哈喽,大家好。
今天给大家分享一个开源的大语言模型ChatGLM-6B。
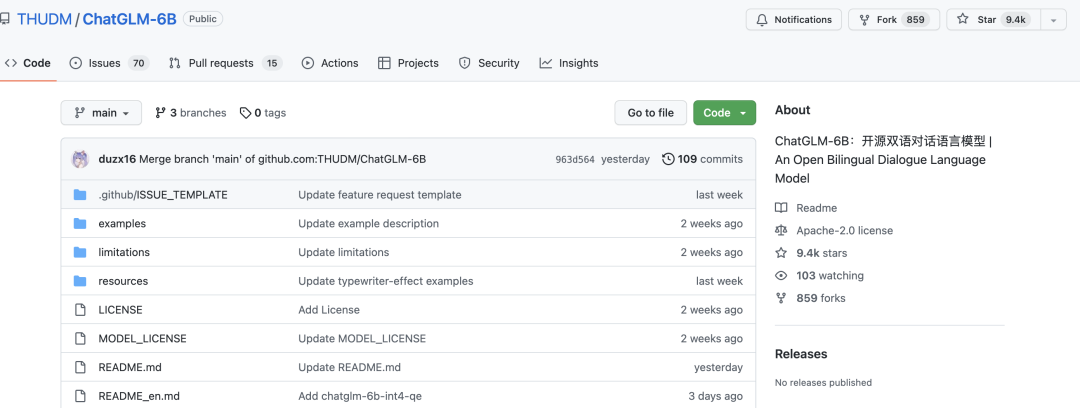
十几天的时间,就收获了近 1w 个 star。
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
大家都可以装在自己的电脑上运行下试试。独显最小显存6G,CPU电脑也可以跑,但很慢。
项目目前只开源了模型和推理代码,并没有开源模型的训练。
运行项目,只需两个
第一步,下载源码
git clone https://github.com/THUDM/ChatGLM-6B.git
执行pip install -r requirements.txt 安装依赖
第二步,运行项目
python web_demo.py
执行后,会自动下载模型文件,大概 4G 左右。
如果是GPU运行,默认情况下, 模型运行显存至少 13G,如果显存不够,可以修改下 web_demo.py
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
将上述代码的THUDM/chatglm-6b改为THUDM/chatglm-6b-int4,即:改用 int4 量化后的模型,只要是显存大于6g就可以顺利运行。
如果报 CPU 内存不足,把其他软件关一关,尤其是浏览器。
运行成功后, 会自动跳转浏览器页面,这时候就可以像ChatGPT一样使用了。
下面是我本地运行的结果,大家可以看看与ChatGPT的差异

自我认知

写提纲

写邮件

写代码

角色扮演
项目运行还是很简单的,大家可以跑跑试试。
如果大家觉得本文对你有用就点个 在看 鼓励一下吧,我会持续分享优秀的 Python+AI 项目。
© 版权声明
文章版权归作者所有,未经允许请勿转载。