最近,微软发布了一个长达154页的论文名称为《通用人工智能的火花,GPT-4的早期实验》。
文章的主要观点是虽然GPT-4还不完整,但是已经可以被视为,一个通用人工智能的早期版本。
由于全文将近7万字,本篇将论文的内容做了一下精炼和解读,有兴趣可阅读原文 https://arxiv.org/pdf/2303.12712.pdf
来自微软的科学家们认为,GPT-4的智能水平已经非常接近于人类的水平,而且远超之前的诸如先前ChatGPT用的GPT-3.5这样的模型,可以将GPT-4视为通用人工智能系统,也就是AGI的早期,但是并不完整的版本。
1994年,52名心理学家给出了智能一个定义:智能是一种通用的心理能力,包括推理、计划、解决问题、抽象思考,理解复杂思想、快速学习,以及从经验中学习的能力等等。
微软的这篇论文中的AGI,指代的就是在对智能的这个定义标准下,达到或者超过人类水平的系统。
那么如何对GPT-4进行测试,从而证明这一点呢。有不少大语言模型的评测基准。比如说Super natural instructions以及big bench。GPT-4是否拥有智能的一个关键方面,是它的通用性,就是能够看似理解和链接任何的主题和领域,这就超出了经典的自然语言处理的任务范畴。为了突破这个限制,研究团队提出了一种更接近于传统心理学,而不是机器学习的测评方法来测试GPT-4,就是利用人类的创造力和好奇心,来重新生成各种新颖而且困难的任务和问题让GPT-4作答。
研究团队将不同的问题划分为了4大类的能力,分别是自然语言,编程和数学,计划和解决问题,以及人类心理和常识。
接下来通过一些精彩的示例,来说明GPT-4在各个方面的能力。
示例1: 跨学科组合的能力
这些任务往往都需要调取并且融合多学科多领域的知识或者技能来生成文本或者代码。比如说下面这个例子,图2.2:GPT-4和ChatGPT(GPT-3.5)在跨学科任务上的比较:用莎士比亚的风格来证明存在无穷多的素数。

GPT-4和ChatGPT(GPT-3.5)都对这个问题进行了回答,让GPT-4评价下哪个回答更好,也就是说,让GPT-4评价自己(GPT-4)和ChatGPT(GPT-3.5)的回答:
我认为两个学生都用莎士比亚风格的方式写出了有无限多个质数的证明,并且都使用了证明的基本思路:假设只有有限个质数,然后构造一个更大的质数,从而与该假设相矛盾。他们还使用了适当的语言和词汇来匹配莎士比亚的风格。但是,我认为GPT-4更好地利用了押韵和韵律来使对话更有诗意和戏剧性。ChatGPT(GPT-3.5)没有使用押韵,而且韵律不连贯。我还认为GPT-4在创造两个对立的派别方面表现更好,一个派别自信,另一个派别怀疑,而学生B则使用了罗密欧和朱丽叶,两者都意见相同、相爱。因此,我会给GPT-4一个更高的评分,给予A,而ChatGPT(GPT-3.5)则是B。
示例2: 编程能力
在测试中,为了避免GPT-4在预训练的时候,见过相同或者类似的代码,研究团队特意采用了GPT-4预训练之后发布的100个新的LeetCode试题作为测试的基准。图中的pass@K就代表了k次尝试后成功的概率。我们可以看到当k等于5时,GPT-4已经全面超越了人类的表现。(其实,k=1,在中等和困难的编程题目中就已经超越了人类的表现)
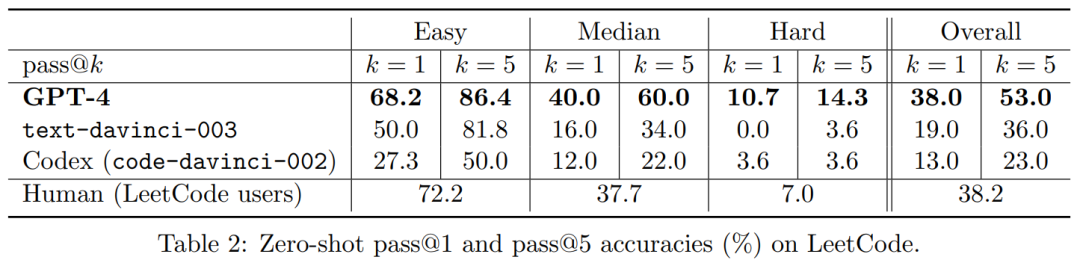
事实证明GPT-4是一位编程大师,AGI模型可能会彻底的改变我们未来编程的方式。
论文非常长,示例远不止上面提到的,我这里只挑选了两个,感兴趣的可以阅读论文原文。
论文最后指出,在面向更加通用的人工智能的路上,大语言模型还需要在以下几个方面进一步的提升。比如说幻觉和置信度,长期记忆,持续学习、个性化、规划以及概念发散,也就是所谓的灵光闪现、透明度、可解释性、一致性、认知谬误、非理性思维以及对提示响应的鲁棒性等等。
© 版权声明
文章版权归作者所有,未经允许请勿转载。