ChatGPT是程序员的好帮手?还是要干掉程序员?
我觉得不仅要看它生成代码的能力,更关键的是要看它是否具备强大的设计能力。
设计能力有两个层面,一个是高层的,例如架构设计,系统设计。
一个是相对低层的设计能力,主要设计具体的类和接口。
今天我们看看它在这两个方面分别表现如何。
由于ChatGPT的回答特别啰嗦,我会删除一些细节,只保留重要部分。
出于公司保密的原因,没法用真实项目,只能用书籍中公开的案例来考考它。
一、架构设计
这里我使用的案例是客服工单系统,是从一本书《从程序员到架构师》中提取出来的,这本书有很多实战案例,顺便向大家推荐一下。
客服工单系统的大概需求是这样:
有个客服系统,用的MySQL数据库,每年产生的工单有3000多万条,每个工单会有5~6次操作,这些操作也要记录下来,这样每年就会有超过1.5亿条操作记录。
现在客服打开系统查看工单的时候,速度非常慢,10秒才能打开, 现在对SQL语句,索引等已经优化到了极致,无法再继续提升。
现在系统性能已经严重影响了客服的处理效率,客户要求一周之内解决这个问题,时间很短。
经过分析业务流程发现,工单如果处理完成,就会增加一个状态“关闭”,这样的工单,一年都打开不了几次。
团队没有用过数据库分区,一周内没有任何把握搞定,就放弃了数据库分区的方案。
对于这个问题,书中的解决方案是“冷热分离”,日常操作“热数据库”,把“关闭”的工单移入新的“冷数据库”,但是在数据冷热分离过程中,需要处理数据一致性问题。
把这个需求抛给GPT-4,看它如何回答。
GPT-4:在这种情况下,我建议采用以下两种方法来解决性能问题:
1.数据库归档:由于大部分已关闭的工单基本上不再需要访问,可以将这些工单数据从主数据库中移动到一个归档数据库中。这样,主数据库的大小将大大减小,从而提高查询速度。归档数据库可以定期(如每月或每季度)更新,将已关闭的工单移动到归档数据库中……
具体操作步骤如下:
a. 创建一个新的MySQL数据库,用于存储归档数据。
b. 编写一个脚本,定期将已关闭的工单及其相关操作记录从主数据 库移动到归档数据库,并确保数据一致性。
c. 修改客服系统,使其默认仅查询主数据库中的未归档数据。
d. 提供一个单独的界面或工具,供客服人员在需要时查询归档数据 库中的数据。
- 缓存:…略…
不错,它一下子就抓住了重点,给出了数据库归档的方案,还有具体的操作步骤。
不过,需求中有一定的提示,这个方案也容易想到。
刘欣:在你的操作步骤中,如何保证数据一致性,这里需要操作两个数据库啊
GPT-4 :确保数据一致性是非常重要的。在操作两个数据库时,可以采用以下方法来保证数据一致性:
- 使用事务:事务可以确保一组操作要么全部成功,要么全部失败。…..略….
刘欣:你在使用事务的时候,怎么能开启一个跨越两个数据库的事务?
GPT-4: 抱歉,我在之前的回答中确实犯了一个错误。在MySQL中,我们无法直接在两个不同的数据库之间使用单个事务。在这种情况下,可以考虑使用其他策略来确保数据一致性。一个可行的方法是使用“两阶段提交协议”(Two-Phase Commit, 2PC)。….略….
刘欣:两阶段提交协议很脆弱,有别的安全的办法来实现数据从主数据库移动到归档数据库吗?
GPT-4: 抱歉之前的方案没有完全满足您的需求。这里我提供一个新的方案,使用消息队列(例如RabbitMQ、Kafka或Amazon SQS)来确保数据迁移过程的一致性。这种方法可以将数据迁移过程分为两个独立的步骤,确保在出错时可以方便地回滚。…..略…..
刘欣:如果不使用MQ,完全自己写代码实现,如何保证数据迁移过程中的一致性?
GPT-4: 如果您不想使用消息队列,您可以使用以下方法自行编写代码来确保数据迁移过程中的一致性:
- 使用锁和标记字段:
a. 为工单表和操作记录表分别添加一个名为“is_migrated”的布尔字段,用于标记记录是否已迁移。
b. 编写一个脚本或程序,从主数据库中查询满足迁移条件(例如,已关闭的工单且“is_migrated”为false)的记录。
……略……
嗯,到此为之,它终于找到了一个方案,和书中有点类似,就是用一个字段来标记“是否已迁移”。
但是,无论我怎么提示,它也不会提出如何做幂等性的方案,我就放弃了。
刘欣:归档数据库数据量很大,查询非常慢,但查询基本上都是”根据客户ID查出工单,然后根据工单ID查出该工单所有的处理记录”,这有什么办法来解决?
GPT-4 :针对这种查询模式,可以采取以下策略来优化归档数据库的查询性能:
- 为客户ID和工单ID创建索引:……略……
- 数据库表分区:……略……
- 数据库视图:……略……
- 结果缓存:……略……
- 拆分读写负载:……略……
- 优化硬件和配置:……略……
这些方案都无法有效解决不了问题,正确的方案是用HBase这样的NoSQL数据库,它是想不到了。
二、详细设计
我使用的案例依然是薪水支付,这是从经典书《敏捷软件开发:原则,模式和实践》中提取出来的。
这个案例的需求是这样的:
该系统由一个公司数据库以及和员工相关的数据组成,系统需要准时地按照规则给员工支付薪水
员工有三种类型
1.钟点工,每个小时有固定报酬,他们每天提交工作时间卡,其中记录了日期以及工作小时数,如果每天工作超过8小时,按1.5倍进行支付。每周五对他们进行支付。
2.月薪员工,工资固定,每个月的最后一个工作日对他们进行支付
3.销售人员,有固定工资,但会根据他们的销售情况,支付给他们一定数量的佣金,他们会提交销售凭条,其中记录了销售的日期和数量。每隔一周的周五对他们进行支付。
员工可以选择支付方式,可以把支票邮寄到他们指定的邮政地址,也可以保存在财务那里随时支取,或者要求直接存入他们指定的银行账户。
看了这个需求以后,一般的设计是这样的:
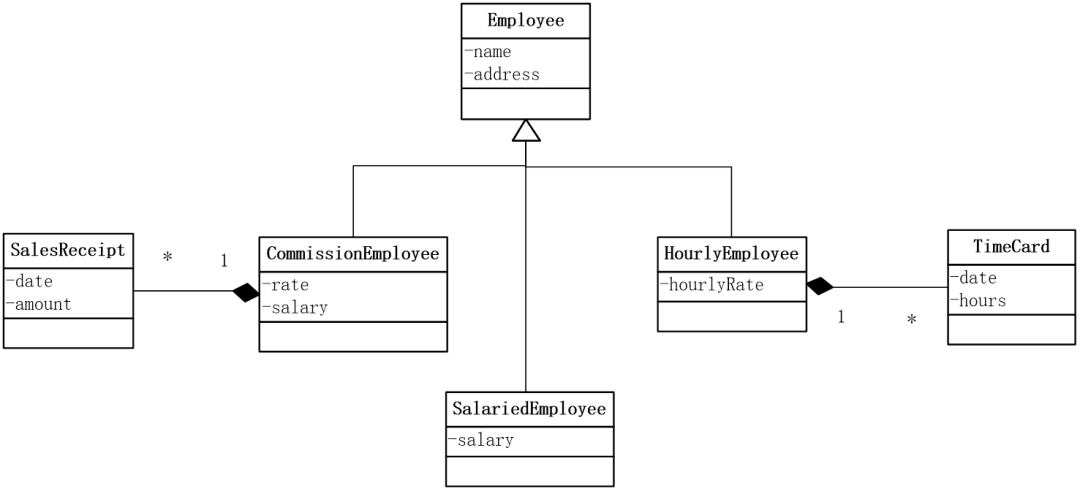
Employee 作为基类,不同类型的雇员类来继承。
但是这个需求会有变更,客户要求员工类型可以变更,例如从钟点工变成月薪雇员,这样上面的设计就不行了。
这个时候应该做个抽象,,用一个类PaymentClassification来表达支付分类,然后让Employee类持有这个实例,简单说就是用组合代替继承。
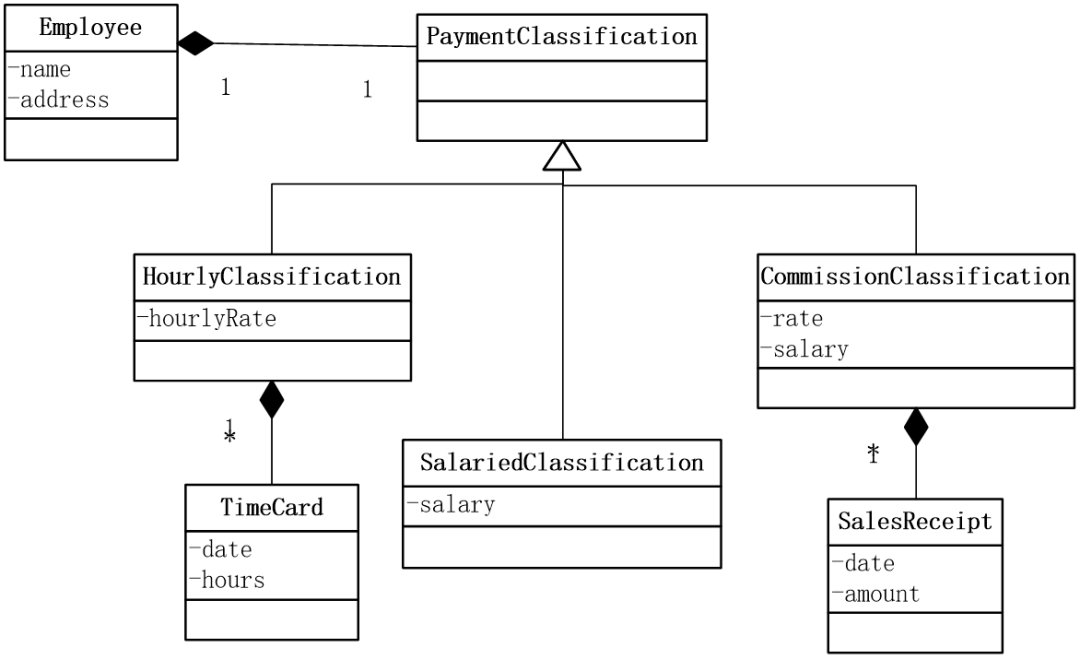
这是一个陷阱,也是给ChatGPT挖的一个坑,看看它是如何处理的。
正式开始,我把需求告诉它,让它设计。
没想到,它一上来就给我写Python代码,这太多细节了,我马上让它停止输出。
刘欣:不用展示代码,把类描述出来就可以。
GPT-4 : 好的,根据您的需求,我们可以设计以下类和相关的属性和方法:
- 基类 Employee: ……略……
- HourlyEmployee 类,继承自 Employee 类:……略……
- SalariedEmployee 类,继承自 Employee 类:……略……
- SalesEmployee 类,继承自 SalariedEmployee 类:……略……
- PaymentMethod 类:略
还真是不错,它“理解”了需求,从中抽取出了名词进行类的设计,它设计出来的Employee,HourlyEmployee,SalariedEmployee,SalesEmployee和第一个UML图几乎是一样的。
已经达到了面向对象设计的初级水平。
接下来开始挖坑:
刘欣:上面的类设计得很好,但是如果一个人刚开始是钟点工,后来变成了月薪员工,上面的设计就无法支持这种变更了,这该怎么办呢?
GPT-4 :为了解决您提到的问题,我们可以将员工的薪水计算策略从 Employee 类中分离出来,使用策略模式进行设计。这样,我们可以在不修改 Employee 类的情况下,为其动态更改薪水计算策略。
在这种设计下,我们需要对原来的类结构进行一些调整:
- 保留基类 Employee:
新增方法:set_salary_strategy,用于设置员工的薪水计算策略
- 移除原来的子类 HourlyEmployee、SalariedEmployee 和 SalesEmployee,因为我们将薪水计算策略从 Employee 类中分离出来。
- 新增抽象类 SalaryStrategy,作为薪水计算策略的基类
- 新增具体策略类:
HourlySalary 类,继承自 SalaryStrategy 类
SalariedSalary 类,继承自 SalaryStrategy 类
SalesSalary 类,继承自 SalaryStrategy 类
通过以上调整,现在可以在不修改 Employee 类的情况下为其动态更改薪水计算策略。当员工从钟点工变为月薪员工时,只需为其设置新的薪水计算策略即可。
不得不说,GPT-4非常厉害!
它用上了策略模式,把薪水计算策略SalaryStrategy给抽象了出来。
和第二个UML图相比,除了名称不同,基本上一样了。
可以说,能做到这一步,就可以超越很多程序员了。
我注意到,它一直没有处理支付周期的问题。我开始继续发问:
刘欣:原来的需求中还有支付的时间,例如钟点工每周五支付,这个该怎么设计?
GPT-4: 为了处理不同类型员工的支付时间,我们可以在 SalaryStrategy 基类中引入一个抽象方法 should_pay_today,该方法根据当前日期判断是否应该支付薪水。接着,在具体的策略类中实现这个方法。
……略……
这里它犯了一个错误,把支付周期放到了薪水计算策略中,还美名其曰“易于维护和扩展”。
刘欣:支付时间和薪水计算策略是两个概念,放在一起不太好,怎么才能达到最大的灵活性呢?
GPT-4 :您是对的,支付时间和薪水计算策略是两个不同的概念。为了使设计更具灵活性,我们可以将支付时间从薪水计算策略中分离出来,创建一个新的抽象类 PaymentSchedule,用于处理支付时间的逻辑。这样,我们可以为每个员工分别设置薪水计算策略和支付时间策略。
以下是调整后的类结构:
保留基类 Employee:
- 属性:姓名、ID、地址
方法:set_payment_method,用于设置员工的支付方式
方法:set_salary_strategy,用于设置员工的薪水计算策略
新增方法:set_payment_schedule,用于设置员工的支付时间策略
- 保留抽象类 SalaryStrategy 及其具体策略类,不做改动。
- 新增抽象类 PaymentSchedule,作为支付时间策略的基类:…略…
- 新增具体支付时间策略类,继承PaymentSchedule:
WeeklyPayment 类 …略…
MonthlyPayment 类 …略…
BiweeklyPayment 类 …略…
- 保留 PaymentMethod 类及其子类,不做改动。
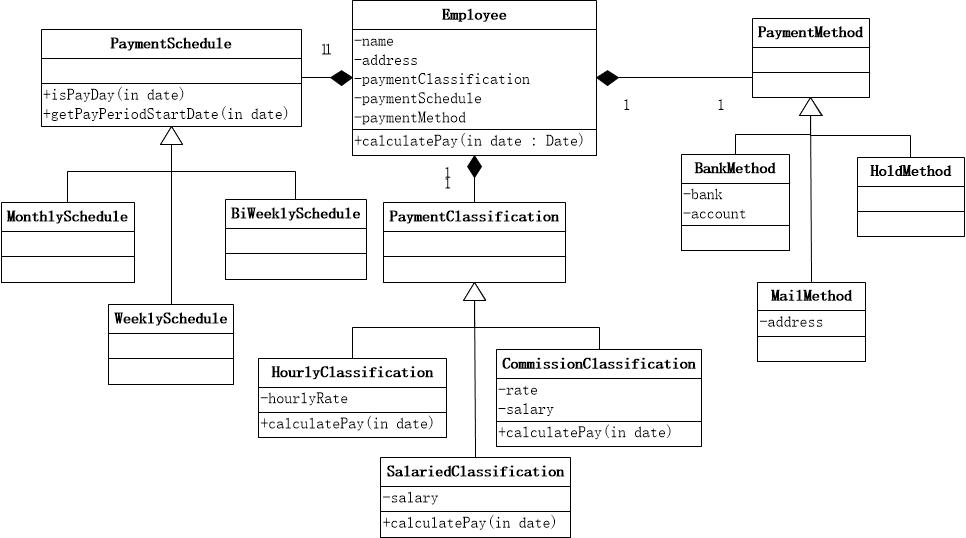
非常惊艳! 它似乎知道我脑海中所想,PaymentSchedule 和 SalaryStrategy 给分开了!
到目前为止,它已经实现了书中最终的,也可能是最好的设计:
三、小结
在详细设计层面上,GPT-4的表现远远强于架构设计。
码农翻身的老读者知道,我在去年用薪水支付案例测试过GPT-3.5, 当时它就是在背诵答案,甚至会给出超出需求之外的设计。
但是GPT-4不同了,它的设计能力更进了一步,在程序员的提示下,他已经学会了分离关注点。
在架构设计上,感觉GPT-4掌握了很多知识,但是无法有效地应用到复杂问题上,出的解决方案很混乱,离我们想要的还比较远。
更关键的问题是如何识别它的回答是正确的,我现在手头有标准答案,可以对它做考核。而在实际项目中,面对的都是未知数,如果没有经验,如何知道GPT-4给出的设计是有效的?是能解决问题的?
© 版权声明
文章版权归作者所有,未经允许请勿转载。