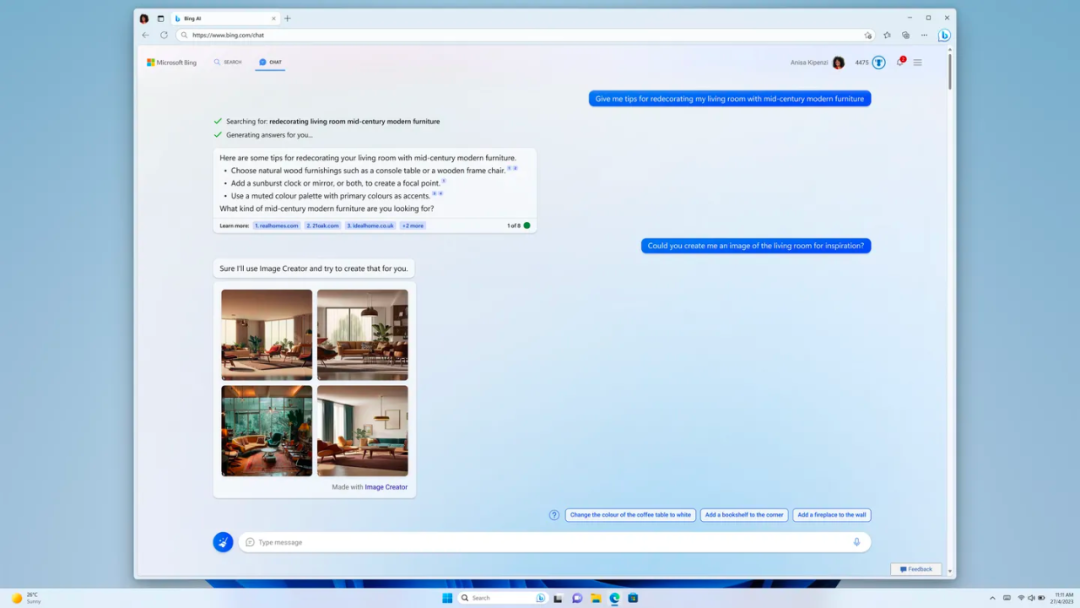
必应具有三种响应模式:创意模式、平衡(balanced)模式和精确(precise)模式。创意模式下必应生成的结果通常是「原创和富有想象力的」,而精确模式则倾向于准确性和相关性,以获得更真实和简洁的答案。目前 Image Creator 只能在创意模式下使用。
值得一提的是,即使没有必应预览版的使用权限,用户也可以通过直接访问 bing.com/create 单独使用 Image Creator 来尝试其图像生成功能,目前仅支持英文输入。微软表示,随着时间的推移,它将支持更多的语言输入。
此外,微软还在必应中推出了新的 AI 支持的视觉故事(visual Stories)和 Knowledge Cards 2.0。
我们简单为大家梳理介绍下 OpenAI 文本生成图像的 DALL·E 系列研究。
2021 年 1 月 6 日,OpenAI 博客发布了两个连接文本与图像的神经网络:DALL・E 和 CLIP。DALL・E 可以基于文本直接生成图像,CLIP 则能够完成图像与文本类别的匹配。这两项研究的发布,引起了社区极大的关注。
据博客介绍,DALL・E 可以将以自然语言形式表达的大量概念转换为恰当的图像,可以说是 GPT-3 的 120 亿参数版本,可基于文本描述生成图像。

DALL・E 示例。给出一句话「牛油果形状的椅子」,就可以获得绿油油、形态各异的牛油果椅子图像。
2 个月后,DALL·E 的论文和代码公开。

- 项目地址:https://github.com/openai/DALL-E
- 论文地址:https://arxiv.org/abs/2102.12092
2022 年 4 月 7 日左右,DALL・E 迎来了升级版本 ——DALL・E 2。与 DALL・E 相比,DALL・E 2 在生成用户描述的图像时具有更高的分辨率和更低的延迟。并且,新版本还增添了一些新的功能,比如对原始图像进行编辑。
OpenAI 还公布了 DALL・E 2 的研究论文《Hierarchical Text-Conditional Image Generation with CLIP Latents》。

论文地址:https://cdn.openai.com/papers/dall-e-2.pdf
此次必应接入的 DALL・E 应该是经过更新迭代的。这在一定程度上,弥补了当前 ChatGPT 在跨模态生成方面缺失的体验。不过等到 GPT-4 多模态能力开放后,也许能为我们带来更多新的体验。
最后提一句,今日还有一项生成式 AI 的发布引起了业内人士的关注与讨论。
那就是 Adobe 发布 Firefly。这是一系列用于创意表达的生成式 AI 模型,让用户可以通过键入命令快速修改图像。目前,Firefly 开放了测试版本,感兴趣的读者可以申请体验。

如今看来,生成式 AI 这场游戏有越来越多的玩家涌入,竞争也变得越来越激烈。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


