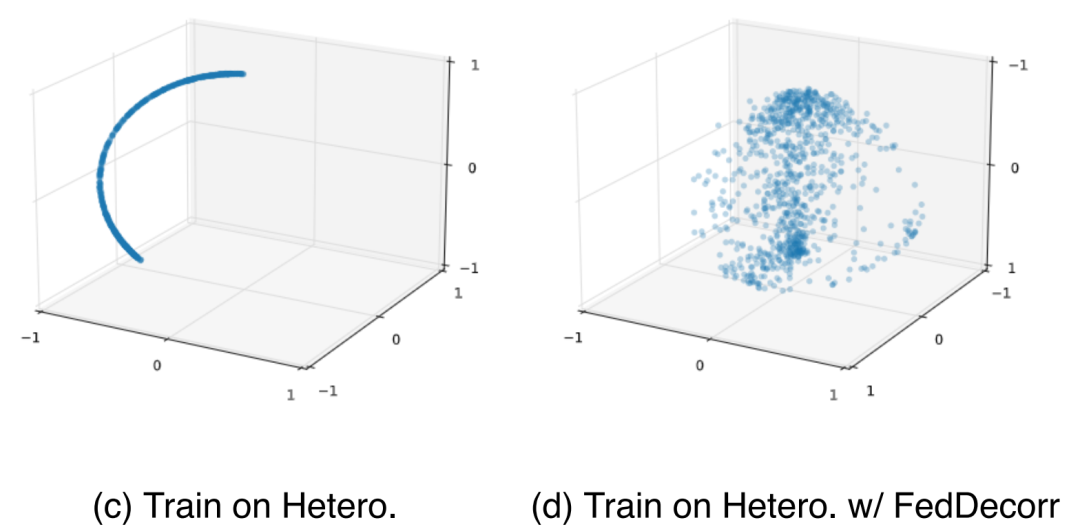
2017年,谷歌团队在论文「Attention Is All You Need」提出了开创性的NLP架构Transformer,自此一路开挂。
多年来,这一架构风靡微软、谷歌、Meta等大型科技公司。就连横扫世界的ChatGPT,也是基于Transformer开发的。
而就在今天,Transformer在GitHub上星标破10万大关!

Hugging Face,最初只是一个聊天机器人程序,因其作为Transformer模型的中心而声名鹊起,一举成为闻名世界的开源社区。
为了庆祝这一里程碑,Hugging Face也总结了100个基于Transformer架构搭建的项目。
Transformer引爆机器学习圈
2017年6月,谷歌发布「Attention Is All You Need」论文时,或许谁也没有想到这个深度学习架构Transformer能够带来多少惊喜。
从诞生至今,Transformer已经成为AI领域的基石王者。19年,谷歌还专门为其申请了专利。

随着Transformer在NLP领域占据了主流地位,还开始了向其他领域的跨界,越来越多的工作也开始尝试将其引到CV领域。
看到Transformer突破这一里程碑,许多网友甚是激动。

「我一直是许多受欢迎的开源项目的贡献者,但看到Transformer在GitHub上达到10万颗星,还是很特别的!」

前段时间Auto-GPT的GitHub星量超过了pytorch引起了很大的轰动。
网友不禁好奇Auto-GPT和Transformer相比呢?

其实,Auto-GPT远远超过了Transformer,已经有13万星。

目前,Tensorflow有17多万星。可见,Transformer是继这两个项目之后,第三个星标破10万的机器学习库。
还有网友回忆起了最初使用Transformers库时,那时的名字叫「pytorch-pretrained-BERT」。
基于Transformer的50个超赞项目
Transformers不仅是一个使用预训练模型的工具包,它还是一个围绕Transformers和Hugging Face Hub构建的项目社区。
在下面列表中,Hugging Face总结了100个基于Transformer搭建的让人惊叹的新颖项目。

以下,我们节选了前50个个项目进行介绍:
gpt4all
gpt4all是一个开源聊天机器人生态系统。它是在大量干净的助手数据集合上训练出来的,包括代码、故事和对话。它提供开源的大型语言模型,如LLaMA和GPT-J,以助理的方式进行训练。
关键词: 开源,LLaMa,GPT-J,指令,助手

recommenders
这个存储库包含构建推荐系统的示例和最佳实践,以Jupiter笔记本形式提供。它涵盖了建立有效推荐系统所需的几个方面: 数据准备、建模、评估、模型选择和优化,以及操作化。
关键词:推荐系统,AzureML
lama-cleaner
基于Stable Diffusion技术的图像修复工具。可以从图片中擦出任何你不想要的物体、缺陷、甚至是人,并替换图片上的任何东西。
关键词:修补,SD,Stable Diffusion

flair
FLAIR是一个强大的PyTorch自然语言处理框架,可以转换几个重要的任务:NER、情感分析、词性标注、文本和对偶嵌入等。
关键词:NLP,文本嵌入,文档嵌入,生物医学,NER,PoS,情感分析

mindsdb
MindsDB是一个低代码的机器学习平台。它将几个ML框架作为「AI表」自动集成到数据栈中,以简化AI在应用程序中的集成,让所有技能水平的开发人员都能使用。
关键词:数据库,低代码,AI表
langchain
Langchain旨在协助开发兼容 LLM 和其他知识来源的应用程序。该库允许对应用程序进行链式调用,在许多工具中创建一个序列。
关键词:LLM,大型语言模型,智能体,链
ParlAI
ParlAI是一个用于分享、训练和测试对话模型的python框架,从开放领域的聊天,到面向任务的对话,再到可视化问题回答。它在同一个API下提供了100多个数据集,许多预训练模型,一组智能体,并有几个集成。
关键词:对话,聊天机器人,VQA,数据集,智能体
sentence-transformers
这个框架提供了一种简单的方法来计算句子、段落和图像的密集向量表示。这些模型基于BERT/RoBERTa/XLM-RoBERTa等Transformer为基础的网络,并在各种任务中取得SOTA。文本嵌入到向量空间中,这样类似的文本就很接近,可以通过余弦相似度高效找到。
关键词:密集向量表示,文本嵌入,句子嵌入
ludwig
Ludwig是一个声明式的机器学习框架,使用一个简单而灵活的数据驱动的配置系统,可以轻松定义机器学习pipelines。Ludwig针对的是各类AI任,提供了一个数据驱动的配置系统,训练、预测和评估脚本,以及一个编程的API。
关键字:声明式,数据驱动,ML 框架

InvokeAI
InvokeAI是Stable Diffusion模型的一个引擎,面向专业人士、艺术家和爱好者。它通过CLI以及WebUI来利用最新的AI驱动技术。
关键词:Stable Diffusion,WebUI,CLI

PaddleNLP
PaddleNLP是一个易于使用且功能强大的NLP库,特别是针对中文语言。它支持多个预训练的模型动物园,并支持从研究到工业应用的广泛的NLP任务。
关键词:自然语言处理,汉语,研究,工业
stanza
斯坦福大学NLP小组的官方Python NLP库。它支持在60多种语言上运行各种精确的自然语言处理工具,并支持从Python访问Java Stanford CoreNLP软件。
关键词:NLP,多语言,CoreNLP
DeepPavlov
DeepPavlov是一个开源的对话式人工智能库。它被设计用于开发可生产的聊天机器人,和复杂的对话系统,以及在NLP领域的研究,特别是对话系统。
关键词:对话,聊天机器人
alpaca-lora
Alpaca-lora包含了使用低秩适应(LoRA)重现斯坦福大学Alpaca结果的代码。该资源库提供训练(微调)以及生成脚本。
关键词:LoRA,参数高效微调
imagen-pytorch
一个Imagen的开源实现,谷歌的封闭源文本到图像的神经网络击败了DALL-E2。imagen-pytorch是用于文本到图像合成的新SOTA。
关键词:Imagen,文生图

adapter-transformers
adapter-transformers是Transformers 库的一个扩展,通过纳入AdapterHub,将适配器集成到最先进的语言模型中,AdapterHub是一个预训练的适配器模块的中央存储库。它是Transformers的直接替代品,定期更新以保持与Transformers发展同步。
关键字:适配器,LoRA,参数高效微调,Hub
NeMo
NVIDIA NeMo是为从事自动语音识别(ASR)、文本-语音合成(TTS)、大语言模型和自然语言处理的研究人员构建的会话AI工具包。NeMo的主要目标是帮助来自工业界和学术界的研究人员重新利用以前的工作(代码和预先训练的模型),并使其更容易创建新的项目。
关键词:对话,ASR,TTS,LLM,NLP
Runhouse
Runhouse允许用Python将代码和数据发送到任何计算机或数据下层,并继续从现有代码和环境正常地与它们进行交互。Runhouse开发者提到:
可以将它看作 Python 解释器的扩展包,它可以绕道远程机器或操作远程数据。
关键词: MLOps,基础设施,数据存储,建模
MONAI
MONAI是PyTorch生态系统的一部分,是一个基于PyTorch的开源框架,用于医疗成像领域的深度学习。它的目标是:
– 发展一个学术、工业和临床研究人员的共同基础上的合作社区;
– 为医疗成像创建SOTA、端到端训练的工作流程;
– 为深度学习模型的建立和评价提供了优化和标准化的方法。
关键词:医疗成像,训练,评估
simpletransformers
Simple Transformers让您快速训练和评估Transformer模型。初始化、训练和评估模型只需要3行代码。它支持各种各样的 NLP 任务。
关键词:框架,简单性,NLP
JARVIS
JARVIS是一个将GPT-4等在内的LLM与开源机器学习社区其他模型合并的系统,利用多达60个下游模型来执行 LLM 确定的任务。
关键词:LLM,智能体,HF Hub
transformers.js
transformers.js是一个JavaScript库,目标是直接在浏览器中从transformers运行模型。
关键词:Transformers,JavaScript,浏览器
bumblebee
Bumblebee在Axon之上提供了预训练的神经网络模型,Axon是用于Elixir语言的神经网络库。它包括与模型的集成,允许任何人下载和执行机器学习任务,只需要几行代码。
关键词:Elixir,Axon
argilla
Argilla是一个提供高级NLP标签、监控和工作区的开源平台。它与许多开源生态系统兼容,例如Hugging Face、Stanza、FLAIR等。
关键词:NLP,标签,监控,工作区
haystack
Haystack是一个开源的NLP框架,可以使用Transformer模型和LLM与数据进行交互。它为快速构建复杂的决策制定、问题回答、语义搜索、文本生成应用程序等提供了可用于生产的工具。
关键词:NLP,Framework,LLM

spaCy
SpaCy是一个用于Python和Cython中高级自然语言处理的库。它建立在最新的研究基础之上,从一开始就被设计用于实际产品。它通过其第三方软件包spacy-transformers为Transformers模型提供支持。
关键词:NLP,架构

speechbrain
SpeechBrain是一个基于PyTorch的开源、一体化的会话AI工具包。我们的目标是创建一个单一的、灵活的、用户友好的工具包,可以用来轻松开发最先进的语音技术,包括语音识别、讲话者识别、语音增强、语音分离、语言识别、多麦克风信号处理等系统。
关键词:对话,演讲
skorch
Skorch是一个包装PyTorch的具有scikit-learn兼容性的神经网络库。它支持Transformers中的模型,以及来自标记器的标记器。
关键词:Scikit-Learning,PyTorch
bertviz
BertViz是一个交互式工具,用于在诸如BERT、GPT2或T5之类的Transformer语言模型中可视化注意力。它可以通过支持大多数Huggingface模型的简单Python API在Jupiter或Colab笔记本中运行。
关键词:可视化,Transformers

mesh-transformer-jax
mesh-transformer-jax是一个俳句库,使用JAX中的xmap/pjit运算符实现Transformers模型并行性。
这个库被设计为在TPUv3上可扩展到大约40B的参数。它是用来训练GPT-J模型的库。
关键词:俳句,模型并行,LLM,TPUdeepchem
OpenNRE
一种用于神经关系提取的开源软件包(NRE)。它的目标用户范围很广,从新手、到开发人员、研究人员或学生。
关键词:神经关系抽取,框架
pycorrector
一种中文文本纠错工具。该方法利用语言模型检测错误、拼音特征和形状特征来纠正汉语文本错误。可用于汉语拼音和笔画输入法。
关键词: 中文,纠错工具,语言模型,Pinyin

nlpaug
这个python库可以帮助你为机器学习项目增强nlp。它是一个轻量级的库,具有生成合成数据以提高模型性能的功能,支持音频和文本,并与几个生态系统(scikit-learn、pytorch、tensorflow)兼容。
关键词:数据增强,合成数据生成,音频,自然语言处理
dream-textures
dream-textures是一个旨在为Blender带来稳定扩散支持的库。它支持多种用例,例如图像生成、纹理投影、内画/外画、 ControlNet和升级。
关键词: Stable-Diffusion,Blender

seldon-core
Seldon core将你的ML 模型(Tensorflow、 Pytorch、 H2o等)或语言包装器(Python、 Java等)转换为生产 REST/GRPC微服务。Seldon可以处理扩展到数以千计的生产机器学习模型,并提供先进的机器学习功能,包括高级指标、请求日志、解释器、离群值检测器、A/B测试、Canaries等。
关键词:微服务,建模,语言包装
open_model_zoo
该库包括优化的深度学习模型和一组演示,以加快高性能深度学习推理应用程序的开发。使用这些免费的预训练模型,而不是训练自己的模型来加速开发和生产部署过程。
关键词:优化模型,演示
ml-stable-diffusion
ML-Stable-Diffusion是苹果在苹果芯片设备上为Core ML带来Stable Diffusion支持的一个仓库。它支持托管在Hugging Face Hub上的稳定扩散检查点。
关键词:Stable Diffusion,苹果芯片,Core ML

stable-dreamfusion
Stable-Dreamfusion是文本到3D模型Dreamfusion的pytorch实现,由Stable Diffusion文本到2D模型提供动力。
关键词:文本到3D,Stable Diffusion

txtai
Txtai是一个开源平台,支持语义搜索和语言模型驱动的工作流。Txtai构建了嵌入式数据库,它是向量索引和关系数据库的结合,支持SQL近邻搜索。语义工作流将语言模型连接到统一的应用程序中。
关键词:语义搜索,LLM

djl
Deep Java Library (DJL)是一个用于深度学习的开源、高级、引擎无关的Java框架,易于开发人员使用。DJL像其他常规Java库一样提供了本地Java开发经验和函数。DJL为HuggingFace Tokenizer提供了Java绑定,并为HuggingFace模型在Java中部署提供了简单的转换工具包。
关键词:Java,架构

lm-evaluation-harness
该项目提供了一个统一的框架,以测试生成语言模型在大量不同的评估任务。它支持200多项任务,并支持不同的生态系统:HF Transformers,GPT-NeoX,DeepSpeed,以及OpenAI API。
关键词:LLM,评估,少样本
gpt-neox
这个资源库记录了EleutherAI用于在GPU上训练大规模语言模型的库。该框架以英伟达的Megatron语言模型为基础,并以DeepSpeed的技术和一些新的优化来增强。它的重点是训练数十亿参数的模型。
关键词:训练,LLM,Megatron,DeepSpeed
muzic
Muzic是一个关于人工智能音乐的研究项目,它能够通过深度学习和人工智能来理解和生成音乐。Muzic是由微软亚洲研究院的研究人员创建的。
关键词:音乐理解,音乐生成

dalle-flow
DALL · E Flow是一个交互式工作流程,用于从文本提示符生成高清图像。它利用DALL · E-Mega、GLID-3 XL和Stable Diffusion生成候选图像,然后调用CLIP-as-service对候选图像进行提示排序。首选的候选者被馈送到GLID-3 XL进行扩散,这通常会丰富纹理和背景。最后,通过SwinIR将候选项扩展到1024×1024。
关键词:高清度图像生成,Stable Diffusion,DALL-E Mega,GLID-3 XL,CLIP,SwinIR

lightseq
LightSeq是在CUDA中实现的用于序列处理和生成的高性能训练和推理库。它能够高效地计算现代NLP和CV模型,如BERT,GPT,Transformer等。因此,它对于机器翻译、文本生成、图像分类和其他与序列相关的任务非常有用。
关键词:训练,推理,序列处理,序列生成

LaTeX-OCR
该项目的目标是创建一个基于学习的系统,该系统采用数学公式的图像,并返回相应的LaTeX代码。
关键词:OCR,LaTeX,数学公式
open_clip
OpenCLIP是OpenAI的CLIP的开源实现。
这个资源库的目标是使具有对比性的图像-文本监督的训练模型成为可能,并研究它们的属性,如对分布转移的鲁棒性。项目的出发点是CLIP的实现,当在相同的数据集上训练时,与原始CLIP模型的准确性相匹配。
具体来说,一个以OpenAI的1500万图像子集YFCC为代码基础训练的ResNet-50模型在ImageNet上达到32.7%的最高准确率。
关键词:CLIP,开源,对比,图像文本

dalle-playground
一个playground生成图像从任何文本提示使用Stable Diffusion和Dall-E mini。
关键词:WebUI,Stable Diffusion,Dall-E mini

FedML
FedML是一个联邦学习和分析库,能够在任何地方、任何规模的分散数据上进行安全和协作的机器学习。
关键词:联邦学习,分析,协作机器学习,分散
© 版权声明
文章版权归作者所有,未经允许请勿转载。