

IBM在年度IBM Think大会上将AI和混合云战略放到了核心位置。在过去几年里,其他厂商一直专注于新AI应用面向消费者的方面,IBM则一直在开发新一代模型以更好地服务于企业客户。
IBM前不久宣布推出了用于混合云应用的AI开发平台watsonx.ai。IBM watsonx AI开发服务目前处于技术预览阶段,将于2023年第三季度全面上市。
AI将成为关键的商业工具,开启生产力、创造力和价值创造的新时代。对于企业而言,这不仅仅是通过云访问大型语言模型(LLM)的新型AI结构。大型语言模型构成了ChatGPT等生成式AI产品的基础,但企业有许多必须考虑的问题:数据主权、隐私、安全性、可靠性(无漂移)、正确性、偏见等。
IBM对企业的一项调查发现,有30%-40%的企业发现了AI的商业价值,这个数字自2017年以来翻了一番。IBM引用的一项预测称,到2030年,AI将为全球经济贡献16万亿美元。该调查突显了使用AI提高生产力,除此之外还可以创造更多独特的价值,就像早期没有人能预测到互联网对未来的独特价值一样。AI将通过提高生产力来填补企业与拥有这些技能的人才之间存在的许多技能需求差距。
如今,AI变得更快速、无错误以改进软件编程。在Red Hat,IBM的Watson Code Assistant使用了watsonx,通过预测和建议要输入的下一个代码段,使编写代码变得更容易。AI的这种应用非常高效,因为它针对的是Red Hat Ansible自动化平台中的特定编程模型。Ansible Code Assistant比其他更通用的代码助手小35倍,因为它的优化程度更高。
另一个例子是SAP,SAP将整合Watson服务处理以支持SAP Start中的数字助理。SAP Start中的新AI功能将通过自然语言功能和使用IBM Watson AI解决方案的预测洞察力,帮助提高用户生产力。SAP发现,AI可以回答高达94%的查询请求。
为watsonx注入生命力
IBM AI开发堆栈分为三个部分:watsonx.ai、watsonx.data和watsonx.governance。这些watsonx组件旨在协同工作,也可以与第三方集成一起使用,例如来自HuggingFace的开源AI模型。此外,watsonx可以在多种云服务(包括IBM Cloud、AWS和Azure)和本地服务器上运行。

带有watson.ai、watsonx.data和watsonx.governance的IBM watsonx平台
Watsonx平台以即服务的形式交付,支持混合云部署。数据科学家借助这些工具就可以对自定义AI模型进行快速工程设计和调整,随后这些模型成为企业业务流程的关键引擎。
watsonx.data服务使用开放表存储以允许将多个来源的数据连接到watsonx的其余部分,管理用于训练watsonx模型的数据的生命周期。
watsonx.governance服务用于管理模型生命周期,在使用新数据训练和完善模型时对模型应用进行主动治理。
该产品的核心是watsonx.ai,开发工作就在这里进行。如今,IBM自身已经开发了20种基础模型(FM),它们具有不同的架构、模式和规模。除此之外,还有在watsonx平台上可用的HuggingFace开源模型。IBM预计一些客户将自己开发应用,由IBM提供咨询服务以帮助选择正确的模型、对客户数据进行再培训,并在需要时帮助加速开发。
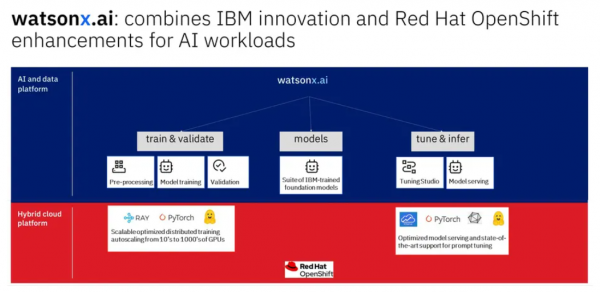
运行在Red Hat OpenShift上的IBM watsonx.ai软件栈
IBM花费三年多时间研究开发watsonx平台。IBM甚至构建了代号“Vela”的AI超级计算机,研究构建基础模型的有效系统架构,并在发布watsonx之前构建了自己的模型库。IBM充当AI平台自己的“客户0”。
与使用标准以太网网络交换机(而不是使用更昂贵的Nvidia/Mellanox交换机)的传统AI超级计算机相比,Vela架构的构建更容易、成本更低,如果客户想在他们的环境中运行watsonx,则可能更容易复制。此外,PyTorch还针对IBM Vela AI超级计算机架构进行了优化。IBM发现在Vela上运行虚拟化只有5%的性能开销。
IBM watsonx支持IBM基于Red Hat OpenShift的混合云战略承诺。watsonx AI开发平台在IBM云或者其他公有云(如AWS)或客户场所运行,即使存在不允许使用公共AI工具的业务限制,企业也可以利用这一最新的AI技术,IBM真正地把领先的AI和混合云与watsonx结合在了一起。
watsonx是IBM的AI开发和数据平台,用于大规模交付AI。Watson品牌下的产品都是具有AI专长的数字劳动力产品,其他Watson品牌产品包括Watson Assistant、Watson Orchestrate、Watson Discovery和Watson Code Assistant(以前的Project Wisdom)。IBM将更加关注Watson品牌,已经把以前的Watson Studio产品整合到watsonx.ai中,以支持新的基础模型开发和访问传统机器学习功能。
基础模型和大型语言模型
在过去的10年中,深度学习模型基于每个应用中的大量标记数据进行训练。这种方法是不可扩展的。基础模型和大型语言模型接受大量未标记数据的训练,这些数据更容易收集,然后可以使用这些新的基础模型来执行多项任务。
对于这种利用预训练模型执行多项任务的新型AI,实际上使用“大型语言模型”这个术语是有些不当的。使用“语言”,则意味着该技术仅适用于测试,但模型可以由代码、图形、化学反应等组成。IBM对这些大型预训练模型使用的术语更具描述性,也就是“基础模型”。通过使用基础模型,训练大量数据以生成特定的模型,然后可以按原样使用此基础模型,或者针对特定进行调整。通过为应用调整基础模型,还可以设置适当的限制并直接使模型更有用处。此外,基础模型还可以用于加快非生成式AI应用(如数据分类和过滤)的迭代。
许多大型语言的规模很大,而且规模越来越大,因为这些模型试图对每种数据都进行训练,以便可以用于任何潜在的开放领域。在企业环境中,这种方法通常是矫枉过正的,并且可能会遇到扩展方面的问题,而通过正确地选择合适的数据集,并将其应用于正确类型的模型,则可以让最终模型变得更高效,这个新模型也可以通过IBM watsonx.governance清除任何偏见、版权材料等。
小结
IBM Think大会期间,AI被号称正处于“Netscape时刻”,这个比喻指的是当更广泛受众接触到互联网时所达到的一个分水岭时刻。ChatGPT向更广泛的受众展示了生成式AI,但仍然需要企业可以依赖且可以控制的、负责任的AI。
正如Dario Gil在他的闭幕主题演讲中所说:“不要将您的AI策略外包给API调用。” HuggingFace公司首席执行官也表达了同样的观点:要有你自己的模型,不要租用别人的模型。IBM正在给企业提供工具来构建负责任的、高效的AI,并让他们拥有自己的模型。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


