时间线
2018 年 6 月
OpenAI发布GPT-1模型,1.1亿参数。
2018 年 11 月
OpenAI发布GPT-2模型,15亿参数,但由于担心滥用,不向公众开放模型的全部代码及数据。
2019 年 2 月
OpenAI开放了GPT-2模型的部分代码和数据,但仍然限制了访问。
2019 年 6 月 10 日
OpenAI发布GPT-3模型,1750亿参数,并向部分合作伙伴提供了访问权限。
2019 年 9 月
OpenAI开放了GPT-2的全部代码和数据,并发布了更大版本。
2020 年 5 月
OpenAI宣布推出GPT-3模型的beta版本,该模型拥有1750亿个参数,是迄今为止最大的自然语言处理模型。
2022 年 3 月
OpenAI发布InstructGPT,用到 Instruction Tuning
2022 年 11 月 30 日
OpenAI通过GPT-3.5系列大型语言模型微调而成的,全新对话式AI模型ChatGPT正式发布。
2022 年 12 月 15 日
ChatGPT 第一次更新,提升了总体性能,增加了保存和查看历史对话记录的新功能。
2023 年 1 月 9 日
ChatGPT 第二次更新,改善了回答的真实性,增加了“停止生成”新功能。
2023 年 1 月 21 日
OpenAI发布限于部分用户使用的付费版ChatGPT Professional。
2023 年 1 月 30 日
ChatGPT第三次更新,在此提升了答案真实性的同时,还提升了数学能力。
2023 年 2 月 2 日
OpenAI正式推出ChatGPT收费版订阅服务,新版本对比免费版响应速度更快,运行更为稳定。
2023 年 3 月 15 日
OpenAI震撼推出了大型多模态模型GPT-4,不仅能够阅读文字,还能识别图像,并生成文本结果,现已接入ChatGPT 向Plus用户开放。
GPT-1:基于单向Transformer的预训练模型
在 GPT 出现之前,NLP 模型主要是基于针对特定任务的大量标注数据进行训练。这会导致一些限制:
大规模高质量的标注数据不易获得;
模型仅限于所接受的训练,泛化能力不足;
无法执行开箱即用的任务,限制了模型的落地应用。
为了克服这些问题,OpenAI走上了预训练大模型的道路。GPT-1是由OpenAI于2018年发布的第一个预训练模型,它采用了单向Transformer模型,并使用了超过40GB的文本数据进行训练。GPT-1的关键特征是:生成式预训练(无监督)+判别式任务精调(有监督)。先用无监督学习的预训练,在 8 个 GPU 上花费 了1 个月的时间,从大量未标注数据中增强AI系统的语言能力,获得大量知识,然后进行有监督的微调,与大型数据集集成来提高系统在NLP任务中的性能。GPT-1在文本生成和理解任务上表现出了很好的性能,成为了当时最先进的自然语言处理模型之一。
GPT-2:多任务预训练模型
由于单任务模型缺乏泛化性,并且多任务学习需要大量有效训练对,GPT-2在GPT-1的基础上进行了扩展和优化,去掉了有监督学习,只保留了无监督学习。GPT-2采用了更大的文本数据和更强大的计算资源进行训练,参数规模达到了1.5亿,远超过GPT-1的1.1亿参数。除了使用更大的数据集和更大的模型去学习,GPT-2还提出了一个新的更难的任务:零样本学习(zero-shot),即将预训练好的模型直接应用于诸多的下游任务。GPT-2在多项自然语言处理任务上表现出了卓越的性能,包括文本生成、文本分类、语言理解等。

GPT-3:创造出新的自然语言生成和理解能力
GPT-3是GPT系列模型中最新的一款模型,采用了更大的参数规模和更丰富的训练数据。GPT-3的参数规模达到了1.75万亿,是GPT-2的100倍以上。GPT-3在自然语言生成、对话生成和其他语言处理任务上表现出了惊人的能力,在一些任务上甚至能够创造出新的语言表达形式。
GPT-3提出了一个非常重要的概念:情境学习(In-context learning),具体内容会在下次推文中进行解释。
InstructGPT & ChatGPT
InstructGPT/ChatGPT的训练分成3步,每一步需要的数据也有些许差异,下面我们分别介绍它们。
从一个预训练的语言模型开始,应用以下三个步骤。
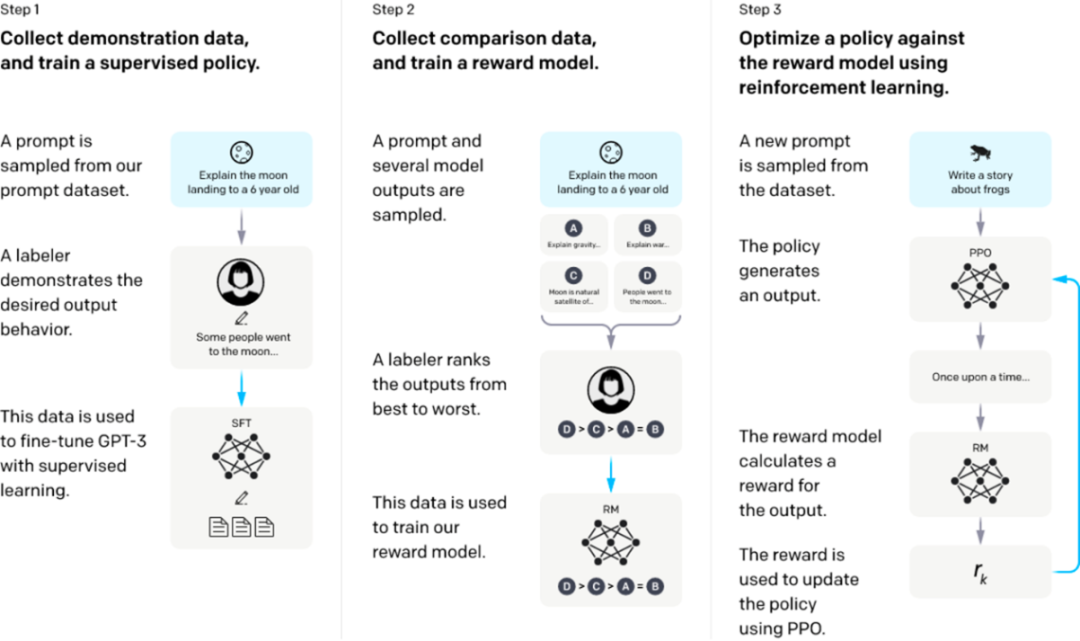
步骤1:监督微调SFT:收集演示数据,训练一个受监督的策略。我们的标签器提供了输入提示分布上所需行为的演示。然后,我们使用监督学习在这些数据上对预训练的GPT-3模型进行微调。
步骤2:奖励模型Reward Model训练。收集比较数据,训练一个奖励模型。我们收集了一个模型输出之间比较的数据集,其中标签者表示他们更喜欢给定输入的哪个输出。然后我们训练一个奖励模型来预测人类偏好的输出。
步骤3:通过奖励模型上的近端策略优化(PPO)强化学习:使用RM的输出作为标量奖励。我们使用PPO算法对监督策略进行微调,以优化该奖励。
步骤2和步骤3可以连续迭代;在当前最优策略上收集更多的比较数据,这些数据用于训练一个新的RM,然后是一个新的策略。
前两步的prompts,来自于OpenAI的在线API上的用户使用数据,以及雇佣的标注者手写的。最后一步则全都是从API数据中采样的,InstructGPT的具体数据:
1. SFT数据集
SFT数据集是用来训练第1步有监督的模型,即使用采集的新数据,按照GPT-3的训练方式对GPT-3进行微调。因为GPT-3是一个基于提示学习的生成模型,因此SFT数据集也是由提示-答复对组成的样本。SFT数据一部分来自使用OpenAI的PlayGround的用户,另一部分来自OpenAI雇佣的40名标注工(labeler)。并且他们对labeler进行了培训。在这个数据集中,标注工的工作是根据内容自己编写指示。
2. RM数据集
RM数据集用来训练第2步的奖励模型,我们也需要为InstructGPT/ChatGPT的训练设置一个奖励目标。这个奖励目标不必可导,但是一定要尽可能全面且真实的对齐我们需要模型生成的内容。很自然的,我们可以通过人工标注的方式来提供这个奖励,通过人工对可以给那些涉及偏见的生成内容更低的分从而鼓励模型不去生成这些人类不喜欢的内容。InstructGPT/ChatGPT的做法是先让模型生成一批候选文本,让后通过labeler根据生成数据的质量对这些生成内容进行排序。
3. PPO数据集
InstructGPT的PPO数据没有进行标注,它均来自GPT-3的API的用户。既又不同用户提供的不同种类的生成任务,其中占比最高的包括生成任务(45.6%),QA(12.4%),头脑风暴(11.2%),对话(8.4%)等。
附 录:
ChatGPT 的各项能力来源:
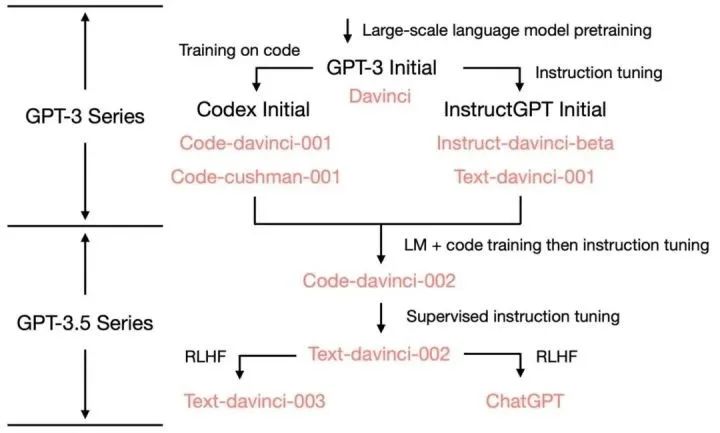
GPT-3 到 ChatGPT 以及这之间的迭代版本的能力和训练方法:

参考文献
1、拆解追溯 GPT-3.5 各项能力的起源:https://yaofu.notion.site/GPT-3-5-360081d91ec245f29029d37b54573756
2、全网最全时间线梳理!从ChatGPT的前世今生,到如今AI领域的竞争格局https://www.bilibili.com/read/cv22541079
3、GPT-1论文:Improving Language Understanding by Generative Pre-Training, OpenAI.
4、GPT-2论文:Language Models are Unsupervised Multitask Learners, OpenAI.
5、GPT-3论文:Language Models are Few-Shot Learners, OpenAI.
6、Jason W, Maarten B, Vincent Y, et al. Finetuned Language Models Are Zero-Shot Learners[J]. arXiv preprint arXiv: 2109.01652, 2021.
7、OpenAI是如何“魔鬼调教” GPT的?——InstructGPT论文解读 https://cloud.tencent.com/developer/news/979148
© 版权声明
文章版权归作者所有,未经允许请勿转载。