
哈喽,大家好。
之前给大家分享过一次配料表识别程序,这次我们用ChatGPT改造一下。
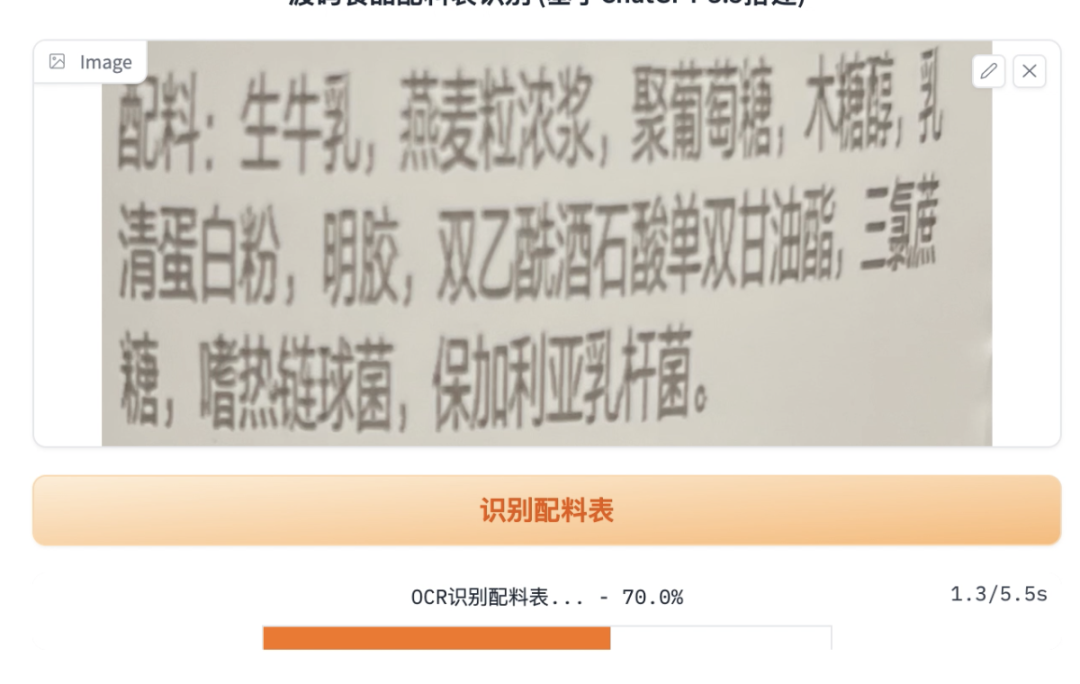
之前的大致思路是,用OCR识别配料表文字,然后开发一个爬虫,爬取每种配料的详细信息(爬百度百科)。
这次的程序不两个不同的地方,第一,配料详情调用ChatGPT获取,免爬取,结果更精准。
第二,web开发框架用gradio,gradio和streamlit类似,都是为了方便AI人员能快速构建web app的框架。
源码已经打包好,大家见文末。
简单贴下核心代码
1. ocr识别
ocr识别使用paddle
def __init__(self):
self.paddle_ocr = PaddleOCR(use_angle_cls=False, lang="ch")
def ocr(self, img):
result = self.paddle_ocr.ocr(img, cls=True)
ocr可以直接用预训练模型,也可以自己训练一个文字识别模型。之前都有介绍过,这里不再赘述了。
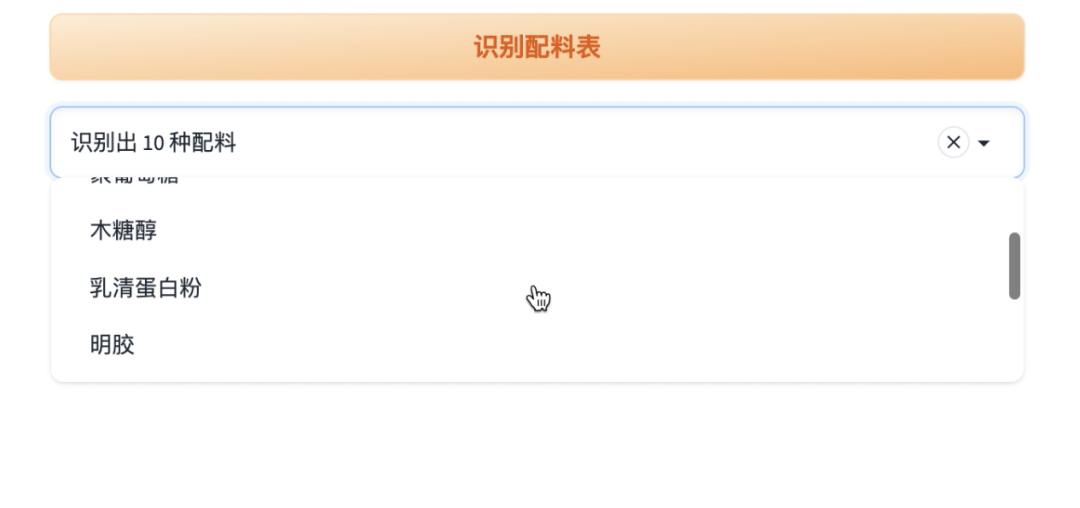
2. 获取配料详情
用下拉列表展示识别出来的配料
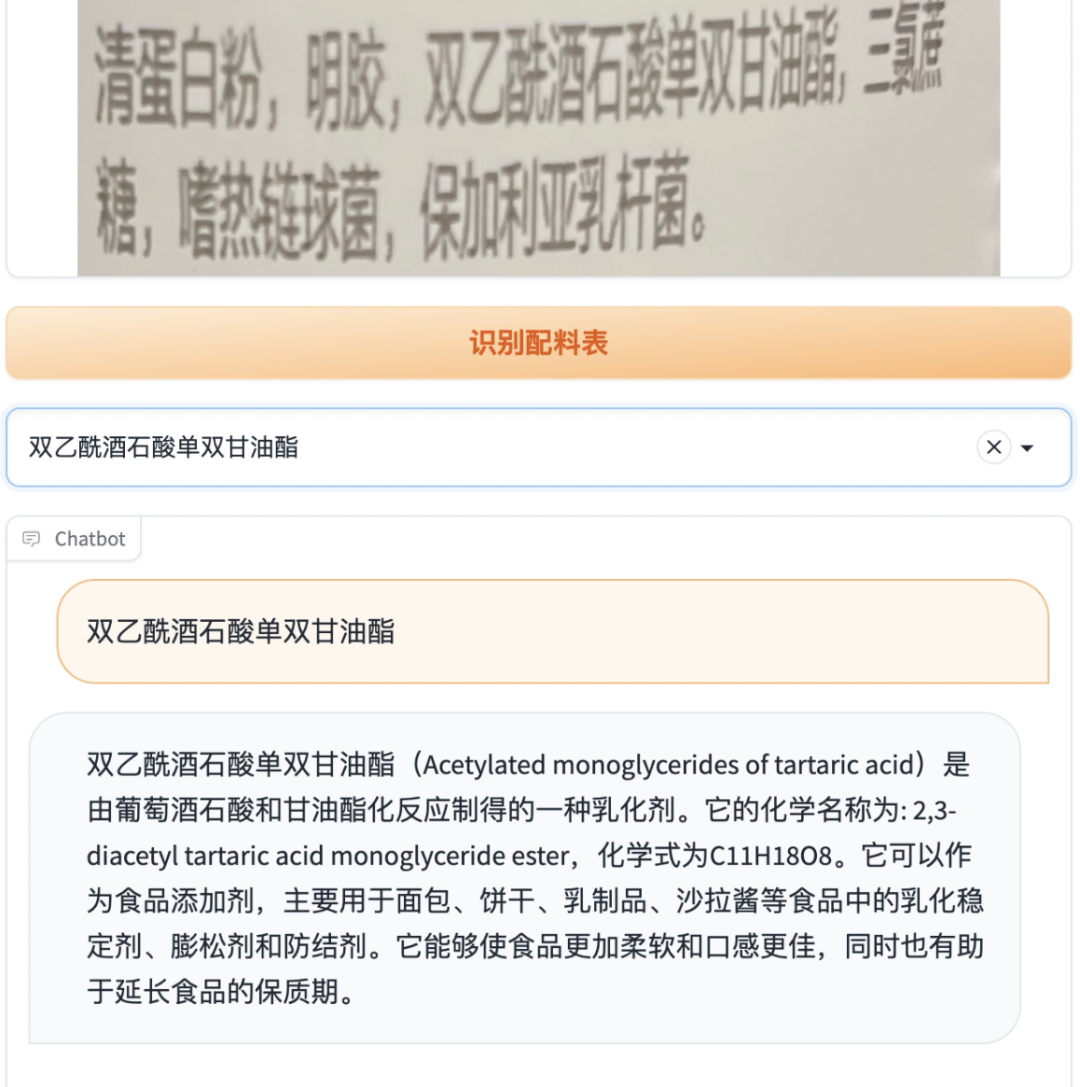
点击每种配料,调用ChatGPT的api获取配料详情
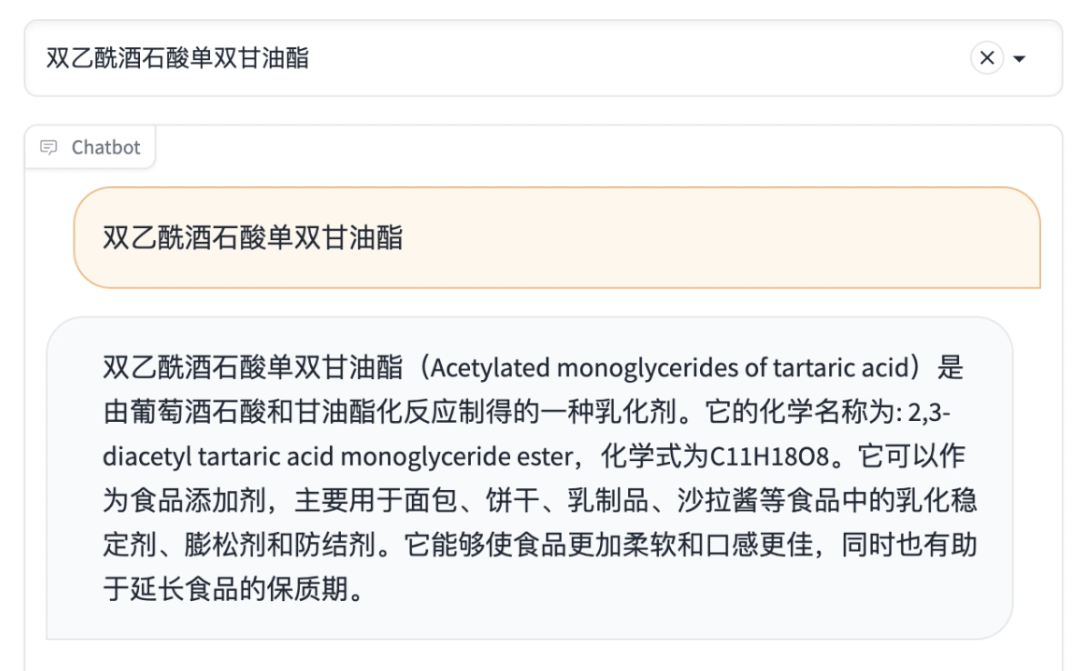
也可以多做一个对话框,支持跟ChatGPT进一步交流
使用ChatGPT还需要魔法和api key,大家需要自行解决。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


