国际学习表征会议 ICLR(International Conference on Learning Representations),被公认为当前最具影响力的机器学习国际学术会议之一。
在今年的 ICLR 2023 大会上,微软亚洲研究院发表了在机器学习鲁棒性、负责任的人工智能等领域的最新研究成果。
其中,微软亚洲研究院与韩国科学技术院(KAIST)在双方学术合作框架下的科研合作成果,因出色的清晰性、洞察力、创造力和潜在的持久影响获评 ICLR 2023 杰出论文奖。

论文地址:https://arxiv.org/abs/2303.14969
VTM:首个适配所有密集预测任务的小样本学习器
密集预测任务是计算机视觉领域的一类重要任务,如语义分割、深度估计、边缘检测和关键点检测等。对于这类任务,手动标注像素级标签面临着难以承受的巨额成本。因此,如何从少量的标注数据中学习并作出准确预测,即小样本学习,是该领域备受关注的课题。近年来,关于小样本学习的研究不断取得突破,尤其是一些基于元学习和对抗学习的方法,深受学术界的关注和欢迎。
然而,现有的计算机视觉小样本学习方法一般针对特定的某类任务,如分类任务或语义分割任务。它们通常在设计模型架构和训练过程中利用特定于这些任务的先验知识和假设,因此不适合推广到任意的密集预测任务。微软亚洲研究院的研究员们希望探究一个核心问题:是否存在一种通用的小样本学习器,可以从少量标记图像中学习任意段未见过的密集预测任务。
一个密集预测任务的目标是学习从输入图像到以像素为单位注释的标签的映射,它可以被定义为:
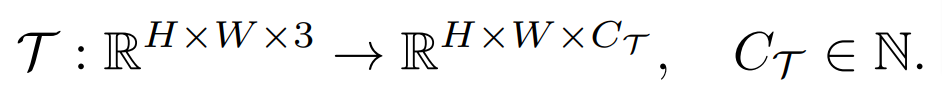
其中 H 和 W 分别是图像的高与宽,输入图像一般包含 RGB 三个通道,C_Τ 表示输出通道的数目。不同的密集预测任务可能涉及不同的输出通道数目和通道属性,如语义分割任务的输出是多通道二值的,而深度估计任务的输出是单通道连续值的。一个通用的小样本学习器 F,对于任何这样的任务 Τ,在给定少量标记样本支持集 S_Τ(包含了 N 组样本 X^i 和标注 Y^i)的情况下,可以为未见过的查询图像 X^q 产生预测,即:
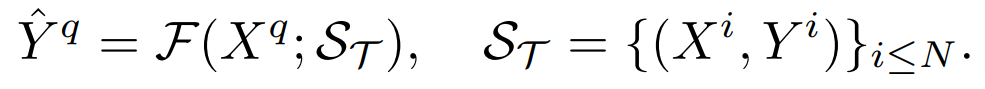
如果存在适配任意密集预测任务的通用小样本学习器,那么必须满足以下期望:
- 首先,它必须具备 e 统一的体系结构。该结构能够处理任意密集预测任务,并共享大多数任务所需的参数,以便获取可泛化的知识,从而能以小量样本学习任意未见过的任务。
- 其次,学习器应该灵活地调整其预测机制,以解决具有各种语义的未见过的任务,同时足够高效,以防止过度拟合。
因此,微软亚洲研究院的研究员们设计并实现了小样本学习器视觉token匹配 VTM(Visual Token Matching),其可用于任意的密集预测任务。这是首个适配所有密集预测任务的小样本学习器,VTM 为计算机视觉中密集预测任务的处理以及小样本学习方法打开了全新的思路。该工作获得了 ICLR 2023 杰出论文奖。
VTM 的设计灵感源于类比人类的思维过程:给定一个新任务的少量示例,人类可以根据示例之间的相似性快速将类似的输出分配给类似的输入,同时也可以根据给定的上下文灵活变通输入和输出之间在哪些层面相似。研究员们使用基于图像块(patch)级别的非参数匹配实现了密集预测的类比过程。通过训练,模型被启发出了捕捉图像块中相似性的能力。
给定一个新任务的少量标记示例,VTM 首先会根据给定的示例以及示例的标签调整其对相似性的理解,从示例图像块中锁定与待预测图像块相似的图像块,通过组合它们的标签来预测未见过的图像块的标签。
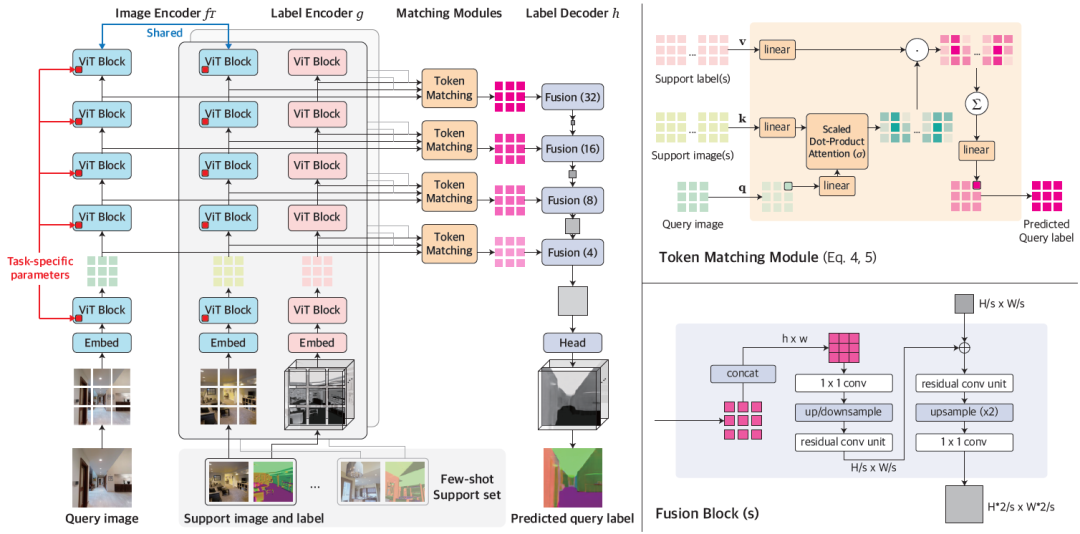
图1:VTM 的整体架构
VTM 采用分层的编码器-解码器架构,在多个层次上实现了基于图像块的非参数匹配。它主要由四个模块组成,分别为图像编码器 f_Τ、标签编码器 g、匹配模块和标签解码器 h。给定查询图像和支持集,图像编码器首先会独立地提取每个查询和支持图像的图像块级表达。标签编码器也会类似地提取每个支持标签的标记。在每个层次的标记给定后,匹配模块会执行非参数匹配,最终由标签解码器推断出查询图像的标签。
VTM 的本质是一个元学习方法。其训练由多个 episode 组成,每个 episode 模拟一个小样本学习问题。VTM 训练运用到了元训练数据集 D_train,其中包含多种有标签的密集预测任务示例。每个训练 episode 都会模拟数据集中特定任务 T_train 的小样本学习场景,目标是在给定支持集的条件下,为查询图像产生正确的标签。通过多个小样本学习的经验,模型能够学习到通用的知识,以便快速、灵活地适应新的任务。在测试时,模型需要在训练数据集 D_train 中未包含的任意任务 T_test 上进行小样本学习。
在处理任意任务时,由于元训练和测试中的每个任务的输出维度 C_Τ 不同,因此使得为所有任务设计统一的通用模型参数成为了巨大挑战。为了提供一个简单而普适的解决方案,研究员们将任务转换为 C_Τ 个单通道子任务,分别学习每个通道,并使用共享的模型 F 独立地对每个子任务进行建模。
为了测试 VTM ,研究员们还特别构建了 Taskonomy 数据集的一个变种,从而模拟未见过的密集预测任务的小样本学习。Taskonomy 包含各种标注过的室内图像,研究员们从中选择了十个具有不同语义和输出维度的密集预测任务,将其分为五部分用于交叉验证。在每个拆分方式中,两个任务用于小样本评估(T_test),其余八个任务用于训练(T_train)。研究员们仔细构造了分区,使得训练和测试任务彼此有足够的差异,例如将边缘任务(TE,OE)分组为测试任务,以便对新语义的任务进行评估。
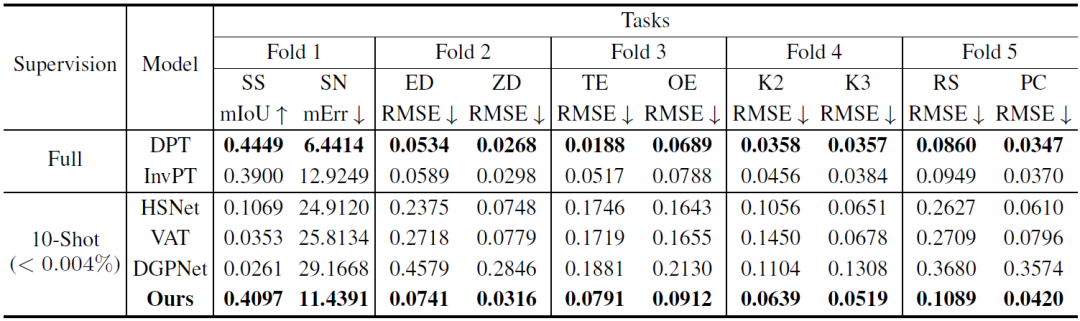
表1:在 Taskonomy 数据集上的定量比较( Few-shot 基线在训练了来自其他分区的任务后,在需测试的分区任务上进行了 10-shot 学习,其中完全监督的基线在每个 fold(DPT)或所有 fold(InvPT)上训练和评估了任务)
表1和图2分别定量与定性地展示了 VTM 和两类基线模型在十个密集预测任务上的小样本学习性能。其中,DPT 和 InvPT 是两种最先进的监督学习方法,DPT 可独立地针对每个单一任务进行训练,而 InvPT 则可以联合训练所有任务。由于在 VTM 之前还没有针对通用密集预测任务开发的专用小样本方法,因此研究员们将 VTM 与三种最先进的小样本分割方法,即 DGPNet、HSNet 和 VAT,进行对比,并把它们拓展到处理密集预测任务的一般标签空间。VTM 在训练期间没有访问测试任务 T_test,并且仅在测试时使用了少量(10张)的标记图像,但它却在所有小样本基线模型中表现得最好,并且在许多任务中的表现都具备与全监督基线模型比较的竞争力。
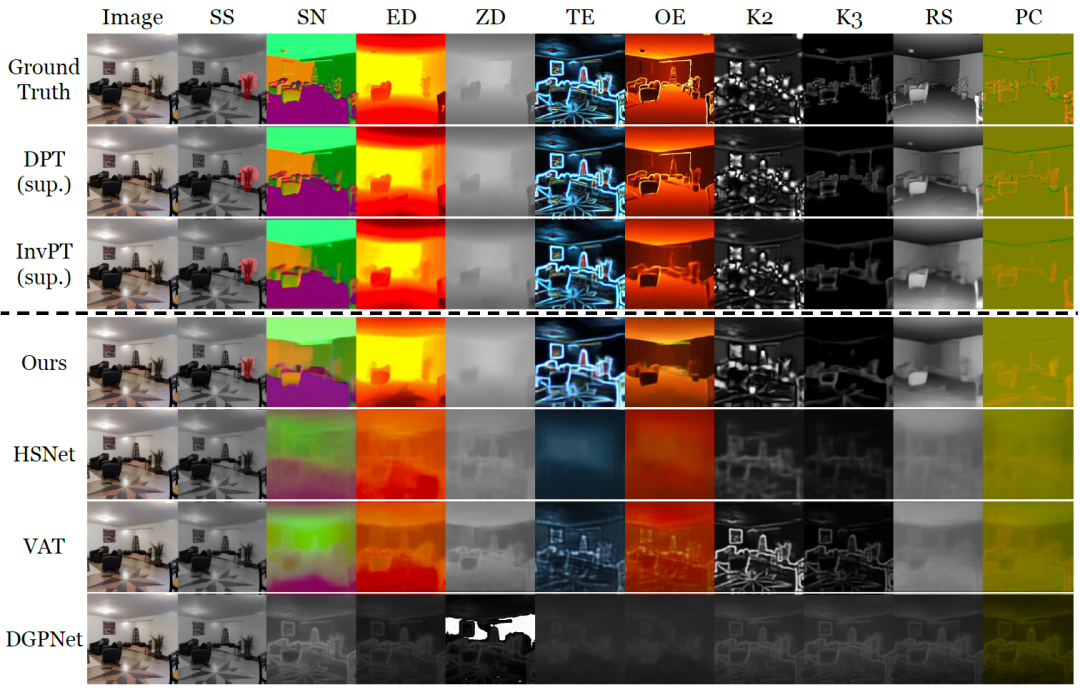
图2:在 Taskonomy 的十个密集预测任务中,在新任务上仅提供十张标记图像的小样本学习方法的定性比较。在其他方法失败的情况下, VTM 成功地学习了所有具有不同语义和不同标签表示的新任务。
在图2中,虚线上方的分别是真实标签和两种监督学习方法 DPT 和 InvPT。虚线下方的是小样本学习方法。值得注意的是,其他小样本基线在新任务上出现了灾难性的欠拟合,而 VTM 成功地学习了所有任务。实验说明,VTM 可以在极少量的标记示例(<0.004%的完全监督)上现表现出与完全监督基线类似的竞争力,并能够在相对较少的附加数据(0.1%的完全监督)下缩小与监督方法的差距,甚至实现反超。
总结来说,尽管 VTM 的底层思路非常简单,但它具有统一的体系结构,可用于任意密集预测任务,因为匹配算法本质上包含所有任务和标签结构(例如,连续或离散)。此外,VTM 仅引入了少量的任务特定参数,就能具备抗过拟合性与灵活性。未来研究员们希望进一步探究预训练过程中的任务类型、数据量、以及数据分布对模型泛化性能的影响,从而帮助我们构建一个真正普适的小样本学习器。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


