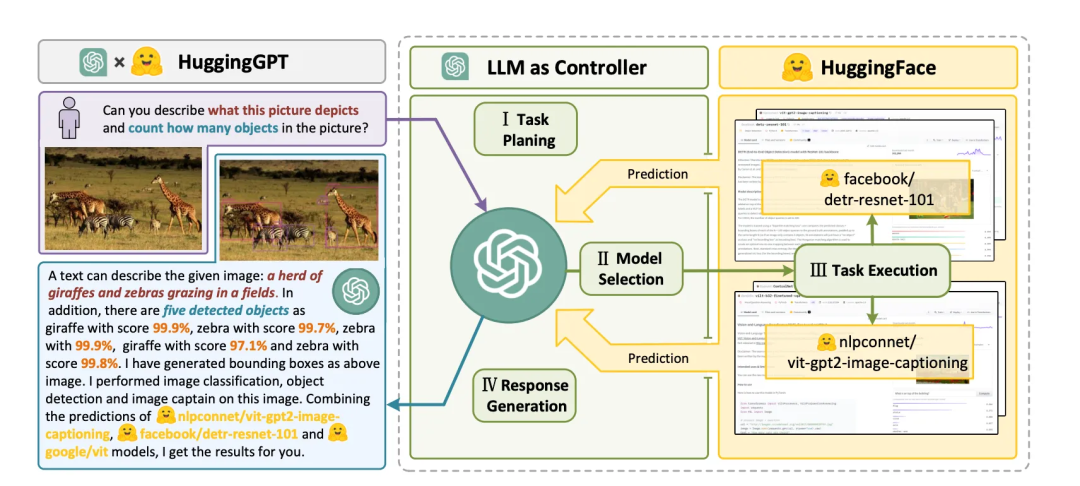
Nature|GPT-4被吹爆,科学家担忧溢屏!
GPT-4的横空出世,既让人兴奋,又让人沮丧。
尽管GPT-4拥有让人震惊的创造力,推理能力,但科学家们却对这项技术的安全性表示出担忧。
由于OpenAI违背初衷,并未开源GPT-4、公布模型的训练方法和数据,因此它的实际工作情况也无从得知。
科学界对此感到十分沮丧。
开源AI社区HuggingFace专门从事环境研究的科学家Sasha Luccioni表示,「OpenAI可以在他们的研究基础上继续发展,但对于整个社区来说,所有这些闭源模型,在科学上就像是一个死胡同。」

还好有红队测试
罗切斯特大学的化学工程师Andrew White作为 「红队」(red-teamer) 成员,享有访问GPT-4的特权。
OpenAI付钱给红队,让其负责测试平台,试图让它做一些坏事。所以Andrew White在过去的6个月里,一直有机会接触到GPT-4。
他向GPT-4提问,制造一种化合物需要哪些化学反应步骤,让其预测反应产量,并选择一种催化剂。
「与以前的迭代相比,GPT-4似乎没有什么不同,我也觉着没什么。但是后来它真的很令人惊讶,它看起来如此逼真,它会在这里幻化出一个原子,又在那里跳过一个步骤。」
但是当他继续测试,并让GPT-4访问论文时,事情发生了巨大的变化。
「我们突然意识到,这些模型也许并不是那么出色。但是当你开始将它们连接到像回溯合成计划器或计算器这样的工具时,突然间,新的能力出现了。」
随着这些能力的出现,人们开始担心。例如,GPT-4能否允许制造危险的化学品?
Andrew White表明,有了像White这样的红队人的测试投入,OpenAI的工程师们将其反馈到他们的模型中,就可以阻止GPT-4创造危险、非法或破坏性的内容。
虚假的事实
输出虚假信息是另一个问题。
Luccioni 说,像GPT-4这样的模型还无法解决它出现幻觉的问题,也就是说还会胡言乱语。
「你不能依赖这类模型,因为有太多的幻觉,尽管OpenAI说它在GPT-4中已经提高了安全性,这在最新版本中仍然是一个问题。」

由于无法获得用于训练的数据,OpenAI对安全性的保证在Luccioni看来是不够的。
「你不知道数据是什么。所以你无法改善它。用这样的模型做科学是完全不可能的。」
关于GPT-4如何训练,这一谜团也一直困扰着心理学家Claudi Bockting:「要人类去对你无法监督的东西负责,这是非常困难的。」
Luccioni 也认为GPT-4会被训练数据加深偏见,而如果不能访问GPT-4背后的代码,就不可能看到偏见可能起源于哪里,也不可能对其进行补救。
伦理讨论
科学家们对GPT一直持保留态度。
在ChatGPT推出时,科学家们就已经反对过GPT出现在作者栏里。

出版商们也都认为,ChatGPT等人工智能不符合研究作者的标准,因为它们不能对科学论文的内容和完整性负责。不过人工智能对撰写论文的贡献可以在作者名单以外的部分得到承认。
此外,人们还担心,这些人工智能系统越来越多地掌握在大型科技公司手中。这些技术应该得到科学家的测试和验证。
我们迫切需要制定一套指导方针,来管理人工智能和GPT-4等工具的使用和发展。
White说,尽管有这样的担忧,GPT-4及其未来的迭代将撼动科学:「我认为它将成为科学领域的一个巨大的基础设施变化,就像互联网一样的巨大的变化。我们开始意识到,我们可以连接论文、数据程序、图书馆、计算工作甚至机器人实验。它不会取代科学家,但可以帮助完成一些任务。」
但是,似乎围绕人工智能技术的任何立法难以跟上发展的步伐。
4月11日,阿姆斯特丹大学将召开一次邀请性峰会,与来自联合国教科文组织科学伦理委员会、经济合作与发展组织和世界经济论坛等组织的代表讨论这些问题。
主要话题包括坚持对LLM输出进行人工检查;在科学界内,相互建立问责规则,旨在实现透明度、诚信和公平;投资由独立非营利组织拥有的可靠和透明的大语言模型;拥抱 AI 的优势,但是必须在人工智能的好处和失去自主性之间做出权衡;邀请科学界与相关方(从出版商到伦理学家)讨论GPT等等。
© 版权声明
文章版权归作者所有,未经允许请勿转载。